Introduction
This article presents TSQL routines that provide support in SQL Server to use JSON data. The focus is on performance and flexibility.
Background
From Wikipedia: "JSON or JavaScript Object Notation, is an open standard format that uses human-readable text to transmit data objects consisting of attribute–value pairs. It is used primarily to transmit data between a server and web application, as an alternative to XML."
JSON is widely used as a simpler alternative to XML. In the last 8 years, it has gained a lot of popularity, and it is now present in almost every kind of situation: as a format for data transmission, for data storage, for defining schemas or templates, ...
SQL Server before 2016 does not include native JSON support, for these systems users willing to use JSON at the database level will have to choose:
- Add JSON support to the database via CLR routines
- Add JSON support via TSQL routines
Using CLR offers flexibility and great performance, it has the following issues:
- requires enabling CLR Integration, which may (or not) be beyond the authorization of the DB developer
- requires developing in other languages (usually C#)
- deployment can be "trickier" as it involves creating and assembly, registering,...
Being as widespread as it is, prior TSQL-JSON work do exist. The most comprehensive one, I have seen, being by Phil Factor (https://www.simple-talk.com/sql/t-sql-programming/consuming-json-strings-in-sql-server). As he states in his article, there are a number of reasons, for exploring, no matter how ugly it seems, the handling of JSON at the database level.
Storage of JSON
In JSON, there are only two types of structured data: objects and list of objects. The definition of the latter is pretty obvious “a set of zero, one or more objects” and relies on the former. This leads us a definition of object: an object is a container for a set of properties. A property is just a name that holds either a simple value (string, number, bool or NULL) or structured data.
In human readable form, JSON defines some syntax conventions, which are easily understood by seeing a sample:
{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"address":{
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumber": [
{"type": "home","number": "212 555-1234"},
{"type": "fax","number": "646 555-4567"}
]
}
There is only one link between a JSON object and its properties, the "owns" property. As properties can represent additional objects, it is straight forward that an object represents a hierarchy of objects. As there is only one single connectivity path (the “owns” property), the relation among a JSON object and its properties, can be represented by a simple hierarchy table. Modeling this hierarchy only requires two fields: one for identifying objects and properties, and other for defining the “owns” property.
Note: As further on, we will be using a JSON top down parser, I find it more intuitive to name this link “parent” instead of “owns”. Conceptually, they express the same: Object A owns property B, if and only if the parent of property B is object A.
Besides the object-property relation, some properties can hold simple values, so we will extend our hierarchy model with two additional fields: one with the value type (string, number,…) and another with the actual value. This model can be expressed in TSQL using a table type:
CREATE TYPE [dbo].[pjsonData] AS TABLE(
[id] [int] NOT NULL,
[parent] [int] NOT NULL,
[name] [nvarchar](100) NOT NULL,
[kind] [nvarchar](10) NOT NULL,
[value] [nvarchar](max) NOT NULL
)
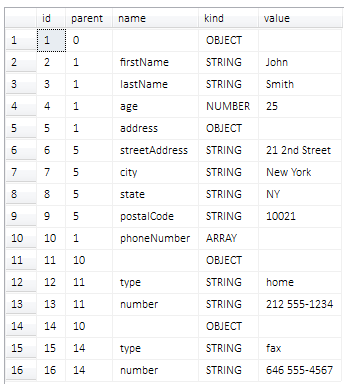
Using this structure, the previous JSON sample would be stored as:
ID Parent Name Kind Value
-----------------------------------------------------
1 0 OBJECT
2 1 firstName STRING John
3 1 lastName STRING Smith
4 1 age NUMBER 25
5 1 address OBJECT
6 5 streetAddress STRING 21 2nd Street
7 5 city STRING New York
8 5 state STRING NY
9 5 postalCode STRING 10021
10 1 phoneNumber ARRAY
11 10 OBJECT
12 11 type STRING home
13 11 number STRING 212 555-1234
14 10 OBJECT
15 14 type STRING fax
16 14 number STRING 646 555-4567
Consuming JSON: json_parse
Given a string representing JSON encoded data, this stored procedure generates a pjsonData table storing the data. The functionality of this procedure is very similar to the other existing parsers, nevertheless the implementation is completely different.
The parsing procedure is called pjsonData and its usage is quite simple. As expected, it receives a string of JSON text.
select * from json_Parse('{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"address":{
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumber": [
{"type": "home","number": "212 555-1234"},
{"type": "fax","number": "646 555-4567"}
]
}')
and returns a pJsonData table:
Generating JSON: json_toJson
This is the counterpart of the previous stored procedure. This procedure generates a JSON string representation for an item in a pjsonData table. Again, its working is better seen with a sample:
First let’s create a pjsonData table:
declare @data pJsonData
insert into @data select * from json_Parse('[
{"Name": "John Smith" ,
"address":{"streetAddress":
"21 2nd Street","city": "New York"}},
{"Name": "Jane Doe" ,
"address":{"streetAddress": "22 Madison Ave","city": "New York"}},
{"Name": "George Williams",
"address":{"streetAddress": "18 3rd Street","city": "Chicago"}}
]')
that sets the following:

JSON data can be generated by executing dbo.json_toJson(@data pjsonData,@id int).
Where @data is a pjsonData table and @id is the ID of the element we want displayed as JSON. So:
Notice that there is no object with ID=0 and dbo.json_toJson(@data,0) would raise an error.
Querying JSON: json_value and json_value2
These procedures apply a query expression on JSON data, if a property matching the query expression is found then the value for that property is returned, otherwise they return NULL. There are two versions for this procedure, one that receives the JSON data as a string (which internally gets parsed using json_Parse) and other that receives the JSON data as pJsonData. Use the second version when the same JSON data is queried more than once to avoid repetitive reparsing.
The syntax for them is:
dbo.json_Value(@json_string NVARCHAR(MAX),@query NVARCHAR(MAX))
dbo.json_Value2(@json_data pJsonData,@query NVARCHAR(MAX))
A query is a path expression detailing a valid route that, starting from the root object, reaches a property. A path expression uses the ‘.’ As a separator and index number or properties names as routing paths.
declare @json_string nvarchar(max)='[
{"Name": "John Jr" ,
"Family":[
{"relationship": "brother","Name": "Michael"},
{"relationship": "father" ,"Name": "John"},
{"relationship": "mother" ,"Name": "Marge"},
{"relationship": "sister","Name": "Jane"}
]
},
{"Name": "June" ,
"Family":[
{"relationship": "brother","Name": "George"},
{"relationship": "father" ,"Name": "Derek"},
{"relationship": "mother" ,"Name": "Lucy"}
]
}
]'
declare @json_data pJsonData
insert into @json_data select * from json_Parse(@json_string)
That can be queried, either with json_value or json_value2:
A great flexibility can be achieved by in-lining the JSON parsing and joining with a sequence generator. In the following sample, we are querying the table people(name,family). This table is generated on the-fly, with the family cell holding a JSON array.
select * from
(
select
people.name
,k.num
,dbo.json_value(people.family,k.num+'.name') [relative]
,dbo.json_value(people.family,k.num+'.relationship') relation
from (values ('John','[ {"relationship": "brother","Name": "Michael"},
{"relationship": "father" ,"Name": "John"},
{"relationship": "mother" ,"Name": "Marge"},
{"relationship": "sister","Name": "Jane"}]'),
('Jane','[ {"relationship": "brother","Name": "George"},
{"relationship": "father" ,"Name": "Derek"},
{"relationship": "mother" ,"Name": "Lucy"}]')) people(name,family)
,(select '0' num union select '1' union select '2' union select '3' union select '4' union select '5') k
) md where md.relation is not null order by name,num
that returns:
Implementation
Instead of using RegExp (or SQL-ish alternatives: PATINDEX, STUFF, temp string tables,…) this stored procedure implements a full lexer-parser engine that iterates through the input string and writes items into the hierarchy table as they are found. This is done through a heavy use of SQL procedural extensions implemented in TSQL. This has its cons & pros.
CONS
- This approach is quite far from the "SQL way of getting stuff done". The code has a loops, recursion,... more than enough to raise an eye brow from a purist point of view.
- Not portable to other SQL dialects (PSQL, PL/SQL, SQL PL,PL/pgSQL,..)
- Support functions pollute the name space
PROS
- Execution flow is simple and easy to follow (and to hack and to customize)
- Trashing of
strings is reduced to the bare minimum, as such there is very little memory overhead which improves performance.
To test the performance, using www.json-generator.com I have generated same sample JSON data of different sizes. This data has been inserted into a table (jdata) and the following test has been executed:
- For each record in the
jData table - Print the size of the JSON data
- Parse the JSON data using this article PROCedural parser, and NON-PROCedural parser from the www.simple-talk.com website
- Print the number of generated JSON elements in both cases (it should be the same for both parsers)
- Print how many seconds it has taken to parse
Which gives:
Conclusion and Future
Use of JSON data at the database level, definitively, is a valid option. It provides a lot of flexibility, and, in some situations, can be a valid technique to simplify the implementation of application-database resources: configuration, simple lookups or joined tables, filters or even dynamic queries.
In doing so, there a number of advantages:
- Less data traffic in certain cases
- Logic implementation closer to the database level (this can be good or bad depending on the situation)
- Simpler data storage design
Although the hierarchy model is robust, and offers the same query possibilities as its underlying relational model, there are two major caveats:
- Performance: Although the use of procedural techniques improves performance, it is still far away from its C# counterpart. In this current incarnation, I discourage it for large sets of JSON records or for large JSON files.
- The syntax for querying is rather convoluted, and not easy to follow.
In the next series of this article, we will develop further more the use of JSON on the server by:
- Improving syntax by creating helper queries
- Use some JSON-based techniques to offer expanded functionality
- Let's take a look at CLR alternatives

