Introduction
There are countless ways to trim all whitespace from a string. Most will work perfectly for the vast majority of use cases, but in some time-sensitive applications picking the fastest method may be the difference between night and day (if you are not a night person, of course).
There's some confusion regarding what whitespace really is. Many people assume whitespace is equivalent to the SPACE character (Unicode U+0020, ASCII 32, HTML  ), but it actually comprises all characters that contribute horizontal or vertical space in typography. It is, in fact, an entire class of characters as defined in the Unicode Character Database. More information can be read at the Whitespace character wikipedia entry.
This article uses the proper definition of whitespace while also including the string.Replace(" ", "") method for comparison with what a naive implementation would be (despite being unfair to the other methods wich properly handle whitespace characters, not only spaces).
The methods benchmarked here will trim all leading, trailing and intervening whitespace. That's what the "all whitespace" in the title is all about. :-)
Note: I've changed the title of the article from "...to trim all whitespace..." to "...to remove all whitespace..." because some readers were having trouble with the definition of the word trim. For them "to trim" means exclusively to trim the edges and, while the dictionary tells a different story, if I could make things clearer, why not? (by the way the movie industry uses the word trim in the exact same meaning as I've used in the original title: to trim from the edges and from the middle of a movie strip).
Background
This article started out of curiosity actually. I didn't need the fastest algorithm for trimming all whitespace on a string at all, anything that worked correctly would do, but I was surprised when I started stumbling on Stack Overflow articles suggesting the use of Regular Expressions and that it would, perhaps, be faster than most other methods "since Microsoft certainly tweaked it for speed", "it will work best with bigger datasets", etc. I didn't buy that, so I've opted to go the experimental way instead (for those curious, one of the SO question that sparked it was: Efficient way to remove ALL whitespace from String?)
Checking for Whitespace Characters
It couldn't be easier to check for the whitespace character. All that is needed is:
char wp = ' ';
char a = 'a';
Assert.True(char.IsWhiteSpace(wp));
Assert.False(char.IsWhiteSpace(a));
But when I was implemeting the hand-optimized trimming methods I realised it wasn't perfoming as expected. A little source code digging revealed this code on char.cs in Microsoft's reference source code repository:
public static bool IsWhiteSpace(char c) {
if (IsLatin1(c)) {
return (IsWhiteSpaceLatin1(c));
}
return CharUnicodeInfo.IsWhiteSpace(c);
}
And then CharUnicodeInfo.IsWhiteSpace turns out to be:
internal static bool IsWhiteSpace(char c)
{
UnicodeCategory uc = GetUnicodeCategory(c);
switch (uc) {
case (UnicodeCategory.SpaceSeparator):
case (UnicodeCategory.LineSeparator):
case (UnicodeCategory.ParagraphSeparator):
return (true);
}
return (false);
}
The GetUnicodeCategory() method calls the InternalGetUnicodeCategory() method and is actually pretty fast but now we already have 4 method calls in sequence (the JIT will certainly inline some of it but...)! Following suggestions by a commenter I've implemented a custom-made version which aims to be very fast and inlined by the JIT by default:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static bool isWhiteSpace(char ch) {
switch (ch) {
case '\u0009': case '\u000A': case '\u000B': case '\u000C': case '\u000D':
case '\u0020': case '\u0085': case '\u00A0': case '\u1680': case '\u2000':
case '\u2001': case '\u2002': case '\u2003': case '\u2004': case '\u2005':
case '\u2006': case '\u2007': case '\u2008': case '\u2009': case '\u200A':
case '\u2028': case '\u2029': case '\u202F': case '\u205F': case '\u3000':
return true;
default:
return false;
}
}
The Different Methods to Trim a String
I've implemented various different methods to trim all whitespace from a string (this includes intervening whitespace).
Split and Concat
This is a very simple method which I've been using for years. You split the string on whitespace characters, excluding empty entries, then concatenate the resulting pieces back together. It doesn't sound very smart, and in fact it looks, at first sight, a lot like a very wasteful way to solve the problem:
public static string TrimAllWithSplitAndJoin(string str) {
return string.Concat(str.Split(default(string[]), StringSplitOptions.RemoveEmptyEntries));
}
LINQ
This is a very elegant way to implement this procedure almost declaratively:
public static string TrimAllWithLinq(string str) {
return new string(str.Where(c => !isWhiteSpace(c)).ToArray());
}
Regular Expressions
Sometimes I think one could write Titanfall entirely in one huge Regular Expression! :-) They are one of the most powerfull assets any programmer should be aware of. On the other hand, maybe what we are trying to achieve is so simple that we will be wasting a lot of power for such a basic thing.
static Regex whitespace = new Regex(@"\s+", RegexOptions.Compiled);
public static string TrimAllWithRegex(string str) {
return whitespace.Replace(str, "");
}
Note: I cache the "whitespace" Regex object outside the method so that it can be reused. There is a considerable overhead instantiating a new Regex object everytime. The Regex is also created with the RegexOptions.Compiled paramenter and it speeds up things considerably!
Inplace Char Array
This method converts the input string into a char array and then scans the string removing whitespace characters inplace (without creating intermediate buffers or strings). In the end a new string is created from a "trimmed" array as there may be whitespace characters left at the end of the string due to the inplace substitution of characters.
public static string TrimAllWithInplaceCharArray(string str) {
var len = str.Length;
var src = str.ToCharArray();
int dstIdx = 0;
for (int i = 0; i < len; i++) {
var ch = src[i];
if (!isWhiteSpace(ch))
src[dstIdx++] = ch;
}
return new string(src, 0, dstIdx);
}
Note: If there was a way to change a .NET array length inplace I believe this method could have been faster by relinquishing the need to create a new array and call Array.Copy at the end. Turns out I can use a string constructor that accepts a char array, an index and a count of characters to return a new string without creating an intermediate array! That had a signficant impact in the speed of this method (and also the Char Array Copy method)
Char Array Copy
This method is similar to the Inplace Char Array method but it uses Array.Copy to copy "strings" of contiguous non-whitespace characters, while skipping whitespaces, in fact it is almost the negative version of the inplace char array method. At the end it creates a properly sized char array and returns a new string from it in the same manner.
public static string TrimAllWithCharArrayCopy(string str) {
var len = str.Length;
var src = str.ToCharArray();
int srcIdx = 0, dstIdx = 0, count = 0;
for (int i = 0; i < len; i++) {
if (isWhiteSpace(src[i])) {
count = i - srcIdx;
Array.Copy(src, srcIdx, src, dstIdx, count);
srcIdx += count + 1;
dstIdx += count;
len--;
}
}
if (dstIdx < len)
Array.Copy(src, srcIdx, src, dstIdx, len - dstIdx);
return new string(src, 0, len);
}
Lexer Loop Switch
This code implements a loop and uses the StringBuilder class to try to create the new string by relying on StringBuilder inherent optimizations. To avoid any other factors from interfeering with this implementation, no other method calls are made and class member access is avoided by caching into local variables. In the end the buffer is resized to the proper length by setting StringBuilder.Length.
public static string TrimAllWithLexerLoop(string s) {
int length = s.Length;
var buffer = new StringBuilder(s);
var dstIdx = 0;
for (int index = 0; index < s.Length; index++) {
char ch = s[index];
switch (ch) {
case '\u0020': case '\u00A0': case '\u1680': case '\u2000': case '\u2001':
case '\u2002': case '\u2003': case '\u2004': case '\u2005': case '\u2006':
case '\u2007': case '\u2008': case '\u2009': case '\u200A': case '\u202F':
case '\u205F': case '\u3000': case '\u2028': case '\u2029': case '\u0009':
case '\u000A': case '\u000B': case '\u000C': case '\u000D': case '\u0085':
length--;
continue;
default:
break;
}
buffer[dstIdx++] = ch;
}
buffer.Length = length;
return buffer.ToString();;
}
Note: This code was suggested by member Basketcase Software in the comments and was implemented as faithful to his original intent as possible. No further optimizations were attempted. The name of the method come from the fact that originally there was some sort of lexical scope in the algorithm but when some bugs were ironed out the lexical scope turned out not to be needed at all, but the name stuck and sounds good by the way! (Maybe it should be changed to Inplace StringBuilder... I'm open to suggestions)
Lexer Loop Char
This method is (almost) the same as the previous Lexer Loop method but it employs an if statement with a call to isWhiteSpace() instead of the dirty switch trick :-). It should perform exactly the same. If it does not then it may be due to the if statement or the method call (despite the fact that the JIT will almost certainly inlined it).
public static string TrimAllWithLexerLoopCharIsWhitespce(string s) {
int length = s.Length;
var buffer = new StringBuilder(s);
var dstIdx = 0;
for (int index = 0; index < s.Length; index++) {
char currentchar = s[index];
if (isWhiteSpace(currentchar))
length--;
else
buffer[dstIdx++] = currentchar;
}
buffer.Length = length;
return buffer.ToString();;
}
String Inplace (UNSAFE)
This method uses unsafe char pointers and pointer arithmetic to change an otherwise immutable string in-place. It is not an advised method to use in production as it breaks a fundamental contract of the .NET framework: strings are immutable. I've attempt to go even deeper and actually change the logical length of the string without instantiating a new one by accessing the private m_stringLength field of the internal native string structure but that resulted in an ulterior access violation in the garbage collector on a Win64 OS (I believe it will work on a Win32 version of windows though).
public static unsafe string TrimAllWithStringInplace(string str) {
fixed (char* pfixed = str) {
char* dst = pfixed;
for (char* p = pfixed; *p != 0; p++)
if (!isWhiteSpace(*p))
*dst++ = *p;
return new string(pfixed, 0, (int)(dst - pfixed));
}
}
Note: I've left the "in-place" string length reset attempt commented above for the curious out there!
String Inplace V2 (UNSAFE)
This is almost the same as the previous method but uses array-like pointer access. I was curious which mode of memory access would be faster.
public static unsafe string TrimAllWithStringInplaceV2(string str) {
var len = str.Length;
fixed (char* pStr = str) {
int dstIdx = 0;
for (int i = 0; i < len; i++)
if (!isWhiteSpace(pStr[i]))
pStr[dstIdx++] = pStr[i];
return new string(pStr, 0, dstIdx);
}
}
String.Replace("", "")
This is a naive implementation which does not use the proper definition of whitespace as it only replaces space characters, missing a lot of other whitespace characters. It should be the fastest method here, but it is not functionally equivalent to the others. The comparison is unfair even if it outperforms every other method by orders of magnitude (it doesn't).
On the other hand, if all you really need is to remove space characters it'll be very, very hard to write anything in pure .NET that outperforms string.Replace. The .NET engineers worked very (and I mean VERY) hard to make sure strings perform spectacularly well in the framework. Most string methods will fallback to hand-optimized native C++ code. The String.Replace itself will call a C++ method in comstring.cpp which have the following signature (based on the SSCLI2.0 source code):
FCIMPL3(Object*,
COMString::ReplaceString,
StringObject* thisRefUNSAFE,
StringObject* oldValueUNSAFE,
StringObject* newValueUNSAFE)
And then resort to all forms of dirty :-) pointer and memory access tricks to make it really fast!
Here is the method in the benchmark suite:
public static string TrimAllWithStringReplace(string str) {
return str.Replace(" ", "");
}
Points of Interest
Since we can potentially create lots of huge strings we could easily stumble into .NET memory limitations. These limitations are not a problem for ordinary scenarios, but may come into play in some critical applications. These are the limits we may face:
- Process memory limit of 2GiB (x86) or 4Gib (x64) (Target: AnyCPU or x86)
- Single-object memory size limit of 2GiB (.NET versions 1.0 up to 4.0)
To workaround these problems the project is compiled targeting platform x64 and framework 4.5. This will lift all previous memory limits and you'll be haunted only by your available operating system memory.
A very good article on this subject is Memory Limits in a .NET Process.
It's important to notice too that since both unsafe methods will change the original strings in-place, which breaks .NET "string contract", I had to perform a deep copy of the source strings to restore it back after each test was run, or else the source strings would be passed already trimmed to the next methods. This time was NOT taken into account when measuring the performance of these methods for obvious reasons. Here is the code for the deep copy for the curious:
public static List<string> CloneStrings(List<string> source) {
using (MemoryStream ms = new MemoryStream()) {
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(ms, source);
ms.Position = 0;
return (List<string>)bf.Deserialize(ms);
}
}
I've opted to serialize it back and forth because I had to make sure no strings were interned and kept the old references!
The Benchmark
To run the benchmarks I've opted to write a very simple WinForms application which will create a list of randomized strings with white space all over. The end-user is able to select how many strings he/she wants to process and the aproximate length for each string (the randomization method does not generate intermediate strings of predictable length, so the final length is not exact). The same source data is passed to all trimming methods individually and timing statistics are recorded and displayed to the user. The benchmark code is trivial. All benchmark methods will look pretty much the same, just a delegate with a loop over the source strings, passing this delegate to the execute(...) method, which will handle logging, timing and some Garbage Collector issues to try to prevent it from interfering with the running methods:
void execute(Action method, string name) {
results = new List<string>(strings.Count);
GC.Collect(GC.MaxGeneration, GCCollectionMode.Default, true);
GC.WaitForPendingFinalizers();
log("START: Method " + name);
watch.Restart();
method();
watch.Stop();
var elapsed = watch.Elapsed;
log(String.Format("ELAPSED: {0}\r\n----", elapsed));
timings[name] = elapsed;
}
private void BenchmarkStringReplace() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithStringReplace(s));
}, "STRING.REPLACE");
}
private void BenchmarkSplitAndConcat() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithSplitAndConcat(s));
}, "SPLIT AND CONCAT");
}
private void BenchmarkRegex() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithRegex(s));
}, "REGEX");
}
private void BenchmarkLinq() {
execute(() => { foreach (var s in strings) results.Add(TrimAllWithLinq(s));
}, "LINQ");
}
private void BenchmarkArrayCopy() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithCharArrayCopy(s));
}, "ARRAY.COPY");
}
private void BenchmarkInplaceCharArray() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithInplaceCharArray(s));
}, "INPLACE CHAR ARRAY");
}
private void BenchmarkStringInplace() {
var backup = Helpers.CloneStrings(strings);
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithStringInplace(s));
}, "STRING INPLACE");
strings = backup;
}
private void BenchmarkStringInplaceV2() {
var backup = Helpers.CloneStrings(strings);
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithStringInplaceV2(s));
}, "STRING INPLACE V2");
strings = backup;
}
private void BenchmarkWithLexerLoop() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithLexerLoop(s));
}, "LEXERLOOP SWITCH");
}
private void BenchmarkWithLexerLoopCharWhitespace() {
execute(() => {
foreach (var s in strings) results.Add(TrimAllWithLexerLoopCharIsWhitespce(s));
}, "LEXERLOOP CHAR");
}
The Benchmark Setup
The benchmark was run on a PC under Windows 7 Ultimate 64-bit with a Core i7-3770K CPU @ 3.5GHz - 3.90GHz and 16GiB of memory. I'm currently gathering other benchmark results on my various computers and I'll update the article with the results on different framework versions, operating systems and CPU. I'm even considering writing the tests for Mono to see how it performs under some Linux flavors.
The Benchmark Results
Disclaimer: The benchmarks on the original version of this article were mistakenly taken with the DEBUG version of the application, not the RELEASE version. While the results were surprising they were also completey bogus! It is not actually important to know how well a code performs before optimizations. All that matters (to the vast majority of scenarios) is how the code performs after the JIT squeezes every ounce of it!
The benchmark results will be shown with screenshots from the application itself and all tests are numbered.
Since the string.Replace() method is not functionally equivalent to the others, it won't be considered for the winner on any benchmark.
Test 1 (Default): 10,000 Strings of 1,024 characters
This is the default benchmark as the application will use these values at startup: 10,000 strings of approximately 1,024 characters each.
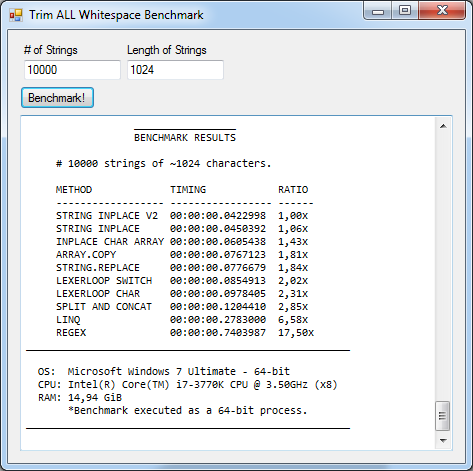
This result was somewhat surprising. While I was expecting the regexp-based solution to take longer, I didn't expect it to be ~10x slower than the fastest managed method and a whooping ~17 times slower than the winner. I also expected the LINQ implementation to at least match the Split and Concat for speed. But what surprised me the most was that I was able to surpass string.Replace() for speed with my own Inplace Char Array method despite the native C++ optimized code of the former! Cool!
Note: the near tie of string.Replace and Array Copy methods makes the winner random on each default benchmark run, so I've chosen a screenshot in which I won! But the credits should really be going to the JIT for optimizing it on the fly and make it so fast!
The other hand-optimized methods are all very fast. The Lexer Loop Char is slower thant the Lexer Loop Switch consistently, which makes me believe that the JIT wasn't able to optimize it as well as the inlined switch-based logic. I didn't looked at the IL code but I really believe that even though the isWhiteSpace() method was certainly inlined there's an added if statement around that inlined code while in the "Switch" version the switch statement is used directly in the loop. I've since updated the other methods to use the switch directly and avoid calling the isWhiteSpace method whatsoever so that no speed penalty is incurred. The benchmark results here are from this optimized version of the code.
The unsafe methods are the fastest though. Both were nearly 50% faster than the fastest managed method, which was to be expected as no extra array allocation is needed to process the strings. Both methods could have been even faster, perhaps significantly faster, if I was able to pull off the direct string length manipulation, but it didn't work and I had to create a new string to return the "trimmed" string back to the caller, which, internally will allocate a new char array which slows it down.
Winner (overall): String Inplace V2
Winner (managed): Inplace Char Array
Test 2: 100,000 strings of 1,024 characters
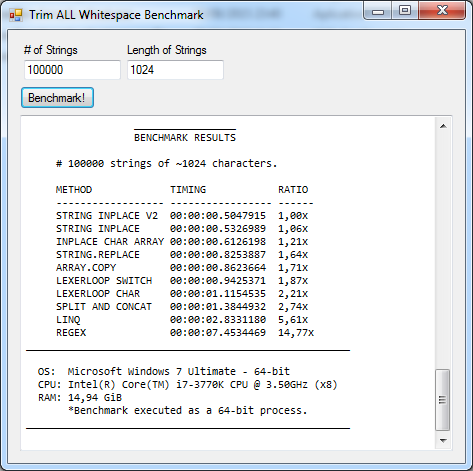
History repeats itself with regexp being ~15x slower and LINQ ~5.6x slower than the fastest method. String.Replace now is consistently faster than Array.Copy but not much.
Winner (overall): String Inplace V2
Winner (managed): Inplace Char Array
Test 3: 10,000 strings of 100,000 characters (Discontinued)
This test was aimed to verify if any of the solutions would perform relatively better with bigger individual strings. It was expected that the Regex engine in .NET is smart enough to work with larger strings. The problem was that my 16 GiB of memory was not enough to run this test properly, and with the requirement to deep copy the source string list for each unmanaged benchmark (as the strings will be changed in-place) this test simply refused to run on my box. So I discontinued it.
The other reason for its discontinuation is: Since all methods are run in succession, and memory usage is really huge in this test (the peak memory used by the process was nearly 15 GiB, perhaps a little bit over my 14,95 GiB physical memory) there exists the possibility that a previous test memory allocation is interfeering with the results from subsequent tests. My computer went totally unresponsive during this test and slowed to a halt after the test finished running! Closing the application took a lot of time, and only after a long minute did the memory usage drop from 93% to 15%! Perhaps the best way to test it would be with individual buttons for each test and run them individually, in separate invocations of the benchmark application process, so that each test really run in total isolation. Perhaps I'll implement it in the next version of the article.
WINNER: Not applicable
Test 4: 10,000 strings of 10,000 characters
This test should be equivalente to (the discontinued) Test 3 as it aims to test the trimming methods against longer strings. The 10,000 repetition will prevent any individual deviations on each test run and the 10,000 long strings will guarantee that each test will have to perform well against huge strings. Since this test won't be too memory intensive as the 100,000 long strings of Test 3, it'll show a clearer picture of which test is faster in real-world scenarios against longer strings.
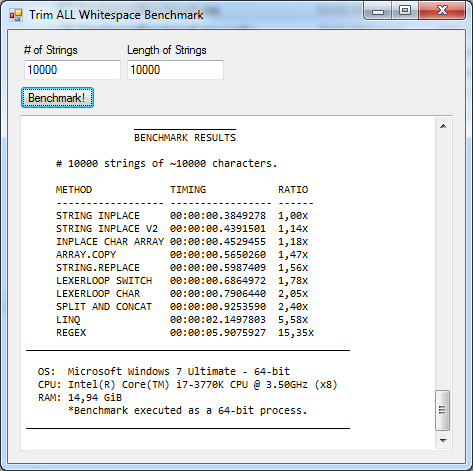
In this test, where physical memory was certainly not an issue, the results are almost the same as the Default Test: Inplace Char Array is still the winner on the managed side and this time Array.Copy outperformed String.Replace consistently. No surprises for LINQ and Regex, and the Lexer Loop methods still perfomed very fast, as also did Split and Concat.
The unmaged methods still come in first place overall but String Inplace surpassed String Inplace V2, but the margin didn't get any bigger, in fact it shrunk a little as Inplace Char Array is narrowing the gap! Cool 2!
Winner (overall): String Inplace
Winner (managed): Inplace Char Array
Conclusion
First of all: this benchmark does not matter for most real-world applications. At least not directly, as it is not that common to remove/trim white spaces on huge strings or inside long running tight loops. The scenario proposed in this article is fabricated and artificial. But these results could be extrapolated to other common string manipulations which we normally use Regular Expressions for. If the manipulation can easily be achieved "by hand", perhaps the power of Regular Expressions is overkill and the overhead of using it could affect performance negatively.
We can safely assume, however, that String.Split() and String.Concat() are very fast and optimized methods, which we can use in a lot of use cases, so don't be afraid, as I was at the beginning, of wasting resources spliting strings and then concatenating them back together. In the end the Split and Concat method performed well in comparison with LINQ and REGEX but still lagged behind the "hand-optimized" methods.
While Regular Expressions are very succinct and powerful, it did not match the performance of any other method, not even with huge strings. So use it judiciously, but don't be fooled: I LOVE REGULAR EXPRESSIONS! I find them indispensible in any programmer's arsenal.
The Inplace Char Array method proved exceptionaly fast. Faster still than the simpler (and not functionally equivalente) C++ optimized string.Replace method!
If I was to choose a method I would certainly go with Inplace Char Array. I didn't think it could possibly match string.Replace for speed but it surpassed it!
The unsafe methods performed very well, but with larger strings the Inplace Char Array method was able to almost match them for speed, being only 18% percent slower. As the unsafe methods will break .NET's string contract of immutability, I adivise in favor of the faster managed method instead.
In the end this articles shows that we can write in managed .NET very performance-intensive code without resorting to unsafe or native implementations. I would stick with it unless absolutely needed.

