In this part, we will demonstrate how to setup Elasticsearch and learn how to write basics statements. You will learn about the structure, commands, tools in Elasticsearch API and get it up and running using standard settings.
Introduction
In this two-part article, we will be talking about the basics of Elasticsearch API.
In Part 1, we are going to walk through its structure, commands, tools, and get it up and running using standard settings. We will also create a simple Windows Form application in order to demonstrate a CRUD operation, showing some of Elasticsearch’s nice features all along the way.
In the second part, we will explore the integration between Elasticsearch and .NET.
Background
If you are interested in this article, I assume you have had some experience with Lucene or, at least, heard about it. It’s clearly a hot topic in the industry lately.
But, if you have never heard about it, or you’re in doubt, I’d suggest have a look here on Code Project. There are plenty of nice articles about it. Since Lucene is the highlight technology of Elasticsearch, it’s quite important to understand how it works before playing with Elastic.
I have been working with Lucene for one year and my personal experience using Elastic started a couple of months ago, when our company decided to migrate our BI’s core from “pure” Lucene to Elastic. My main source of information comes from its official website.
What is Elasticsearch Anyway?
As I mentioned previously, Elastic runs on top of a Lucene storage. Among other things, it allows us to save significant legwork creating standard features, for instance: indexing, querying, aggregating, and the distribution of the physical index files across servers.
For those who have used several frameworks or even have created your own set of classes in order to deal with "pure" Lucene, this is exciting news. It's really a productive API.
Getting Started
So, let’s start the “funny” part (I believe I'm not the only developer here who dislikes environmental setup!). First, you will need to install and take care of a couple of settings:
1) Dependencies
Luckily just one, Elasticsearch requires a recent version of Java. You should install the latest version from the official Java website.
2) API
You can download the latest version of Elasticsearch from its website.
3) Config
Before starting Elastic server, you must change these settings on the [Installation Path]\config\elasticsearch.yml file:
4) Run It!
Getting the server up and running is simple as:
- Open the Command Prompt as administrator.
- Go the folder where you have installed Elastic.
- Go to bin folder.
- Type elasticsearch.bat and press Enter:
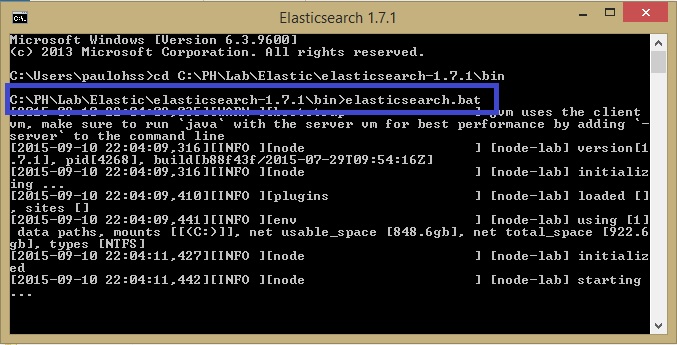
You can check if it is alive by testing the following URL in your browser:
http://localhost:9200/_cluster/health?pretty.
5) IDE for Quering
In order to test your brand new storage, you definitely need a good IDE. Fortunately, Elastic.org provides it.
I’ve been testing others IDEs, but Marvel and Sense are the best by far. This step should be done after you get Elastic server running and the installation command is:
[Installation Path]\bin> plugin -i elasticsearch/marvel/latest

Then, you are able to access these tools via browser:
Marvel (health monitor):
http://localhost:9200/_plugin/marvel/kibana/index.html#/dashboard/file/marvel.overview.json
Sense (IDE for querying):
http://localhost:9200/_plugin/marvel/sense/index.html
Writing Elastic Commands
Well, if you have survived the installation session, the fun part starts now!
As you can realise by this stage, Elastic is a RESTFul API thus its commands are totally based on Json. Good news since it’s largely used in the industry nowadays.
Roughly speaking, what I’m showing here is a parallel with what we would create in a relational database. Taking it into account, let’s start with our "create database" and "create table" statements.
Mapping
Mapping is the way that we will tell Elastic how to create our "tables". Throughout mapping, you will define the structure of your document, type of the fields, etc.
We will be working with the hypothetical (not too creative though!) entity “Customer”. So, the command you have to write in the Sense IDE is:
PUT crud_sample
{
"mappings": {
"Customer_Info" : {
"properties": {
"_id":{
"type": "long"
},
"name":{
"type": "string",
"index" : "not_analyzed"
},
"age":{
"type": "integer"
},
"birthday":{
"type": "date",
"format": "basic_date"
},
"hasChildren":{
"type": "boolean"
},
"enrollmentFee":{
"type": "double"
}
}
}
You can test if the mapping is fine with this command:
GET /crud_sample/_mapping
As a result, you should get:
Let’s say we have forgotten to create a field. Not a problem, you can add it by:
PUT /crud_sample/_mapping/Customer_Info
{
"properties" : {
"opinion" : {
"type" : "string",
"index" : "not_analyzed"
}
}
}
You can check how it went using the previous command.
Inserting a Row
Insert a new line (indexing is the correct term) is quite straightforward:
PUT /crud_sample/Customer_Info/1
{
"age" : 32,
"birthday": "19830120",
"enrollmentFee": 175.25,
"hasChildren": false,
"name": "PH",
"opinion": "It's Ok, I guess..."
}
You can check it through this command:
GET /crud_sample/Customer_Info/_search
Nevertheless, inserting line by line could be a bit painful. Fortunately, we can use a bulk load, like this:
POST /crud_sample/Customer_Info/_bulk
{"index": { "_id": 1 }}
{"age" : 32, "birthday": "19830120", "enrollmentFee": 175.25,
"hasChildren": false, "name": "PH", "opinion": "It's cool, I guess..." }
{"index": { "_id": 2 }}
{"age" : 32, "birthday": "19830215", "enrollmentFee": 175.25,
"hasChildren": true, "name": "Marcel", "opinion": "It's very nice!" }
{"index": { "_id": 3 }}
{"age" : 62, "birthday": "19530215", "enrollmentFee": 205.25,
"hasChildren": false, "name": "Mayra", "opinion": "I'm too old for that!" }
{"index": { "_id": 4 }}
{"age" : 32, "birthday": "19830101", "enrollmentFee": 100.10,
"hasChildren": false, "name": "Juan", "opinion": "¿Qué tal estás?" }
{"index": { "_id": 5 }}
{"age" : 30, "birthday": "19850101", "enrollmentFee": 100.10,
"hasChildren": true, "name": "Cezar", "opinion": "Just came for the food..." }
{"index": { "_id": 6 }}
{"age" : 42, "birthday": "19730101", "enrollmentFee": 50.00,
"hasChildren": true, "name": "Vanda", "opinion": "Where am I again?" }
{"index": { "_id": 7 }}
{"age" : 42, "birthday": "19730101", "enrollmentFee": 65.00,
"hasChildren": false, "name": "Nice", "opinion": "What were u saying again?" }
{"index": { "_id": 8 }}
{"age" : 22, "birthday": "19930101", "enrollmentFee": 150.10,
"hasChildren": false, "name": "Telks", "opinion": "Can we go out now?" }
{"index": { "_id": 9 }}
{"age" : 32, "birthday": "19830120", "enrollmentFee": 175.25,
"hasChildren": false, "name": "Rafael", "opinion": "Should be fine..." }
Now if you run the search statement, you will see 9 hits, which is pretty much all we have gotten so far. But if you want to check one particular customer, you just need to add its ID at the end of the URL:
GET crud_sample/Customer_Info/3
Updating
Elastic is clever enough to understand if you are adding a new doc or updating it by the “id” provided in the statement. For instance, imagine that you need to change the “opinion” of the customer number 3:
POST /crud_sample/Customer_Info/3/_update
{
"doc": {
"opinion": "I'm really too old for it."
}
}
Deleting
You must be as careful with these commands as you would be dealing with any database. The main options here are:
Delete the whole storage:
delete crud_sample
Delete a specific customer:
delete crud_sample/Customer_Info/1
Querying
Elastic is extremely resourceful when it comes to querying. I will cover the basics ones for our CRUD app.
Before running the following query samples, it might be interesting if you add some extra rows/doc.
Finding Exact Values
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"term" : {
"opinion" : "It's cool, I guess..."
}
}
}
}
}
You should get as a response the doc where the "opinion" matches with the query:
Combining Boolean Filters
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"must" : {
"term" : {"hasChildren" : false}
},
"must_not": [
{ "term": { "name": "PH" }},
{ "term": { "name": "Felix" }}
],
"should" : [
{ "term" : {"age" : 30}},
{ "term" : {"age" : 31}},
{ "term" : {"age" : 32}}
]
}
}
}
}
}
Note that we are combining three clauses here:
- "
must": Query must appear in matching documents. - "
must_not": Query must NOT appear in the matching documents. - "
should": Query should appear in the matching documents, but is not mandatory.
Finding Multiple Exact Values
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"filter" : {
"terms" : {
"age" : [22, 62]
}
}
}
}
}
As you can see above, Elastic allows to inform multiple values for the same field.
Ranges Queries
In this example, we are getting all docs with the enrollment fee between 10 and 100:
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"enrollmentFee" : {
"gte" : 10,
"lt" : 100
}
}
}
}
}
}
Now, using a date range for birthdays:
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"birthday" : {
"gt" : "19820101",
"lt" : "19840101"
}
}
}
}
}
}
And combining both, date and number fields:
GET /crud_sample/Customer_Info/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool": {
"must": [
{"range": {"enrollmentFee": { "gte": 100, "lte": 200 }}},
{"range": {"birthday": { "gte": "19850101" }}}
]
}
}
}
}
}
Aggregations
For big data analysis, aggregation is the icing on the cake. After all steps that a BI project demands, that is the moment where you start making sense from a huge amount of data.
Aggregations enable you to calculate and summarize data about the current query on-the-fly.
They can be used for all sorts of tasks, for instance: dynamic counting, average, min and max values, percentile, among others.
Roughly comparing, a count aggregation for our entity Customer in a SQL server would be:
Select Count(id) From customer
Let’s work out some sample with our indexes:
Counting Names
GET /crud_sample/Customer_Info/_search?search_type=count
{
"aggregations": {
"my_agg": {
"terms": {
"field": "name",
"size": 1000
}
}
}
}
You should get as a response:
Getting the Min Enrollment Fee
GET /crud_sample/Customer_Info/_search?search_type=count
{
"aggs" : {
"min_price" : { "min" : { "field" : "enrollmentFee" } }
}
}
The syntax is quite similar, basically the aggregation keyword will change. In this case, we are using "min".
Getting the Average Age
GET /crud_sample/Customer_Info/_search?search_type=count
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "age" } }
}
}
Now, calculating the average...
Getting a Multi-Value Aggregation
GET /crud_sample/Customer_Info/_search?search_type=count
{
"aggs" : {
"grades_stats" : { "extended_stats" : { "field" : "enrollmentFee" } }
}
}
This is a useful resource, running it you will get multiple aggregations.
Nested Aggregation
GET /crud_sample/Customer_Info/_search?search_type=count
{
"aggs": {
"colors": {
"terms": {
"field": "hasChildren"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
And at last, the nested aggregation. This is very interesting, the statement above is grouping the aggregation by the field 'hasChildren' and, inside its values (True or False) you will find the average age:
Conclusion
The purpose of this article was to demonstrate how to setup Elasticsearch and learn how to write basics statements. All of these concepts are going to be applied in our CRUD application.
Our main goal is to combine all of this with .NET, which we will achieve in the next (and final) article.
History
- 15th September, 2015: Initial version

