TLDR; I wrote an open source library called StackRedis.L1. It's a .NET Level 1 cache for Redis. What that means is that if you're using StackExchange.Redis in a .NET application, you can drop this library in to accelerate it by caching data locally in-memory to avoid unnecessary calls to Redis when the data hasn't changed. Visit the GitHub page, or get the NuGet package.
This is an account of how and why it was written.
Back Story
For the past couple of years I've been working on a SharePoint app, Repsor custodian. For those that know about SharePoint, the SharePoint app model requires that apps do not execute within the SharePoint process, but on a separate app server. This model provides for better stability and a cleaner architecture; however, this is at the cost of performance since every time you need SharePoint data you are at the mercy of network latency.
For this reason, we introduced Redis caching into the app, with StackExchange.Redis as the .NET client. We're using strings, sets, sorted sets, and hashes to cache all aspects of the app data.
Naturally, this speeded up the application hugely. Pages returned in around 500ms instead of the previous 2s - but when profiling, it was apparent that a large chunk of this 500ms was spent sending or receiving from Redis; much of which was being received on every page request without being changed.
Caching the Cache
Redis is a very very fast cache, but it's not just a cache because it lets you operate on the data in that cache. And, it's mature and widely supported. The StackExchange.Redis library is free and open source, with a lively community. It's what Stack Exchange uses to aggressively cache *all* their data - and that's one of the busiest sites on the internet. However, they have another trick up their sleeve - caching everything possible in-memory on the web server so that much of the time, they don't even have to talk to Redis.
This Stack Exchange meta answer explains in some detail the caching mechanisms they use: http://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how
"Naturally, the fastest # of bytes to send across a network is 0."
When you cache data before it reaches another cache, then you have multiple levels of cache. If you're using in-memory caching before your Redis cache, then the in-memory cache can be referred to as Level 1: https://en.wikipedia.org/wiki/CPU_cache#MULTILEVEL
So, if Redis is the slowest part of your app, then you're doing something right - and you can definitely speed it up further.
In-Memory Caching
At its simplest, when you use Redis, your code might look a little like this:
RedisValue redisValue = _cacheDatabase.StringGet(key);
if(redisValue.HasValue)
{
return redisValue;
}
else
{
string strValue = GetValueFromDataSource();
_cacheDatabase.StringSet(key, strValue);
return strValue;
}
And if you decided to introduce an in-memory cache (ie. a level 1 cache), it gets a little more complicated:
if (_memoryCache.ContainsKey(key))
{
return key;
}
else
{
RedisValue redisValue = _cacheDatabase.StringGet(key);
if (redisValue.HasValue)
{
_memoryCache.Add(key, redisValue);
return redisValue;
}
else
{
string strValue = GetValueFromDataSource();
_cacheDatabase.StringSet(key, strValue);
_memoryCache.Add(key, strValue);
return strValue;
}
}
Although this is not difficult to implement, things quickly get MUCH more complicated when we attempt to follow the same pattern for other Redis data types. In addition we are faced with the following issues:
- Redis allows us to operate on the data via functions such as StringAppend. In this case, we need to invalidate the in-memory item.
- When a key is deleted via KeyDelete, it needs to be removed from the in-memory cache.
- Another client may update or delete a value. In this case, the in-memory value on our client would be outdated.
- When a key expires, it needs to be removed from the in-memory cache.
Now, StackExchange.Redis data access and update methods are defined on the IDatabase interface. So, what if we wrote a custom IDatabase implementation to handle all of the situations outlined above? In this case, we could solve all of the above problems:
- StringAppend - in this trivial example, we'd append to the in-memory string, then pass the same operation to redis. For more complex data manipulation operations, we'd delete the in-memory key.
- KeyDelete, KeyExpire etc - deletes the in-memory data
- Operations via another client - Redis keyspace notifications are handled to detect that data has changed elsewhere, and is invalidated appropriately
The real beauty of this approach is of course that the same interface is implemented - the same interface you're already using - so you don't need to make *any* code changes to use this L1 caching solution.
Architecture
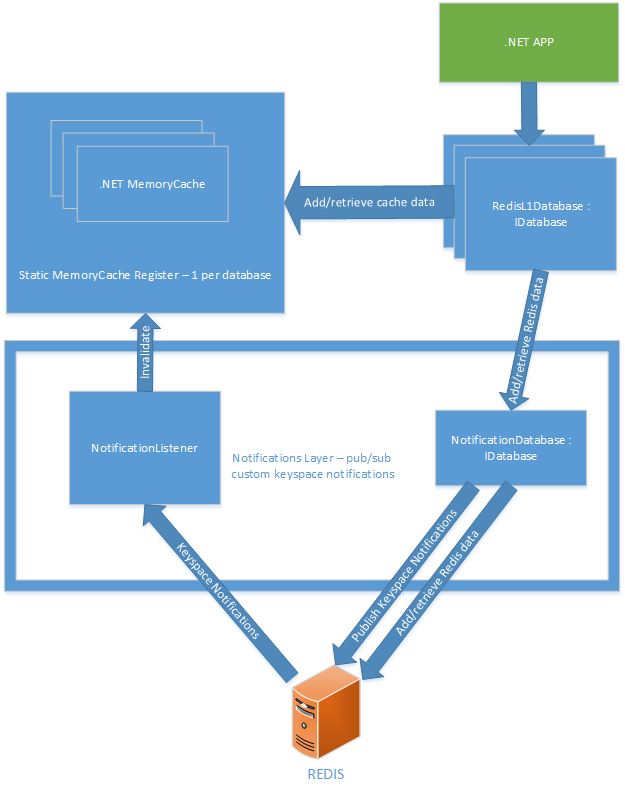
Here's the solution I've gone for. The important elements are:
Static MemoryCache Register
This means you can create new instances of RedisL1Database - passing in the Redis IDatabase instance you already have - and it'll continue to use any in-memory cache it had created previously for that database.
Notifications Layer
- NotificationDatabase - this publishes custom keyspace events which are required to keep any in-memory caches up-to-date. Redis out-of-the-box keyspace notifications on their own are not sufficient as they don't generally provide enough information to invalidate the correct parts of the memory cache. For example, if you delete a Hash key, you get a HDEL notification that tells you which hash had a key deleted. But, it doesn't tell you which element of the hash it was! The custom events include information on the actual hash element itself.
- NotificationListener - this subscribes to the custom keyspace events, and calls into the static memory cache to invalidate the relevant key. It also subscribes to one built-in redis keyspace event - expire. This means that keys are always removed from memory when redis expires a key.
In the following section we'll look at the caching techniques for the different Redis data types.
String
String is relatively simple. The IDatabase StringSet method looks like this:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags =
CommandFlags.None)
- Key and Value are obvious.
- Expiry - this is an optional timespan, so we need to use an in-memory cache that can handly expiry.
- When - This allows you to only set the string if it already exists, or doesn't already exist.
- Flags - This allows you to specify aspects of the redis cluster and isn't relevant.
To store strings, we're using System.Runtime.Caching.MemoryCache - this allows automatic expiry of keys. So our StringSet method looks something like this:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None)
{
if (when == When.Exists && !_cache.Contains(key))
{
return;
}
if (when == When.NotExists && _cache.Contains(key))
{
return;
}
_memCache.Remove(key);
CacheItemPolicy policy = new CacheItemPolicy()
{
AbsoluteExpiration = DateTime.UtcNow.Add(expiry.Value)
};
_memCache.Add(key, o, policy);
return _redisDb.StringSet(key, value, expiry, when, flags);
}
StringGet can then read the in-memory cache before attempting to retrieve from Redis:
public RedisValue StringGet(RedisKey key, CommandFlags flags = CommandFlags.None)
{
var cachedItem = _memCache.Get<redisvalue>(key);
if (cachedItem.HasValue)
{
return cachedItem;
}
else
{
var redisResult = _redisDb.StringGet(key, flags);
_memCache.Add(key, redisResult);
return redisResult;
}
}
</redisvalue>
Redis has a lot of supported string operations. In each case, our implementation must decide whether to update the in-memory value, or invalidate it entirely. In general, invalidation is better. This is because otherwise we risk introducing the complexity of many of Redis' operations needlessly.
- StringAppend - this is a very simple operation and the in-memory string is appended to if present, and not invalidated.
- StringBitCount, StringBitOperation, StringBitPosition - the operation is done in redis and no in-memory involvement is required.
- StringIncrement, StringDecrement, StringSetBit, StringSetRange - the in-memory string is invalidated before forwarding the operation to redis.
- StringLength - returns the length of the string if it's in-memory. Otherwise, gets it from redis.
Set
Sets are only a little more complicated. SetAdd follows the following pattern:
- Check the MemoryCache for a HashSet<RedisValue> with the given key
- If it doesn't exist, create it.
- Add each redis value to the set.
Adding and removing values from the sets is fairly trivial. SetMove is a SetRemove followed by a SetAdd, so that's simple too.
Many of the other set requests can be intercepted for caching. For example:
- SetMembers returns all the members of a set, so its results can be stored in memory.
- SetContains, SetLength can check the in-memory set before checking redis.
- SetPop pops an item from the Redis set, then removes that item from the in-memory set if present.
- SetRandomMember retrieves a random member from Redis, then caches it in-memory before returning.
- SetCombine, SetCombineAndStore - no in-memory involvement needed.
- SetMove - removes an item from in-memory set, adds to another in-memory set and forwards to redis.
Hash
Hash is relatively simple and the in-memory representation is a simple Dictionary<string,RedisValue>. In fact, the implementation is remarkably similar to the String type.
The basic operation is as follows:
- If the hash is not available in-memory, create an empty
Dictionary<string,RedisValue> and store it. - Perform the operation on the in-memory dictionary if possible.
- Forward the request to Redis if required
The Hash operations are roughly implemented as follows:
- HashSet - Stores values in the dictionary stored at key, then forwards to Redis.
- HashValues, HashKeys, HashLength - no in-memory implementation.
- HashDecrement, HashIncrement, HashDelete - removes the value from the dictionary and forwards to Redis.
- HashExists - returns true if the value is in-memory. Otherwise, forwards to Redis.
- HashGet - Attempts to get from in-memory. Otherwise, forwards to redis and caches results.
- HashScan - Retrieves results from Redis and adds to in-memory cache
Sorted Set
Sorted Sets are by far the most complicated data type to attempt to cache in-memory. The technique involves using a "Disjointed Sorted Set" as the in-memory caching data structure. This means that every time the local cache 'sees' a small section of the redis sorted set, that small section is added to the 'disjointed' sorted set. If, later on a subsection of the sorted set is requested, the disjointed sorted set is checked first. If it contains that section in full, it can be returned in the knowledge that there are no missing entries.
The in-memory set is sorted by score; not value. It would be possible to extend the implementation to also keep a disjointed sorted set which is sorted by value, but this is currently not implemented.
The operations utilise the in-memory disjointed set as follows:
- SortedSetAdd - the values are added to the in-memory set in a "non-continuous" manner - ie. we cannot know whether or not they are related in terms of score.
- SortedSetRemove - the value is removed from both memory and Redis.
- SortedSetRemoveRangeByRank - the entire in-memory set is invalidated.
- SortedSetCombineAndStore, SortedSetLength, SortedSetLengthByValue, SortedSetRangeByRank, SortedSetRangeByValue, SortedSetRank - the request is passed directly to redis.
- SortedSetRangeByRankWithScores, SortedSetScan - data is requested from Redis, and then cached in a "non-continuous" manner.
- SortedSetRangeByScoreWithScores - this is the most 'cachable' function since scores are returned in order. The cache is checked and if it can service the request, it's returned. Otherwise a redis request is sent, and the scores are then cached as a continuous set of data in memory.
- SortedSetRangeByScore - data is retrieved from the cache if possible, otherwise retrieved from Redis. If it's retrieved from redis, it is not cached since scores aren't returned.
- SortedSetIncrement, SortedSetDecrement - In memory data is updated and the request is forwarded to Redis.
- SortedSetScore - the value is retrieved from memory if possible, otherwise a Redis request is sent.
The complexity of the Sorted Set is twofold - the inherent difficulty of building an in-memory representation of known subsets of a sorted set (ie. building a discontinuous set), and the number of various Redis operations available that need to be implemented. The complexity is limited somewhat by only implementing meaningful caching for requests involving Score. However, heavy unit testing of everything is definitely required!
List
The list type can't be cached easily in memory. This is because operations generally involve either the 'head' or the 'tail' of the list, which seems like it's simple, until we consider that we have no way of knowing for sure whether or not the in-memory list contains the same head or tail as that in Redis. This could possibly be overcome by handling keyspace notifications, but is not implemented at this time.
Handling updates from other clients
Up until now we've assumed that there's one client connected to the Redis database, but of course multiple clients may be connected. In this situation we've got the potential for one client to have data cached in-memory, and another client to update that data - leaving client 1 in an invalid state. There's only one way to handle this - and that's for all clients to communicate. And conveniently, Redis provides a communication mechanism in the form of its pub/sub notifications. These are used in this project in two ways:
Keyspace notifications
These are notifications which are published automatically in Redis when a key changes
Custom published notifications
These are notifications published by the notifications layer implemented as part of the client caching mechanism. The purpose of these is to augment the Redis keyspace notifications such that extra information is included - enough information to be able to invalidate small, specific parts of the cache.
The use of multiple clients is the main source of 'issues' with caching. See 'Risks'.
Risks/Issues
No guaranteed delivery of keyspace notifications
A problem with Redis notifications is that there is no guaranteed delivery. That means that there is a risk of a notification being lost, and the cache being left with invalid data. This is the main risk of this project. Luckily, it's not a regular occurrence; but it's definitely a risk that needs to be managed when using more than one client.
Solution: use a guaranteed message delivery mechanism between clients. Obviously this is not currently implemented. See the alternative solution…
Alternative solution: Only cache in-memory for a short time, let's say 1 hour. This way, all data accessed repeatedly within an hour is accelerated, and if any notifications are missed, then data is only stale for a limited time. Call Dispose on the database and re-instantiate it to clear it.
Use for one client, use for all
When one client is using this caching layer, all clients must use it so that they can keep each other notified of changes to the data.
No limit to in-memory data
At the moment, everything possible is cached and it would be possible to run out of memory! In my use case, this isn't a risk. But that may not be the case for everyone.
Summary
As they say, there are only 10 hard problems in computer science - cache invalidation, naming things, and binary... However, I believe that this project could be useful in a number of situations. It's true that many people are attempting to cache their data in-memory before hitting Redis, so I am certain that this can be of use elsewhere. Please visit the GitHub page to browse the code - and maybe contribute!

