What is Naïve Bayes
Trying not to be redundant with Wikipedia and simply put, Naive Bayes is a popular AI model for making predictions using classed datasets. A common use is for document classification. In other words, does this document fit into the criteria I'm looking for? This is done by comparing a predetermined set of words that fit some criteria to a set that does not. Each word is weighed using probability rules for the comparison.
Tools for This Paper
Borrowing some data from one of my text books consisting of collections of tweets from the twitter application, I shall attempt to explain this by using R as my programming language. Why R? I suppose I could use C++, C#, or Python. Python has similar syntax to R and can be compiled to executable objects, but R is easier to read in my opinion. So, it makes the explanation easier to see when one views the code I’ve written. Most importantly…
- R avoids the often confusing syntax and algorithms found in more complex languages.
- It allows one to quickly arrange data easily recognizable into frames or tables.
- Comparing data between several tables is easily done without much clutter.
Now many languages, including R, have a Naïve Bayes libraries and function calls. One or two lines of code will do the trick. When applying my skills as a professional service, I would use the libraries without hesitation. But for this paper, what fun would be in that? I want to actually create my own crude version of Naïve Bayes to demonstrate how easy it is to understand.
The borrowed data was easier to work with than to find my own and I was very careful to use my own algorithms instead of what the text book offered for several good reasons. The book I am referring to is one of the finest for explaining several computer science models and I intend to write more concerning some of the others.
The data is based on the assumption that out of 100s of tweets that contain the same search criteria, only some of them are important to the researcher. So there must be a pre-selected collection of tweets that matches the intended and a collection that does not. These would serve as the training model for Naïve Bayes. The more that we can put into these collections, the better, and is recommended that a new result from the Naïve Bayes would put into these collections each time a search is made.
Once the training model is in place, the new search result should be compared – word by word for each tweet – with both the matched and unmatched collections. The words are weighed by probability percentages and summed for each tweet. Afterwards, we simply compare which has the greater probability for the tweet to be in the matched set or not. Voila!
Explaining Naïve Bayes with R
The R script in full with data examples are presented for download with thisi paper. So now, let’s explore some of the snippets in the script.
As mentioned previously, there are just a few steps to implement Naïve Bayes to determine if a new search of tweets match what I’m looking for. Here it is in:
#########################################################################
# MAIN
#########################################################################
# TRAIN THE MODEL- CALCULATE FOR isClass and notClass INSTANCES
isClass = getTableWithCount( getDoc("./data/is_class.txt") )
notClass = getTableWithCount( getDoc("./data/not_class.txt") )
# PREPARE Test DOC
fdata = getDoc("./data/testdata.txt")
IsProbability = getTestTable( fdata, isClass )
NotProbability = getTestTable(fdata, notClass)
# CREATE table with final analysis
FinalAnalysis = getAnalysis(IsProbability, NotProbability)
Figure 1 - Basic Rule
First, we load the train data into two tables. isClass is a collection of desired tweets, notClass is… not… of course. Next, we must prepare two sets of tables that weigh the probabilities of the test data being in one class or the other. Finally, a report is generated in FinalAnalysis that compares the two weighed tables returning TRUE if the tweets in the isProbability table are greater than same tweets applied to the NotProbability table.
It’s easy enough. But now let’s get into each of the calls of Figure 1. The first two lines load a text file into a table then use that table to create the isClass and notClass tables. (The text files are offered at the end of this paper).
getDoc is illustrated in Figure 2. Here, we see that we are simply reading a collection of records with tilde separated delimiters. We lower case all the data to make word recognition easier and remove punctuation and extraneous spaces. The result is just a list of tweets taken from each of the files.
getDoc <- function(filename) {
fdata = read.csv(filename, sep = "~", fill=FALSE) # load doc of words
fdata = sapply(fdata,tolower) # lowercase all words
fdata = gsub("'s","",fdata) # remove 's
fdata = gsub(": ", " ", fdata)
fdata = gsub("?","", fdata)
fdata = gsub("!","", fdata)
fdata = gsub(";","", fdata)
fdata = gsub(",", "", fdata)
fdata = gsub("\\. ", " ", fdata)
fdata = trimws(fdata)
fdata = gsub(" ", " ", fdata) # double space to single
fdata = gsub(" ", " ", fdata) # double space to single again
fdata = gsub(" ", " ", fdata) # double space to single once more
return (fdata)
}
Figure 2 - Getting useful words
getTableWithCount is illustrated in Figure 3. Here, we create a table that splits out all the words in the tweets, storing their unique values along with the number of words found in the whole collection. The count is not enough because we may have to include rare words in the calculation later which will get a value of 1. At this point, it is best to add a column called smoothing which is the count + 1 for each word. The probability column will be the smoothing count divided by the sum of all smoothing counts for this table arriving at the decimal version of the percentage that a word is weighed by the overall number of words. Since the number of decimal places can get rather long with huge numbers of words, we can use the natural log for our future calculations rather than the percentage. This is added to the table.
All of this data in the tables are not truly necessary for calculating a Naïve Bayes. But it is left in to make this exercise a bit more understandable. Figure 4 shows a little of the result.
# get count of each word in doc
getTableWithCount <- function(fdata) {
library(plyr)
wlist = unlist(strsplit(fdata, " ")) # a list of each word
wlist = sort(wlist)
# filter out words that have a length less than 4
df = data.frame(wlist)
df = ddply(df, .(wlist), nrow)
colnames(df) = c("words", "count")
# apply additive smoothing to df
v = df$count + 1
df["smoothing"] = v
# calculate the probability of each word (word-count/total-words)
v = df$smoothing / sum(df$smoothing)
df["probability"] = v
# calculate the natural log of each proability
v = log(df$probability)
df["log"] = v
return(df)
}
Figure 3 - getTableWithCount
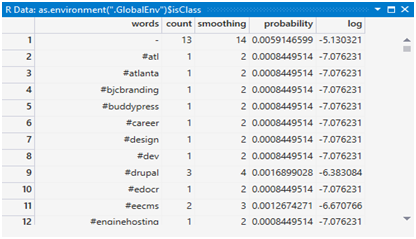
Figure 4
getTestTable is illustrated in Figure 5. After loading the “testdata.txt” file, we can now proceed to creating a table that sums the percentage weights for each word in each of the test data’s tweets. As mentioned, this is done for weights against both tables for what is probable for – isClass – and what is not – notClass.
In Figure 5, we create an empty table consisting of probabilities and tweets called rdata. It will be populated with the sum of probabilities for all the words of each tweet and, of course, the tweet itself. I made this part a little more complicated than it needed to be in order to illustrate what goes on to arrive at the sum of probabilities.
Also, rare words are included at this point. Since all the smooth counts of the words in the isClass and notClass tables can be no less than two, if a word does not show in the table, it is given a smooth value of 1. Hence, a rare word probability may be 1 divided by the total count of words ( 1 / sum(smooth) ) in the respective Class tables. Figure 6 is a clip of what might be seen in the rdata.
#table created from lookups of each word in probability table
getTestTable <- function(fdata, tclass) {
library(plyr)
library(data.table)
rdata = data.frame(
"probability" = numeric(), "tweet" = character(), stringsAsFactors = FALSE)
df = data.frame(fdata)
df = data.frame(lapply(df, as.character), stringsAsFactors = FALSE)
deflog = log(1 / sum(tclass$count))
wlist = strsplit(df$Tweet, " ") # a list of each word
for (gidx in 1:length(wlist)) {
wgrp = wlist[[gidx]]
probability = 0.0
tweet = df[gidx, 2]
for (widx in 1:length(wgrp)) {
if (nchar(wlist[[gidx]][widx]) > 3) {
inclass = tclass[tclass$words == wlist[[gidx]][widx], 1:length(tclass)]
if (nrow(inclass) > 0) {
probability = probability + inclass$log
}
else { # use smoothing
probability = probability + deflog
}
}
}
newrow = data.frame(probability, tweet)
rdata = rbind(rdata, newrow)
}
return(rdata)
}
Figure 5 - getTestTable

Figure 6
At Last We Come to the Report
getFinalAnalysis, in Figure 7, simply creates a table consisting of all the test data tweets along with a logical TRUE or FALSE that tells us whether or not the tweet matches the criteria sought. The formula is quite simple. If each row of the weighted probability of the isProbability table is greater than that of the notProbability table, then the answer is TRUE. A quick look at Figure 8 tells us all we need to know about our test data.
getAnalysis <- function(isProbability, notProbability) {
df = data.frame("Is it in class" =
(isProbability$probability > notProbability$probability),
"tweet" = isProbability$tweet
)
return(df)
}
Figure 7 - getAnalysis
Figure 8
Feel free to copy the information accompanying this article and try it for yourself.

