Introduction and Background
You may have seen many security systems that allow you to just see in the camera to authenticate yourself (or as called in some areas, authorize) to enter the building or to perform any action in the environment. Such biometric methods require hardware and software that is capable of understanding how the data is being input and how the output must be given based on the algorithms and logics being used deep inside. Now I want to simplify things really very much in order to help you to get started with programming software frameworks of your own that would allow your connected devices to be able to actually perform facial recognition across the network. The purpose of this post is to clarify the understanding of facial recognition as well as trying to guide you to understand how to build these programming frameworks and host them that can be used to deliver the same feature across your devices. Now you can of course build the system on one of your hardware device or one of the mobile phone but what if you have to connected multiple devices and perform the same actions on all of those devices? In such cases, adding a simple program to each one of them an then maintaining them won't be a good idea. That is why, in this guide I will show you how to build a server too. The server would be able to handle the requests, process the data being sent and generate the responses.
You are not required to have any intermediate level background in any of these concepts and fields of programming as I will be covering most of them in my post thinking you are beginner to them. However, you are required to have the basic C# programming understanding and how ASP.NET web development framework works. I will be using a web server based on ASP.NET to support my API-based facial recognition system. As we continue through in the sections, you will be able to get a firm grasp of the idea that is being presented here.
Note: All of the images below (unless of shorter size) are higher than 640 pixels in resolution. You can open the images in a new tab to view them in their full resolution.
List of Content
- Introduction and Background
- Things to know before we get started
- Starting with Facial Recognition
- Computer vision—the parent field
- Explanation of the idea
- Algorithms to use for facial recognition
- How recognition works?
- Developing the server-side of the project
- Why use a server at all?
- ASP.NET web application development
- Developing the helper library of face detection and recognition
- Writing the source code for library
- Writing the source code for web application
- Writing the
LoginKeysAuthenticationController
- ASP.NET's Startup.Auth.cs
- Writing the
FacialAuthenticationController—API Controller
- Hosting the application
- Building a sample HTTP client
- Adding the source code for the application
- Building the
HomePage
- Building the
LoginPage
- Using the application—Demonstration
- Final words
- Words on performance
- Words on security
- References
Things to know before we get started
There are a few things that I'd like to share to get your mind ready that you are going to learn in this post here today. In this post we are going to learn a combination of frameworks, concepts and the services that we are going to create and provide for our users (or in many cases, the customers). These multiple platforms are going to be merged into a single service which will then be consumed by multiple clients independent of their hardware, software, operating system or any other layer. This way we will be able to generate the results for the devices that are connected despite the fact as how they are developed, built, and how they work.
So, the topics that we will be covering here are:
- Facial recognition programs.
- Hub or a server for the connected devices to communicate through.
- Implementing the protocols and generating the APIs and interfaces for the devices to connect at.
- Hosting the API on an actual device (mine would be a server, yours can be another connected device running Windows 10 IoT or something)
- Consuming the API through the devices.
However, the only thing that I want you guys to know and be able to use is the HTTP protocol. Although this protocol is going to be heavily used in the article throughout the stages and sections, I will want you to have it understood at your own side as I won't be explaining it here. See in the references portion to find a few helpful URLs to get started on HTTP protocol.
Starting with Facial Recognition
Our main focus in this article guide will be on the facial recognition, algorithms that are used in facial recognition and how you can do that so in this section my major concern will be to give you as much broader, briefer and easier ideas to get a firm grasp on the entire facial recognition concept. So let's get started with the very basics of how it all began...
Computer vision—the parent field
Facial recognition is a sub-field of the computer vision field. Basic algorithms and the theoretical stuff goes around in the computer vision field of computer science. What this field is,
Afzaal Ahmad Zeeshan's definition of computer vision:
Computer vision is the field of computer science, in which the aim is to allow computer systems to be able to manipulate the surroundings using image processing techniques to find objects, track their properties and to recognize the objects using multiple patterns and algorithms.
I had missed (intentionally) most of the aspects that are covered in a technical definition of this concept and I did that because that was just going to confuse you guys at all. If you really want to know what computer vision is, have a look at one of the defintions provided in a course book, Wikipedia article or any other research paper. Of course the concept is a lot broader but that is not what we are going to talk about. Instead, what we are interested in is the methods for recognizing the objects. Computer vision works (or tends to work) just like human vision. Help from biologists have been taken in order to allow computers to see and percieve the objects around them in a way that humans do. However, computers are not perfect. Computer vision, thus, uses experts from over multiple fields to come and join to make the computers work in a much better and efficient way.

Figure 1: Computer vision and artificial intelligence cloud mashup with bunch of other technologies and fields of study.
Computer vision has enormous amount of benefits and regular uses in many fields ranging from smart houses, all the way to complex security programs that control who is walking around and who should be recognized as someone who is required (for any purpose!) by the personnel using the programs.
Now, since we are talking about computer vision, and the programs are capable of detecting the objects, we need to consider how are we going to "recognize the detected objects". Just the way in human vision, our eye is responsible of viewing the scene and our brain then detects human faces in the scene and then later it tries to recognize the ones that it knows. Similarly, facial recognition uses the algorithms to:
- Detect the human faces in the image frame (image frame can come from multiple sources, web cam, image file, network or any other resource)
- This step requires the image frame to be loaded in the memory.
- Special algorithms then read the image and study the pattern of the objects.
- If the pattern ressembles with one known pattern, such as a pattern of face, then it saves that location of the image as detected,
- Forehead space
- Two eyes at top
- Nose at the center of the shape
- Lips
- Chin
- Recognize the data as known (or unknown)
- We perform the same actions in this process.
- But once we have detected an object, we try to get the data from the image about the object only.
- We need a database to store the objects that we "know" of. Computer programs use that database of objects to train the model set for later use.
- Upon request, computer program would then continue to match the detected object with the ones in the database.
- If match is found, object is "recognized". Otherwise, it is stated to be unknown and further steps can be taken to either remember the object or leave it.
These two things are going to be learnt, implemented and played around with! Do not worry, I am sure these concepts and things seem to be a bit confusing at the moment, but as we continue in the article post, I will explain these concepts even in a simpler and deeper way, so that you can understand these steps taken in order to perform what was mentioned in the subject of this post.
Explanation of the idea
The idea of this post was to enable the devices to be able to know who is using them. The uses of this feature can be enormous, ranging from tracking the people in the home, knowing who is where and other similar uses in the house hold environment. This can also be applied to the security purposes, to track when someone enters a building and when someone is leaving the building. However, the purpose that we are going to explain in this post is somewhat simple and fun-to-learn.
What we want to build in this article is somethng really very simple, yet powerful enough to provide support and features to your connected devices to be able to know who is using them. What we need to do in this is, that we need to:
- Create a service that recognizes the faces
- This service would use OpenCV's .NET wrapper Emgu CV as the base framework for computer vision specific functionality.
- The service would be created to use the bytes of data that are being sent to it, service will then perform the actions of building up the matrices and then performing the detection and recognition algorithms on the data.
- OpenCV and other similar frameworks have provided the data templates and models that are used to detect and recognize the objects. We will be using them in our programs to make the programming simpler and easier.
- Host the service in the web application
- I wanted to do this because instead of adding the functionality and managing it on each and every device won't be a good idea. Instead of that, using a web service would have been the best possible solution to provide the same set of functionality to the devices.
- The web application would be live on the network, throughout the day and devices can connect to it.
- Host the web application on a live server
- Now, the thing is, we are going to use a web server to allow the devices on the network to connect. Thus, we will be able to allow the devices in our own network to connect to a "local server".
- By local server, I mean we are going to use a local IP address for the server. You can of course create a server that is hosted at a network that can be accessed outside the network too.
- Consume the service
- We can use any device that can communicate over the HTTP protocol.
- Almost every IoT-based device comes with a web interface, that can support the HTTP communication, and thus every device will be able to consume this service. The data trafficing will be based on the native HTTP protocol and the serialization and deserialization will be performed using JSON data schematics for data-interchange.
An illustration of this can be seen in the following image,
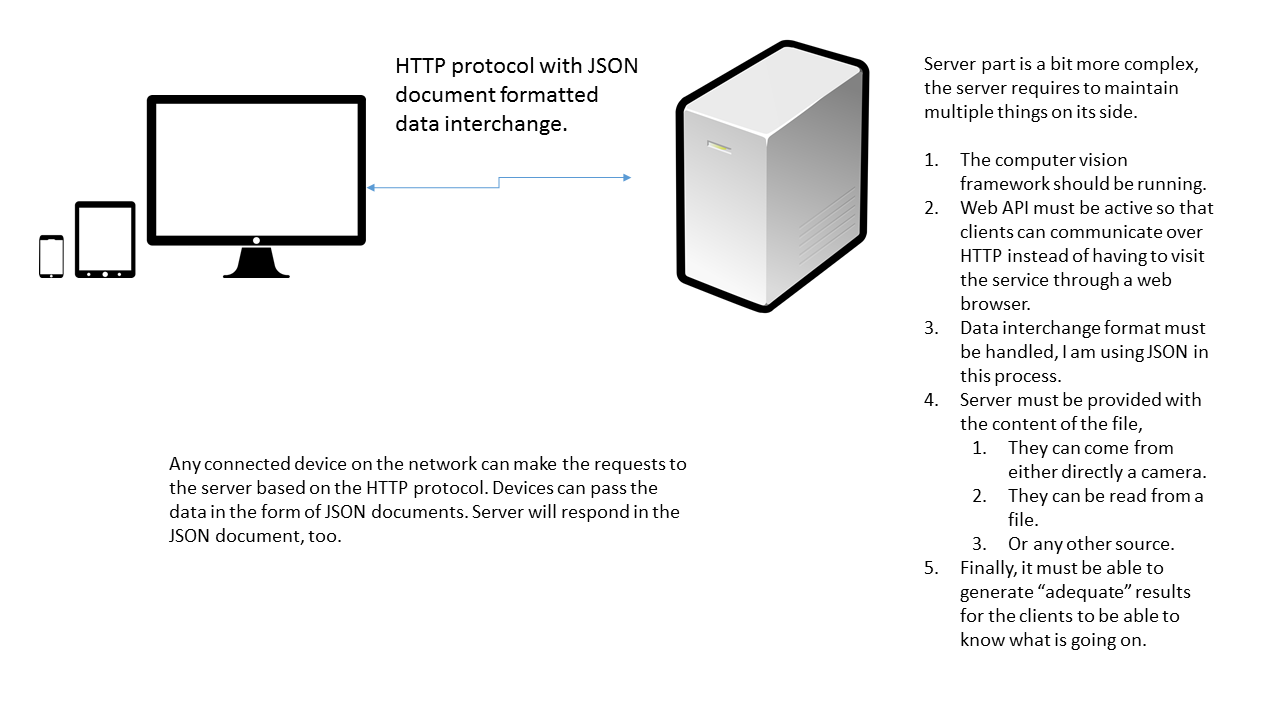
Figure 2: The idea of our project. The big screen monitor isn't required always, it is only required when you want to create the account. But you can do so from your mobile's web browser too.
Most of our time would be consumed on the server side of this article, so let's get started doing the server-side programming and building the service that is going to be consumed by the clients connected to that server through HTTP protocol. But first things first, let's have a look in the algorithms that are to be used in the example. In the next sections (before starting the programming) we will look into a few things and few conceptual theories that are going to help us in the next part of the article.
Algorithm to use for facial recognition
There are many algorithms defined for the sake of facial recognition, for example, EigenFaces, FisherFaces etc. Both of these are really very helpful and very much easy to learn. Most of the online available tutorials already use the EigenFaces algorithms to teach the facial recognition to their readers. In this post I am going to LBPH algorithm, Known as, Local Binary Patterns, this is a powerful algorithm for texture classification and helps in many cases of facial recognition, such as in different conditions of lighting etc. The concept of this algorithm is beyond the scope of this guide, so I would recommend that you pay the OpenCV's tutorial a look, I have found their tutorial very simple to understand and provides a very clear understanding.
Besides, they also highlight the differences of these three algorithms and when you should consider using them. Note that OpenCV contains the definition and engines for all three of the algorithms and you can use any of them. But remember, you cannot alter their usage on the runtime, you should consider which one to use and then design and prepare your models for that particular algorithm. In this post, you will learn how to use LBPH algorithm and how to train the models for that.
How recognition works?
Basically, image processing works on the matrices, the objects detected, and then the patterns in the geometry are checked and matched with the already known patterns; such as faces. The recognition is performed on the images to determine the objects that match a specific shape, geometry or region. Special classifiers are trained to get the results from the images, Haar Cascade is one of such classifiers.
The programs are interested in extracting the properties of the object, such as:
- Width of person's eye-area; or whatever that is called.
- Height of the nose.
- Area of the chin.
- Geometry of the face, such as the width and height of the face.
For example, have a look at the following image and see how the properties of the face can be easily distinguished based on their location and other stuff. Notice that at this spot we are just detecting the face, not recognizing the face. In detection phase, we don't care about how far should the nost be, how big the eyes be etc.

Figure 3: My face, highlighted with the important features of my face as (approximately) seen by the face recognition software.
I masked the face myself, of course the algorithm would detect the face in a much different way and the areas of these properties must be different as in my own case. But you get the idea, how the faces are detected in the images.
Until this point, the detection has been performed, detected was just to detect where a face is, computer program won't know who that person is. So, you are going to store the names of the people alongwith the images. It is a better approach to create a database of people and then record each face alongwith the names of the person whose face that is. The algorithms that we use are equipped with the lines of the codes that are required in order to determine whether the person is existing in the database, or not. That is done by matching the properties of currently detected face by the ones that are already in the database. If the regions match, then the person is "recongnized" as the person from the database and the name is returned for that person. Otherwise, the person is said to be unknown.
The algorithms also detect whether the faces match closely, or whether they have a lot of distances. The distance is also used to determine the threshold that is to be kept in determining the faces. The lower the threshold is kept, the perfect match is made but there are chances that even a little angle is about to cause a great change and difference in the results. However, larger values of the threshold would result in a match, but the error ratio is very high. So you need to look for a model that minimizes the error ratio. A sample of this process can be seen in the following image,

Figure 4: An illustration of how two images are mapped to each other and how their distances are measured based on where facial features are existing in the image.
The faces are of different rotation and thus they have a different geometry in the image. A facial recognition program, if highly sophisticated, will be able to judge who this is, otherwise it won't be able to recognize the person because of the distance of the two faces. Computer relies heavily on the matrices that an image or the object in the image creates, it does not have a perfectly working recognition system as humans have. So, these are a few things that you need to understand first, before diving any deeper into the recognition system.
Tip for developers
As you can see, the face detection depends a lot upon the lighting, the features of face, how clear they are in the image, how clear the image itself is etc. Notice how my mustache can cause problems in accuracy of detecting my lips, notice how the areas of the eyes are different in sizes because of the eye sizes and the eye brows (if algorithm cares about them). It is always a good idea to equalize the histogram, to make sure that the image quality is good, to make sure that noise is removed from the image. These can help improve the accuracy of your programs.
Developing the server-side of the project
In the previous sections you were given the theoretical concepts of the facial recognition softwares and programs and how they work so that you can understand how and what we are going to create. In this section, we are going to actually write the programs that actually perform these actions on the servers in the runtime and generate the outputs for our programs. I am going to use ASP.NET web application, to actually build the servers and run them. But before I actually continue to the hosting section, I want to start with the building process. So let's get started with the programming.
Why use a server at all?
Every IoT device that comes in the market has the features built in, and supports a lot of functionality in itself that you won't have to write a piece of software at all. But what if you were to buy a device that doesn't contain this feature? You can of course write a software for that, but what if you were to buy another product, like a Smart TV, or a Smart Phone, or any other Arduino device etc. In these cases, it won't be efficient to write a software for each of those frameworks, deploy the software and then maintain each and evey piece of software every time they run into a trouble. That won't be a good idea.
In such cases, IoT should use a web service because all it needs and does is it keeps the source code on a central hub and the rest of the devices can connect to that server to consume the resources, share the data and respond to the requests of the users. I am going to use this in this article, and you will see how useful this can be. A few of the benefits of having a server installed over having to write the software for each device are,
- You only have to write the programs and source code once.
- Server is accessible to every device, devices only need to have a web interface to communicate over HTTP protocol.
- Additional devices do not cause a problem, you just install a minimal program to consume the API.
- In case of any error, you just have to debug the code on the server side, which is very easy and takes less time. Once fixed, service can be consumed by any device.
However, there are a few troubles too, in a server-client architecture, such as, if a server is down every client is also down. But this doesn't make much sense when you are available to fix the problem.
ASP.NET web application development
Finally, a bit of coding to get started with. We now need to understand how we want to get started with the design of our application. What we need to build here is that we need to design an authentication system that allows the users to authenticate themselves using their facial geometry. This requires an authentication system designed in such a way that can keep up the facial authentication along with the basic authentication that is performed using the classic ways; username and password. I could have used the ASP.NET's Identity process and for sure that is very simple to use, but instead of that I used my own library that I wrote back 2 years ago, LoginKeys. I would like to warn you, that I am using this library for the sake of simplicity, the library I wrote was not very efficient and had many problems that I am working on fixing and will publish the library soon to the NuGet package where it belongs. Until then, do not use that library. The system is very simple, it has everything that is required by a basic authentication system, yet it includes additional fields to support facial authentication.
public class Account
{
public string Email { get; set; }
public string Password { get; set; }
public DateTime CreateDate { get; set; }
public int UserId { get; set; }
public bool RequireEmailVerification { get; set; }
public string AuthenticationToken { get; set; }
public DateTime TokenExpires { get; set; }
public bool IsVerified { get; set; }
public bool IsLocked { get; set; }
public DateTime AccountLockedSince { get; set; }
public DateTime PasswordResetDate { get; set; }
public string PasswordResetToken { get; set; }
public int TotalPasswordFailure { get; set; }
public string FacesName { get; set; }
public string Name { get; set; }
public string FacialAuthenticationToken { get; set; }
public string SecurityQuestion { get; set; }
public string SecurityAnswerHash { get; set; } }
In the above class, the fields were define in the library itself and I had to add these fields additionally to support my framework with the facial authentication. The class diagram for this, and the service that actually creates the user accounts, assigns them with the user credentials and the tokens etc. is shown in the following image,

Figure 5: Class diagram for the authentication system objects.
The programs until this point are really very simple and straight forward. Besides this, I am using JSON format for data-interchange and for storing the data of the user accounts and other stuff. JSON is of great use in regular day programming as it is really very light weight and makes a lot of sense while being used on the network for its compact size.
Have a look at the above classes, you can see how the procedures are managed and how the stuff goes around together to create an authentication system. You can see, how the tokens from Account class are going to be used in the clients, instead of actually passing the UserIds etc to the clients. This is really very helpful and in many cases it ressembles the way OAuth works. Your applications are provided with tokens, which are used on your behalf to perform an action. Same thing is going to be done here, your tokens are to be used—token can be used anywhere and however you would like it to be used in your application, I won't debate on that. Upto this point, we have just developed the authentication system, notice that we have used an existing working (with a bit performance issues) library and we have ported it with a few of our own requirements so that we can authenticate the users based on their facial geometry. In the next section, we will see how you can actually perform the facial recognition of the users in an ASP.NET web application.
Developing the helper library of face detection and recognition
Before we get started, you need to install the OpenCV's wrapper for .NET framework. EmguCV is a free library for computer vision, infact it is primarily just a wrapper around the open source computer vision library, OpenCV. You can get the library free of cost and install it before you can actually start writing any code, implementing any of their interfaces and APIs in your own code samples of applications. So, go here and download and install the Emgu CV, they will guide you throughout the process and then you can come back here and continue.
Now that you have installed the wrapper for OpenCV, you can continue working on the programming aspect of the programs and services that actually do the task of detection and reconition of the objects (in our case which are faces). I will assume that you have created a new project to work on. If you haven't created a new project with ASP.NET web application template, please follow the directions.
In Visual Studio, select,
- File
- New → Project
- Select "ASP.NET Web Application" from the provided templates.
- Enter the details for the project, such as name for the project, directory etc.
- Click finsih to create the project.
Once this is done, you and I are on the same page and now we can continue to add the libraries and packages that we are going to use in this project of ours.
Adding required components to the project
Since we are using a third-party library, we need to be able to add the libraries to the project's executable's directory. Most of the components of this framework execute in a native environment and that is where the major issue comes in, however, there are managed wrappers provided which you can use for your purpose. First of all, let us include the managed wrappers in the project.

Figure 6: Directory where the libraries are existing.
You need to include these two managed libraries to your project. They will be included easily, because their structure is that of a .NET library, whereas the other library that we are going to include is a native library and not a managed one.
If you run the projects as they are, Emgu CV would complain about TypeInitializerException. That is because the library knows that the type exists, but doesn't know how to actually intialize the object. That is exactly what OpenCV is doing in the background of the wrapper library. So, you also need to reference the OpenCV library in order to actually perform the actions because Emgu CV actually transfers the stuff to the OpenCV library.
There are two versions of OpenCV wrappers that depend on the architecture you are using. I am going to include the x86 arch based wrapper. Which is,

Figure 7: cvextern.dll is required to be available in the bin folder of your application project.
Notice how I said that they cannot be included as managed libraries to your project.

Figure 8: An error message shows up, when you try to add the required library to the project; because it is not a managed library.
To actually include this to your project, what you should do is copy and paste this into the "bin" folder of your application. That is a quick hack, and it would allow you to actually use the library on the runtime as the error comes up at the runtime; not at the compile time. You should pay attention to which version of library to include, their names are similar but the directory they are located under is different.

Figure 9: Pasting the library works. This image shows that the library is copied to the bin folder.
After this, your library would be setup and you can start programming the components and making a use the features available.
Tip: It would be best to check if the framework itself is working efficienty and perfectly without any errors or not. To do so, you should actually start and try out the applications provided by the Emgu CV library itself. They are available unders the directory, "C:\Emgu\emgucv-windesktop 3.1.0.2282\bin" (if you haven't changed the location of the install directory yourself). Select any one of them and run them. This would let you know if the framework has been installed successfuly.
Writing the source code for library
Now, we would continue writing the library itself. For that, first of all, create a new class that we are going to use as our library class for executing the functions. I call it, FacialAuthenticationHelper. I will be writing the code in this class to actually perform the functions, this would provide us with a very simple way of calling the functions, and later editing the functions once we want to modify the code for later use.
1. Face detection part
First lets have a look at what is done in the detection part,
#region Face detection
public static void Detect(Mat image, List<Rectangle> faces, out long detectionTime)
{
Stopwatch watch;
using (CascadeClassifier face = new CascadeClassifier(FacesHaarCascadeFile))
{
watch = Stopwatch.StartNew();
using (UMat ugray = new UMat())
{
CvInvoke.CvtColor(image, ugray, Emgu.CV.CvEnum.ColorConversion.Bgr2Gray);
CvInvoke.EqualizeHist(ugray, ugray);
Rectangle[] facesDetected = face.DetectMultiScale(
ugray,
1.1,
10,
new Size(20, 20));
faces.AddRange(facesDetected);
}
watch.Stop();
}
detectionTime = watch.ElapsedMilliseconds;
}
#endregion
This code, if you can see would perform the face detection in the image (Mat type) and then store their locations in the faces (List<Rectangle> type) variable that would be returned. Now, first of all, have a look at the initial using block, the block initializes a new classifier that uses the Haar Cascade classifier to actually detect the faces. Emgu CV comes shipped with many classifiers that can help in detecting objects of many shapes.

Figure 10: Multiple Haar cascade classifiers provided in the API itself.
We are only interested in the haarcascarde_frontalface_default.xml file. That allows us to detect the faces in our images and then later on perform the actions that we want. In the actual examples, you will see how these programs allow us to detect the faces and store the only face content from the image.
Just for the example demonstration, it looks something like this (example in Windows Forms),

Figure 11: An example of face detection and extraction from the image, shown in a Windows Forms application.
Notice that the face in the upper right corner is just the face which is detected in the image being captured. This is the image that we are later going to use in the recognition process. So let's continue to the next step, and write the code for the recognition process.
2. Face recognition part
This part is also very simple, short hand, but requires a bunch of model generation, a bit of complex functionality such as predictions and checking up with the thresholds. The difference is that, in the detection process you only have to detect if there is an object in the image, whereas in this process you have to state whether the object is the object that you are looking for! In such case, you have to care about the details of the image object, such as eyes, lips, nose dimensions etc. Luckily, we have got the engines, we just have to train the models, we just have to perform the actions that are required and not worry about the low-level details of the process.
#region Face recognition
private static FaceRecognizer recognizer { get; set; }
public static FaceRecognizerType type { get; set; }
public static void UseEigen()
{
recognizer = new EigenFaceRecognizer();
type = FaceRecognizerType.EigenFaces;
}
public static void UseEigen(int numComponents, double threshold)
{
recognizer = new EigenFaceRecognizer(numComponents, threshold);
type = FaceRecognizerType.EigenFaces;
}
public static void UseFisher(int numComponents, double threshold)
{
recognizer = new FisherFaceRecognizer(numComponents, threshold);
type = FaceRecognizerType.FisherFaces;
}
public static void UseLBPH(int radius, int neighbors, int grid_x, int grid_y, double threshold)
{
recognizer = new LBPHFaceRecognizer(radius, neighbors, grid_x, grid_y, threshold);
type = FaceRecognizerType.EigenFaces;
}
public static void Load()
{
recognizer.Load(TrainedEngineFile);
}
public static void Train(List<Image<Gray, byte>> images, List<int> labels)
{
recognizer.Train(images.ToArray(), labels.ToArray());
}
public static int Recognize(Image<Gray, byte> image)
{
int label = -1;
var result = recognizer.Predict(image);
label = result.Label;
return label;
}
#endregion
This is the code that would perform the recognition, notice that I have added the other two methods too, but I won't be using those algorithms. The functions that I want to think about are,
- Load
- Load function actually loads the already trained model from a file. It prepares the engine for recognition using that trained model.
- Train
- This function trains the engine using a model. It trains the recognition engine based on the algorithm being used. The internal implementation has been abstracted, but you can see the differences as you actually perform them.
- Note that we are going to use LBPH algorithm, so we need to use at least 2 different people in order to allow LBPH algorithm to work. Otherwise, it will generate error similar to, "LBPH expects 2 classes". Where classes are two people.
- Recognize
- This function performs the prediction of the face, it predicts the face with a label. The label can then be used to find out the person from the database. We already have a system where our UserIds and the names of the people are saved. We now only require to have the system save the images in a directory, collectively. You will learn that soon.
These functions would perform the recognition. We can then manage the threshold to which we want the engine to relax while predicting the person name.
3. Misc.
Just as helper class needs, the following properties and enumeration lists are also added.
#region Files and other settings
public static string FacesHaarCascadeFile = HttpContext.Current.Server.MapPath("~/App_Data/haarcascade_frontalface_default.xml");
public static string TrainedEngineFile = HttpContext.Current.Server.MapPath("~/LoginKeys_Data/recognitionEngineTrainedData.yml");
#endregion
#region Enum
public enum FaceRecognizerType
{
EigenFaces, FisherFaces, LBPH
}
#endregion
Until this point, we have successfully created the library side of the project. In the next section we will continue to add the source code that consumes the library and how to write the API in ASP.NET web application.
Writing the source code for web application
Although the project is built for the sake of IoT connected devices across the internet but for simplicity I created the module for addition of pictures and account creation to be an online process. It uses simple HTML documents and a bit of programming to create the accounts, to actually store their data. What we want to do is:
- While the account is being created, also create a new directory to store the face bitmaps of that person in that directory.
- This way, we will be able to distinguish the images of people around the system .
- We also want that their tokens and other recognition-oriented properties and fields to be auto-generated. Most of the parts are generated using
Guid.NewGuid() function that gives a unique string. We can later create extra strings as tokens for the users.
- Notice that we also want to allow the users to get abstracted from the username and password required to be authenticated. We want them to be able to actually perform the actions, by just authenticating themselves using the facial metrics.
The content would be as below.
Modifications to account creation
The following code would create the accounts for our users, note that we have only filled the required fields for our account. We have left most of the stuff at users' spare to update them later.
Account account = new Account() { Name = name, Email = email, Password = Crypto.SHA256(password) };
account.FacesName = name.ToLower().Replace(" ", "");
account.FacialAuthenticationToken = Guid.NewGuid().ToString().Replace("-", "");
account.UserId = Account.GetID();
accounts.Add(account);
Directory.CreateDirectory(System.Web.HttpContext.Current.Server.MapPath($"~/LoginKeys_Data/FaceBitmaps/{account.FacesName}"));
string accountList = JsonConvert.SerializeObject(accounts);
File.WriteAllText(AccountFile, accountList);
Rest if handled by the LoginKeys library and the JSON library Newtonsoft.Json. I won't be diving into that, you can try it out yourself by downloading the packages. Only this of the content was updated, now the major code is written in the controller that actually perform the account management.
Writing the LoginKeysAuthenticationController
This controller controls, how your accounts are created, where your accounts are created and how the content is updated. In this section we will be learning and looking into a lot of "important" aspects of facial recognition over the network. Such as:
- Showing the account details; tokens, email etc.
- Allowing users to perform the facial detection and face metric storage. You will see how we are going to store the faces using the library that we just created,
FacialAuthenticationHelper.
- Automatically trigger the training of the engine as you upload the faces.
This controller will be only used on the web browser side of the project, whereas in other cases you will be using the API controllers to communicate over the HTTP protocol. You will find that building the previous libraries and controls was the best bid to do, as they are literally going to help us a lot in the further stages.
I will start by showing you the codes of the controller actions and their views. They are very much simple to understand and I am very much sure that you will be able to get the idea quickly. They are just form submissions etc. Nothing rocket science involved here.
1. Register action
The source code to run at the server is something like this,
public ActionResult Register()
{
if (System.Web.HttpContext.Current.Request.HttpMethod == "POST")
{
var requestHandle = System.Web.HttpContext.Current.Request;
var email = requestHandle["email"];
var name = requestHandle["name"];
var password = requestHandle["password"];
if (LoginService.CreateAccount(name, email, password))
{
Response.Redirect("~/?message=account-created");
}
else
{
ViewBag.ErrorMessage = "Error creating the account.";
}
}
return View();
}
The HTML goes like this,
@{
ViewBag.Title = "Register";
}
<h2>Register</h2>
@if(ViewBag.ErrorMessage != null)
{
<h4 style="color: #e06161">Error</h4>
<p>@ViewBag.ErrorMessage</p>
}
<script>
function checkPasswords() {
// Script to handle the Password combination
var password = document.getElementById("password");
var cpassword = document.getElementById("confirmpassword");
var landing = document.getElementById("landing");
// Check their properties
if (password.value != cpassword.value) {
document.getElementById("lblControl").style.color = "#f00";
return; // Just terminate
} else {
document.getElementById("lblControl").style.color = "#0f0";
}
return true;
}
</script>
<p>Use <code>LoginKeys</code> API to create a new account. Enter the details to register.</p>
<p id="landing"></p>
<form method="post">
<label for="name">Name</label>
<input type="text" class="form-control" id="name" name="name" /><br />
<label for="email">Email</label>
<input type="text" class="form-control" id="email" name="email" /><br />
<label for="password">Password</label>
<input type="password" class="form-control" id="password" name="password" /><br />
<label for="confirmpassword" id="lblControl">Confirm Password</label>
<input type="password" class="form-control" onkeyup="checkPasswords()" id="confirmpassword" name="cpassword" /><br />
<input type="submit" class="form-control" onsubmit="checkPasswords()" value="Register" />
</form>
<p>Already have an account? <a href="~/LoginKeysAuthentication/Login">Login in here</a>.</p>
As you can see, there is nothing very much serious going on here. It is just a plain-HTML form, that gets submitted. The major part of the processing is done by the library LoginKeys itself.
2. Login action
The server code is like this,
public ActionResult Login()
{
if (System.Web.HttpContext.Current.Request.HttpMethod == "POST")
{
var requestHandle = System.Web.HttpContext.Current.Request;
var email = requestHandle["email"];
var password = requestHandle["password"];
bool rememberMe = requestHandle["rememberMe"] == "false" ? false : true;
if (LoginService.Login(email, password, rememberMe))
{
Response.Redirect("~/");
}
else
{
ViewBag.ErrorMessage = "Error creating the account.";
}
}
return View();
}
The view's HTML content is like below,
@{
ViewBag.Title = "Login";
}
<h2>Login</h2>
@if (ViewBag.ErrorMessage != null)
{
<h4 style="color: #e06161">Error</h4>
<p>@ViewBag.ErrorMessage</p>
}
<p>Use <code>LoginKeys</code> API to login to your account.</p>
<form method="post">
<label for="email">Email</label>
<input type="text" class="form-control" id="email" name="email" /><br />
<label for="password">Password</label>
<input type="password" class="form-control" id="password" name="password" /><br />
<label for="rememberMe">Remember me</label>
<input type="checkbox" id="rememberMe" name="rememberMe" /><br />
<input type="submit" class="form-control" value="Login" />
</form>
<p>Don't have an account? <a href="~/LoginKeysAuthentication/Register">Register here</a>.</p>
3. Showing the profile
Before I move forward to adding the faces to the user profiles, I would like to show the view that I am using to actually display the profile of the account active at the moment.
@using LoginKeys;
@{
ViewBag.Title = "Profile";
var account = LoginService.GetAllAccounts().Where(x => x.UserId == LoginService.ActiveID()).FirstOrDefault();
}
<h2>Profile</h2>
This would generate and show the profile. As suggested, it shows the name of the folder, it also shows the token that is to be used for authentication by the user.
4. Adding the faces to the system
Finally, the major part of the controller is the function to actually add the faces to the system. This requires the faces to be detected by the service and then saved as bitmaps to the user directory. Works just like database, but I am not a fan of saving images in their byte format in the database itself. Instead, what I recommend is to save the images (and other multimedia files) on the file system and just save their names (if required) in the database.
The code is a bit lengthy, and since I am performing multiple tasks there, such as adding the security questions, uploading the files, or just showing the view (in case of an HTTP GET), the code is required to be a long one.
public ActionResult AddFaces()
{
if (System.Web.HttpContext.Current.Request.HttpMethod == "POST")
{
if (Request.Form["question"] != null)
{
var question = Request.Form["question"];
var answer = Request.Form["answer"];
var accounts = LoginService.GetAllAccounts().Where(x => x.UserId == LoginService.ActiveID()).ToList();
var account = accounts.FirstOrDefault();
account.SecurityQuestion = question;
account.SecurityAnswerHash = Crypto.SHA256(answer);
accounts = LoginService.GetAllAccounts();
accounts.RemoveAt(accounts.IndexOf(account));
accounts.Add(account);
LoginService.SaveAccounts(accounts);
}
var files = Request.Files;
if (files.Count > 0)
{
for (int i = 0; i < files.Count; i++)
{
var file = files[i];
var facesname = LoginService.GetAllAccounts().Where(x => x.UserId == LoginService.ActiveID()).FirstOrDefault().FacesName;
var bitmapName = FacesDbHelper.AddBitmap(facesname, file);
try
{
Bitmap map = (Bitmap)Image.FromFile(bitmapName);
List<Rectangle> faces = new List<Rectangle>();
Image<Bgr, byte> image = new Image<Bgr, byte>(map);
map.Dispose(); map = null;
Mat matrix = image.Mat; long detectionTime = -1;
FacialAuthenticationHelper.Detect(matrix, faces, out detectionTime);
if (faces.Count == 0)
{
ViewBag.ErrorMessage = "No faces found.";
System.IO.File.Delete(bitmapName);
return View();
}
if (faces.Count > 1)
{
ViewBag.ErrorMessage = "Multiple faces were detected.";
System.IO.File.Delete(bitmapName);
return View();
}
var face = faces[0]; var faceImage = image.Copy(face).Convert<Gray, byte>().Resize(100, 100, Emgu.CV.CvEnum.Inter.Cubic);
new Bitmap(faceImage.Bitmap, 100, 100).Save(bitmapName);
ViewBag.Success = "Face added.";
var imageName = bitmapName.Split('\\')[bitmapName.Split('\\').Length - 1];
var imageUrl = $"LoginKeys_Data/FaceBitmaps/{facesname}/{imageName}";
ViewBag.BitmapLink = imageUrl;
}
catch (Exception e)
{
ViewBag.ErrorMessageCV = e.InnerException.Message;
}
}
}
else
{
ViewBag.ErrorMessage = "No files were uploaded.";
}
}
return View();
}
I will talk about the face detection only, as the security section will discuss the question and answer portion later. Until this stage, you can see that the application is going to check for which files are uploaded to the server and whether there are faces in the image. Notice that the condition is checked,
- If there is no face in the image. There is no need to save anything.
- If there are multiple faces, which one belongs to the user?
- If there is a single metric detected as a face, save it to the directory. This would later help us is training the engine with the faces.
We do a bit of clean up in other cases too. This looks like this, and see that the system also shows that there are some extra images uploaded to the system.

Figure 12: Profile page.

Figure 13: Facial authentication page on the web application.
It would use these two images of mine (and other images provided by other users on the network) to train the model. You can see the button "Train" at the bottom, that does the job of triggering the request to train the engine.
public string Train()
{
return _Train();
}
public static string _Train()
{
List<Image<Gray, byte>> images = new List<Image<Gray, byte>>();
List<int> ids = new List<int>();
FacesDbHelper.GetBitmaps("*").ForEach((bitmapFile) =>
{
string facesname = bitmapFile.Split('\\')[bitmapFile.Split('\\').Length - 2];
int id = LoginService.GetAllAccounts().Where(x => x.FacesName == facesname).FirstOrDefault().UserId;
Image<Gray, byte> image = new Image<Gray, byte>(new Bitmap(bitmapFile));
images.Add(image);
ids.Add(id); // Bitmap must use the ID of the person.
});
try
{
FacialAuthenticationHelper.UseLBPH(1, 8, 8, 8, 100);
FacialAuthenticationHelper.Train(images, ids); // It will also load the file.
return "true";
}
catch { return "false"; }
}
We use Ajax request to trigger this,
<script>
$(document).ready(function () {
$('#refresh').click(function () {
event.preventDefault();
$.ajax({
url: '/loginkeysauthentication/train',
success: function (data) {
data = "" + data;
if (data.toLowerCase() == 'true') {
$('#trainResult').text('Engine has been trained with your latest images.');
} else {
$('#trainResult').text('There was problem training the engine.');
}
}
});
});
});
</script>
If there are any errors, this would result in an error otherwise it will let you know that things went great.
This is the server-side programming of the project. Until this step, we have set up the controllers that allow users to create their accounts and sets up the directory for their profiles. The system also maintains many things such as handling the requests from the clients to trigger multiple actions; such as this training action. There are other stuff that needs to be checked, and I added all of that in the ASP.NET web application's startup class.
ASP.NET's Startup.Auth.cs
Since our application is a lot complex and requires stuff to be readily available. We want to ensure that everything is in its place, if it is not then it should be created and placed at that location. I have written the code that perform the checks on the content and creates if the resources are not available. I have then triggered them in this Startup class.
LoginService.Start();
FacesDbHelper.Setup();
LoginKeysAuthenticationController._Train();
public static void Start()
{
Directory.CreateDirectory(HttpContext.Current.Server.MapPath("~/App_Data"));
Directory.CreateDirectory(HttpContext.Current.Server.MapPath("~/App_Data/LoginService"));
if (!File.Exists(AccountFile))
{
File.Create(AccountFile).Close();
File.WriteAllText(AccountFile, "[]");
}
if (!File.Exists(GroupsFile))
{
File.Create(GroupsFile).Close();
File.WriteAllText(GroupsFile, "[]");
}
if (!File.Exists(UserInGroupsFile))
{
File.Create(UserInGroupsFile).Close();
File.WriteAllText(UserInGroupsFile, "[]");
}
var accounts = JsonConvert.DeserializeObject<List<Account>>(File.ReadAllText(AccountFile));
}
public static void Setup()
{
if (!Directory.Exists(directory)) { Directory.CreateDirectory(directory); }
var accounts = LoginService.GetAllAccounts();
foreach (var account in accounts)
{
if (!Directory.Exists(directory + "/" + account.FacesName)) { Directory.CreateDirectory(directory + "/" + account.FacesName); }
}
}
At this moment, our system has been set up and we are now ready to continue to the next stage of creating the API controllers and then consuming the service through out devices.
Writing the FacialAuthenticationController—API Controller
Now that we have got our service up and running, we just need to expose the service to the HTTP API controller interfaces so that our connected devices can consume the service themselves instead of having to use a web browser only.
Web APIs in ASP.NET have been of a great use to the developers, who wanted to support cross-platform, yet, a native experience for their clients who are going to use the service. Although I am going to use the API on a local network because the server that I had set up for this purpose was a local server, but this can surely be used at a higher level, such as in the enterprise web application servers which can be accessed across the globe. ASP.NET does support that, and your services would be consumed on the Internet anywhere, and all of the clients would be using the native UI and UX experience for the clients instead of having to follow the same old HTML, CSS and JavaScript way of programming the clients to the network based applications.
Recognition process
By default, the initial request to be made to the controller is an HTTP POST request, along with the image in it attached to the headers. One thing to note here is that HTML does that by itself and browser performs all of the stuff in itself, however, in the case of APIs, we don't have that much simplicity. The concept here is a bit complex.
The POST request handler is like this,
public string Post()
{
int id = -1;
Bitmap map = null;
string root = HttpContext.Current.Server.MapPath("~/App_Data");
var provider = new MultipartFormDataStreamProvider(root);
Request.Content.ReadAsMultipartAsync(provider);
using (var memStream = new MemoryStream(provider.Contents[0].ReadAsByteArrayAsync().Result))
{
map = new Bitmap(memStream);
}
try
{
List<Rectangle> faces = new List<Rectangle>();
Image<Bgr, byte> image = new Image<Bgr, byte>(map);
map.Dispose(); map = null;
Mat matrix = image.Mat; long detectionTime = -1;
FacialAuthenticationHelper.Detect(matrix, faces, out detectionTime);
if (faces.Count == 0 || faces.Count > 1)
{
return "-2";
}
var face = faces[0]; var faceImage = image.Copy(face).Convert<Gray, byte>().Resize(100, 100,
Emgu.CV.CvEnum.Inter.Cubic);
id = FacialAuthenticationHelper.Recognize(faceImage); }
catch { }
Account account = null;
try
{
account = LoginService.GetAllAccounts().Where(x => x.UserId == id).FirstOrDefault();
}
catch { }
if (account == null) { return "null"; }
var tempAccount = new Account
{
UserId = account.UserId,
Name = account.Name,
SecurityQuestion = account.SecurityQuestion
};
return JsonConvert.SerializeObject(tempAccount);
}
You will be consuming this using a client that would send the requests through HttpClient object (or any other WebClient or other similar objects that can send HTTP based requests for HTTP communication over the network). We will see how that is done, but let's first understand the process that is being done here. The above code gets the image from the request, then, it performs the same function on it to detect the faces and recognizes them. See how the helper is being used here, FacialAuthenticationHelper.Recognize(faceImage); and then the result is provided either as null or an account detail.
We will then later use that detail of the user account to fetch the question and the answers of the account that is being used. That is upto the device itself whether it wants to authenticate the user further or not. I will show this here, but in the next section of security, I will demonstrate why this is required at all.
The following code returns multiple properties as they are required by the client device, this allows the clients to actually request for more data as that is required.
[System.Web.Http.Route("api/facialauthentication/{id}/{property}")]
public string Get(int id, string property)
{
var accounts = LoginService.GetAllAccounts().Where(x => x.UserId == id);
if (accounts == null) { return "null"; }
var account = accounts.FirstOrDefault();
switch (property.ToLower())
{
case "name":
return account.Name;
case "id":
return account.UserId.ToString();
case "question":
return account.SecurityQuestion;
case "answer":
return account.SecurityAnswerHash;
case "token":
return account.FacialAuthenticationToken;
default:
return "UnknownProperty";
}
}
We would initially request the question for the current user, and this would return that based on the ID set. It is also controlled whether the user has a question set or not, if there is a question then the question itself is returned, otherwise, a null string is returned; string containing null.
Finally, to get the authentication token from the server that would be used across the system for authentication, we can use the following action route in the API,
[System.Web.Http.Route("api/facialauthentication/{question}/{id}/{answer}")]
public string Get(string question, int id, string answer)
{
if (Crypto.SHA256(answer) == Get(id, "answer"))
{
return Get(id, "token");
}
return "error";
}
This action would simply return the token of the user (see the above HTTP GET handler) otherwise would return the error. All of this can be implemented in a single page on the client side program. On the client-side, you can perform all of these checks on a single page and the client would be authenticated, and up and running in less than 15 seconds; assuming he can provide the data in time.
Hosting the application
I won't take much pain to explain how you can host the applications, I have already written an article covering the basics of hosting the ASP.NET web applications on your IIS servers. You should consider reading that article of mine which covers the basics of this entire step and also explain how you can actually host your own application. I am doing the same here and as a matter of face, this application is going to be hosted on the same IP address, used in that post. Read more at, A simple guide to setting up home server using IIS and ASP.NET. Now continue to the main part of this article. Until this step, your server side programming has been done and your API is ready to be consumed so lets get started with building the clients that can consume the resources.
Building a sample HTTP client
I would also want to take this time to explain how you can build the HTTP clients in order to actually perform the functions of HTTP communication in your own clients. In .NET clients, the HttpClient code can work in a similar manner and code re-use is possible. In other environments, you just have to search for an object that allows HTTP based communication.
I am using a Windows 10 based application as a client for this application, other applications, devices, frameworks can also be used in this, but for the sake of simplicity I am going to use a UWP application. I am going to create two pages, one would be the home page, where the content is going to be loaded, and another is going to be the login page where users would login, by capturing their images in the camera. This would demonstrate how simple, easy and straight-forward the process is.
First of all, create a new Windows 10 (Univeral application), you can select the blank application as the template being used because we are going to write everything from scratch in the application. Follow the same options and create a new project under the File menu.
Adding the source code for the application
Initially, the MainPage is provided, but we want to change that. What we want to change here is that we want other pages to communicate with this MainPage dynamically, and change the content of the application. The content of the MainPage was updated to the following one to allow the users to navigate across the features of the application.
<SplitView Name="myMenu" DisplayMode="CompactOverlay" IsPaneOpen="False"
CompactPaneLength="50" OpenPaneLength="150">
<SplitView.Pane>
<StackPanel>
<Button x:Name="HamburgerButton" FontFamily="Segoe MDL2 Assets" Content=""
Width="50" Height="50" Background="Transparent" Click="HamburgerButton_Click"/>
<StackPanel Orientation="Horizontal">
<Button x:Name="homeBtn" FontFamily="Segoe MDL2 Assets" Content=""
Width="50" Height="50" Background="Transparent" Click="homeBtn_Click" />
<TextBlock Text="Home" FontSize="18" VerticalAlignment="Center" />
</StackPanel>
<StackPanel Orientation="Horizontal">
<Button x:Name="loginBtn" FontFamily="Segoe MDL2 Assets" Content=""
Width="50" Height="50" Background="Transparent" Click="loginBtn_Click" />
<TextBlock Text="Login" FontSize="18" VerticalAlignment="Center" />
</StackPanel>
</StackPanel>
</SplitView.Pane>
<SplitView.Content>
<Frame Name="mainFrame" />
</SplitView.Content>
</SplitView>
This would allow us to allow the users to navigate in the menus and to actually select different areas of the application. The source code for C# program that executes at its back end is like this,
public sealed partial class MainPage : Page
{
public static string resultFromAPI { get; set; }
public static Frame rootFrame { get; set; }
public MainPage()
{
this.InitializeComponent();
rootFrame = mainFrame;
}
private void HamburgerButton_Click(object sender, RoutedEventArgs e)
{
myMenu.IsPaneOpen = !myMenu.IsPaneOpen;
}
private void loginBtn_Click(object sender, RoutedEventArgs e)
{
mainFrame.Navigate(typeof(LoginPage));
}
private void homeBtn_Click(object sender, RoutedEventArgs e)
{
mainFrame.Navigate(typeof(HomePage));
}
protected override void OnNavigatedTo(NavigationEventArgs e)
{
mainFrame.Navigate(typeof(HomePage));
base.OnNavigatedTo(e);
}
}
1. Building the HomePage
The following sample demonstrates how you can create a home page for the application. Which later can be updated from the code itself.
<StackPanel>
<TextBlock Text="Home Page" FontSize="40" HorizontalAlignment="Center" />
<StackPanel>
<TextBlock Text="This application is a demo application for the facial authentication project that I have created. In this applicatin, I will demonstrate how your applications will be able to consume the ASP.NET's Web API based facial authentication service." TextWrapping="Wrap" />
<TextBlock Text="To get started, just select the login menu from the split view and get started." />
<TextBlock>
<Run FontWeight="Bold">Note</Run>: The service is subject to the API being consumed. If the API is not active, or not available, then the application cannot be used.
</TextBlock>
</StackPanel>
<StackPanel Name="askQuestionPanel" Visibility="Collapsed">
<TextBlock Name="question" />
<TextBox Name="answer" Margin="0, 15" />
<Button HorizontalAlignment="Center" Name="authorizeBtn" Click="authorizeBtn_Click">Authorize</Button>
</StackPanel>
<StackPanel Visibility="Collapsed" Name="loggedInPanel">
<TextBlock Name="loginStatus" />
<TextBlock Name="loginId" />
<TextBlock Name="loginName" />
<TextBlock Name="loginToken" />
</StackPanel>
</StackPanel>
The program that handles the stuff here, is,
public sealed partial class HomePage : Page
{
private static bool authorized { get; set; }
private static string errorMessage { get; set; }
private int Id { get; set; }
private new string Name { get; set; }
private string Question { get; set; }
private static string Token { get; set; }
public HomePage()
{
this.InitializeComponent();
}
protected override void OnNavigatedTo(NavigationEventArgs e)
{
base.OnNavigatedTo(e);
string result = MainPage.resultFromAPI;
if (result == null)
{
return;
}
else if (result == "-2")
{
errorMessage = "Image was not correct.";
}
else if (result == "null")
{
errorMessage = "No face was detected.";
}
else
{
dynamic obj = JsonConvert.DeserializeObject(result);
string _id = obj.UserId;
Id = Convert.ToInt32(_id);
Name = obj.Name;
Question = obj.SecurityQuestion;
Token = "request_question";
}
if (Token == "request_question")
{
askQuestionPanel.Visibility = Visibility.Visible;
question.Text = $"You are required to answer a security question to get authorized as the identified person, What is the answer for "{Question}"?";
}
else
{
if (authorized)
{
loggedInPanel.Visibility = Visibility.Visible;
loginId.Text = Id.ToString();
loginName.Text = Name;
loginStatus.Text = "Logged in using Facial Authorization";
loginToken.Text = Token;
}
}
}
async private void authorizeBtn_Click(object sender, RoutedEventArgs e)
{
using (var client = new HttpClient())
{
client.BaseAddress = new Uri("http://localhost:52138");
var result = await client.GetAsync($"/api/facialauthentication/question/{Id}/{answer.Text}");
var content = JsonConvert.DeserializeObject<string>(await result.Content.ReadAsStringAsync());
if (content == "error")
{
MainPage.resultFromAPI = null;
await new MessageDialog("Incorrect answer provided.").ShowAsync();
}
else
{
Token = content;
MainPage.rootFrame.Navigate(this.GetType());
authorized = true;
}
}
}
}
I will also give you a glimpse of explanation as I continue to actually move forward to use the application for demonstration purposes. Until now, just see this as it is. But as you can see in the code here, I am actually using a bit of structure of security here, to provide the UI to the user for whether he was authenticated, not, or whatever is the result.
2. Building the LoginPage
Second part of this project is to create the login page, where users can actually smile infront of their cameras and get themselves authenticated with a token access that they can use later for their own use in the system. Now, let us see the code for this page,
<StackPanel>
<TextBlock Text="Facial authentication API client" HorizontalAlignment="Center" FontSize="35" />
<StackPanel Orientation="Horizontal">
<TextBlock Text="To get started, press "start"." Margin="0, 5, 0, 0" />
<Button Content="Start" Margin="10, 0, 0, 0" Click="Button_Click"/>
</StackPanel>
<CaptureElement Name="mediaElement" Height="500" Width="700" FlowDirection="RightToLeft" />
<Button Name="authenticate" Click="authenticate_Click" Content="Authenticate" Visibility="Collapsed" />
</StackPanel>
The C# code for this page is like this,
public sealed partial class LoginPage : Page
{
private MediaCapture camera { get; set; }
public LoginPage()
{
this.InitializeComponent();
}
private async void Button_Click(object sender, RoutedEventArgs e)
{
camera = new MediaCapture();
await camera.InitializeAsync();
mediaElement.Source = camera;
await camera.StartPreviewAsync();
authenticate.Visibility = Visibility.Visible;
}
private async void authenticate_Click(object sender, RoutedEventArgs e)
{
using (var client = new HttpClient())
{
client.BaseAddress = new Uri("http://192.168.1.10");
using (var content = new MultipartFormDataContent())
{
ImageEncodingProperties imgFormat = ImageEncodingProperties.CreateJpeg();
StorageFile file = await ApplicationData.Current.LocalFolder.CreateFileAsync(
"CapturedPhoto.jpg",
CreationCollisionOption.GenerateUniqueName);
await camera.CapturePhotoToStorageFileAsync(imgFormat, file);
byte[] bytes = null;
await Task.Run(async () =>
{
bytes = File.ReadAllBytes(file.Path); });
content.Add(
new ByteArrayContent(bytes), "imageFile"
);
await file.DeleteAsync();
string result = null;
try
{
var postResult = await client.PostAsync("/api/facialauthentication", content);
var responseString = postResult.Content.ReadAsStringAsync().Result;
result = JsonConvert.DeserializeObject<string>(responseString);
MainPage.resultFromAPI = result;
}
catch (Exception error)
{
await new MessageDialog(error.Message + "\n\n" + result, "Cannot connect").ShowAsync();
}
MainPage.rootFrame.Navigate(typeof(HomePage));
}
}
}
}
This page actually, clicks an image of the person infront of the camera. The image is then sent over the network to the server where it is processed and the results are generated to either authenticate the user or send an error mesage to the user. I think enough coding has been done, and it is time to move forward to actually use the application.
Using the application—Demonstration
I am finally done with the programming aspect of this guide for you, now let us see how this thing actually works in a real application environment. Obviously, you can skip this section if you want to because this is just the demonstration of what has been shared up in this guide. So, let's see how this works, just to not waste your time I will keep this section topic very short and just the visual presentation of the application itself. Other stuff will be covered in the later sections where I will give you a bit tips about using this in your production applications later.
Note: At this stage you must make sure that the API is active and running, I used 192.168.1.10 to connect to the API, you can (and should!) change the IP address to the location where your service is hosted on, can be a localhost address. Otherwise, application won't show anything and in many cases would terminate unexpectedly.
The initial page of the application looks like this, notice that we have already shown the home page (unauthenticated state of the application).

Figure 14: Home page of the client application.
You can surely change the home page, show some unauthorized content, public news etc. but we wanted to keep things straight-forward and wanted to show most of the stuff only related to our topic here. So, I created a home page, where the application guides the user to move forward to actually use the login page.
We need to provide our image, and we can get the image from the webcam, and on the other page I do exactly the same I access the camera, take the picture and send it to the server for authentication. Here is what server does and how the entire process of facial authentication (or authorization) looks like,

Figure 15: Camera service being consumed in the application to take a sample picture to be uploaded to the server in order to perform facial recognition.
Device's camera will be used for publishing the image to the server, the image bytes would be captured from the file being saved and then they will be sent to server. Device itself doesn't have to know what server is doing and where it is, it has the IP address of the server and would just upload the content there. Server would then respond and would guide the application to dynamically adopt to the standards of the application.

Figure 16: A question is returned to be answered, as a security measure.
Application would ask the user to answer the security question, the security question is a bit of security layer because, you know, there are always people trying to access the content they are not allowed to.

Figure 17: The question is being answered.
Security question's answer is in plain text, you should convert it to password, I wanted to show that the string would move in a plain-Unicode-text form, instead of being hashed here. The server would be hashing for us,
Crypto.SHA256(answer);
This way, we would only have to upload the content without having to worry about the hashing methods being used and other stuff like that.

Figure 18: The image shows what result the HTTP service provides once the correct answer is posted to the server.
This image should be explained in a bulleted list:
- First of the TextBlock here, shows that the user has been authenticated providing his:
- Facial geometry
- Answer to the security question
- Got his facial authentication token and is ready to use the service.
- P.S. Forgive the "Authorization" there, I was confused as to use which one.
- This one has the UserID, just for showing purposes. You don't have to show anything here.
- This is the name of the account.
- This is the token, that can be used to authenticate and authorize the user on behalf of their usernames and passwords. I will talk about the benefits in a coming section.
This way, your accounts can be authenticated using the same resources that you have, adding a bit of Emgu CV library to it to consume the power of computer vision and you're done! In case you wanted to see what happens once the face is not recognized, nothing happens. The code that actually manipulates the UI is like this,
if(authorized)
{
loggedInPanel.Visibility = Visibility.Visible;
loginId.Text = Id.ToString();
loginName.Text = Name;
loginStatus.Text = "Logged in using Facial Authorization";
loginToken.Text = Token;
}
There is no else block here, you can feel free to add one as your requirement. And then, it will show an error message saying that the user is not authenticated, user is unknown or, add a new user? What ever you would like to do with the application would be amazing.
Final words
I hope you have enjoyed building the system for authenticating users using their facial geometry. I have enjoyed learning a lot of computer vision, a lot about core programming of facial authentication and much more. Seriously, if you still think I missed something, let me know and I'd be more than happy to add that to this post. However, time for a bit of my own tips for the readers and a few of the things that I didn't have but should have made this process a bit more simpler, easier and secure all by itself.
Words on performance
This framework require a really fast architecture and system to actually work. Even a small image would result in a huge matrix (although just 2-dimensional) and would thus case the CPU to take some to generate the results. And this is definitely going to have some down time for you because CPU would typically be working on the processing and would have less time to generate the responses for the clients.
There are many ways in which you can upgrade and increase the performance of the service that does everything related to computer vision.
- Change the configuration of the service.
- The functions of the API allow you to pass the values that are used to tune the engine. You can always change their values.
- Some values provide best results on the cost of high computation power (and time).
- Some values provide best performance, fast results but are not as much efficient and perfect.
- Upgrade the hardware being used.
- Sometimes, tuning the API doesn't bring about any updates in the performance factors. In such cases, you would require to upgrade the hardware of your machine that is acting as the server for the clients. In most cases, the hardware is not enough for even keeping up to generating responses for the requests.
- CPU can be powerful enough, but in most cases, especially when you are to perform image processing, GPU can be really helpful. You can add a GPU to your computer and then forward the processing to your GPU.
- Make most of your hardware.
- Most of the hardware drivers can be updated in order to get the best of your device.
- GPU drivers can be updated, if you are using Nvidia's GPU technology, then installing CUDA drivers should be a recommended step to take.
- If your CPUs have multiple cores, then you can use parallelism to make most of your CPU's power and process complex functions in a parallel environment.
- Simple threading can also be used, but that doesn't decrease the time required to process. It simply makes your application or service responsive to the user actions etc.
These actions can be performed in order to get better performance. Note that they are not guaranteed to be working 100% all the times. Sometimes, it better to not use them at all. Such as parallelism, as it may lead to deadlocks if not used properly. It is still a good idea to try them all and see which one works for you. I am using a dual core processor for my home network set up and since users are limited to 4-10, the performance is enough and the average response time is ~4 seconds. I can for sure increase performance to decrease the wait time to ~2 seconds but that doesn't count for a home network, since no clients are waiting for response and thus adding an expensive GPU would be an overkill to get extra 2 second time.
Words on security
Since this is an authentication system, "security must be given a really very high priority". For example, computer won't know if the person's face is actually a person's face or an image photograph being shown to the camera at a range. Who knows? Computer won't be able to tell that from a 2D space. The security aspect of this concept is really very simple, straight-forward, but requires a lot of complex understanding to actually work. In my own opinion, there are following ways in which you can improvide accuracy and security of your authentication system.
- Decrease the threshold that the engine is going to allow the images to have a distance at.
- Typically, an average distance is provided and allowed for a less number of images.
- You should consider increasing the number of images being used and that would increase the accurasy of your engine (~5-10 images). This way, you can decrease the threshold to get more accurate results and notice when someone is unknown.
- The more the threshold, the poorer the result (which can be said to be providing a match, always!).
- Use a camera that can determine the depth of the images, their z-index.
- Consider using the images in their 3D space instead of 2D.
- Images in 3D space had been suggested to have a better accuracy results as compared to a 2D space image. There is a paper also published, that provides an overview; sadly I was not able to read it because of the price tag.
- 3D space camera would be independant of the space geometry, background noise, spatial differences and luminance. 3D images would provide the excellent results for the facial geometry analysis and to perform facial recognition.
- 2D algorithms are based on the spatial information, such as luminance, noise, face properties etc. This is why most of the algorithms differ in many senses and cases. In most of the cases, you should consider using the one that suits your service environment and how your users are going to use. LBPH is a useful algorithm, but Eigen algorithms are simple ones to use. Fisher algorithm on the other hand is as simple as Eigen faces, but is a really very accurate algorithm to use and is competent to LBPH. But remember, it entirely depends on the use of the service.
- Above all, implement a two-way security mechanism.
- Review the article, you will find that although the face has been identified, the token isn't granted. Token should be used to authenticate the users on the API, instead of using their UserIds and passwords.
- You can consider other methods of authenticating the users using the two-way factors. Such as sending a pin code to their mobile devices or any connected device.
- If you do not consider adding a two-way security, your accounts are always open to hackers and the simplest one of them being, showing an image to the camera of someone who, hacker needs to be authorized against.
Someone has also recorded a video about this comparison as to which method has a great accuracy in most cases (for 2D space images), you can see that video here, https://www.youtube.com/watch?v=x8W_htbct3U.
References
As I mentioned above, I will share the references that I think will most likely help you out in your learning process. Following are a few, if you think there are other links out there that can help readers, please let me know and I will include them here.
- Conceptual references
- OpenCV references
- Networking references
- Statistical concept references
Now, this is it for this guide. See you in later posts. 

