I’ve added a Resources and Speaking page to my site, check them out if you want to learn more.
Stack Overflow Tag Engine
I first heard about the Stack Overflow Tag engine of doom when I read about their battle with the .NET Garbage Collector. If you haven’t heard of it before, I recommend reading the previous links and then this interesting case-study on technical debt.
But if you’ve ever visited Stack Overflow, you will have used it, maybe without even realizing. It powers the pages under stackoverflow.com/questions/tagged, for instance you can find the questions tagged .NET, C# or Java and you get a page like this (note the related tags down the right-hand side):
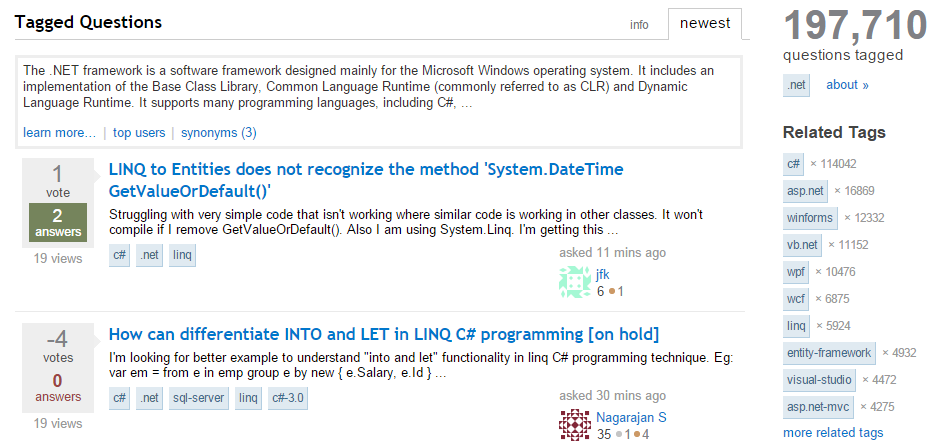
Tag API
As well as simple searches, you can also tailor the results with more complex queries (you may need to be logged into the site for these links to work), so you can search for:
It’s worth noting that all these searches take your personal preferences into account. So if you have asked to have any tags excluded, questions containing these tags are filtered out. You can see your preferences by going to your account page and clicking on Preferences, the Ignored Tags are then listed at the bottom of the page. Apparently, some power-users on the site have 100s of ignored tags, so dealing with these is a non-trivial problem.
Publicly Available Question Data Set
As I said, I wanted to see what was involved in building a version of the Tag Engine. Fortunately, data from all the Stack Exchange sites is available to download. To keep things simple, I just worked with the posts (not their entire history of edits), so I downloaded stackoverflow.com-Posts.7z (warning direct link to 5.7 GB file), which appears to contain data up-to the middle of September 2014. To give an idea of what is in the data set, a typical question looks like the .xml below. For the Tag Engine, we only need the items highlighted in red, because it is only providing an index into the actual questions themselves, so we ignore any content and just look at the meta-data.

Below is the output of the code that runs on start-up and processes the data, you can see there are just over 7.9 millions questions in the data set, taking up just over 2GB of memory, when read into a List<Question>.
Took 00:00:31.623 to DE-serialise 7,990,787 Stack Overflow Questions, used 2136.50 MB
Took 00:01:14.229 (74,229 ms) to group all the tags, used 2799.32 MB
Took 00:00:34.148 (34,148 ms) to create all the "related" tags info, used 362.57 MB
Took 00:01:31.662 (91,662 ms) to sort the 191,025 arrays
After SETUP - Using 4536.21 MB of memory in total
So it takes roughly 31 seconds to de-serialise the data from disk (yay protobuf-net!) and another 3 1/2 minutes to process and sort it. At the end, we are using roughly 4.5GB of memory.
Max LastActivityDate 14/09/2014 03:07:29
Min LastActivityDate 18/08/2008 03:34:29
Max CreationDate 14/09/2014 03:06:45
Min CreationDate 31/07/2008 21:42:52
Max Score 8596 (Id 11227809)
Min Score -147
Max ViewCount 1917888 (Id 184618)
Min ViewCount 1
Max AnswerCount 518 (Id 184618)
Min AnswerCount 0
Yes that’s right, there is actually a Stack Overflow questions with 1.9 million views, not surprisingly it’s locked for editing, but it’s also considered “not constructive”! The same question also has 518 answers, the most of any on the site and if you’re wondering, the question with the highest score has an impressive 8192 votes and is titled Why is processing a sorted array faster than an unsorted array?
Creating an Index
So what does the index actually look like, well it’s basically a series of sorted lists (List<int>) that contain an offset into the main List<Question> that contains all the Question data. Or in a diagram, something like this:
Note: This is very similar to the way that Lucene indexes data.
It turns out that the code to do this isn’t that complex:
tagsByLastActivityDate = new Dictionary<string, int[]>(groupedTags.Count);
var byLastActivityDate = tag.Value.Positions.ToArray();
Array.Sort(byLastActivityDate, comparer.LastActivityDate);
Where the comparer is as simple as the following (note that is sorting the byLastActiviteDate array, using the values in the question array to determine the sort order.
public int LastActivityDate(int x, int y)
{
if (questions[y].LastActivityDate == questions[x].LastActivityDate)
return CompareId(x, y);
return questions[y].LastActivityDate.CompareTo(questions[x].LastActivityDate);
}
So once we’ve created the sorted list on the left and right of the diagram above (Last Edited and Score), we can just traverse them in order to get the indexes of the Questions. For instance, if we walk through the Score array in order (1, 2, .., 7, 8), collecting the Ids as we go, we end up with { 8, 4, 3, 5, 6, 1, 2, 7 }, which are the array indexes for the corresponding Questions. The code to do this is the following, taking account of the pageSize and skip values:
var result = queryInfo[tag]
.Skip(skip)
.Take(pageSize)
.Select(i => questions[i])
.ToList();
Once that’s all done, I ended up with an API that you can query in the browser. Note that the timing is the time taken on the server-side, but it is correct, basic queries against a single tag are lightening quick!
Next Time
Now that the basic index is setup, next time, I’ll be looking at how to handle:
- Complex boolean queries .NET or jquery- and C#
- Power users who have 100’s of excluded tags
and anything else that I come up with in the meantime.
The post The Stack Overflow Tag Engine – Part 1 appeared first on my blog Performance is a Feature!
CodeProject

