Introduction
This article explains, with detailed examples, how to use PIVOTING to take maximum advantage of queries making use of GROUPING SETS. Besides, ROLLUP and CUBE operators will be analysed as well. We'll see thoughout the article that it's very easy to get simple, practical and powerful queries by integrating all of them in the same query.
I think that master these operators contributes to make cleaner code and save a lot of time when developing. Thus, I hope this article will be useful to both improve your knowledge and develop faster cool queries for your reports, forms or views.
Background
Let's suppose we have a table similar to the one showed below. It's a simple table showing the Quantity of Products sold by every Employee for each ShipCountry in a given company and period of time.
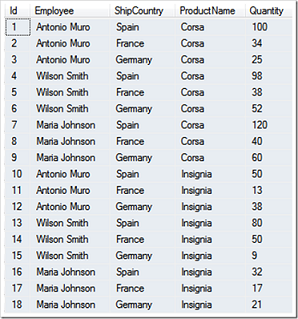
From the previous table, we would like to show a final result set that looks like to the next picture as our first goal. Background colors are only painted for later explanations.

As you can see, original table has been rotating by converting values of ShipCountry field in rows into new columns and also, new calculations have been performed to obtain:
- GREEN Cell:
Sum of Quantity of Products sold by All Employees in All Countries. - YELLOW Cells:
Sum of Quantity of Products sold for each Employee in All Countries. - ORANGE Cells:
Sum of Quantity of Products sold by All Employees for each ShipCountry. - BLUE Cells:
Sum of Quantity of Products sold for each Employee for each ShipCountry.
We'll see how to get these different calculated values by using GROUPING SETS, CUBE or ROLLUP operators over a GROUP BY clause and how to rotate data values in ShipCountry field from the original result set by using PIVOT operator.
Using the code to get our first goal
To begin with, we'll create a table with the proper structure:
create table tbl_Sales(Id int,
Employee nvarchar(50),
ShipCountry nvarchar(50),
ProductName nvarchar(50),
Quantity int
primary key (Id)
)
And we'll populate table with data:
insert into tbl_Sales
values (1,'Antonio Muro','Spain','Corsa',100),
(2,'Antonio Muro','France','Corsa',34),
(3,'Antonio Muro','Germany','Corsa',25),
(4,'Wilson Smith','Spain','Corsa',98),
(5,'Wilson Smith','France','Corsa',38),
(6,'Wilson Smith','Germany','Corsa',52),
(7,'Maria Johnson','Spain','Corsa',120),
(8,'Maria Johnson','France','Corsa',40),
(9,'Maria Johnson','Germany','Corsa',60),
(10,'Antonio Muro','Spain','Insignia',50),
(11,'Antonio Muro','France','Insignia',13),
(12,'Antonio Muro','Germany','Insignia',38),
(13,'Wilson Smith','Spain','Insignia',80),
(14,'Wilson Smith','France','Insignia',50),
(15,'Wilson Smith','Germany','Insignia',9),
(16,'Maria Johnson','Spain','Insignia',32),
(17,'Maria Johnson','France','Insignia',17),
(18,'Maria Johnson','Germany','Insignia',21)
Before going on, I would like to point out briefly some issues about how GROUPING SETS works. You can go deeper on it by searching in this site or Microsoft Documentation. There's a lot of information about and there's no sense explain the same again.
On one hand, GROUPING SETS lets you perform aggregations (sum, avg, etc.) over a list of combinations or sets of different fields. Have a look to the next piece of code:
select Employee,
ShipCountry,
SUM(Quantity) as Quantity
from tbl_Sales
group by GROUPING SETS(
(Employee, Shipcountry),
Employee,
ShipCountry,
())
I'm calculating the Sum of Quantity of Products grouping by four different combinations or sets of fields.
Employee, ShipCountry: Employee and ShipCountry.Employee: Only Employee (All ShipCountries are taken for each employee).ShipCountry: Only ShipCountry (All Employees are taken for each ShipCountry).() : All Fields (All ShipCountries and All Employees are taken)
The result from que query is:
Employee, ShipCountry: Results in BLUE color.Employee: Results in YELLOW color.ShipCountry: Results in ORANGE Color.() : Results in GREEN Color.
It's important to note that GROUPING SETS operator has calculated new aggregations and has added new rows to the result set. That being said, we can see that null values have been returned in rows that contains aggregations. I mean, a null value in ShipCountry column is returned as a equivalent to All Countries and a null value in Employee field is returned as an All Employees value.
At this point, I would like to mention two new point to consider:
- How could I differenciate a
null value returned from an aggregation operation instead of a null from the original query? - I dont'like much to deal with
null values. Could I do something clearer or better?
To respond question one, there's a function called GROUPING that let us obtain exactly what we are looking for. I will use in the next piece of code. In short, this function returns an tinyint value of 1 when null value comes from aggregation and 0 if not.
To answer question two, I like to substitute null values from aggregations with strings such us All Employees or All Countries. We'll achieve this by using the next improved piece of code.
So, here is our query using GROUPING SETS with GROUPING function inside CASE statements:
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
sum(Quantity) as Quantity
from tbl_Sales
group by GROUPING SETS(
(Employee, Shipcountry),
Employee,
ShipCountry,
())
And here is our new obtained result set:
You should note that null values have been replaced with strings All Employees and All Countries. Look at ORANGE, GREEN and YELLOW rows to check this.
So far, we have achieved all the calculations needed to put in our final result set. It will be necessary rotate the table, but we have done at least the half part of our first objective. Any other way of achieving this? Yes. We might have reached it by using CUBE operator instead of GROUPING SETS. Without diving a lot into it, CUBE operator calculates aggregated values for all possible combinations for specified fields in the GROUP BY clause. So, at least, you should know that there are 2n possible combinations, where n is the number of fields included in the GROUP BY clause. In this case n=2 so that there are four different cases or possible combinations. These combinations are exacty the same as used in our previous piece of code.
Anyway, here is the query using CUBE operator:
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
sum(Quantity) as Quantity
from tbl_Sales
group by Employee, Shipcountry with CUBE
As I said before, the result is the same as using the previous code. Here is the identical result:
Let's go on with our first example. Now, we just have to rotate CountryShip values in rows into new columns. How to get this? It's easy. We've only to make use of PIVOT operator. You can read some of my previous articles to go deeper on it (i.e. Using PIVOT with T-SQL)
Here is our final query using GROUPING SETS and PIVOTING our source query making previous use of a common table expression:
;with CTE_OriginalQuery as
(select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
sum(Quantity) as Quantity
from tbl_Sales
group by GROUPING SETS(
(Employee, Shipcountry),
Employee,
ShipCountry,
())
)
select Employee, Spain, France, Germany, [All Countries]
from CTE_OriginalQuery
PIVOT (sum(Quantity) for ShipCountry in
(Spain, France, Germany, [All Countries])) as Pivoted_FinalQuery
At last, by executing our final query we obtain our desired result set.
We've achieved our first goal only by using simple SQL (not cursors, not strange code...) I think that it's worthwhile.
To end up this section, only one more issue. Why not using ROLLUP operator? Is it possible to obtain the same result? If not, why? Let's check it with another example:
Our query using Rollup would be:
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
sum(Quantity) as Quantity
from tbl_Sales
group by Employee, Shipcountry with ROLLUP
And the result of previous query:
Where are the ORANGE rows? They aren't up there. This is because ROLLUP operator doesn't generate aggregations only grouped by CountryShip field. Why? Because ROLLUP just calculates these grouping sets:
Employee, ShipCountry: Results in BLUE color.Employee: Results in YELLOW color (All ShipCountries are taken for each employee).() : Results in GREEN Color (All ShipCountries and All Employees are taken).
As you can check, ROLLUP operator only obtains aggregated values in ascending order in the hierarchy, I mean in the specified order of fields in the GROUP BY clause. Thus, aggregated values grouped by only ShipCountries are not calculated. It doesn't match our initial requirements. Anyway, which kind of final result set we would have obtained with this query using ROLLUP and applying PIVOTING. Let's see the differences with our next piece of code and related picture from results.
Query using ROLLUP and then PIVOTING Source Query Data:
;with CTE_OriginalQuery as (
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
sum(Quantity) as Quantity
from tbl_Sales
group by Employee, Shipcountry with ROLLUP)
select Employee, Spain, France, Germany, [All Countries]
from CTE_OriginalQuery
PIVOT (sum(Quantity) for ShipCountry in (Spain, France, Germany, [All Countries])) as Pivoted_Sales
Results from previous query:
As you can see again, there are no values for All Employees for each single country.
One more advanced example
I think that, at this point, there is enough SQL code for the article, but I would like to finish it showing one more advanced example. What if we wanted to obtain a even more advanced result set like the following? Again, I have given background color to cells only to help to explain the origin for each set of values.
It should be noted that a new column field Product has been added to our final result set. It might seem difficult to obtain this result, but not, it's easy taking into account all previously-explained before. You just have to add some new combinations of GROUPING SETS.
Here is the code with our new GROUPING SETS:
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry
end ShipCountry,
case GROUPING(ProductName)
when 1 then 'All Products'
else ProductName
end ProductName,
sum(Quantity) as Quantity
from tbl_Sales
group by GROUPING SETS(
(Employee, Shipcountry, ProductName),
(Employee, Shipcountry),
(Employee, ProductName),
(ShipCountry,ProductName),
Employee,
ShipCountry,
ProductName,
()
)
Now, we have three fields to group by. Then, according to what we saw before, there are 23 = 8 possible combinations to consider. I have maintained same code colors from first example and added new ones for the new combinations. Here are the new GROUPING SETS:
Employee, ShipCountry, ProductName: Employee, ShipCountry and ProductName. Employee, ShipCountry: Employee and ShipCountry (All Products are taken for each combination)Employee, ProductName: Employee and ProductName (All ShipCountries are taken for each combination)ShipCountry, ProductName: ShipCountry and ProductName (All Employees are taken for each combination)Employee: Only Employee (All ShipCountries and All Products are taken for each employee)ShipCountry: Only ShipCountry (All Employees and All Products are taken for each employee)ProductName: Only ProductName (All ShipCountries and All Employees are taken for each employee)() : All Fields (All ShipCountries, All Employees and all Products are taken)
We have again all the information to obtain our second goal in this article. We just need pivoting the previous result. Here is the code:
;with cte_OriginalQuery as (
select case GROUPING(Employee)
when 1 then 'All Employees'
else Employee
end as Employee,
case GROUPING(ShipCountry)
when 1 then 'All Countries'
else ShipCountry end ShipCountry,
case GROUPING(ProductName)
when 1 then 'All Products'
else ProductName end ProductName,
sum(Quantity) as Quantity
from tbl_Sales
group by GROUPING SETS(
(Employee, Shipcountry, ProductName),
(Employee, Shipcountry),
(Employee, ProductName),
(ShipCountry,ProductName),
Employee,
ShipCountry,
ProductName,
()
)
)
select Employee, ProductName, Spain, France, Germany, [All Countries]
from cte_OriginalQuery
PIVOT (sum(Quantity) for ShipCountry in (
Spain, France, Germany, [All Countries])) as Pivoted_Sales
order by Employee, ProductName
And here are the explained results from PIVOTING our new GROUPING SETS:
Employee, ShipCountry, ProductName:Results in GREY color.Employee, ShipCountry: Results in BLUE color.Employee, ProductName: Results in BROWN color.ShipCountry, ProductName: Results in RED color.Employee: Results in YELLOW color.ShipCountry: Results in ORANGE color.ProductName: Results in PURPLE color.(): Results in GREEN color.
Points of Interest
I'm used to reviewing a lot of pieces of SQL code and very little times I have found use of GROUPING SETS, PIVOT or even other powerful SQL facilities such us WINDOWING functions, etc. Instead, massive use of cursors, temp tables, etc. has been coded. As a consequence, it usually implies worse maintainability and performance. So, I think it's worthwhile make a strong effort to master these options.
History
This is the first version of the article. I hope this is useful for you.

