In this article, I will discuss the fundamental aspects of software design and how to better understand individual elements of principles and patterns.
Introduction
The article is intended for intermediate and veteran programmers looking to expand their knowledge of principles and patterns. Before reading this article, you should be familiar with general OOP, design patterns, and architecture.
In this article, I'm going to examine what's behind and underneath principles and patterns to expand awareness of them. I am not going to try to cover any specific principle or pattern besides in examples.
Most developers are familiar with a lot of the buzzwords around OOP if not just for plastering all over their resume and anticipated interview questions; however, beyond job hunting additional familiarity with these terms and concepts can actually be bad. Yes, bad! Because most of the time, when we learn these concepts, we learn them very early in our career before we actually can understand them in-depth.
I recently asked a "20 year architect" I was interviewing to explain the differences between IOC and other creational patterns. He couldn't - at least not in a coherent manner. Throw aside stale interviews for a moment and ask yourself, is there a value in being able to understand and dissect these differences?
I'll give you a clue to the answer on this one... It starts with a 'y' and ends with an 'es'. Granted a large portion of the time there's not huge value in dissecting these technical differences, but development is a never ending stream of problem solving where inevitably those differences will be critical. If you want to qualify yourself as an "expert" or "architect", you need to know those kinds of differences.
What happened here is a classic case of "I learned it so I know it forever". The problem is we typically can't fully understand new, complex information without a cyclic learning process. For example, requirements are new, complex pieces of data that evolve the more they're understood. It is a major driving force behind the Agile Manifesto and part of the underlying reason pushing development more towards Agile over Waterfall.
So what can we do about expanding our knowledge of OOP? We can apply a cyclic, evolving learning process to principles and patterns (for that matter everything in life) just like we do for requirements. We have to accept we don't know everything from the beginning. The cycle starts when we understand the more we learn, the less we know just like it is digging into requirements...
Software Design Goals
Before diving into any area, we need to make sure to understand that OOP and patterns weren't designed out of some pretentious desire to create singular ways to code. The end goal is to achieve greater software development productivity. So whatever you choose to do, regardless of how technically better a solution may be, you have to ask whether that choice fosters more productivity than the other choices.
Let's dissect that for a second just in case your immediate thought is something like, "No it's not! It's so that software can be cleaner and more maintainable!" Why do you think people want clean and maintainable code? It's so that developers can be more productive by less time to fix bugs, easier to scale features, more flexibility to make changes, etc.
Going back to Agile versus Waterfall, the goal of each is better requirements. I know many developers who slam Waterfall, but Waterfall has its purpose. There are systems that have a high cost of failure (loss of life, millions of dollars, etc.) and for those systems, the goal in Waterfall is upfront, rigorous processes to mitigate the occurrence of a failure. The average website isn't going to have those same risks so Agile and roll forward approaches are not only acceptable, but they often yield the best productivity.
Point is make choices based on goals and productivity. We can get trapped reducing our own productivity over principles - OOP and other. If Waterfall suits your project, better choose that approach. If modifying your Agile process to incorporate more control works best, do that instead.
You Ain't Gonna Need It (YAGNI) is another great example of how principles can kill productivity. Development time spent creating hooks and features for extensibility without ever using said hooks and features is still a waste of time regardless of how elegant it may be. Not only that, typically speaking, more code means increased complexity and reduced understandability.
So what is productive code? Well, that depends... The vast majority of software is written to solve a business need so in most development shops, it's meeting business needs that defines productivity. As such, productivity is defined per company, per project.
Let's say writing sloppy code to push a change early creates technical debt, but the cost of not being able to push out early is the project getting cancelled. What produces more value? Clean code? Or keeping the software project alive? Obviously, most day to day software decisions aren't that extreme, but the point remains that clean code isn't always the most productive choice.
Clean code definitely should be the default the way to go, but how clean should you go to still maintain business value? That brings us to the common difficulty developers face - determining the level of clean code that needs to be maintained.
Let's take naming conventions as a simple example of what I mean by the level of clean code... It would be best to use industry standard naming conventions for whatever development environment the code is in; however, it's usually considered acceptable to have a consistent naming convention even if it deviates from standards. If the names are completely meaningless (x, y, MySuperDuperClass) or the conventions aren't consistent, then there is a bigger issue.
Those levels are straightforward. The first two are acceptable, the last is not. What about the gray area? What about poor naming choices?
Hypothetical scenario... Joe just submitted a pull request and he's got horrible naming choices. Joe is rather sensitive to criticism and is on another critical project due this week. You're the reviewer. Do you break down all the poor naming choices? Or do you let it slide because you don't want to risk derailing his work/attitude on the critical project?
If Joe blows the deadline for the critical project, there can be severe costs. If Joe feels excessively criticized, what does that do to the professional relationship? What's the cost to poor naming choices? Being more productive at times means picking battles and it's a key part of any developer's career. The reality of the matter is goals are bigger than the technical picture.
Please don't take this the wrong way. In the vast majority of cases, it's clean code that produces the most value. I do want to emphasize though it's the value from a choice that should determine when to make that choice.
The pitfall with this decision making process is ending up in a position where sloppy code is prevalent and technical debt is never addressed. As technical debt builds, steps must be periodically taken to address it or productivity will inevitably decline to the point it becomes too much to address. When it gets to that point, the software is basically a Daily WTF story...
Goals of the software establish the value of any delivered software, therefore it's goals that should drive the software decision process. Remember to pick battles and keep development pragmatic.
How to Avoid a Bowling Green Massacre
One of my biggest pet peeves in software design discussions is the "1,000s of solutions" argument. As in, there's no best way because there are 1,000s of solutions that can solve the problem. That's bullshit. There are best ways and definitely ways that are better than others. It might not be clear or even possible to determine at design time which ends up being the best, but you can most certainly make educated decisions and provide some level of quantification to design choices.
Most initial designs have some sort of pitfall. Not necessarily due to a lack of effort, but simply because at the start of projects in today's Agile environments, it is almost impossible to see everything. If you have never looked up the actual definition of pitfall, here it is:
Quote:
pitfall
-
a hidden or unsuspected danger or difficulty.
The key point here being "hidden". That means no matter anyone's infinite glory, they might not see the problems ahead. Remember that in these circumstances:
- You think you can get by coding from the hip.
- Someone else has issues with your perfect design.
- Unexpected difficulties become as common as Star Wars references.
Falling victim to a pitfall isn't the end of the world and regardless of not being able to eliminate them all, there are coding measures that can help mitigate their damage. A typical way to mitigate damage is planning for pitfalls to happen even if you don't know where they're going to appear.
The bigger blunder is the anti-pattern:
Quote:
anti-pattern
- A common response to a recurring problem that is usually ineffective and risks being highly counterproductive.
Here's an anti-pattern I often see... Developers using "IOC" who declare the interface in the same exact library as the implementation. A huge benefit to IOC is it's support for dependency injection, and that's defeated by this anti-pattern. In this case, anyone resolving the interface will automatically have a dependency on the implementation code. There's virtually no benefit over simply working with the implementing class. The optimal way is to have a high level library with the interface declarations as the dependency than have the implementation in another decoupled library.
The anti-pattern is much worse than a pitfall because it often elicits dangerous responses such as:
- I know my code works.
- I shouldn't have to.
- But this is how everyone else does it...
These responses often form blinders that cause developers to start "fixing" working code. Meanwhile, there are inadvertent impacts galore and by the time the actual issue is resolved, the code needs a full regression test. In other words, anti-patterns are huge productivity killers.
So what do bad decisions have to do with principles and patterns? If you don't dig into the purpose of a principle or pattern, you will likely hit pitfalls and succumb to anti-patterns. The next thing you know you'll be scrambling to save face making up stories about a "Bowling Green Massacre" or whatever else that becomes the "real reason" behind code issues...
Principles, Patterns, and Parley
In "Pirates of the Carribean: The Curse of the Black Pearl" Elizabeth Swan demands parley by the code of pirates. After meeting with the pirate captain Barbossa, he ends the parley with this:
Quote:
First, your return to shore was not part of our negotiations nor our agreement so I must do nothing. And secondly, you must be a pirate for the pirate's code to apply and you're not. And thirdly, the code is more what you'd call "guidelines" than actual rules.
Elizabeth Swan wound up blindsided in a predicament because she was trying to use something she didn't fully understand. A big part of that misunderstanding was the principles of parley versus the guidelines. Developers wind up in this boat all the time...
So let's try to avoid this by first identifying key terms:
- Principle - a fundamental source or basis of something
- Pattern - a repeated design
- Best practice - commercial or professional procedure that is accepted or prescribed as being correct or most effective
- Special snowflake - a person or company that believes they are outside of the common denominator of whatever industry they are in
Principle can be a tough one because many recommendations and guidelines are just that - recommendations and guidelines. The tricky part is some are rigid rules that must apply or you can just throw it out the window.
For example, a principle of N-tier architecture is to physically enforce layer interaction to achieve the goal of segregation of responsibility of layers. I can't tell you how many times I've seen a developer call a layered architecture N-tier...
If there is only one layer or all layers live in the same physical location, then it's not N-tier. How many tiers there are or how many layers are in each tier are up to the developer's discretion. There's a reason why they have different names!
So why is that important? In layered development, there's nothing stopping a developer from violating the application standards of layer interaction. It also means the code may be harder to distribute to future applications or services. If you don't understand those differences, it means you might not be prepared for what happens next in the project...
On that note, let's talk patterns... The very first thing to understand is that there are two main types of patterns:
- Design patterns
- Architectural patterns
Huge differences between the two and very important to understand. And let's just assume at this point I only will discuss topics in this article I feel are important to understand so I don't have to keep mentioning it...
There are three classifications of design patterns which are:
- Creational
- Behavioral
- Structural
A design pattern is a specific way to implement a solution to a common problem. So creational patterns are specific implementations on how to create objects.
One of the most common creational design patterns is a Singleton. The principle details to a Singleton are:
- Private constructor such that the class controls any initialization
- At any point in time, the class only has one instance initialized
Notice how these principles are based on implementation? Private constructor... That tells me how I have to write a specific line of code... The class must do x, y, z... It means I have to write specific functionality...
If you don't implement a private constructor, you are not implementing a Singleton - period. At any point in time, someone else can create another instance of that class and the entire goal of the design pattern is to prevent that from ever happening!
A static instance of an object is not a Singleton. A shared instance in a container is not a Singleton. Both of these are examples of what you'd refer to as lifetime objects, but again that's different.
Architectural patterns are higher level patterns that often define how code is physically structured and how layers interact with each other. Below are some common architectural patterns:
- N-Tier
- Service Oriented Architecture (SOA)
- Model-View-* (MV*)
- Domain Driven Design (DDD)
Architectural patterns essentially have the same level of scope (your entire project) but are commonly blended. In fact, the four architectural patterns mentioned are often blended in the modern business application. For example, you can have MVVM and N-tier simply by physically separating each layer. The Model layer can be based on DDD and use SOA to communicate with business services.
It's possible to blend design patterns too, but since design patterns are implementation specific, there are some that are mutually exclusive. It's very common to see lazy initialized singletons for example; however, you cannot have a factory that creates singletons. You can have a method return singletons, but then it's not a factory...
On the topic of lazy initialized singletons, we've now hit our next topic - best practices. It is a best practice to lazy initialize lifetime objects or any object that may be resource intensive. Only create what you need, right?
So below is a best practice approach to lazy initialize a thread-safe singleton:
public sealed class MySingleton
{
private static object initializationSyncRoot = new object();
private static MySingleton current;
public static MySingleton Current
{
get
{
if (current == null)
{
lock (initializationSyncRoot)
{
if (current == null)
{
current = new MySingleton();
}
}
}
return current;
}
}
private MySingleton()
{
}
}
I have seen (and written myself) a sync root without the double null check many times, but it's an optimized way to handle concurrent value checking. The vast majority of time this is accessed, the current value not be null so there no need for synchronization. In the rare case of competing for the critical section at startup, you grab the lock, then make sure no one else got to set current first, and finally set the field.
On top of proper implementation of the Singleton pattern with thread-safe lazy initialization, we also have proper naming conventions and relatively standard class organization (fields, properties, constructors, methods). So all-in-all, a good example.
Sure you don't have to make the Singleton thread-safe, but when it's easy to do, it's usually the best thing to do. A best practice is called a best practice because the industry as a whole has encountered numerous issues from not doing it that way.
So if there are all these best ways of programming, it should be easy right? The problem is just about every single company I've been in has said:
- We have more demanding business requirements than most companies.
- We have more complex data than most companies.
What I've never heard from any company I've been in:
- We have average software needs.
- We can't justify the amount of technical debt we have.
The attitudes behind these sentiments typically cause avoidance of best practices. There are certainly legitimate reasons to deviate from best practices and other industry standard practices from time to time, but odds are it's not often and not because your needs are so drastically different than everywhere else.
These phrases also tend to foster special snowflakes because you're so unique after all, right? The special snowflake looks at existing best practices and says things like:
- That doesn't apply to me.
- I can do it better.
It does apply! The thing about the lowest common denominator (the industry) is that it includes everyone. I'm not one to use argument by authority, but most of the times, the experts are called such for a reason. If you think you can do something better you just might, but you absolutely better be able to qualify why and how.
Of course, the real issue with special snowflakes isn't that illusions of grandeur exist, it's that it's everywhere. I worked in a team that kept touting "world class" data. Meanwhile the data was objectively the worst data I've seen in a production system - caused a ton of heartache. No standard naming conventions, lack of referential integrity, unintentional 1NF/2NF tables, and more. The real kicker was storing computed quarterly data by name like JFM_exports with sometimes inconsistent, unidentifiable units...
Poor performance dominates and "uniqueness" becomes the scapegoat. A project did not blow it's deadline because the business requirements are so much more intense than everywhere else. It's because the self-described "database god" Joe Schmoe didn't know how the hell to design a database.
If we're able to recognize all these facets to code and the development environment, it might just be able to make things easier to handle. If something seems harder than it should be, there's a good chance it is. Unfortunately for legacy development, sometimes it just has to be handled with hands tied behind the back. At least if it's recognized, there's ways to prepare for it.
The Litmus Test
The way to tell a project is going well as it continues to grow is that things get easier. Wait a second... Project gets bigger, more features, and it's supposed to get easier to make changes? What the what?
Think of it like this... If you're cooking a meal and someone has already preheated the oven, got water boiling, took out the spices, cut/diced the ingredients, etc., isn't it easier to make a meal? Of course, there are alternative outcomes... The oven is full, all the pans are dirty, and there's no more garlic... Makes it really tough to do anything in that case and all you can make is spaghetti, but that's the point... How hard you have to work with what's there is usually a pretty good indicator on how clean it is.
Most of the pain in development is caused by one of two things:
- The fundamental architecture of the program
- Technical debt
If you're not familiar with the term technical debt, it is the sub-optimal coding choices made as a sacrifice for some other priority. Debt being a key word here because you expect to pay it back; however, the vast majority of time it just builds until the project should be declaring bankruptcy.
Different patterns for delivery time can be seen based on the amount of technical debt in a project. What pattern an application exhibits is usually a pretty good indicator how well it was designed. The first litmus test is therefore time to deliver.
NOTE: Please excuse my awesome MS Paint artistry.
If you just absolutely nail the architecture and design, here's what time to deliver should look like:
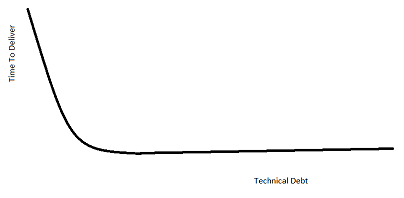
Basically, what this means is that you've got a large, initial investment in your architecture and design. After the frameworks and fundamental application logic get established, everything becomes very smooth. No large refactoring needed and even as technical debt grows, separation of concerns limits exposure therefore not significantly impacting delivery.
Here's the opposite end of the spectrum:

What this means is initial upfront delivery is very easy because you're hacking away and pushing out changes at a whim. Everything is smooth until a particular complexity breaking point is reached and development costs for even small changes sky rockets because there's no separation of logic. Fixing one problem tends to create more. As things can only get so bad, it levels off quickly; however, the code is so badly mangled at this point any major refactoring is essentially a re-write.
Here's a more pragmatic scenario you hope to see:
You're trying to do things as best as you can, considering all things including your TPS reports and boss breathing down your neck. When things start to get bad, you bite the bullet and do some refactoring. You only pulled out what you needed to, but when it gets bad again, you'll have to suck it up again.
The key concept that I just glossed over in all this is separation. The earmark of any good design, despite choice of architecture, is separation of concern. It's so important not only does OOP directly tackle it, but two other fundamental concepts also tackle it - SOLID and GRASP.
Think about this a minute... If a particular section of code is properly segregated, it means that internal class code changes will not break any external code. If a particular section of code is properly segregated, it also means changes to behavior only have to be made once. If both of those hold true, how easy is dealing with problems by refactoring?
Refactoring is a great litmus test. How many classes do you have to change to fix a bug? How easy is it to add an enhancement? Refactoring is also critical to maintenance, scalability, and flexibility making it arguably the most important type of coding.
Types of coding? Yes, there are three types of coding changes:
- Extending
- Modifying
- Refactoring
Hopefully all three terms are familiar, because everyone should know refactoring and the first two are covered by the open/closed principle. The open/closed principle is the 'O' in SOLID and states code should be open for extension, but closed for modification.
It's really important to note that modification is not synonymous with changing code. Refactoring and fixing bugs changes code obviously, but these aren't necessarily modification. Modifying code is modifying the expected behavior of the code. For example, modification would be taking a method called GetList and changing the return type, adding a parameter, or having it do some completely different function internally. If you just have to rework the internal method code to do the same thing, it's simply refactoring.
Modification should be avoided for any released software; however, if it's early in development or the application is isolated, then it's condonable. That being said, how much modification is needed throughout an application's life is another litmus test. If you find yourself regularly having to, or wanting to, modify code function, there's probably some bad design.
Normally, if a parameter needs to be added, this would be handled by extending via overload. That way, any existing code will still function as expected and function is just being added - hence extension. Extension can also include refactoring. In the parameter change, for example, you might end up moving the code to the new method and passing a null parameter from the old.
So in summary, our three litmus tests we have are:
- time to deliver
- effort needed to refactor
- need or desire to modify code behavior
If you find problems in any of these three areas, don't make excuses, instead look for answers.
Blah, Blah, Blah, Blah
Okay so I've word vomited just about enough, but in all seriousness, everyone needs to constantly discuss these topics. Your knowledge isn't going to expand unless you work through your ideas and get your ideas challenged by others.
Don't take anything personally. Even if someone calls your ideas stupid, suck it up and ask why - they just might be. What would you honestly rather have? Knowledge that can expand your professional career? Or pride?
Always strive not to be the smartest guy in the room. You can learn a lot working through your own ideas, but not nearly as much as when you've got a smarter guy helping you along.
Don't try to memorize definitions. Try to learn the concepts and applications. I doubted myself on this one for a long time until I watched Jeffrey Snover, creater of PowerShell and esteemed Windows engineer, relying on help in PowerShell.
Hope you enjoyed my rant of the day!
Thoughts? Comments? Insults?
History
- 1st March, 2017: Initial version

