Provided Sample Code
GITHUB now available
https://github.com/LdB-ECM/Raspberry-Pi
Introduction
This article unfortunately will be quite long because of the scope of the code presented. My current push with the Pi is developing my own 64 bit O/S but as part of that process, I need a loader, which is a piece of code that looks and behaves a lot like a BIOS on a normal computer. The simplest description of it is a piece of code that can initialize the Pi and work out the Pi model, memory, peripherals, etc. and then pass that information onto the O/S as it boots the O/S. Finally, the code itself may actually even be removed from memory by the O/S as it replaces and enforces its own functions.
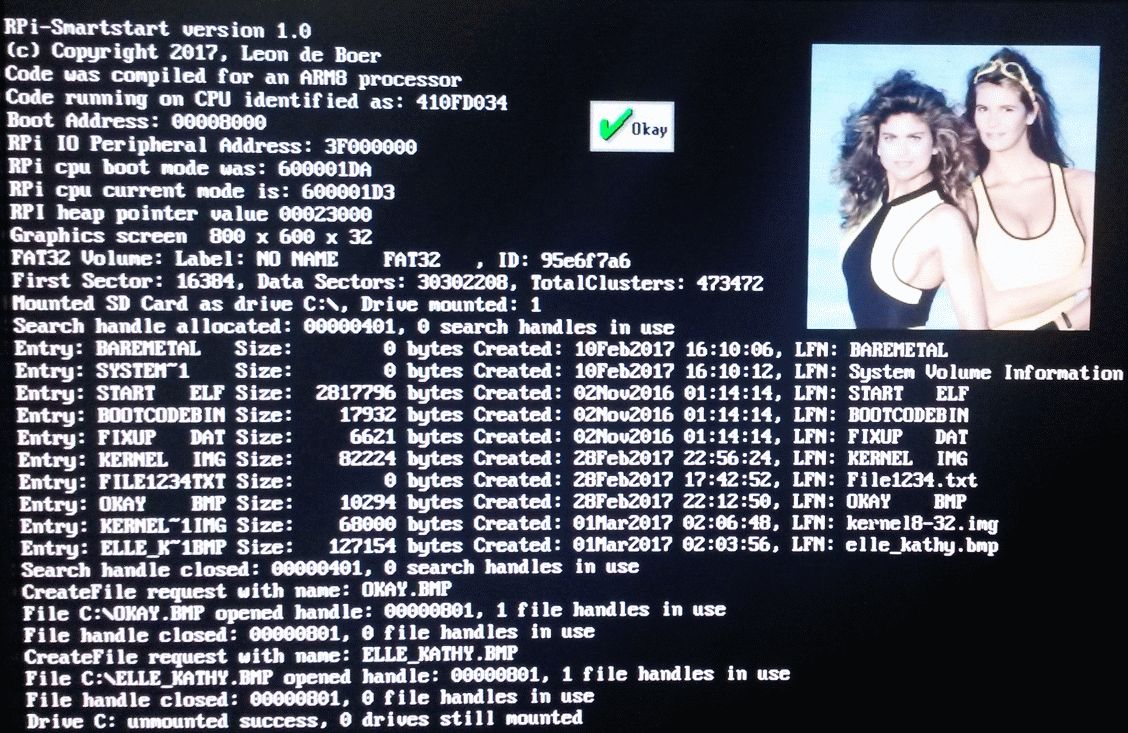
The loader code must cover a diverse range of functions from mounting drives and partitions, reading file systems along with the more mundane things such as screen display. My loader is still at this stage incomplete but the code is at a point it might be useful as a start point for other uses. This is the screen of the current version I am releasing.
Background
As with my previous articles, the code is organized to compile with one of the batch files matching the Pi model you are using (pi1, pi2, pi3.bat) and provides a simple command line link to the directory I installed the windows arm cross compiler in (for me G:\Pi\gcc_pi_6_2). I use the standard ARM cross compiler available from the official ARM site here.
So we need to get into the details of how SmartStart works. For those not familiar with assembler coding, you may need to do some basic reading to fully understand the next parts. Why assembler and not C has a two part answer from me. First, this is something like a BIOS. It needs to be the lowest Pi version code (ARM6) as it must run on every Pi board. You could setup a make file to make certain C files in ARM6 and then other in ARM7/8 but that process is just plain messy. The second factor is precisely sizing the code blocks in C. This is even more messy and unreliable and to some extent, you can never be certain that everything contained in the code is included. This is especially true with higher optimizations as small C code blocks can even be selected to be inlined into large C blocks. So that is the basis of why I choose assembler over C.
Smartstart starts by doing a series of autodetection functions storing that information and then passing into the normal C main block. Code from C can then access API functions provided by smartstart (which always start with RPI_xxxxxxxx) and which are fully aware of the underlying Pi model structure because of the autodetection phase. They use this held information to then execute the function seamlessly on any model Pi without the user needing to intervene.
Smartstart is basically blocks of assembler code which at its core is built around a fairly simple system that has 7 key points:
- Put each assembler function source in one assembler file.
- Include every function as its own section of the normal sections (.txt, .data, etc.) in your assemble process
- Create a single C header file for the library function prototypes and any
typedefs - The above header file is shared and included to the assembler so they can never differ or go into error
- Compile with the flags
-ffunction-sections -Wl, -gc-sections (garbage collect and toss unused sections) - Release your source to the unsuspecting client/public.
- They need nothing else, blocks are incorporated only if they are used. It is use it or lose it compiling.
A typical section block looks like this:
.section .text.RPI_GetArmTickCount, "ax", %progbits
.align 2
.globl RPI_GetArmTickCount;
.type RPI_GetArmTickCount, %function
.syntax unified
.arm
;@"================================================================"
;@ RPI_GetArmTickCount -- Composite Pi1, Pi2 & Pi3 code
;@ C Function: uint64_t RPI_GetArmTickCount (void)
;@ Return: R0, R1 will have tickcount value
;@"================================================================"
RPI_GetArmTickCount:
stmfd sp!, {r4, lr}
ldr r3, =RPi_IO_Base_Addr
ldr r3, [r3]
add r3, r3, #0x3000
.HiTimerMoved2:
ldr r2, [r3, #8] ;@ Read timer hi count
ldr r0, [r3, #4] ;@ Read timer lo count
ldr r1, [r3, #8] ;@ Re-Read timer hi count
cmp r2, r1
bne .HiTimerMoved2 ;@ Check both hi count reads were same
ldmfd sp!, {r4, pc}
.align 2
.ltorg ;@ Tell assembler ltorg data for this code can go here
.size RPI_GetArmTickCount, .-RPI_GetArmTickCount
The code compiles to its own subsection of the normal .text segment (subsection .RPI_GetArmTickCount) and we even carry the section size both to aide the linker and later if I wish to throw the code block out of memory or move it, I know its size.
The .ltorg tells the assembler where it can put hard code literals that come from the pseudo opcode instructions like "ldr r3, =RPi_IO_Base_Addr". What that will really do is put a literal word into the ltorg position ".word RPi_IO_Base_Addr" and the load will be from that literal. Those literal values must be linked with the block at exactly that position and they form part of the code and thus part of the block size.
The C header to encapsulate that function looks like:
extern uint64_t RPI_GetArmTickCount(void) __attribute__((pcs("aapcs")));
The "aapcs" attribute is the current standard calling convention for ARM and just protection should another standard crop up in the future. That standard simply covers what is carried in and on registers as they go into and out of C functions and as our assembler is assuming "aapcs" standard, I have just clarified that to the compiler. You can always read up on "aacps" if you have interest in that.
Now if our function above is used anywhere when we compile our program, the code block will be added to the output file and if not, it will be tossed away by our compiler flag instructions (-ffunction-sections -Wl, -gc-sections).
So let's take an absolute minimal code - something like this one:
#include "rpi-smartstart.h" // Needed for smart start API
int main (void) {
while (1){
RPI_Activity_Led(1); RPI_WaitMicroSeconds(500000); RPI_Activity_Led(0); RPI_WaitMicroSeconds(500000); }
return(0);
}
It is the good old flash the activity LED on a half second interval on, then off and repeats. SmartStart knows where the activity led is for each model of Pi as well as the timer and the code neatly compacts down to a fairly minimal IMG file of about 9K on each model. All the code blocks that are not referenced in the program (the block above for example) will be ignored by the linker. If you are interested in trying a minimal example, here is the code.
The code blocks really do function in a use it or lose it setup mode. You do not need to get alarmed about the amount of code in the assembler file, only sections that you use will be included in your IMG file.
The more advanced users may care to look at the linker file "rpi.ld" and look at the layout of the stacks, data and text segments. There are some more advanced tricks in there, for example, I have two data segments - one which is 4 byte aligned and one 16 byte aligned to try to minimize data gaps. A lot of mailbox data structures are required to be 16 byte aligned and by keeping them together in a 16 byte alignment block, it aids neat compacting of the data.
Another interesting thing is "rpi-smartstart.h" is included by both the assembler and the C compiler because some of the definitions in it are required by both to ensure they match. You need to remember section between #ifdefs can be for the assembler, the c compiler or both.
The final warning is about alignment issues with the ARM7 and ARM 8 compilations. Many fixed structures such as that used in FAT32 and even BMP files are not aligned to 4 byte boundaries. Even simple code like memcpy, etc. will cause a processor to throw an unaligned halt. You will see at a number of points in the code references to unaligned access and you need to take care not to ignore it. There is support on the subject on the ARM website, for example, on memcpy here. I do not like the suggestion to divert memcpy back to what is essentially the ARM6 version of memcpy and face the speed penalty everywhere for what is a few specific cases I can easily identify. However, if it does become troublesome to you, then it may be an option.
Personally my workflow goes, I compile and work with everything in ARM6 (pi1 compilation) even on the Pi2, Pi3. The smartstart autodetect takes care of all the differences between the two models and my ARM6 code works flawlessly and without alignment issues on the Pi2, Pi3. Finally, when I have everything running as I desired, I change to ARM7 or ARM8 compilation and then look at what breaks which will always just be alignment issues which can then be easily run down.
Using the Code
The smartstart API has many functions embedded in it like all the normal ones like Timer and GPIO access right through to graphics and SD Card access. I encourage you to open the rpi-SmartStart.h file and look at the various functions which are documented there. I am trying to find time to create a detailed documentation on the smartstart API, but for now, the most up to date descriptions are on in the header file itself.
Okay, having covered the basic background, I will need to discuss the provided sample. The example provides an incomplete file system (filesys.c and filesys.h) which I am using to test and debug on. The keyword here is incomplete - it does some things and doesn't do many others. Further warning - the filesystem is based around the Windows API, I simply am not familiar enough with linux to work an example on it.
A disk drive has on it one or more partitions in a particular format such as FAT16, FAT16, NTFS, EXT3. The provided filesystem file currently know FAT16 and FAT32 and as that is what the format of the SD card is on the Pi, it is the obvious choice to use on our sample.
So to use a drive, one must first mount it on a selected drive letter you want to know that drive by which can be A to Z inclusive. The mount code takes this form and it's pretty easy to see the sample mounts SD card partition 0 as "C" drive. Note the code currently only mounts partition 0, I have not yet dealt with multi partition drives but have provided the interface to do that expansion in the near future.
if (mountSDCard('C', 0) == SD_OK) {
As our baremetal file is starting, we are pretty guaranteed that the SD card has a FAT16 or FAT32 partition so it should mount. Once it mounts, you then have access to a range of file functions provided by smartstart. If you are interested in how the FAT16/32 systems work, I cannot go past recommending the wikipedia page.
As per all Windows file operations, they work on a thing called a file handle. Our file system follows that scheme and we have two types of file handles called search handles and access handles.
The first part of the example lists the files on the drive by using a search handle in the functions FindFirst, looping on FindNext while valid and then FindClose to cleanup the handle. Now you need to be aware of a number of restrictions because I have not completed full Windows API implementation. All these restrictions are clearly commented in the function code and refer to there for more detail.
FindFirst has no concept of "current drive" you must provide a drive letter to a valid mounted driveFindFirst has no subdirectory support yet it will do only root directory (TBD item)- Search handles take up around 600bytes they are limited to 4 in filesys.c (you can change look at code)
- From 3, when you have finished with a search, use
FindClose to free up that handle so it can be used again
Assuming FindFirst returns successfully, we then call findnext with the valid search handle returned. It will either return with the next file entry or finally fail when no more files exist. The sample displays some details returned from the file search (date/time/size, etc.) for each valid file. I then execute FindClose to release the search handle for re-use. It's all pretty straight forward and I use the standard C time functions for display.
You can see the 3 simple steps marked in the code shown here:
FHANDLE handle = FindFirstFile("C:\\*.*", &search_data);
if (handle & SHE_ERROR_PRESENT) printf("Findfirst failed with Error ID: %8lx\n", handle);
while ((handle & SHE_ERROR_PRESENT) == 0) {
char buffer[26]; strftime(buffer, sizeof(buffer),
"%d%b%Y %H:%M:%S", &search_data.CreateDT); printf("Entry: %s Size: %8lu bytes Created: %s, LFN: %s\n",
search_data.cAlternateFileName, search_data.nFileSizeLow,
&buffer[0], search_data.cFileName); if (FindNextFile(handle, &search_data) == false) break; }
FindClose(handle);
The second part of the demonstration does basic file read access functions. The write function provided is incomplete as it does not set the FAT entry filesize correctly as a TDB exercise. As I am doing a loader, I have been far more interested in the read functions, not the write functions. I only remembered that shortcoming while writing this article and will attempt to update that in the coming days.
So our read file testing basically displays the two bitmap files to screen. It begins by creating a valid file access handle and again we have restrictions:
CreateFile has no concept of "current drive" - you must provide a drive letter to a valid mounted driveCreateFile has no subdirectory support, yet it will do only root directory (TBD item)- File access handles take up around 640bytes - they are limited to 4 in filesys.c
- From 3, when you have finished, call
FileClose to free up that handle so it can be used again
The other two functions used in the bitmap display ReadFile and SetFilePosition take that valid file handle returned and do the appropriate functions with it. If you wish to change the bitmap files, they must be 24 or 32 bit BMP files if you wish to use the rough display code I provided. I have made no provision for the use of low colour depth BMP files with things like 16 or 256 colour.
Points of Interest
This is hopefully the beginning of a number of smartstart version releases which will add more and more functionality. I am currently working with mounting USB drives which is working with Pi1, Pi2 but not Pi3 and that will hopefully make the next release.
If anyone has public release C code to read linux ext2/3/4 partitions, I would love to hear from you in the comments link below or via my email on my contact details.
History

