Introduction
Cekirdekler API is open-source C# OpenCL wrapper that makes load-balancing between multiple opencl-capable devices and adds pipelining to get more performance and lets users apply their genuine C99 codes on all GPUs, CPUs and even FPGAs in their system.
Shortly, it speeds-up a simple hot-spot bottleneck of a program by 10x 100x 1000x.
The project was pushed to github a few weeks ago:
https://github.com/tugrul512bit/Cekirdekler/wiki
with its C++ part:
https://github.com/tugrul512bit/CekirdeklerCPP
(new info is incrementally added to the end, new dll files always before Introduction, see the changelog part at the end)
(now dll files here is built on an FX8150, with the fixed console logging bug for non-console apps)
Simple usage cases in Unity Game Engine(computing on Vector3 arrays and primitive arrays with R7-240 GPU and CPU):
https://www.youtube.com/watch?v=XoAvnUhdu80
https://www.youtube.com/watch?v=-n_9DXnEjFw
https://www.youtube.com/watch?v=7ULlocNnKcY
Background
Generally for all thin wrappers of OpenCL, users are needed to implement all buffer copies and event handling themselves. This API takes care of that and users need only select what is to be done with simple API commands. Single line to declare a device or all devices or a sub-group of devices depending on their vendors or compute units ormemory sizes. Single line to declare number cruncher that holds OpenCL kernel that is written in C99 language and passed as a simple multi-line string. Single line to declare an array backed by a buffer in C++(optionally) or just gather user's C# array and enhance it. Single line to compute.
Using the code
The compressed files given in the beginning are for the lazy developers. They are built on a Celeron N3060 so don't expect miracles. I advise you to visit github address I've given and download whole project and build on your computer, it's open-source after all. Thats the best way for performance and security.
Just in case the compressed files are used:
- Cekirdekler.dll: add this as reference in your C# project. Then add usings like "using Cekirdekler;" and some of its sub-namespaces in code files you use it.
- Cekirdekler.XML: this helps intellisense to tell you about methods and classes.
- KutuphaneCL.dll: needs to be in same folder with Cekirdekler.dll as it uses this with dllimport attributes.
- System.Threading.dll: you can download this from Microsoft's site too. This makes it able to run in .Net 2.0. Add this as reference too.
- System.Threading.XML
Main namespaces are:
- Cekirdekler: has ClNumberCruncher and Tester classes
- Cekirdekler.Hardware: explicit device selection instead of selecting all of them
- Cekirdekler.Arrays: contains array wrappers as ClArray{generic} and ClFloatArray and similar.
Let's assume developer needs to add value of PI to all elements of an array
then he/she needs to write this:
ClNumberCruncher gpu = new ClNumberCruncher(AcceleratorType.GPU | AcceleratorType.CPU, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.1415f;
}
");
ClArray<float> f = arrayOfPIs;
f.compute(gpu, 1, "test0", 1024);
this makes the addition happen using all GPUs and all CPUs in the system. By running the C99 codes in the string on the array elements.
The parameter "1" in the compute method is compute-id which means the next time compute method with same compute id is reached, load balancer will trade some workitems between all devices to minimize the overhead of compute method.
The parameter "1024" in the compute method is the number of total workitems distributed to devices. If there are two GPUs in system, both devices start with 512 workitems each, then converge to a time-minimizing point later with more repeatations of compute.
Default value for the workgroup(OpenCL's definition of memory-sharing smallest group of threads that run in same compute unit) size is 256. If one needs it be 64,
f.compute(gpu, 1, "test0", 1024,64);
When more than one buffers are needed in kernel code:
__kernel void test0(__global float * a,__global float * b,__global float * c){...}
they can be added from host-side like this:
f.nextParam(g,h).compute(gpu, 1, "test0", 1024,64);
such that, the arrays f,g and h must be in the same order as in the kernel parameters with __global memory specifier. Then f is linked to a, g is linked to b and h is linked to c.
If developer needs more performance, pipelining can be enabled:
f.compute(gpu, 1, "test0", 1024,64,0,true);
parameter with zero is the offset where compute begins so each thread gets a global id shifted by this amount. True value enables pipelining. It is false by default. When enabled, API partitions each device's workload into 4 smaller works and pushes them in an even-driven pipelined manner so these parts hide each others latencies. By default, pipeline type is event-driven. There is also a driver-controlled version which uses 16-command-queues without event synchronizations but with complete blobs(with their own read+compute+write combined) to hide much higher latencies between command queues. Driver-controlled pipelining is enabled by adding another true value:
f.compute(gpu, 1, "test0", 1024,64,0,true,true);
this needs more CPU threads to control all blobs' uploading and downloading datas. Some systems are faster with event-based pipelining with separated reads hiding separating computes or separated writes, some systems are faster with driver-controlled version.
Number of blobs for the pipelining must be a minimum of 4 and has to be multiple of 4 and is 4 by default. This value can be changed with adding it after pipeline type:
f.compute(gpu, 1, "test0", 1024*1024,64,0,true,true,128);
Sometimes even pipelining is not enough because of unnecessary copies between C# arrays and C++ OpenCL buffers, then one can adjust a field of array wrapper to make it zero-copy access:
f.fastArr = true;
this immediately creates a C++ array inside, copies values of C# array to this C++ array and uses it for all compute methods it calls. If it will be used more than once, it will decrease GPU to Host access timings greatly. If developer needs to start with C++ rightaway,
ClArray<float> f = new ClArray<float>(1024);
this creates and uses C++ arrays by default. There is also ClFloatArray that can be passed to this as initialization. API has these types for use arrays: float, double,int,uint,char,byte,long.
ClNumberCruncher class automatically handles CPUs and iGPUs and any other RAM-sharing devices as a streaming-processor to gain advantage of zero-copy read/writes within kernel. This is useful especially with low compute-to-data scenarios as in this "adding PI" example in the beginning.
Streaming option is also enabled for all devices by default so devices may not use dedicated memories.
When developer needs to disable this feature for discrete GPUs, a parameter needs to be given value of false:
ClNumberCruncher gpu = new ClNumberCruncher(AcceleratorType.GPU | AcceleratorType.CPU, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.14f;
}
",-1,-1,false);
Developers can also choose devices for GPGPU in a more explicit way:
Hardware.ClPlatforms platforms = Hardware.ClPlatforms.all();
var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing();
ClNumberCruncher gpu = new ClNumberCruncher(selectedDevices, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.14f;
}
");
the upper example selects all Intel platforms, then selects all devices in them that share system RAM, effectively selecting CPU and its iGPU, better for streaming data. There are a lot of different methods to pick devices depending on their specialities such as memory size, number of compute units and benchmarks(this in future versions).
When performance is not satisfactory, buffer copies needs to be optimized carefully. Cekirdekler API by default behavior, copies all arrays to all device buffers, computes, reads partial results back from all devices. This duplicates some unused same data to all devices. When devices are needed to read only their own part from array, a field needs to be set:
array.partialRead=true;
then, if device-1 computes %50 of array, then it reads only %50 of the array, device-2 reads the rest of it. Then after compute, both write results on array.
There are several flags to inform the API about how buffers will be handled:
array.read
array.partialRead
array.write
"read" instructs the API that array will be read as a whole(unless partial is set) before compute.
"write" instructs the API that array will be written on it but partially by eah device, opposite of partialRead.
If there is only single device and an array needs to be computed many times without copying to/from host, all three fields are needed to be set to false.
Another important part of buffer handling is, "array elements per workitem" value. The API interprets this value equal for all workitems. For example, it there are 1024 workitems and each workitem loads, computes, writes only float4 type variables, it is developer's responsibility to choose "4" for the elementsPerWorkItem value while using float array on host side.
f.numberOfElementsPerWorkItem = 4;
the upper sample enables 4x number of elements to be copied to devices. If a device runs 400 workitems, that device now gets 1600 float elements from array. First workitem works on elements 0-3, second workitem works on elements 4-7 and so on.
Getting some helpful info from console(will be file in future versions) is also easy:
Selected platforms:
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all();
platforms.logInfo();
Selected devices:
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all();
var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing();
selectedDevices.logInfo();
Load balancer distributing workitems at each compute method call:
numberCruncher.performanceFeed = true;
You can find more detailed info on wiki page of github repository.
Quote:
Important info: If total work is salt or sand, then load balancer is trading grains between devices. Grain size is equal to local workgroup size multiplied by pipeline blobs. If pipeline is disabled, then grain size is just local workgroup size. If grainsize is very small compared to global size, then it load balancing becomes finer grained.
When there are M number of GPUs in system, global size must be a minimum of M * Grain size.
Each device has to have a minimum of 1 grain(for example,256 threads). Devices can't totally sell all grains.
Increasing pipelining increases grain size so makes it harder to load balance.
Similar for buffers, now one needs to keep in mind: multiply everything with "numberOfElementsPerWorkItem" of array to know how much data it copies.
Example: 2k workitems shared to 2 devices, 1.5k and 512. If pipelining is activated with 4 blobs and workgroup size is 128, then these two devices can trade only 512 workitems and have minimum of 512 workitems. Very bad example of load balancing, grains are not fine. Now assuming kernel uses float16 but host side is given a byte-array(such as it came from TCP-IP directly), then developer needs to set "number OfElementsPerWorkItem" value of byte array to 16*4 because each float is 4 bytes and each workitem is using 16-floats structs.
Edit:
Kernels can be repeated or different kernels can be run consecutively by names, each separated by space or comma or semicolon or newline char "\n" or minus char. (these repeats don't change load partitioning, profiles as one operation)(seems useful for only single device usage)
f.compute(gpu, 1, "findParticles buildBoxes findNeighbors,calculateForces;moveParticles", 1024);
Edit-2: Example of O(N²) algorithm with high data re-use ratio but low compute-to-data ratio
Code:
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all();
var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing(true);
selectedDevices.logInfo();
ClNumberCruncher gpu = new ClNumberCruncher(selectedDevices, @"
__kernel void algorithmTest(__global float4 * a,__global float4 * b)
{
int i=get_global_id(0);
float4 accumulator=(float4)(0.0f,0.0f,0.0f,0.0f);
for(int j=0;j<4096;j++)
{
float4 difference=a[i]-a[j];
accumulator+=(difference*difference);
}
b[i]=sqrt(accumulator);
}
");
ClArray<float> f = new ClArray<float>(4096*4);
f.numberOfElementsPerWorkItem = 4;
f.write = false;
f.partialRead = true;
ClArray<float> g = new ClArray<float>(4096*4);
g.numberOfElementsPerWorkItem = 4;
g.read = false;
gpu.performanceFeed = true;
for(int i=0;i<25;i++)
f.nextParam(g).compute(gpu, 1, "algorithmTest", 4096,64);
This opencl kernel does 4096*4*(1 subtraction + 1 addition + 1 multiplication) per workitem per compute. Host side executes 4096 workitems so each compute method is doing 201M floating point operations and 537MB RAM access. When load balancer converges, iGPU completes most of the work as quick as 5ms which means 40.2 GFLOPs (%35 of max theoretical value) because compute-to-data ratio is low in the innermost loop. CPU cannot get even closer because CPU is also serving as scheduler for opencl devices.
iGPU has 12 compute units = 96 shaders
CPU has 2 cores but 1 core is selected = 4 arithmetic logic units
Output:
1 cores are chosen for compute(equals to device partition cores).
---------
Selected devices:
#0: Intel(R) Celeron(R) CPU N3060 @ 1.60GHz(Intel(R) Corporation) number of compute units: 1 type:CPU memory: 3.83GB
#1: Intel(R) HD Graphics 400(Intel(R) Corporation) number of compute units: 12 type:GPU memory: 1.52GB
---------
Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 1,278.48ms, workitems: 2,048
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 21.15ms, workitems: 2,048
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [35.9%] - [64.1%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 742.94ms, workitems: 1,472
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 21.16ms, workitems: 2,624
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [25.0%] - [75.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 532.38ms, workitems: 1,024
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 16.43ms, workitems: 3,072
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [17.2%] - [82.8%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 361.98ms, workitems: 704
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 22.07ms, workitems: 3,392
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [12.5%] - [87.5%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 271.71ms, workitems: 512
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 10.75ms, workitems: 3,584
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 185.23ms, workitems: 384
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.56ms, workitems: 3,712
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 131.08ms, workitems: 256
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 15.73ms, workitems: 3,840
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 90.93ms, workitems: 192
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.82ms, workitems: 3,904
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 75.73ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 13.49ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 101.55ms, workitems: 192
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.33ms, workitems: 3,904
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 100.61ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 35.24ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 80.28ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.82ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.85ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 18.15ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 99.78ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 12.82ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.12ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 23.98ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 76.66ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.47ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 81.75ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 19.97ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 66.52ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.36ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 78.79ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 7.36ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 80.02ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 15.07ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 69.05ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.79ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 81.47ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.99ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 70.18ms, workitems: 128
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 4.88ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [1.6%] - [98.4%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 34.74ms, workitems: 64
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 8.58ms, workitems: 4,032
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [1.6%] - [98.4%] ------------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.93ms, workitems: 64
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 10.67ms, workitems: 4,032
-----------------------------------------------------------------------------------------------------------------
now same program with an FX8150 + R7-240(much stronger) system:
Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 197.44ms, workitems: 2,048
Device 1(gddr): Oland ||| time: 95.84ms, workitems: 2,048
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [45.3%] - [54.7%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 136.6ms, workitems: 1,856
Device 1(gddr): Oland ||| time: 80.23ms, workitems: 2,240
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [42.2%] - [57.8%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 117.06ms, workitems: 1,728
Device 1(gddr): Oland ||| time: 5.86ms, workitems: 2,368
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [31.3%] - [68.8%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 82.22ms, workitems: 1,280
Device 1(gddr): Oland ||| time: 2.12ms, workitems: 2,816
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [21.9%] - [78.1%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 55.55ms, workitems: 896
Device 1(gddr): Oland ||| time: 2.06ms, workitems: 3,200
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [15.6%] - [84.4%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 51.72ms, workitems: 640
Device 1(gddr): Oland ||| time: 2.22ms, workitems: 3,456
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 76.16ms, workitems: 448
Device 1(gddr): Oland ||| time: 65.09ms, workitems: 3,648
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 51.23ms, workitems: 448
Device 1(gddr): Oland ||| time: 27.52ms, workitems: 3,648
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 57.61ms, workitems: 384
Device 1(gddr): Oland ||| time: 18.26ms, workitems: 3,712
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.48ms, workitems: 448
Device 1(gddr): Oland ||| time: 2.06ms, workitems: 3,648
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] -----------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 28.99ms, workitems: 448
Device 1(gddr): Oland ||| time: 29.28ms, workitems: 3,648
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.65ms, workitems: 384
Device 1(gddr): Oland ||| time: 3.96ms, workitems: 3,712
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [7.8%] - [92.2%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 27.39ms, workitems: 320
Device 1(gddr): Oland ||| time: 2.13ms, workitems: 3,776
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 30.99ms, workitems: 256
Device 1(gddr): Oland ||| time: 15.85ms, workitems: 3,840
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.29ms, workitems: 256
Device 1(gddr): Oland ||| time: 2.59ms, workitems: 3,840
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 28.12ms, workitems: 256
Device 1(gddr): Oland ||| time: 3.13ms, workitems: 3,840
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.39ms, workitems: 256
Device 1(gddr): Oland ||| time: 2.21ms, workitems: 3,840
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.06ms, workitems: 192
Device 1(gddr): Oland ||| time: 2.65ms, workitems: 3,904
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 43ms, workitems: 192
Device 1(gddr): Oland ||| time: 3.3ms, workitems: 3,904
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.02ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.49ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.75ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.9ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 34.34ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.71ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 26.74ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.54ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 23.89ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.66ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------
Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 23.71ms, workitems: 128
Device 1(gddr): Oland ||| time: 2.61ms, workitems: 3,968
-----------------------------------------------------------------------------------------------------------------
a stronger GPU beats a stronger CPU. This is probably caused by CPU implementation not having enough registers for all threads, also having less threads in-flight and having slower memory(also same memory used for API buffer copies).
Example for streaming data with same host codes but different kernel and 4M workitems with 16M array elements:
__kernel void algorithmTest(__global float4 * a,__global float4 * b)
{
int i=get_global_id(0);
b[i]=2.0f+a[i];
}
even a single CPU-core has comparable streaming performance to its iGPU
Output:
Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 274.97ms, workitems: 2,097,152
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 109.74ms, workitems: 2,097,152
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [43.6%] - [56.4%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 44.11ms, workitems: 1,826,944
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 59.08ms, workitems: 2,367,360
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [45.7%] - [54.3%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 62.52ms, workitems: 1,918,400
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 16.6ms, workitems: 2,275,904
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [37.5%] - [62.5%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.73ms, workitems: 1,573,056
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 46.12ms, workitems: 2,621,248
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [33.5%] - [66.5%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.76ms, workitems: 1,405,568
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 59.51ms, workitems: 2,788,736
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [35.8%] - [64.2%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 36.81ms, workitems: 1,502,656
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 37.58ms, workitems: 2,691,648
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [36.0%] - [64.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.64ms, workitems: 1,508,672
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.78ms, workitems: 2,685,632
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [35.8%] - [64.2%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 35.24ms, workitems: 1,502,720
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 43.96ms, workitems: 2,691,584
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [37.4%] - [62.6%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 47.63ms, workitems: 1,568,512
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 47.72ms, workitems: 2,625,792
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [37.1%] - [62.9%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 40.25ms, workitems: 1,555,200
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 26.12ms, workitems: 2,639,104
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [36.2%] - [63.8%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 43.01ms, workitems: 1,517,760
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.6ms, workitems: 2,676,544
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [35.7%] - [64.3%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 51.87ms, workitems: 1,498,816
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.02ms, workitems: 2,695,488
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [34.6%] - [65.4%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 43.02ms, workitems: 1,452,992
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 33.43ms, workitems: 2,741,312
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [34.2%] - [65.8%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.68ms, workitems: 1,434,624
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 22.51ms, workitems: 2,759,680
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [33.7%] - [66.3%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 46.59ms, workitems: 1,415,296
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.88ms, workitems: 2,779,008
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [33.1%] - [66.9%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 26.05ms, workitems: 1,389,440
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.56ms, workitems: 2,804,864
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [32.9%] - [67.1%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 39.74ms, workitems: 1,379,648
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 34.79ms, workitems: 2,814,656
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [32.6%] - [67.4%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 39.8ms, workitems: 1,365,888
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 33.18ms, workitems: 2,828,416
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [32.0%] - [68.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.77ms, workitems: 1,340,736
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.22ms, workitems: 2,853,568
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [31.1%] - [68.9%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 41.33ms, workitems: 1,304,640
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 40.6ms, workitems: 2,889,664
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [30.6%] - [69.4%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.4ms, workitems: 1,283,264
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 38.03ms, workitems: 2,911,040
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [30.0%] - [70.0%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.96ms, workitems: 1,257,024
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.33ms, workitems: 2,937,280
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [29.7%] - [70.3%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.62ms, workitems: 1,243,904
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.64ms, workitems: 2,950,400
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [29.3%] - [70.7%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 45.05ms, workitems: 1,228,032
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 32.9ms, workitems: 2,966,272
-----------------------------------------------------------------------------------------------------------------
Compute-ID: 1 ----- Load Distributions: [29.1%] - [70.9%] -----------------------------------------------------
Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 41.57ms, workitems: 1,222,144
Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.57ms, workitems: 2,972,160
-----------------------------------------------------------------------------------------------------------------
Changelog(v1.1.5):
- Added global workitem number versus local workitem bounds checking
- Added array bounds checking (doesn't check global offset value)(doesn't check kernel parameter type)
- If out of bounds, returns immediately after the console message and early-quits in future compute methods.
- Hidden the non-useful ClDevices constructor, device selection starts from ClPlatforms.all() and ends in devices____ named methods which return ClDevices
-
when kernel parameters interpret different typed host arrays, element alignment conditions must be met
-
No need to put -1 to both number-of-cores and number-of-gpus parameters in ClNumberCruncher constructor when choosing devices explicitly(these parameters are only exist for implicit device selection now)
Changelog(v1.1.6)
- English language translation of cluster computing related classes (prealpha)
- Renaming some class files to proper names
- Added minor documentation
Changelog(v1.1.9)
- Now array of user-defined structs can be wrapped by a ClArray of type byte, example:
xyzoGPU = ClArray<byte>.wrapArrayOfStructs(vertices);
in the upper example, vertices is an array of Vector3(this is from a working Unity example).
This automatically sets the "numberOfElementsPerWorkItem" property accordingly with the bytes per struct so no need to set it but can get it to see.
Beware! OpenCL treats float3(kernel-side struct) differently for each vendor. So use Vector3 and similar 3D elements as pure floats and multiply the indexer by 3 and add 1 for y, 2 for z (x is already + zero).
Changelog(v1.2.0)
- Device to device pipelining feature added. This lets develoeprs use multiple GPUs concurrently on different kernels that are to be run consecutively. Double buffering is handled automatically to overlap all pipeline stages compute and data movement operations to hide their latencies. Here is its demonstration: https://www.youtube.com/watch?v=pNIBzQvc4F8 and here is the wiki page about it: https://github.com/tugrul512bit/Cekirdekler/wiki/Pipelining:-Device-to-Device
- Removed "Copy Memory" dependency, Now its even more adaptable to Unity Game Engine (still Windows).
- Added `normalizedGlobalRangesOfDevices(int id)` and `normalizedComputePowersOfDevices()` to ClNumberCruncher to query some performance info from client code directly(without needing to set performanceReport flag)
Here is a gif showing how the pipeline works:
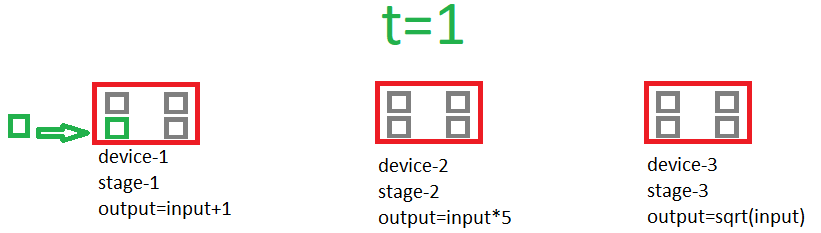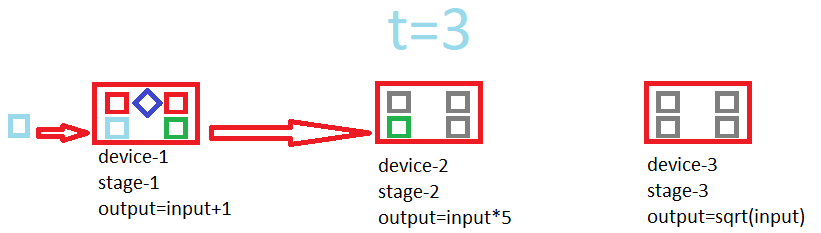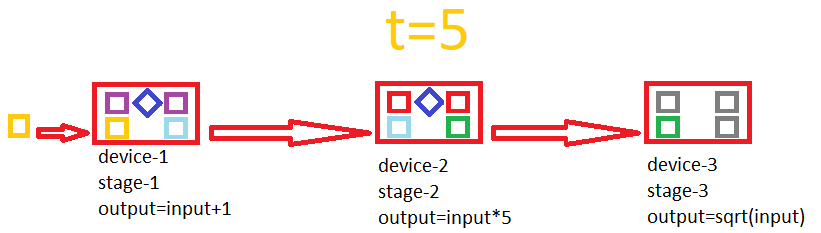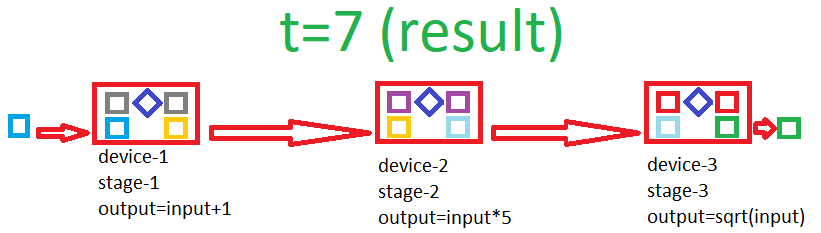
Example of building a pipeline:
Single stage to compute x+1:
Hardware.ClDevices gpu1 = Hardware.ClPlatforms.all().devicesWithMostComputeUnits()[0];
Pipeline.ClPipelineStage add = new Pipeline.ClPipelineStage();
add.addDevices( gpu1);
ClArray<float> inputArrayGPU1 = new ClArray<float>(1024);
ClArray<float> outputArrayGPU1 = new ClArray<float>(1024);
add.addInputBuffers(inputArrayGPU1);
add.addOutputBuffers(outputArrayGPU1);
add.addKernels(@"
__kernel void vecAdd(__global float * input, __global float * output)
{
int id=get_global_id(0);
output[id]=input[id]+1.0f;
}", "vecAdd", new int[] { 1024 }, new int[] { 256 });
single stage to compute x*5:
Hardware.ClDevices gpu2 = Hardware.ClPlatforms.all().devicesWithMostComputeUnits()[1];
Pipeline.ClPipelineStage mul = new Pipeline.ClPipelineStage();
mul .addDevices( gpu2);
ClArray<float> inputArrayGPU2 = new ClArray<float>(1024);
ClArray<float> outputArrayGPU2 = new ClArray<float>(1024);
mul .addInputBuffers(inputArrayGPU2);
mul .addOutputBuffers(outputArrayGPU2);
mul .addKernels(@"
__kernel void vecMul(__global float * input, __global float * output)
{
int id=get_global_id(0);
output[id]=input[id]*5.0f;
}", "vecMul", new int[] { 1024 }, new int[] { 256 });
binding two stages together and creating the pipeline:
add.prependToStage(mul);
var pipeline = add.makePipeline();
pushing data to pipeline, getting result to an array:
if(pipeline.pushData(new object[] { arrayToGetData }, new object[] { arrayToReceiveResult }))
{
Console.WriteLine("Needs M*2+1 iterations");
Console.WriteLine("Extra client arrays for both inputs and outputs of pipeline");
Console.WriteLine("First result is ready!");
}
if(pipeline.pushData())
{
Console.WriteLine("Needs M*2-1 iterations");
Console.WriteLine("input of first stage and output of last stage are directly accessed");
}
now it computes (x+1)*5 for each element of array and uses two gpus concurrently, one per stage and moving data at the same time with help of double buffering.
Changelog(v1.2.1)
- decreased command queue consumption per "device to device pipeline stage" to have room for more stages.
Changelog(v1.2.2)
-
Now device to device pipeline stages can be initialized in buildPipeline() method automatically with the parameters given in this method:
stage.initializerKernel("kernelName", new int[] { N }, new int[] { 256 });
Changelog(v1.2.3)
-
Multiple kernel names in "device to device pipeline stages" can be grouped with "@" separator instead of " ",",",";" separators so they read inputs from host only once before first kernel and write output to host only once after last kernel. Without "@", each kernel reads and writes inputs and outputs, making "multiple kernel stage" slower.
"@" separated kernels run as a single kernel so all use single global-local range value.
"a@b@c" N : 256 1 read 1 write
"a b@c" N,M : 256,128 2 reads 2 writes
Changelog(v1.2.4)
Changelog(v1.2.5)
Changelog(v1.2.6)
Changelog(v1.2.7)
Changelog(v1.2.8)
-
unnecessary clSetKernelArg issues are reduced
added ClArray.writeAll to get result arrays as a whole instead of just a number of elements. Similar to non-partial reads by ClArray.read = true and ClArray.partialRead=false. If multiple GPUs are used, each GPU writes only 1 of result arrays(instead of writing same array, undefined behavior).
a C# char array bug fixed(for not getting true pointer to its data when passed to C++)
Enqueue mode performance query bug fixed(was not giving exact timing) now its queryable by clNumberCruncher.lastComputePerformanceReport()
Changelog(v1.2.9)
For example, this kernel gains %10 performance by setting readOnly for first parameter and writeOnly for second parameter
__kernel void test(const __global float * data,__global float * data2)
{
int id=get_global_id(0);
for(int i=0;i<50;i++)
data2[id]=sqrt(data[id]);
}
Changelog(v1.2.10)
- Added async enqueue mode to number cruncher. This lets some operations to be overlapped in timeline to save even more time and push the GPU to its limits. Maximum of 16 queues can be used this way and works with only single device(per ClNumberCruncher instance). Customized "pipelines" can be built with this.
Changelog(v1.2.11 and v1.2.12)
Matrix multiplication pipeline example:
https:
Image processing(blur, rotate, resize, blend) pipeline example:
https:
Changelog(v1.3.2)
- added multiple kernel instance generation based on compute-id + kernel name (decreases number of clsetkernelarg() calls and makes async queue computing with same kernel name and different parameters)(for tiled computing by task pool + device pool)
- Added task (to compute() later instead)
- Added task pool and device pool features (non separable kernels are distributed to devices with greedy algorithm)
Changelog v1.3.3 - v1.4.1
- added callback option to tasks which helps communicating early, asynchronously with other parts of C#
- optimized pool for performance
- some bug fixes
- OpenCL 2.0 dynamic parallelism support. Now parent kernels can enqueue child kernels. Device-queue initialization(with queue size = (preferred+max)/2) is handled automatically.
Smoothed k-means clustering example video, using OpenCL 2.0 dynamic parallelism feature:
https:
Comparison of performance of "batch computing" feature versus "pipelining" and "load balancing":
https:
Grainsize revisited:
- Each device has to have a minimum of 1 grain. Then, if any grains left, those are placed by load-balancer.
- Enabling N-blob-pipelining multiplies grain size by N(4 by default).
- Increasing local range(workgroup size or number of workitems per local-memory-sharing-group) also increases grain size
- Trading grains between devices are fast for the first 10 iterations, then smoothing is enabled so sudden spikes of performances of individual devices can't corrupt it.
- Global offset parameter doesn't affect number of workitems or any workitem based bounds check but it affects array out of bounds and developer/user needs to check it before running(probably in cluster)
Note: there are some classes that have "cluster" in their names, those are in prealpha stage and works unoptimized way and not translated to english(yet). The global offset parameter was being used by those classes.
Note2: number cruncher object allocates 16 queues, which may not be appropriate for some devices and may give CL_OUT_OF_RESOURCES or CL_OUT_OF_HOST_MEMORY even if RAM is not full. Works for AMD and INTEL, didn't try with NVIDIA. I didn't even get close to any FPGA, I'd like to. I heard their opencl compile times are hours!
Note3: ClNumberCruncher doesn't check if compiler is available, so, ClNumberCruncher will be added that control logic in future so it will be more thread-safe. For now, build all ClNumberCruncher instances serially, with locks. Compute methods of different ClNumberCruncher instances are also thread-safe but same instance can't be used in different threads for compute method.
Note4: All devices, platforms, everything releases their C++(unmanaged) objects upon destruction so user may not need to dispose() them ever(unless some tight memory control is needed)
For latest version, please visit github repository and feel free to add an "issue" if you have a problem related to Cekirdekler API.
Thank you for your time.
Points of Interest
If you have written a complete image-resizer with this, you will have instant-speedup whenever you put another GPU into case, whether it is same vendor or not, same tier or not. Even overclocking one of the cards will have positive effect on performance, if the image is big enough to have a finer-grained load balancing.
History
Will keep adding more here after each new feature added in github.

