Overview
Part 1 introduced you to OpenCV and its Emgu CV wrapper library plus showed the easiest way to create Emgu project in Visual Studio 2017. Part 2 was all about grabbing frames from video file. The third (and last) episode focuses on image transformations and contour detection...
If case you forgot: here's the complete code sample on GitHub (focus on Program.cs file as it contains all image acquisition and processing code). This is the app in action:
STEP 4: Difference Detection and Noise Removal
In the previous post, you've seen that VideoProcessingLoop method invoked ProcessFrame for each frame grabbed from video, here's the method:
private const int Threshold = 5;
private const int ErodeIterations = 3;
private const int DilateIterations = 3;
private static Mat rawFrame = new Mat();
private static Mat backgroundFrame = new Mat();
private static Mat diffFrame = new Mat();
private static Mat grayscaleDiffFrame = new Mat();
private static Mat binaryDiffFrame = new Mat();
private static Mat denoisedDiffFrame = new Mat();
private static Mat finalFrame = new Mat();
private static void ProcessFrame
(Mat backgroundFrame, int threshold, int erodeIterations, int dilateIterations)
{
CvInvoke.AbsDiff(backgroundFrame, rawFrame, diffFrame);
CvInvoke.CvtColor(diffFrame, grayscaleDiffFrame, ColorConversion.Bgr2Gray);
CvInvoke.Threshold(grayscaleDiffFrame, binaryDiffFrame, threshold, 255, ThresholdType.Binary);
CvInvoke.Erode(binaryDiffFrame, denoisedDiffFrame, null,
new Point(-1, -1), erodeIterations, BorderType.Default, new MCvScalar(1));
CvInvoke.Dilate(denoisedDiffFrame, denoisedDiffFrame, null,
new Point(-1, -1), dilateIterations, BorderType.Default, new MCvScalar(1));
rawFrame.CopyTo(finalFrame);
DetectObject(denoisedDiffFrame, finalFrame);
}
AbsDiff and CvtColor
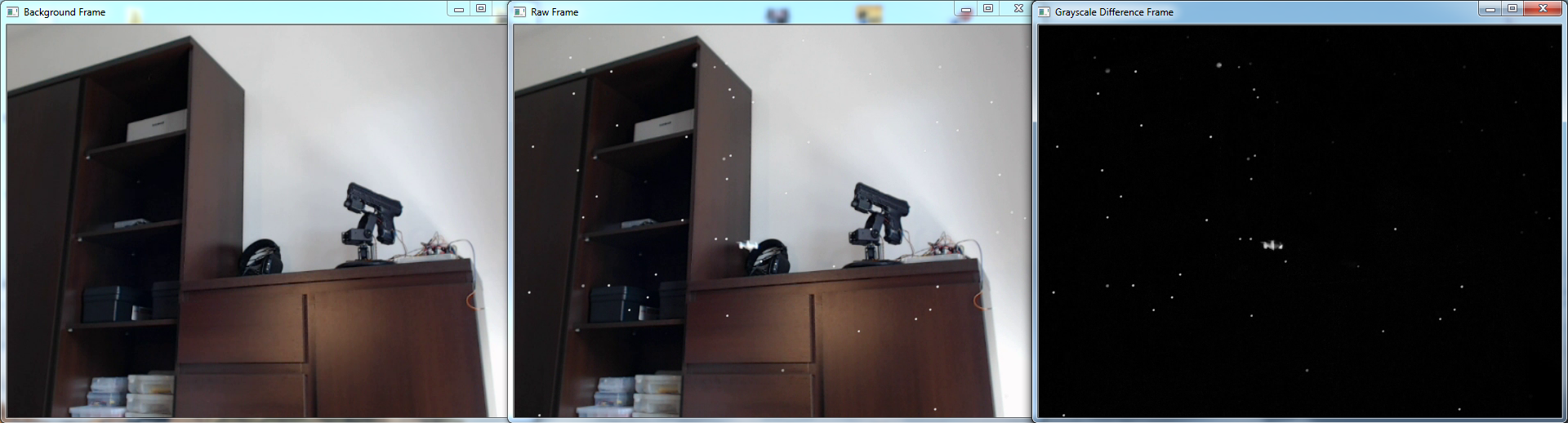
First the current frame (kept in rawFrame) is compared to background with CvInvoke.AbsDiff. In other words: current frame is subtracted from background frame pixel by pixel (absolute value is used to avoid negative results). After that, the difference image is converted into grayscale with CvInvoke.CvtColor call. We care only about overall pixel difference (not its individual blue-green-red color components). The whiter the pixel is, the more its color has changed... Take a look at the below picture showing background frame, current frame and the grayscale difference:
Threshold
Grayscale image is changed into an image with only black and white (binary) pixels with the use of CvInvoke.Threshold. Our intention is to mark changed pixels as white. Threshold value allows us to control change detection sensitivity. Below, you can see how different thresholds produce various binary results:

First image (left) was produced with Threshold = 1, so even the slightest change got marked - such image is not a suitable input for contour detection. Image in the middle used Threshold = 5. Drone position is clearly marked and smaller white pixel zones can be removed with erosion... Last image (right) is the result of setting Threshold to = 200. This time, sensitivity was too low and we got just a couple of white pixels.
Erode and Dilate
It's hard to find a threshold that gives desired difference detection for each video frame. If threshold is too low, then too many pixels are white, if it's too high then the drone might not be detected at all... The best is to pick a threshold which marks the change we need even if we get a bit of undesired white spots as these can be safely removed with erosion followed by dilation. When combined, these two operations create so called opening operation which can be treated as a noise removal method. Opening is a type of morphology transformation (read this article to learn more about them). These operations work by probing pixel neighborhood with a structuring element (aka kernel) and deciding pixel value based on the values found in the neighborhood...
CvInvoke.Erode is meant to simulate a physical process in which object area is reduced due to destructive effects of its surroundings. Detailed behavior depends on the parameters passed (structuring element, anchor, border type - never mind, this is a beginners guide, right?) but the general idea is like this: if pixel is white but has a black pixel around it, then it should become black too. The more erode iterations are run, the more white pixel zones get eaten away. Here's an example of image erosion:
On the left is the input image and on the right we have the result of erosion which used structuring element in the shape of a 3x3 square (this is the default value used when null is passed for element parameter in Erode invocation). The value of output pixel was decided by probing all neighboring pixels and checking for their minimal value. If a pixel was white in the input image but had at least one black pixel in its immediate surroundings, then it became black in the output image.
If erosion is used wisely, we can get rid of irrelevant white pixels. But there's a catch: the white pixel zone that marks the drone is reduced too. Don't worry: dilation is going to help us! Just like pupils in your eyes are enlarged (dilated) when it gets dark, the white pixel zones that survived erosion can get enlarged too... Again, details vary by CvInvoke.Dilate parameters but generally speaking: if pixel is black but has white neighbor, it gets white too. The more iterations are run, the more white zones are enlarged. This is an example of dilation:
On the left, we have the same input image as used in erosion example and on the right, we can see the result of single call to Dilate method (again with 3 by 3 kernel matrix). Notice how pixel obtains the maximal value of its surroundings (if any neighboring pixel is white, it becomes white too)...
Erosion followed by dilation is such a common transformation that OpenCV has methods that combine the two into one opening operation but using separate Erode and Dilate calls gives you a bit more control. Below, you can see how opening cleared the noise and enhanced white spot that marks drone position:
STEP 5: Contour Detection
Once all the above image preparation steps are done, we have a binary image which is suitable input for contour detection provided by DetectObject method:
private static void DetectObject(Mat detectionFrame, Mat displayFrame)
{
using (VectorOfVectorOfPoint contours = new VectorOfVectorOfPoint())
{
CvInvoke.FindContours(detectionFrame, contours, null,
RetrType.List, ChainApproxMethod.ChainApproxSimple);
if (contours.Size > 0)
{
double maxArea = 0;
int chosen = 0;
for (int i = 0; i < contours.Size; i++)
{
VectorOfPoint contour = contours[i];
double area = CvInvoke.ContourArea(contour);
if (area > maxArea)
{
maxArea = area;
chosen = i;
}
}
MarkDetectedObject(displayFrame, contours[chosen], maxArea);
}
}
}
The method takes binary difference image (detectionFrame) on which contours will be detected and another Mat instance (displayFrame) on which detected object will be marked (it's a copy of unprocessed frame)...
CvInvoke.FindContours takes the image and runs contour detection algorithm to find boundaries between black (zero) and white (non-zero) pixels on 8-bit single channel image - our Mat instance with the result of AbsDiff->CvtColor->Threshold->Erode->Dilate suites it just fine!
A contour is a VectorOfPoint, because image might have many contours, we keep them inside VectorOfVectorOfPoint. In case many contours get detected, we want to pick the largest of them. This is easy thanks to a CvInvoke.ContourArea method...
Read the docs about contour hierarchy and approximation methods if you are curious about RetrType.List, ChainApproxMethod.ChainApproxSimple enum values seen in CvInvoke.FindContours call. This is a good read too...
STEP 6: Drawing and Writing on a Frame
Once we've found the drone (that is we have a contour that marks its position), it would be good to present this information to the user. This is done by MarkDetectedObject method:
private static void MarkDetectedObject(Mat frame, VectorOfPoint contour, double area)
{
Rectangle box = CvInvoke.BoundingRectangle(contour);
CvInvoke.Polylines(frame, contour, true, drawingColor);
CvInvoke.Rectangle(frame, box, drawingColor);
Point center = new Point(box.X + box.Width / 2, box.Y + box.Height / 2);
var info = new string[] {
$"Area: {area}",
$"Position: {center.X}, {center.Y}"
};
WriteMultilineText(frame, info, new Point(box.Right + 5, center.Y));
}
The method uses CvInvoke.BoundingRectangle to find minimal box (Rectangle) that surrounds the entire contour. Box is later drawn with a call to CvInvoke.Rectangle. The contour itself is plotted by CvInvoke.Polylines method which takes a list of points that describe the line. You can notice that both drawing methods receive drawingColor parameter, it is an instance of MCvScalar defined this way:
private static MCvScalar drawingColor = new Bgr(Color.Red).MCvScalar;
Bgr structure constructor can take 3 values that define its individual color components or it can take a Color structure like in my example.
Important: Point, Rectangle and Color structures come from System.Drawing assembly which by default is not included in new console application template so you need to add reference to System.Drawing.dll yourself.
Information about detected object location is written by WriteMultilineText helper method (the same method is used to print information about frame number and processing time). This is the code:
private static void WriteMultilineText(Mat frame, string[] lines, Point origin)
{
for (int i = 0; i < lines.Length; i++)
{
int y = i * 10 + origin.Y;
CvInvoke.PutText(frame, lines[i], new Point(origin.X, y),
FontFace.HersheyPlain, 0.8, drawingColor);
}
}
In each invocation of CvInvoke.PutText method, y coordinate of the line is increased so lines are not colliding with each other...
This is how frame captured from video looks like after drawing and writing is applied:
STEP 7: Showing It All
In part 1, you've seen that CvInvoke.Imshow method can be used to present a window with an image (Mat instance). Below method is called for every video frame so the user has a chance to see various stages of image processing and the final result:
private static void ShowWindowsWithImageProcessingStages()
{
CvInvoke.Imshow(RawFrameWindowName, rawFrame);
CvInvoke.Imshow(GrayscaleDiffFrameWindowName, grayscaleDiffFrame);
CvInvoke.Imshow(BinaryDiffFrameWindowName, binaryDiffFrame);
CvInvoke.Imshow(DenoisedDiffFrameWindowName, denoisedDiffFrame);
CvInvoke.Imshow(FinalFrameWindowName, finalFrame);
}
Displaying intermediate steps is a great debugging aid for any image processing application (I didn't show separate windows for erosion and dilation because only 6 windows of my test video fit on full HD screen):
Summary
This three part series assumed that you were completely new to image processing with OpenCV/Emgu CV. Now you have some idea what these libraries are and how to use them in Visual Studio 2017 project while following a coding approach recommended for version 3 of the libs...
You've learned how to grab frames from video and how to prepare them for contour detection using fundamental image processing operations (difference, color space conversion, thresholding and morphological transformations). You also know how to draw shapes and text on an image. Good job!
Computer vision is a complex yet very interesting topic (its importance is constantly increasing), you've just made a first step in this field - who knows, maybe one day, I will ride in autonomous vehicle powered by your software? :)

