It's not always what you think it is.
Once in a while, I needed to plug some third-party module into our project. Despite the fact that Spring makes it extremely simple in terms of design, an actual plugging may give you a lot of headache at the moment you realize it does not behave as you expect. The trick was that the module had XML context configuration, while we used to employ JavaConfig...
In this part of the series, we shall review Spring's bean loading process in detail for both XML and Annotation contexts. Bean overriding, extension points, custom per-project defaults, and all this stuff are actually not that hard if you know where to look.
This article describes processes usually happening around bean factory creation and post-processing. Here's where we are relating to the previous article (https://www.codeproject.com/Articles/1195578/Spring-Context-Internals-Part-Refresh):
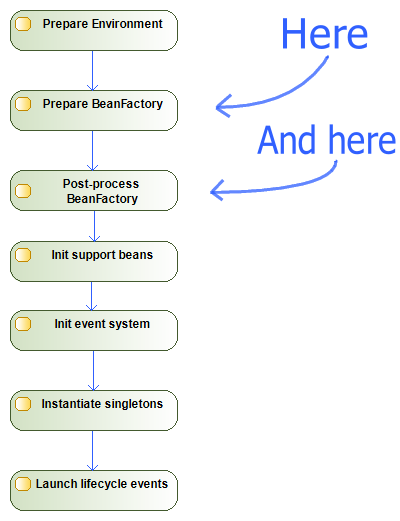
At the bottom of this text, there is a schema that structurally summarizes all the components described today. You may use it to navigate yourself back whenever you're lost in the article.
Bean Definition Reader Concept
Spring's context configuration parsing infrastructure is usually detached from contexts themselves by an entity called bean definition reader. This reader accepts a single bean definition source type (e.g., an XML context descriptor or a @Configuration class instance) and encapsulates all the logic related to this source.
On BeanDefinitionReader Interface
Whilst there is a BeanDefinitionReader interface, not every reader implements it. An AnnotatedBeanDefinitionReader is a fine example. The reason latter one doesn't is that the interface was kind of poorly designed to only represent resource-based contexts. It is centered around Resource class, which is redundant in case of JavaConfig.
Bean definition usually provides a method for parsing bean source, be so a Resource instance, or a pre-loaded Class. There are 5 standard readers:
XmlBeanDefinitionReader - hard-coded into XML contextsAnnotationBeanDefinitionReader - hard-coded into Annotation contextsConfigurationClassBeanDefinitionReader - invoked by ConfigurationClassPostProcessor, parses @Bean methodsGroovyBeanDefinitionReader - hard-coded into GenericGroovyApplicationContextPropertiesBeanDefinitionReader - can only be used externally (see below)
Since there's no significant operational difference between XML- and Groovy-based parsers, we shall skip Groovy one.
Property-based Bean Definition Reader
In present days, when you need a simple context definition without all that excessive XML hassle, you take JavaConfig. However, long before JavaConfig, there was an even more simple approach. We can actually describe our context... in a property file:
transport.(class)=me.jtalk.example.TcpTransport
# We take constructor parameters, only indexed access is supported
transport.$0=127.0.0.1
transport.$1=8080
# Access property by value
transport.description=A transport to some HTTP service on port 8080
# We set it to prototype scope
transport.(scope)=prototype
requester.(class)=me.jtalk.example.PollingRequester
requester.timeout=1000
# Access property by reference to another bean
requester.transport(ref)=transport
The context above is somehow equivalent to:
= "1.0"= "UTF-8"
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd">
<bean name="transport"
class="me.jtalk.example.TcpTransport"
scope="prototype">
<constructor-arg index="0">127.0.0.1</constructor-arg>
<constructor-arg index="1">8080</constructor-arg>
<property name="description">A sample transport definition</property>
</bean>
<bean name="requester"
class="me.jtalk.example.PollingRequester">
<property name="timeout">1000</property>
<property name="transport" ref="transport"/>
</bean>
</beans>
And imagine that: this context definition approach is so rare there's literally no matching context type associated with it! Spring itself uses it for WebMVC's resource bundles parsing, but if we want to make a real runtime context from it, we need to make it the hard way:
GenericApplicationContext ctx = new GenericApplicationContext();
PropertiesBeanDefinitionReader reader
= new PropertiesBeanDefinitionReader(ctx);
reader.loadBeanDefinitions("classpath:/context.properties");
ctx.refresh();
This property-based context is rather simple and has no extension points. It also does not participate in any importing relations. Its only purpose seems to be that it is, well, funny. On this high note, let's proceed to where the REAL work's being done!
XML Bean Definition Reader
There is a family of XML-based contexts from Spring's internal point of view, including ClassPathXmlApplicationContext, WebXmlApplicationContext, and so on. By oversimplifying things a little, we might say that:
XmlApplicationContext = AbstractAC + XmlBeanDefinitionReader
The abstract context implementation is something we have already reviewed quite precisely in the previous article, so we shall now focus on that reader thing.
About Refreshable Contexts
For most of context implementations, usually derived from GenericApplicationContext, it is impossible to load configuration more than once: successive refresh() calls just throw an exception with no gain. Unlike, a refreshable context can be hot-reloaded in runtime, allowing us to change whatever is configured there. While refreshability is kind of useless when speaking of application's primary context because of its kill-all-and-start-again stance, it might come in handy for small per-component contexts to be reloaded on demand.
XML application contexts is the only major refreshable context family. Both Annotation-config and Groovy ones are not.
The XmlBeanDefinitionReader itself is not that important: it just provides basic configuration capabilities with resource handling and thread safety. All the actual work is done by BeanDefinitionDocumentReader, capable of actual XML-to-BeanDefinition conversion.
About Document Reader Configuration
Despite the fact that XmlBeanDefinitionReader implements all the proper interfaces and provides a bunch of custom setters, it is instantiated inside an AbstractXmlApplicationContext by a simple "new" invocation, and it is thus impossible to configure it without providing your own context implementation.
BeanDefinitionDocumentReader
The reader is quite straight-forward: it just parses XML, detects its hard-coded tags, and delegates custom tags to a pre-configured set of resolvers. The list of these hard-coded tags include:
<profile>: Check if this XML is included into a specified profile<bean>: Parse bean definition<beans>: Parse subset of bean definitions<alias>: Register bean definition alias<import>: Process another configuration file
About Nested <beans> Element
Sometimes, we need to apply global configuration options (e.g. profile) to a subset of bean definitions. A fine example would be to provide two sets of bean implementations based on profile, without messing with multiple XML configurations. <beans> allows us to configure this in a single XML descriptor.
Spring reads tags one by one, overriding bean definitions when necessary. <import> statements are handled recursively: the reader calls itself with a new resource location. Spring also keeps track of resources already being loaded to avoid cyclic dependencies.
About Cyclic Dependencies Detection
Even though Spring does keep track of already loaded resources, it will handle two successive import clauses with the same resource. Cyclic dependencies detection works like a call stack: a locator of a resource currently being imported is stored into a set, and removed after importing is done. It is thus unwise to duplicate import clauses relying on this mechanism.
Here's a simplified example of this "hard-coded only" configuration. Seems poor, doesn't it?
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd">
<import resource="classpath:/properties.xml"/>
<bean name="myService" class="me.jtalk.spring.example.MyService">
<constructor-arg ref="transport"/>
</bean>
<alias name="myService" alias="myTransportService"/>
<beans profile="integration">
<bean name="transport"
class="me.jtalk.spring.example.IntegrationTransportImpl"/>
</beans>
<beans profile="production">
<bean name="transport" class="me.jtalk.spring.example.TransportImpl"/>
</beans>
</beans>
Custom XML Handlers
You might've noticed that the subset of tags mentioned above is not anyhow sufficient. In our actual descriptors, we usually have a lot of stuff including <aop:scoped-proxy>, <context:annotation-config>, <tx:annotation-driven>, <util:map>, and so on. Even though these tags are provided by Spring Framework, the "context" code base is unaware of them. There is a magic bringing these to life, and this magic is called NamespaceHandlerResolver.
You might've heard of a file named spring.factories: the way Boot's auto-configuration works - we provide a file into our classpath with a pre-defined name, and from that file, Spring can determine whatever it needs to bootstrap a related subsystem. XML parser works in a similar fashion: there is a contracted name spring.handlers with mappings between schema names and handler classes, and each handler is capable of processing the element specified:
http\://www.springframework.org/schema/aop=\
org.springframework.aop.config.AopNamespaceHandler
http\://www.springframework.org/schema/c=\
org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler
http\://www.springframework.org/schema/p=\
org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
http\://www.springframework.org/schema/util=\
org.springframework.beans.factory.xml.UtilNamespaceHandler
If I were an XML context user...
... I would really keep the above in mind. The common downside of all that managed Java thing is that you have no way of just tracking the entity you're interested in back to the one that defines its behaviour. You can hardly track annotations, and you have almost no means of tracking this extension magic. An IDE could help if you remember to make a full-text search amongst all the libraries with your xmlns value.
We can have as many of these files in our classpath as needed, all of them will be parsed and added into context's NamespaceHandler registry. When BeanDefinitionDocumentReader discovers an unknown tag, it resolves its namespace and then looks a corresponding handler up in that registry.
Once a handler is found, all the parsing is delegated to its corresponding method. There are two methods in NamespaceHandler, related to a pair of corresponding element handling modes BeanDefinitionDocumentReader supports: bean parsing and delegation.
NamespaceHandler actually has a third method named init(), but it is kind of useless and self-describing.
Although NamespaceHandler can be used directly, it is usually better to extend NamespaceHandlerSupport instead. It provides a handy way of registering per-tag-name bean registrars and decorators:
public class SomeNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("herp-bean", new HerpBeanParser());
registerBeanDefinitionParser("derp-bean", new DerpBeanParser());
registerBeanDefinitionDecorator("proxified", new ProxifierDecorator());
}
}
A thoughtful reader might find herp/derp-bean to be similar to util:map and util:list and myns:proxified to mimic aop:scoped-proxy.
Bean parsing means handling of a top-level bean definition. Unintuitive, but bean parsing is not required to always end up in bean definition creation. Some Spring-provided bean parsers, like context:annotation-config's one, never produce any bean definition. Instead, they use their ParserContext argument for adjusting BeanDefinitionRegistry settings and registering annotations-related post-processors without actual bean creation. They thus return null instead of a produced bean definition, like a simplified <context:annotation-config> parser below:
public class AnnotationConfigBeanDefinitionParser implements BeanDefinitionParser {
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionRegistry registry = parserContext.getRegistry();
registerAnnotationConfigProcessors(registry);
return null;
}
}
On weird "return null" thing
Spring actually has no use for top-level bean definition parser's result. It will be gently abandoned around DefaultBeanDefinitionDocumentReader#parseBeanDefinitions and serves no purpose. However, it is needed for nested bean definitions. It is because of Spring's funny feature of declaring beans inside <constructor-arg> and <property> elements: if we allow their parsers to return null bean definitions, we'll end up having nothing to inject.
Spring Handlers Practice
Let's play some spring handlers. Our step-by-step plan will be to:
- Create our own
namespace with XSD - Write a handler for that
namespace - Match them by providing custom spring.handlers to classpath
We'll invent our very own (quite useful, of course) logger bean registration system.
Well, considering that juniors may be reading this, I should explicitly proclaim the parenthesized part of the previous sentence being ironical.
All Spring namespaces look quite the same: these start from http://www.springframework.org/schema gibberish ending with a sub-namespace name, like http://www.springframework.org/schema/context, http://www.springframework.org/schema/beans, or http://www.springframework.org/schema/util. The XSD is not required to match to an actual HTTP address, so we can just provide a fake reasonable name, like http://xmlns.jtalk.me/schema/logger-bean.
As XSD infrastructure and format are out of scope of this article, here's an unexpected transition right to the end:
="1.0"="UTF-8"="yes"
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://xmlns.jtalk.me/schema/logger-bean"
elementFormDefault="qualified">
<xs:element name="log-bean">
<xs:complexType>
<xs:attribute name="type">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="slf4j"/>
<xs:enumeration value="jul"/>
<xs:enumeration value="jcl"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="name">
<xs:simpleType>
<xs:restriction base="xs:string"/>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="package">
<xs:simpleType>
<xs:restriction base="xs:string"/>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
The schema above will match into something like:
<log:log-bean name="slfLogger"
package="me.jtalk.spring.my.business.package"
type="slf4j" />
Now, we make a handler. Watch for hints:
public class LoggerBeanHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("log-bean", new LoggerParser());
}
@Getter
@RequiredArgsConstructor
private enum LogType {
SLF4J(Logger.class, LoggerFactory::getLogger),
JCL(Log.class, LogFactory::getLog),
JUL(java.util.logging.Logger.class, java.util.logging.Logger::getLogger);
private final Class loggerType;
private final Function<string object=""> loggerFactory;
}
private static class LoggerParser implements BeanDefinitionParser {
@Override
public BeanDefinition parse(Element element,
ParserContext parserContext) {
LogType type = LogType.valueOf(element.getAttribute("type")
.toUpperCase());
String loggerPackage = element.getAttribute("package");
BeanDefinition bd = createFactoryBeanDefinition(type, loggerPackage);
String beanName = parseBeanName(element,
bd,
parserContext.getReaderContext());
parserContext.getRegistry().registerBeanDefinition(beanName, bd);
return bd;
}
private BeanDefinition createFactoryBeanDefinition(LogType type,
String loggerPackage) {
AbstractBeanDefinition bd = BeanDefinitionBuilder
.genericBeanDefinition(LoggerFactoryBean.class)
.getBeanDefinition();
ConstructorArgumentValues args = new ConstructorArgumentValues();
ConstructorArgumentValues.ValueHolder logTypeArg
= new ConstructorArgumentValues.ValueHolder(
type.getLoggerType());
logTypeArg.setName("loggerClass");
args.addGenericArgumentValue(logTypeArg);
ConstructorArgumentValues.ValueHolder logSupplierArg
= new ConstructorArgumentValues.ValueHolder(
(Supplier)()
-> type.getLoggerFactory().apply(loggerPackage));
logSupplierArg.setName("loggerSupplier");
args.addGenericArgumentValue(logSupplierArg);
bd.setConstructorArgumentValues(args);
return bd;
}
private String parseBeanName(Element element,
BeanDefinition bd,
XmlReaderContext readerContext) {
if (element.hasAttribute("name")) {
return element.getAttribute("name");
} else {
return readerContext.generateBeanName(bd);
}
}
}
private static class LoggerFactoryBean<t> extends AbstractFactoryBean<t> {
private final Class<t> loggerClass;
private final Supplier<t> loggerSupplier;
public LoggerFactoryBean(Class<t> loggerClass, Supplier<t> loggerSupplier) {
this.loggerClass = loggerClass;
this.loggerSupplier = loggerSupplier;
}
@Override
public Class<?> getObjectType() {
return loggerClass;
}
@Override
protected T createInstance() throws Exception {
return loggerSupplier.get();
}
}
}
Phew! Now, as we have seemingly suffered enough, a spring.handlers part will be short:
http\://xmlns.jtalk.me/schema/logger-bean=\
me.jtalk.spring.xmlhandler.LoggerBeanHandler
We just match our namespace with a handler definition above. That's all, we can now test our approach:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:log="http://xmlns.jtalk.me/schema/logger-bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://xmlns.jtalk.me/schema/logger-bean
log-bean-1.0.xsd">
<log:log-bean name="slfLogger"
package="me.jtalk.spring.logger.slf"
type="slf4j" />
<bean class="me.jtalk.spring.xmlhandler.LogTester">
<constructor-arg name="slj" ref="slfLogger"/>
<constructor-arg name="jul">
<log:log-bean package="me.jtalk.spring.logger.jul" type="jul" />
</constructor-arg>
</bean>
</beans>
You can do any testing inside LogTester implementation. I just print some gibberish into different log engines, nothing special.
Handling @Configuration Classes
There is a significant part of XML context design we have not discussed yet. @Bean-annotated methods were designed for Annotation-config contexts to be able to employ FactoryBean-alike attitude with all due flexibility. As a backward compatibility change, these methods were enabled to work from XML context: you can just declare any bean with @Bean-annotated method inside your XML context, and all these methods will be instantiated at runtime, performing all due checks. An enclosing XML can override bean definitions declared this way, and everything will work as expected. But how does Spring do it? Is there a custom tag parser? A hard-code?
A Fine Exercise
As an exercise, an engaged reader can now stop reading, remember <context:annotation-config>, and make a fine detective work by employing whatever was discussed above. The answer goes below.
The answer lies inside a <context:annotation-config> handler. We have already taken a look to a simplified context namespace handler above. Here it is, for your convenience:
public class AnnotationConfigBeanDefinitionParser implements BeanDefinitionParser {
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionRegistry registry = parserContext.getRegistry();
registerAnnotationConfigProcessors(registry);
return null;
}
}
For them who have made it to the end of the first half of the previous article, it should all make sense now. All the annotation-config element does is register a bunch of registry post-processors enabling various annotations handling mechanisms. Our pal is called ConfigurationClassPostProcessor, and it, aside from a lot of @Configuration instrumentation and importing, does that @Bean parsing by redirecting it to a ConfigurationClassBeanDefinitionReader instance. So, if we run our XML context from the XML below, our flow will be:
@Configuration
public class Config {
@Bean
public String myBean() {
return "JavaConfig";
}
}
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.0.xsd">
<context:annotation-config/>
<bean class="Config"/>
<bean name="myBean" class="java.lang.String">
<constructor-arg>XmlConfig</constructor-arg>
</bean>
</beans>
Since post-processors are run after all the XML parsing is done (see "and here" at the heading schema of this article), they technically must override any bean definitions inside a context despite actual XML tags order. However, it is not the case here: Spring does not allow @Bean methods to override parent XML's work with a magical method ConfigurationClassBeanDefinitionReader.isOverriddenByExistingDefinition. It works by disallowing several bean definitions to be overridden, except:
- Ones that were loaded from
@Configuration class not within the same inheritance hierarchy (i.e., not from current class' descendant) - Component-scanned beans
- Support and infrastructure beans
Our bean below does not match any of the criteria above, so it cannot override XML-provided bean even though it is parsed much later.
On Support and Infrastructure Beans
Spring employs bean definition's role parameter as a mark of what does this bean does in terms of business-related application life-cycle. Aside from application role, which relates to business activities, Spring also supports infrastructure and support beans. First, take care of Spring's internals and are irrelevant to business beans, and latter provide reasonable assistance around third-party beans registration, but are not used in business code directly.
An interesting part here is that Spring will not override XML-provided beans even if they are registered before our @Configuration class. Spring has no information on bean registration order here. Here comes the rule of thumb of Spring inter-source bean processing: you can only override @Bean by XML, not the other way around.
When I Was Younger
We used to have @ImportResource annotation for configuring Spring Batch in our JavaConfig application. Batch was an external project not yet officially acclaimed to be part of Spring Framework, and we also wanted to replace one of its service beans with our implementation. Bug squashing, all that thing. We tried to override these XML-provided beans within our @Configuration class... with no luck. It took me a day to derive some sort of tendency with these imports, it took me a week to end up with a theory of why is it what it is, and it took almost a year to replace that theory with actual understanding which, to be honest, differs quite a lot.
Bean override suffers from a long lasting backward compatibility trail, making it hard to introduce new functionality seamlessly. The rule of thumb above can save you a lot of effort.
Annotation Bean Definition Reader
Annotation-driven context was an attempt to move applications away from XML metadata. Enterprise JavaBeans had long before made XML dependency descriptor a synonym of pain, and people thus started looking for more lightweight and stable IoC containers. The JavaConfig project was an attempt to reduce amount of declarativeness by replacing XML with @Configuration classes. It was merged into Spring 3.0, and it would be enhanced with component scanning capability as per Spring 3.1.
Even though JavaConfig seems entirely different from what XML has to offer, it's not that bad. Spring had its architecture polished by years of development and maintenance, making it extremely decoupled and so maintainable. We shall see that a lot of what we've learned at the XML part applied here as well.
AnnotationConfigApplicationContext is designed aside from SOLID's S, making it an entry point of both component-scanning and @Configuration-annotated approaches. This context class thus employs two different venues:
ClassPathBeanDefinitionScanner - handle component scanning patternsAnnotatedBeanDefinitionReader - handle a pre-loaded @Configuration-annotated class
public void main(String[] args) {
AnnotationConfigApplicationContext scannedCtx
= new AnnotationConfigApplicationContext("me.jtalk.example");
AnnotationConfigApplicationContext scannedCtx2
= new AnnotationConfigApplicationContext();
scannedCtx2.scan("me.jtalk.example");
scannedCtx2.refresh();
AnnotationConfigApplicationContext classCtx
= new AnnotationConfigApplicationContext(MyConfig.class);
AnnotationConfigApplicationContext classCtx2
= new AnnotationConfigApplicationContext();
classCtx2.register(MyConfig.class);
classCtx2.refresh();
}
A Note on Refresh
Please note that both constructor-initialised contexts require no manual refreshing. Moreover, they will fail as annotation contexts are not refreshable. Would you need to do some preparations, like injecting a manual dependency into context's bean factory, scan/register methods come to rescue.
As a rule of thumb: in Spring, context constructors that consume configuration location trigger refresh rendering a context to be "sealed" at once.
Despite these two types of annotation-config venues seem different, they actually are tiny and simple. The catch here is that all the major work is made under-the-hood by an already-presented ConfigurationClassPostProcessor. As we have already discovered, this is a BeanDefinitionRegistryPostProcessor capable of converting @Configuration classes into bean definitions via ConfigurationClassBeanDefinitionReader, an unusual reader that, instead of some resource, parses bean definitions as declared as @Bean methods on specified @Configuration classes! So here it is: all the AnnotationConfigApplicationContext's difference is the way it adds annotated beans into the registry. The rest is the same as for XML!
Both ClassPathBeanDefinitionScanner and AnnotatedBeanDefinitionReader just create bean definitions for every class mentioned and put them into BeanDefinitionRegistry. They also must parse bean-related metadata, like:
- Bean name
- Proxy mode
- isPrimary mode
- Bean scope
isLazy mode- Bean role (application/support/infrastructure, see above)
- Bean description
On Scanner Internals
Whilst both seem quite the same, scanner differs in a quite significant manner: it does not actually load class instance. Scanner heavily employs Spring's internal ClassReader infrastructure, parsing class byte-code in order to obtain metadata. It allows applications to actually skip whatever doesn't match their filtering criteria without wasting class-loader cache. The whole thing became less important since Java 8 has decommissioned PermGen space, yet there's a bit of satisfaction left for whoever hates wasting resources.
Most of the above is done by scanner/reader's internal hard-code. The only three exceptions here are bean name, scope, and proxy mode.
AnnotationBeanNameGenerator
Bean names are generated by BeanNameGenerator. XML context employs its simplified implementation, while Annotation-config uses an advanced AnnotationBeanNameGenerator. However, we can provide whatever instance we want via setBeanNameGenerator method of our context instance! While XML context's one was a boring collection of inner/child/whatever bean specifics, this one actually covers a lot of customary stuff alone. This single bean covers:
- Spring's
@Component - CDI's
@ManagedBean - CDI's
@Named
On General Purpose Framework Development
Spring is a widely-used general-purpose framework used in both performance-critical and enterprise applications, start-up prototypes and highly regulated environments. Its developers face various challenges while trying to satisfy the whole Java market with their product. AnnotationBeanNameGenerator contains a catchy point on that: whilst most developers would use something like instanceof to check annotation type, Spring uses String.equals. Because you might want to skip these annotations from your classpath, while Spring must keep supporting them.
Generator provides an isStereotypeWithNameValue method, which actually allows us to register ANY annotation having value attribute to be a name source. Watch the hands:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface MyNamed {
String value();
}
class CustomABNG extends AnnotationBeanNameGenerator {
@Override
protected boolean isStereotypeWithNameValue(String annotationType,
Set<string> metaAnnotationTypes,
Map<string object=""> attributes) {
return Objects.equals(annotationType, MyNamed.class.getName())
|| metaAnnotationTypes.contains(MyNamed.class.getName())
|| super.isStereotypeWithNameValue(annotationType,
metaAnnotationTypes,
attributes);
}
}
@MyNamed("nameFromMyNamed")
class SampleBean {}
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@MyNamed("nameForNestedMyNamed")
public @interface CustomComponent {
}
@CustomComponent
class NestingSampleBean {}
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext();
ctx.setBeanNameGenerator(new CustomABNG());
ctx.scan("me.jtalk.examples");
ctx.refresh();
SampleBean sb = ctx.getBean("nameFromMyNamed");
NestingSampleBean nsb = ctx.getBean("nameForNestedMyNamed");</string></string>
This way, we can add extra naming techniques from less-renown frameworks Spring will never support in a couple lines of code!
About meta-annotations
You could've noted metaAnnotationTypes in the code above. Spring calls inherited annotations that way, so you can actually put your @MyNamed at any other annotation, and the generator above will process it! Meta-annotation check is what makes CustomComponent look-up to work!
ScopeMetadataResolver
Unlike bean name generator above, this is a whole new concept. Scoping rules might be difficult to adjust in runtime, so there is a special resolver in place.
On XML Analogue
In XML context, the only true way of providing extension data to our bean definition is NamespaceHandler. Everything we'd wish to do with our context can be expressed through a set of handlers, and we thus need no special treatment for extensions. Annotation-config lacks such extensibility, thus making it essential to interfere with bean creation that way. All the latter adjustments can be made with custom BeanPostProcessor/BeanFactoryPostProcessor.
Resolver takes a not-yet-registered bean definition and converts it into ScopeMetadata instance. The metadata is later used by both Scanner and Reader to apply scoping/proxying rules accordingly.
Spring by now provides two resolver implementations out-of-the-box:
- Spring
@Scope resolver - annotation-based with scope defaulting to singleton - CDI resolver -
@Singleton-based with scope defaulting to prototype.
And, well, there are strong chances you'll never see CDI resolver in use in your life, so we'd better focus up on @Scope-based one.
Spring prototype scope vs. CDI's @Dependent One
Whilst Spring declares its prototype to be the same as CDI's @Dependent, but it actually is not. Java EE strictly defines bean scoping rules, there's effectively no bean with undefined lifetime. Dependent bean's shutdown is tied up to its holder, so its @PreDestroy will be handled as soon as its parent bean (to which it is dependent) gets destroyed. Unlike CDI, Spring never calls destruction callbacks on non-singleton beans. So, Spring's CDI conformity is not what you should actually rely on.
As you could've seen, @Scope annotation is defined like this:
public @interface Scope {
String scopeName();
ScopedProxyMode proxyMode();
}
Basically, ScopeMetadataResolver does one thing: converts this annotation into ScopeMetadata instance. While we can't really intervene here, we can define our own resolver with custom defaulting rules. The one below parses @Scope annotation, defaulting to prototype scope and TARGET_CLASS proxying for non-singleton beans:
public class MyScopeMetadataResolver
implements ScopeMetadataResolver {
ScopeMetadata resolveScopeMetadata(BeanDefinition definition) {
ScopeMetadata metadata = new ScopeMetadata();
metadata.setScopeName(BeanDefinition.SCOPE_PROTOTYPE);
metadata.setScopedProxyMode(ScopedProxyMode.TARGET_CLASS);
if (definition instanceof AnnotatedBeanDefinition) {
AnnotatedBeanDefinition annDef = (AnnotatedBeanDefinition) definition;
Map<string object=""> attrs = annDef.getMetadata()
.getAnnotationAttributes(Scope.class.getName());
if (attrs != null) {
String scopeName = (String) attrs.get("value");
if (Strings.isNullOrEmpty(scopeName)) {
scopeName = BeanDefinition.SCOPE_PROTOTYPE;
}
metadata.setScopeName(scopeName);
ScopedProxyMode proxyMode
= (ScopedProxyMode) attrs.get("proxyMode");
boolean defaultProxyMode = proxyMode == null
|| proxyMode == ScopedProxyMode.DEFAULT;
if (!scopeName.equals(BeanDefinition.SCOPE_SINGLETON)
&& defaultProxyMode) {
proxyMode = ScopedProxyMode.TARGET_CLASS;
} else {
proxyMode = ScopedProxyMode.NO;
}
metadata.setScopedProxyMode(proxyMode);
}
}
return metadata;
}
}
As soon as we register this resolver with our AnnotationConfigApplicationContext#setScopeMetadataResolver, all the annotated beans will be registered as prototypes by default. I'd say you should skip doing so in production environments, but this feature has its uses, for instance, when defining a nested context with set of third-party prototype worker beans you can't adjust scopes on.
@Bean Method Nuance
As of Spring 4.3.7, you cannot override scoping rules of @Bean-annotated factory methods. They accept @Scope annotation, but its resolver is hard-coded to be AnnotationScopeMetadataResolver in ConfigurationClassBeanDefinitionReader. After all these years, there's still room for improvements!
Annotation Bean Definition Scanner
In the previous paragraph, we have already mentioned the ClassPathBeanDefinitionScanner. It covers component-scanning approach and has a lot of conditionals evaluation. Spring's conditionals are out of scope for this article.
Configuration Class Parsing Infrastructure
As you might've noticed, both XML- and annotation-based context approaches use ConfigurationClassBeanDefinitionReader as a way of handling Java-configured beans. I would say even more: this class is the only standard way of doing so. No matter how you would register your @Configuration class into a bean factory, in order to turn it into bean definitions, you need this reader.
Let's recall the way to enable it:
- XML context: registered by
AnnotationConfigBeanDefinitionParser in ContextNamespaceHandler via NamespaceHandler infrastructure - Annotation context (by
@Configuration): registered by AnnotatedBeanDefinitionReader - Annotation context (by
component-scan): registered by ClassPathBeanDefinitionScanner
ConfigurationClassBeanDefinitionReader is package-private, and we thus have no options of manipulating it. No default name generator override, no custom scope resolving, nothing. I might speculate that Spring guys found no gentle way of introducing a configurable version inside both XML- and annotation-based configurations since they provide quite different APIs. Also, in XML-based configurations, its post-processor is injected in a way inaccessible for end-user's application.
Conclusion
Let's now take an overview of what we have reviewed today:
Spring
|-- XmlApplicationContext
| \-- XmlBeanDefinitionReader
| \-- BeanDefinitionDocumentReader
| |-- DefaultBeanNameGenerator
| \-- NamespaceHandler
| |-- ContextNamespaceHandler
| | \-- AnnotationConfigBeanDefinitionParser
| | \-- ConfigurationClassPostProcessor
| | \-- ConfigurationClassBeanDefinitionReader
| |-- AopNamespaceHandler
| |-- ...
| \-- TxNamespaceHandler
\-- AnnotationApplicationContext
|-- BeanFactory
| \-- ConfigurationClassPostProcessor
| \--- ConfigurationClassBeanDefinitionReader
|-- AnnotationBeanDefinitionReader
| |-- AnnotationBeanNameGenerator
| \-- ScopeMetadataResolver
\-- ClassPathBeanDefinitionScanner
|-- AnnotationBeanNameGenerator
\-- ScopeMetadataResolver
The whole monstrous Spring infrastructure is built on a small-yet-solid foundation of context infrastructure. Once we manage to understand that foundation, the whole thing lies open in front of us.

