This article discusses simple infrastructure for data acquisition and processing which allows developers to build a range of software from a single-process application to complex distributed multi-service system.
Introduction
This article presents compact software providing basic infrastructure for massive continuous data acquisition and processing. The system is based on well-known and wide spread in industry products. Kafka with Zookeeper is responsible for data streaming, and Redis acts as in-memory data storage. This products stack below is referred to as ZKR. These are short excerpts from Wikipedia descriptions of ZKR stack elements.
-
Apache ZooKeeper is a software project of the Apache Software Foundation. It is essentially a distributed hierarchical key-value store, which is used to provide a distributed configuration service, synchronization service, and naming registry for large distributed systems.
-
Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a "massively scalable pub/sub message queue architected as a distributed transaction log. ...ZooKeeper is used by Kafka for coordination among consumers.
-
Redis is an open-source in-memory database project implementing a distributed, in-memory key-value store with optional durability. Redis supports different kinds of abstract data structures, such as strings, lists, maps, sets, sorted sets, hyperloglogs, bitmaps and spatial indexes. The name Redis means REmote DIctionary Server.
Although the code sample for the article employs ZKR stack, demonstrated approach is rather generic. With usage of uniform interfaces, these products may be replaced relatively easily. Overall system structure is depicted in Figure 1.
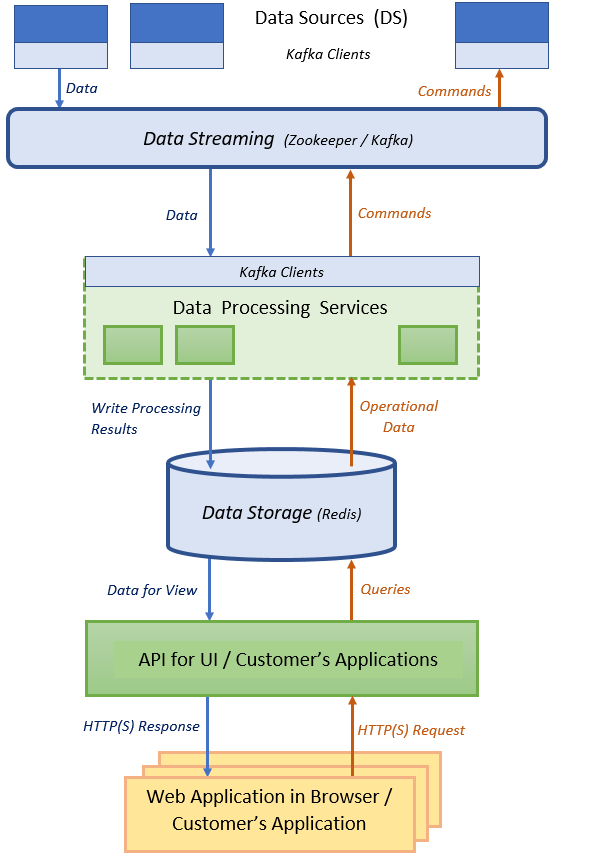
Figure 1. Overall System Structure.
Data Sources (DS) periodically produce metrics and text data to be stored and processed. DS write the data to Data Streaming component (Zookeeper / Kafka in our case). Collection of Data Processing Services is responsible for reading data from Data Streaming, storing them to Data Storage (Redis is our case), and processing the data. Results of the processing are also written to the Data Storage. API for UI and Customer's Applications constitutes additional layer of services reading data from the Data Storage. It provides viewing capabilities for the system. Such a layout is very flexible and convenient. Usage of a standard well performant Data Streaming component spares developer from writing a lot of tedious routine communication code. The third party in-memory Data Storage supports fast read / write operations for the services. Data Streaming and Data Storage provide access to the data with Web API and dedicated DLL adapters (the latters are used in the article sample). The Data Processing Services run indepedently and exchange data via Data Storage. This layout allows users to have a collection of relatively simple services that may be developed in different program languages.
Data Model
The main purpose of this system is efficient data acquisition, storage and processing. For the sake of simplicity, data are travelling from DS via Data Streaming to Data Storage packed in a uniform object defined as class DSData in assembly ObjectsLib. This object consists of a timestamp, array of floats (an integer indicating length of the array is not a part of DSData but inserted before the array itself on serialization), and a string. Each DS periodically generates such an object. It is serialized and written to Data Streaming, then read from there by Data Processing Service. The latter may deserialize data object for its pre-processing if required, and then write it to Data Storage. The Service may decide not to write data object to Data Store (perhaps the object is too old or invalid), or to store processed data only. In our system, the Service performs a very simple check whether data is not too old and if not, then stores them as they are.
Each DSData object is placed to Data Streaming with its identification key. In our case, this is integer serial number of DS generated the object. As it was said above, our simple system stores data to Data Storage as they read from Data Streaming without any reshafling. Example of data structure stored in Data Storage is shown in Figure 2. It is shown that some floats may be omitted. String may contain data and clarifications regarding metric data (e.g., in our example that values 0 and 3 were actually written).
 <
<
Figure 2. Data Object
As you can see, data stored with the same key are placed in inverse chronological order with certain history depth (if required). Structure of stored data should not necessarily copy structure of received object. Usually by one reading operation from Data Storage, data of a single key may be obtained. But data storage layout should be optimized according to subsequent reading.
Design
The system is designed bearing in mind the following objectives:
- Provide uniform infrastructure appropriate for small single-process solution with in-process Data Storage and larger multi-services systems alike.
- Possibility for easy replacement of specific Data Streaming and/or Data Storage provider.
- Convenient starting point for adding horizontal scaling (scale-out) for several machines.
- Developing open system with the ability to add / remove services seamlessly.
The solution is described in the table below.
Table 1. Description of Folders and Projects in the Solution
| Folder | Description |
| Tests | Two tests applications.
FullFlowTest allows developer to test full data flow Data Simulation --> Writing to Data Streaming --> Reading from Data Streaming --> Writing to Data Storage --> Reading from Data Storage in the single application in debug friendly environment.
RedisEventTest tests publishing and subscribing to Redis events. |
| Applications | The folder contains DS simulator DataSourcesSimulator, services for data reading from Data Streaming to Data Storage DataReceiver, for data processing DataProcessor and presentation Dashboard, NodeJsDataProcessor. All these applications are C# console applications, but the latter written in Node.js. _RunMe application starts the entire work process. |
| Common | Basic common assemblies referenced to across the entire solution. |
| Serializers | Assemblies providing standard serialization and deserialization procedures. |
| DataStorage | General data access layer hiding from its user details of specific Data Storage. |
| Factories | General factories for generation of concrete Data Streaming and Data Storage according to uniform interfaces. |
| Kafka | Concrete implementation of Data Streaming with Kafka data producer and consumer. Confluent.Kafka library (version 0.11.0.0) is used. |
| Redis | Concrete implementation of Data Storage with Redis. StackExchange.Redis (version 1.2.6.0) is used. |
The system provides the following data flow:
- Producing data to Data Streaming
- Consuming data from Data Streaming
- Writing data to Data Storage
- Reading data from Data Storage, and
- Data processing
The activities related to Data Streaming and Storage are carried out with types implementing certain interfaces defined in CommonInterfacesLib namespace.
Interface for streaming producer has a single method to send array of (string key -> T value) pairs to Data Streaming component:
public interface IStreamingProducer<T> : IDisposable
{
void SendDataPairs(params KeyValuePair<string, T>[] arr);
}
This can be done either synchronously or asynchronously depending on concrete implementation. In our system, the interface is implemented by type KafkaProducer<T> in namespace KafkaProducerLib. Its constructor gets arguments for connection to Data Streaming, topic and partition and error handling delegate. The constructor launches periodic dequeueing KeyValuePair<string, T> pairs and writing them to Data Streaming using ThreadProcessing type. Method SendDataPairs() enqueues the pairs and triggers writing process.
Interface for streaming consumer also has a single method to start asynchronous data consuming:
public interface IStreamingConsumer : IDisposable
{
void StartConsuming();
}
Type KafkaConsumer<T> implements the interface.
Mechanism of writing to and reading from Data Storage is defined with single interface, IDataStore<T> : IDisposable.
public interface IDataStore<T> : IDisposable
{
void Add(string key, T t, int trimLength = -1);
Dictionary<string, IList<T>>
Get(ICollection<string> keys, long start = 0, long stop = -1);
IList<T> Get(string key, long start = 0, long stop = -1);
void Trim(ICollection<string> keys, int length);
void Delete(ICollection<string> keys);
Task PublishAsync(string channelName, string message);
void Subscribe(string channelPattern, Action<string> callback);
Dictionary<string, TimeSpan> OperationsAverageDuration { get; }
}
The above interface supports adding data to Data Storage, trimming historical data, getting data by either single key or a collection of keys. It also allows publishing and subscribing to Data Storage events - a useful feature provided by Redis. Type RedisAdapter<T> implements the interface.
As you can see, the interfaces for Data Streaming and Storage are very basic and not demanding. Here, their concrete implementations dealing with specific products Kafka and Redis respectively. Factory types StreamingProducer, StreamingConsumer and DataStore decouple general interfaces from their concrete implementations. It means that different implementations of the interfaces may be instantiated with appropriate factory type.
It is convenient to begin acquaintance with the system with FullFlowTest application. The application demonstrates all phases of data travelling from DS to data processing in debug-friendly environment. Static method StreamingProducer.Create<DSData>() of StreamingProducerFactoryLib.StreamingProducer type creates a DSData producer object streamingDataProducer to simulate data generation by DS. Its method SendDataPairs() actually asynchronously generates array KeyValuePair<string, DSData>[] as key -> value pairs (in this test case just a single pair). Then class StorageWriter<T> is instantiated producing object dataStorageWriter. This object is responsible for insertion of data to Data Storage. Appropriate periodic process is started by its constructor. The constructor receives all necessary parameters as its arguments, including address and port of the storage, period of writing, data filter and error handling methods. Type parameter T defines format of stored data and in the sample may be either byte[] or string. The latter is easier to read by various kinds of readers (particularly Node.js reader). Data Storage writer StorageWriter<T> works as following. Its constructor starts periodic process that dequeues data from internal queue and writes them to Data Storages in a different thread. Data Streaming consumer (described below) enqueues to the queue data read from Data Streaming. The Data Streaming consumer object streamingDataConsumer is created by static method StreamingConsumer.Create<byte[]>() that provides message processor as an argument, and its method StartConsuming() launches reading from Data Streaming. The message processor is our sample simply enqueues messages into Data Storage writer queue, but may be assigned with some filtering and pre-processing tasks.
Code Sample
Prerequisites
The first step is installation of the Zookeeper, Kafka and Redis. Simple but yet comprehensive guidance for installation of Zookeeper and Kafka on Windows may be found e.g., here (Zookeeper and Kafka). Redis as either msi of zip file may be downloaded from here (Redis). Version Redis-x64-3.2.100 is used.
Elements of ZKR stack are installed as Windows services but may be run as console applications. For simplicity in our code sample, we will run them as console applications using appropriate command files 1 - Start_Zookeeper.cmd, 2 - Start_Kafka.cmd and Start_Redis.cmd (numbers in files name indicates order in which they start).
Note for running Redis. By default, Redis runs in so called protected mode permitting only local calls to it. To allow network call Redis server should start not in protected mode:
redis-server.exe --protected-mode no
This is how Redis starts from our command file.
NodeJsDataProcessor project in developed in Node.js. So if you want to run it, then Node.js should be installed, e.g., following this guidance. It would also be useful to install Node.js Development Tools for Visual Studio from here.
Some more handy tips that I found empirically playing with the sample. Update of Java in your computer may cause change of environment variable JAVA_HOME used by ZKR stack elements, and they may cease to operate. Zookeeper should be started before Kafka. Before every start of Kafka (at least as console application), folders containing Kafka logs and Zookeeper data (in my installation kafka_2.11-0.11.0.1kafka-logs and kafka_2.11-0.11.0.1zookeeper-data) should be deleted form Kafka installation folder (in my case C:\kafka_2.11-0.11.0.1).
Note. When you will run sample applications as it is described below, you need not worry about these complications since this operation is performed by the samples themselves.
After successful installation of the ZKR stack elements, appropriate referenced assemblies dealing with ZKR have to be installed. This may be carried out using NuGet. Required packages are included to packages.config files of appropriate projects. These are the following components:
- for Kafka: Confluent.Kafka.0.11.0 and librdkafka.redist.0.11.0
- for Redis: StackExchange.Redis.1.2.6
Running Software
After having installed required packages and built the solution, you may run the applications. It is suggested to begin with test application, FullFlowTest. The application first started all elements of ZKR stack as three console applications (you will notice three additional console windows appearing in the screen), and then perform all steps of the data flow chain:
Data Simulation --> Writing to Data Streaming --> Reading from Data Streaming --> Writing to Data Storage --> Reading from Data Storage
The above operations, but the last one, are performed once. Reading from Data Storage is performed periodically. So the application reads and displays as delimited string the same DSData object. Starting with the second, the string object is preceded with "?" indicating that the data are old (indeed, the same object with fixed timestamp is read). To quit the application, press any key and kill all ZKR windows.
You may proceed with the next small test application, RedisEventTest. It demonstrates usage of Redis events. These events are a very handy inter-process synchronization tool. The application first starts Redis and then invites user to publish event. Result appears on the screen.
Finally, the main data flow may be tested by starting _RunMe application from Applications folder. It starts all ZKR applications, then DataProcessor, two DataReceivers, Dashboard, NodeJsDataProcessor and finally DataSourcesSimulator. _RunMe configures all started applications (but DataSourcesSimulator which is configured by itself) via Data Storage (Redis): it writes configuration data to the Storage that applications aware of, and the applications read them. According to default configuration, DataSourcesSimulator generates and writes to Data Stream (Kafka) 1000 DSData objects with array of 4 float values every second. These data are evenly distributed between two DataReceivers which read them from Data Stream and write to Data Storage. The first DataReceiver stores data as bytes arrays and the second one as strings. DataProcessor, Dashboard and NodeJsDataProcessor read data from Data Storage. Dashboard visualizes data from one DS (in our case, this sine function is simulated by DataSourcesSimulator).
Figure 3. Data Visualization with Dashboard Application.
Very simple (few lines of code) application NodeJsDataProcessor written in Node.js, illustrates the possibility to use services developed in different languages by various vendors to extend the system.
Some Measurements and Discussion
While running the sample, some time measurements were performed. Dell laptop (CPU i7-7600U, RAM 16 GB, 2.90 GHz; Windows 10 Enterprise) was used for local tests. An older laptop CPU i7-3610QM, RAM 16 GB, 2.30 GHz; Windows 10 Pro) ran Redis in remote tests. Relatively slow home WiFi connection was used. It is interesting to measure average duration of such operations with one record as writing to and reading from Redis. Some results are presented in the following table.
Table 2. Average Duration of Writing and Reading Operation with Redis.
| Operation | Write byte[]
mcs | Write string
mcs | Read byte[]
mcs | Read string
mcs |
| Local | 140 | 140 | 120 | 320 |
Writing to Redis was tested in synchronous mode (CommandFlags.None in RedisAdapter<T> class). Direct remote reading and writing take much longer (milliseconds). Massive remote reading and synchronous writing are not possible with weak network (although asynchronous writing with CommandFlags.FireAndForget for this example was successful).
These rough measurements provide some clue for design of system layout. When Redis is installed as local application, services running in different machines can asynchronously write data to it, whereas local reading is preferred. In case of extensive reading, it is probably better to store data as array of bytes, but the possibility of reading these data with different readers in different programming languages should be kept in mind. It is a good idea to preprocess data before writing to Data Storage when possible. Wise grouping of stored data in order to optimize their subsequent reading should not be underestimated. And if remote data reading is absolutely necessary, then probably a better choice is to first read the data locally and then transfer them to client machine by other communication means. Redis cluster should be checked for remote operations.
So it is clear that performance of Data Storage, particularly for remote reading, should be improved for real world applications. Such enhancements may imply, e.g., usage of Redis pipelining technique allowing to send multiple commands at once. Usage of Redis cluster may be considered to mitigate remote call problems. redis-benchmark utility may be used for more accurate measurements. It is quite possible that skilled Redis expert will immediately suggest how to improve performance.
Conclusions
Simple infrastructure for data acquisition and processing presented in the article, allows developers to build range of software from a single-process application to complex distributed multi-service system. The sample in the article deals with Zookeeper - Kafka - Redis stack. But these products may be replaced with some others without change of basic infrastructure (e.g., RabbitMQ may be considered for Data Streaming, and Apache Ignite is a promising candidate for Data Storage). Moreover, in simple case of a single-process system, Data Streaming and/or Data Storage may be developed "in house" using same common interfaces. The next step can be usage of distributed version of Data Streaming and Data Storage. For example, it will be very interesting to use distributed cluster installation of Redis. The sample presented in the article can be easily moved to .NET Core. Possibility to use the same 3rd party libraries or finding other libraries compatible with .NET Core are to be checked. Cloud installation of the system will be interesting to perform.
History
- 15th February, 2018: Initial version

