This is Part 1 of an article about microservices with Kubernetes, Docker, Helm.
Introduction
Using Kubernetes to deploy services and support micro-service architectures is nice and is pretty fast. It is just better than setting up things one by one. It's also really good for DevOps people, trying to automate deployment and patches. However, much like any other system, the question of parametrization is somehow hard to solve. The purpose of DevOps team is to streamline everything and reduce the amount of time a patch gets into production, the purpose of the Dev Team is to deliver and integrate the IDE backbone with the streamline, the Security Team must ensure that everything is as hardened as possible.
Kubernetes solves a couple of problems by:
- Providing container-based isolation and offering a supplementary layer of abstraction over hardware and software resources
- Providing an easier means to online microservices in micro-service based architectures;
- Kubernetes allows for some specific securing of software environments by its structure and default services;
- Easy to setup with Ansible, Helm for large amounts of microservices, which (should) take the load of development teams when it comes to streamlining and DevOps;
- Code base can be integrated with CI/CD pipelines and infrastructure;
- Supporting HA/Cluster configurations, as well as some other concepts like circuit breakers, a nice to have in critical environments;
- Reducing the amount of overhead costs on the load of a developed system, by removing a vast swath of people not actually being required to maintain the system, once it gets to a reasonable Alpha State Release. And I say this, because once the main system functionality set is developed and tests are written, the probable required development roles can be reduced, as people like testers, POs, architects are non-necessary personnel inside a business. Once a baseline of a system is reached, the only required man-power to be maintained is a reasonable developer force to cover for the upgrades and bugs.
Kubernetes and Docker together, add even more to the overall versatility of the solution, as well as the overall utility for the CI/CD DevOps culture.
Background
Imagine you are in a system that has about 30+ microservices that require to do some important task, a pretty chunky U.I with lots and lots of nice dashboards, all running in an environment with 2n+1 configuration for a true HA/Cluster/Redundancy configurated environment. You would require some sort of INGRESS controller or API Gateway (depending on how you want to call it, they pretty much do the same things, more or less...)
When using Kubernetes INGRESS, like an NGINX, you have a couple of out-of-the-box features, including load balancing and cluster configuration. Actually Kubernetes provides for authentication services if required. For other solutions however, customizing Kubernetes comes with a little work, behind the doors, like setting various parametrization for some modules to work.
Such parametrization may be:
- setting paths to other required services and addresses inside and outside of the cluster. Depending on the system architecture you are working on, this can be achieved using config maps, environment variables, service discoveries, etc.
- some exotic configuration that is not dependant on Kubernetes itself
- adding components inside your cluster
The need usually dictates the final system architecture, while actual functionality is achievable with what you have as a resource at the time of doing something specific.
To shorten the story, let's look at the architecture:
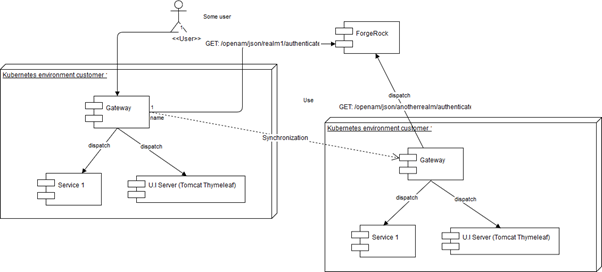
So we have a couple of customers running different versions of the same cluster image, nothing too complicated. The Service 1 is an abstraction, as in there it can be any number of services running inside the cluster. Addressing is done using a simple label-based approach, with a naming convention similar to http://service1/, where service1 is the label for a given pod.
Now for the securing of the application, a ForgeRock instance is just fine, where a separate realm is configured for each environment. ForgeRock provides authentication and token validation, while the innerworkings of each deployment, handles session for each Kubernetes environment.
For the Gateway, I have used a demo Zuul with two simple filters, one that executes when calling login, and one that executes at each call towards the pods inside the cluster.
Note that a better solution would be to have the UI sitting on top of the Gateway and outside the cluster (really cool people would make the U.I sit inside a DMZ, to provide for more security... but subjects like setting up HTTPS, Kubernetes Federated Services and other stuff, I will leave for another time).
The choice of Zuul is pure flavor. Normal workings of how some user might access the cluster, is:

(The above image is done for the purpose of showing a successful authentication only. CORS filter is there to prevent browser errors. Simple setup, accepts all. For hardening purposes, one may want to set the accept header to the cluster external address only. That 401 is there to show what would happen if no CORS would be set in this configuration - browser would throw a CORS/CORB error and block all resources, especially static content.)
So the translated story of the above diagram is:
- Some user requests a login to access the cluster resources.
- The cluster redirects to the gateway which handles all calls as an INGRESS, running inside Kubernetes.
- All service mappings are for the internal labeling of each pod.
- The UI gets served with the CORS filter set to
accept-all (see previous comments). - On the login phase, a token is obtained from ForgeRock, based on login realm.
- Any subsequent requests towards the cluster, also sets a header with the
tokenId, taken from ForgeRock.
The experimentation can be done really easy on local environments. I setup a local ForgeRock instance with OpenAM and OpenDJ to simulate the source, while setting a minikube on two different laptops (by personal choice). Someone may setup a similar configuration with 3 VM images running on a virtualization provider, to see the effects.
Implementation
The mapping for each outside address, as long as the UI sits inside the cluster and not outside (to which I would be against, but for the purpose of this demo, I guess it's fine. I will however update this and come up with something that someone would see in real-life, including HTTPS support), must always point to the Kubernetes address that is exposed (you may have an INGRESS that redirects all traffic to the Gateway, isolates the UI in a DMZ..., use a NodePort configuration, etc.). You may want to map the UI address to whatever label you have given to that pod, but the purpose is to hide the calls to the cluster services behind the UI, if the UI is inside the cluster and there is no filter to manage security.
Zuul mapping may look like this (inside application.yml):
zuul:
ignoredPatterns: /testendpoint/**
routes:
google:
url: http://google.com/
login:
url: ${ENV_LOGIN_URL:http://localhost:8083/login}
strip-prefix: true
static:
path: ${ENV_UI_STATIC_PATH:/static/**}
url: ${ENV_UI_STATIC_VAR:http://localhost:8083/}
strip-prefix: true
Parameter ${ENV_LOGIN_URL} is part of the above specification of parametrizing the Kubernetes environment and adding environment variables to accommodate for various parametrization. In this case, Zuul has a registered route to the login page exposed by the U.I pod, which runs on port 8083.
A route for all incoming static content (since the U.I is sitting inside the cluster, for this time) is also added. In this case, all routes matching /static/** are being routed to the root context of the U.I service. In this case, another environment variable was added ${ENV_UI_STATIC_VAR} to accomodate for that too. In fact, this model may be extended as required.
LoginFilter and RequestFilter are all marked as "route". Execution of each one, is controlled on shouldFilter():
@Override
public boolean shouldFilter() {
ctx = RequestContext.getCurrentContext();
if ( ctx.get("proxy").equals("login")) {
GatewayLoggingFactory.GatewayLogger().info(" Someone requested a login! "
+ "Origin: " + ctx.getRequest().getRemoteAddr() );
return true;
}
else {
return false;
}
}
Getting a token from ForgeRock, as per ForgeRock documentation is easy if using REST endpoints. How to get it, is up to each implementation. I used REST endpoints for ease of use purpose (I used the WebClient to prep for async implementation and using the Spring Flux):
String forgeRockResponse = WebClient.builder().baseUrl(baseUrl)
.build().get().uri(path).retrieve().bodyToMono(String.class).block();
Adding CORS configuration is easy:
@Bean
public CorsFilter corsFilter() {
final UrlBasedCorsConfigurationSource source =
new UrlBasedCorsConfigurationSource();
final CorsConfiguration config = new CorsConfiguration();
config.setAllowCredentials(true);
config.addAllowedOrigin("*");
config.addAllowedHeader("*");
config.addAllowedMethod("GET");
config.addAllowedMethod("POST");
source.registerCorsConfiguration("/**", config);
return new CorsFilter(source);
}
People may want to change the config.addAllowedOrigin("*") to config.addAllowedOrigin(System.getenv("ENV_ALLOWED_ORIGIN")) where the second is a parametrized version, where each origin is based on the Kubernetes cluster node, where each application context runs.
Using Kubernetes for Parametrization of Services
Each parametrization for the services in this case, was done using environment variable injections. This can be seen in the application.yml settings shown above, where environment variable injection is being used with ${ENV_PARAM:default), where ENV_PARAM has a value set inside the Kubernetes environment, and the default value is set as a fallback (though not really useful if that value hasn`t been setup in some way or form).
Achieving this result, can be done depending on how exactly the environment is setup. What is sure, let`s say you have a deployment.yaml file describing your service for Kubernetes, then your file may look something like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: gateway-sample
labels:
app: gateway-sample
spec:
[...]
spec:
containers:
[...]
env:
- name: FORGEROCK_REALM
value: http://localhost:8082
- name: ENV_ALLOWED_ORIGIN
value: http://localhost:8083
For large scale environments, using Helm, allows for neat centralized parametrization control of the entire deployment. This is useful since it can be integrated with Jenkins or other CI/CD solutions.
If Docker Compose is used, the file may look like this:
version: '0.1'
services:
gateway-sample:
build : .
image: api-gateway-img
ports:
- "8081:8081"
environment:
- FORGEROCK_REALM=http://localhost:8082
Using a centralized .env is however the practice.
Planned Work Ahead
While working on this big architecture with Kubernetes, I realized that Kubernetes is setting the path for a true hybrid cloud deployment, especially since the Federation is also out there. I will continue this project to add support for more Kubernetes features and support for more interesting things like the ability to run on cloud hosts and local (for let's say a scenario where you would want some solutions to run partly at the customer and partly in your personal hosted cloud service, for a true hybrid cloud experience) hosted environments, for picky / special scenarios, as well as go deep into the security side of things.
Code Sample
A small code sample with Zuul can be found here: ZuulExperimentWithForgeRockAndKubernetesOnGit You can setup your own ForgeRock instance and of course, update the configuration.
The code base contains two classes representing services to get data from ForgeRock, one with parametrization and one without parametrization.
The user would just require to autowire the right / desired implementation mode and see differences.
History
- 2nd July, 2018: Initial version

