Preface
This article is the sequel to previous article Writing basic Windows Debugger, and it is mandatory for the reader to read and understand the
first part first! Without grasping what is mentioned in first part of this series, you may not understand what is
presented here, nor you would be able to appreciate this stuff!
One thing I should mention, which I did not state in previous part, is that our debugger is only able to debug
Native Code. Thus, an attempt to debug a .NET/managed application would fail. May be, in next
article I would cover debugging the Managed Code also.
I am here to present more of intriguing aspects, in debugging parlance, which you might not know before. This
would include showing the source code and the call stack, setting the breakpoints, stepping into code, attaching
(our) debugger to a process, making it a default debugger and so on. Since this article presents somewhat
advanced concepts in debugging, I removed "basic" word from the title!
The debugging experience would be as per with Visual C++, that includes debugging terms (Step-Into), shortcuts
(F5) etc.
Table of contents:
So, what you do when you want to debug your program? Well, mostly we hit F5 to begin debugging our
applications, and the Visual Studio Debugger would halt at the places where we have placed breakpoints (or
conditional breakpoints!). A "Debug Assertion Failed" message box, followed by Retry button also
opens the source code, and halts there. The DebugBreak call or {int 3} instruction would
also do the same. There are other approaches for debugging, you know!
Rarely or occasionally, we also start debugging from the beginning by hitting F11 (Step-Into),
and the VS starts from main/wmain or WinMain/wWinMain (or
_t prefixed variants of them). Well, that is the logical start address of
your process where debugging begins. I call it logical since it is not the actual start address -
the address also known as Entry Point of the module. For a console application, it is
mainCRTStartup which calls main function, and VS Debugger starts at main.
The entry-point is also applicable for DLLs too. Please have a look at /ENTRY switch for more information.
This turns out that we need to stop program execution at the entry-point location, and
let user (programmer) continue debugging. Yes, I said "stop" the execution at entry-point location - the
process is already started (being debugged), and unless we halt it somewhere the process would complete its
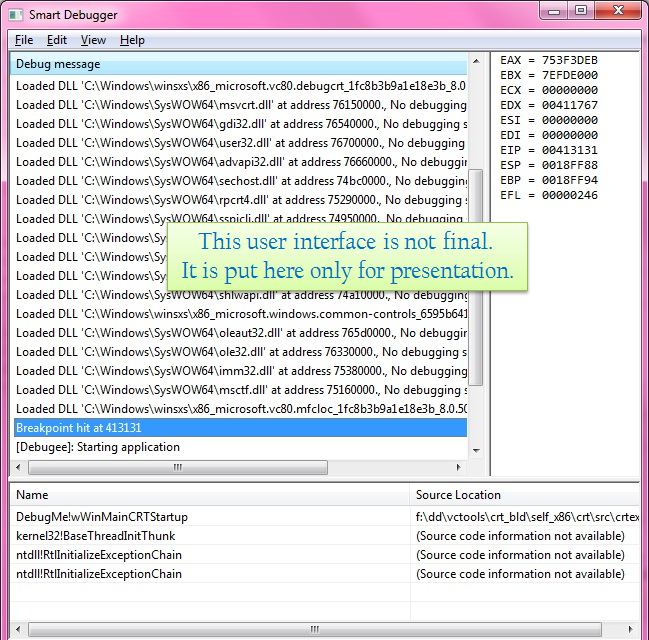
startup. The following call-stack appeared as soon as I hit F11, for an MFC application - which clarifies what I
mentioned.

What we need to do, to stop program execution at Entry-Point?
In a nutshell:
- Obtain the start address of process
- Modify the instruction at that address - replace it with breakpoint instruction, for example.
- Handle the breakpoint event, revert the instruction with original instruction
- Stop execution, show call stack, display registers and source code, if available.
- Continue debugging (as per user request)
And this 5-step task is not easy, boy!
Start Address, Entry Point and the logical* entry point (your main/WinMain) -
welcome to the complex world. Before I present textual content about these terms, let me give you visual idea about
it. But first thing you should understand: the first instruction at the given address is the point where execution
begins, and debuggers play with that address only.
* [This term is coined by me, and is relevant to this article only!]
Here is how WinMain looks in Disassembly View in Visual Studio, with annotations for the
gibberish you see:
You can launch the same view for you code by right clicking in code editor, and selecting Go To
Disassembly. The Code Bytes are not shown by default (Green content above), you enable it by Show
Code Bytes context menu.
Relax! You need not to understand the machine language instructions, nor the ASM language! This is just for
illustration. For the example above, 00978F10 is the start-address, 8B FF is the first
instruction. We just need to make the given instruction (mov blah blah), a breakpoint
instruction. We know the API called DebugBreak - but that cannot be used here.
{int 3} is the assembly code for the same, and we need the x86 instruction for the same. The breakpoint x86
instruction is
0xCC(204).
Thus, we just replace 8B with CC and we are done! When the program continues further
(within our debugger-loop), it would raise an exception event (EXCEPTION_DEBUG_EVENT), having the
exception code EXCEPTION_BREAKPOINT (0x80000003). We know this is our sin, we handle is
appropriately. If you don't understand this paragraph, I request you (last time) to read the first part of
this article.
The x86 instructions are not of fixed width - but who cares? We don't need to see if instruction is of
1, 2, or N bytes. We always replace the first byte. The first byte (of instruction) may be
anything, and not just 8B! But, we must ensure that as soon as desired breakpoint is
hit, we reverse our sin - i.e. replace the replaced instruction with original code-byte.
For few geeks out there, who know it, and for everyone else who do not know it. The breakpointing is
not the only way to stop program at start-address. There is better alternative for these One-shot/stop-once
breakpoints, which is to be discussed. Secondly, CC instruction is not the only breakpoint instruction
- but it is sufficient enough for us.
There is more of complexity involved with Start-Address, but to keep grabbing your interest, let me
jump straightaway to C++ code that retrieves the start address. The CREATE_PROCESS_DEBUG_INFO has
member named lpStartAddress, that represents the start address. We can read this information while
processing the very first debugging event:
switch(debug_event.dwDebugEventCode)
{
case CREATE_PROCESS_DEBUG_EVENT:
{
LPVOID pStartAddress = (LPVOID)debug_event.u.CreateProcessInfo.lpStartAddress;
...
...
The type of CREATE_PROCESS_DEBUG_INFO::lpStartAddress is LPTHREAD_START_ROUTINE, and I
assume you know what exactly it is (function pointer). But, as I mentioned before, there are complexities around
start address. In short, this address (lpStartAddress) is relative to where image is actually loaded
in memory. To make all this sound convincing and significant, let me show you the output of dumpbin
utility with /HEADERS switch:
dumpbin /headers DebugMe.exe
...
OPTIONAL HEADER VALUES
10B magic # (PE32)
8.00 linker version
A000 size of code
F000 size of initialized data
0 size of uninitialized data
11767 entry point (00411767) @ILT+1890(_wWinMainCRTStartup)
1000 base of code
This address (00411767) is what I received with lpStartAddress member, while debugging
from our debugger. But when I tried to debug the same executable from Visual Studio, the address at
wWinMainCRTStartup was somewhat different (@ILT stuff has no relevance for this).
Thus, allow me to postpone discussing intricacies around start address. Let's just have
GetStartAddress()
user defined function, whose code would be disclosed later. This would return the exact address where we
would put the breakpoint instruction!
Once we get the start-address, modifying the instruction at that location with breakpoint (CC) is
quite trivial. We need to do:
- Read one byte from that memory location, store it.
- Write
0xCC instruction at that location. - Flush the instruction cache.
- Continue debugging.
Two important questions should hit you now:
- How we read, write and flush the instructions?
- When we do the same?
Let me uncover the second query first. We do read, write and flush instructions while processing
CREATE_PROCESS_DEBUG_EVENT debug event (or optionally at EXCEPTION_BREAKPOINT event).
When the process is being loaded, we grab the actual start address (I mean the CRT-Main's address!), we
read the very first instruction at that location of one byte, store it, and place the breakpoint
(0xCC) at that instruction. Then we let our debugger to ContinueDebugEvent.
To depict how to do the same, here I present relevant code!
DWORD dwStartAddress = GetStartAddress(m_cProcessInfo.hProcess, m_cProcessInfo.hThread);
BYTE cInstruction;
DWORD dwReadBytes;
ReadProcessMemory(m_cProcessInfo.hProcess, (void*)dwStartAddress, &cInstruction, 1, &dwReadBytes);
m_OriginalInstruction = cInstruction;
cInstruction = 0xCC;
WriteProcessMemory(m_cProcessInfo.hProcess, (void*)dwStartAddress,&cInstruction, 1, &dwReadBytes);
FlushInstructionCache(m_cProcessInfo.hProcess,(void*)dwStartAddress,1);
About the code:
m_cProcessInfo is member of class (not yet presented), which is nothing but
PROCESS_INFORMATION and is filled-in by CreateProcess function. - The user defined function
GetStartAddress returns desired start-address of the process.
For a GUI based unicode application, it would return the address of wWinMainCRTStartup. - Next we call
ReadProcessMemory to grab what is at the given start-address. We store it in a member
variable of class. - The we replace the instruction with
0xCC, a breakpoint instruction, using
WriteProcessMemory. - Finally we call
FlushInstructionCache, so that CPU would read the new instruction, and not
any of cached (old) instruction. The CPU may or may not cache the CPU instructions, but you should always
flush it.
Remember that ReadProcessMemory requires permission
PROCESS_VM_READ. Likewise, WriteProcessMemory requires permission
PROCESS_VM_READ|PROCESS_VM_OPERATION - all these permissions are already granted to the debugger, as
soon as Debugging-Flag was given to CreateProcess. Therefore, we need not to do anything, and
reading/writing would always succeed (at valid locations, of course!).
As you know that breakpoint (EXCEPTION_BREAKPOINT) instruction is a kind of exception that
arrives under EXCEPTION_DEBUG_EVENT debugging event. We handle the exception events through
EXCEPTION_DEBUG_INFO structure. The following code would help you recollect and understand it:
switch(debug_event.dwDebugEventCode)
{
case EXCEPTION_DEBUG_EVENT:
{
EXCEPTION_DEBUG_INFO & Exception = debug_event.u.Exception;
...
The OS would always send one breakpoint instruction to the debugger, which is just an indication that process is
being loaded. That is why you can also perform "placing breakpoint instruction at start-address"
on this very first breakpoint exception. This would ensure that after this very first breakpoint, all next
breakpoints are yours!
Irrespective of where you put your breakpoint instruction for the start-address, you still need to
ignore the first breakpoint event. Though, debuggers like WinDbg, would also show you this
breakpoint also. Visual C++ debugger, for instance, on other hand, does not give any indication about this very
first breakpoint, and starts executing at Logical beginning of program
(main/WinMain and not CRT-Main).
Therefore, the breakpoint handling code would look like:
switch(Exception.ExceptionRecord.ExceptionCode)
{
case EXCEPTION_BREAKPOINT:
if(m_bBreakpointOnceHit)
{
}
else
{
m_bBreakpointOnceHit = true;
}
break;
...
You can also use the else-part to place the breakpoint instead of placing it on process-start event.
Either way, the main breakpoint event handling code goes in if-part. We need to handle the breakpoint that
we had placed at start-address.
Now it goes tricky and intriguing - you need to concentrate, read carefully, sit relaxed (adjust your butt on
the chair, if you need to!). If you have not taken a break reading this article, take it now!
In simple terms, the breakpoint event has occurred at the location/address where we placed it. We now just halt
debugging, show call stack (and other useful elements), revert the original instruction and wait for user input to
continue debugging.
At assembly or machine-code level, when any exception occurs and the debugger notified, the faulting instruction
has already executed - though, for breakpoint, it would be just of one byte. The instruction pointer has already
moved ahead by few bytes, depending on instruction size. And the system has given us this exception-event to
handle.
Thus, in addition to writing back the original instruction at the "breakpoint-location", we need to
play with CPU registers also. The registers, that are specific to the process (more specifically, thread), can be
retrieved and modified using two Windows functions: GetThreadContext and
SetThreadContext. Both of the functions take a CONTEXT structure. Strictly speaking, the
members of this structure are dependent on processor-architecture. Since, this article is about x86 architecture,
we would follow the structure definition for the same, and that can be found in winnt.h header.
This is how we retrieve the thread-context of a given thread:
CONTEXT lcContext;
lcContext.ContextFlags = CONTEXT_ALL;
GetThreadContext(m_cProcessInfo.hThread, &lcContext);
Okay! Now you retrieved the thread-context, now what?
The EIP register tells you the Instruction Pointer, which is
the next instruction to be executed. This is represented by Eip member of CONTEXT
structure. As I mentioned already, the EIP has already moved ahead, and we need to move it back. Luckily for us, we
just need to move it by exactly one byte, since BP instruction was of one byte. The following code does the
same:
lcContext.Eip --;
SetThreadContext(m_cProcessInfo.hThread, &lcContext);
The EIP is the location from where the CPU would pick the next instruction and start executing. Yes, we need to
have THREAD_GET_CONTEXT and THREAD_SET_CONTEXT access permissions to successfully execute
these function, and we do already have.
For a while, allow me to take a Context-Switch to another frame: Reverting the original instruction! To
write back the original instruction into the running process, where BP instruction was placed, we just need to use
WriteProcessMemory followed by FlushInstructionCache. This is how we can do it:
DWORD dwWriteSize;
WriteProcessMemory(m_cProcessInfo.hProcess, StartAddress, &m_cOriginalInstruction, 1,&dwWriteSize);
FlushInstructionCache(m_cProcessInfo.hProcess,StartAddress, 1);
The original-instruction is reverted this way. We then call ContinueDebugEvent. The combined code
would look like:
Well, where is the call-stack? Registers? Source code? And when did the program halt? It all continued without
user interaction/intervention!
To display the call stack we need to load the debugging symbols, which would exist in relevant
.PDB files. The set of functions from DbgHelp.DLL would help us to load symbols,
enumerate the source files, walk through the call stack and so on. All these would be discussed soon.
To render the CPU registers, we just need to display relevant registers from the CONTEXT structure.
To display the 10 registers as shown by Visual Studio debugger (Debug->Windows-
>Registers, or Alt+5), we can use following code to generate text:
CString strRegisters;
strRegisters.Format(
L"EAX = %08X\nEBX = %08X\nECX = %08X\n"
L"EDX = %08X\nESI = %08X\nEDI = %08X\n"
L"EIP = %08X\nESP = %08X\nEBP = %08X\n"
L"EFL = %08X",
lcContext.Eax, lcContext.Ebx, lcContext.Ecx,
lcContext.Edx, lcContext.Esi, lcContext.Edi,
lcContext.Eip, lcContext.Esp, lcContext.Ebp,
lcContext.EFlags
);
And display the generated text to relevant window.
To halt program execution, until user gives appropriate commands (Continue, StepIn, Stop Debugging etc), we do
not call ContinueDebugEvent. Since the debugger-loop would be in another thread than the GUI thread,
we just ask GUI thread to display relevant information, and let the debugger-thread wait for some
"event" to occur. On user command, we trigger that "event", which would end the wait in
debugger-thread.
Confused? The event in quotes is nothing but a windows event, which is created by
CreateEvent. To halt execution we just call WaitForSingleObject (in debugger-thread). To
let debugger-thread to continue from that wait-location, we just call SetEvent (from GUI-thread). Of
couse, depending on your taste, you can use other synchronization primitive, or some class (CEvent?)
to do the same. This paragraph only gave the rough idea how we can implement Halt-and-Continue.
With this additional desription, the logical-code to achieve all this would be:
GetThreadContext, reduce EIP by one, call SetThreadContext. - Revert the original instruction, using
WriteProcessMemory, FlushInstructionCache.
- Display the relevant members of
CONTEXT - Registers View. - With the help of symbol-information functions, locate the source file and line (if possible) and
display the Source Code!
- With stack-walking functions and symbol-info functions, enumerate the Call Stack of debuggee and
redner on UI.
- Since the GUI thread is intimated by now, we wait for use action through "Event".
- On wait-complete, we perform the action initiated by user (Continue, Step, Stop...)
- Call
ContinueDebugEvent.
Astonished? Great! I hope you are enjoying the Debugging !
One important point worth mentioning here - the thread which is being debugged may not be primary
thread of debuggee, but the thread that caused this breakpoint event to occur. Till now, we are still processing
the very first BP event that we had created to stop execution at process-startup. But the eight-step process I
listed above would be applicable for all debugging events (from any debuggee' thread), that can
cause program to halt.
There is slightly more of complexity involved with instruction modification and EIP change. Whilst I would show
the solution to it later, let me just mention the problem. The breakpoints may also be placed by
user; and for the same, we would just replace the instructions with CC instructions on those addresses
(yes, saving the original instructions). When those breakpoints would arrive, we would just revert the instructions
and perform the 8-step processing that I am currently describing. Fine enough? Well, that would prevent the user-
defined breakpoint events to arrive only once! If we don't revert original instruction - well, that's a total
mess!
Anyway, let me continue further! :-)
Ah! Source-Code! I know you are dying to see how this can be retrieved!
Any EXE or DLL image you build may have Debugging Information attached with it in form of a
.PDB file. Few points on this:
- The debugging-information is only available when
/DEBUG switch is given in linker settings. In VS,
you can see this here: Linker->Debugging->Generate Debug Info. - The
/DEBUG symbol does not mean that the EXE/DLL would be Debug build. The preprocessor macro
_DEBUG/DEBUG controls the debug build at compile time. Other linker settings and
appropriate library imports define the meaning of debug build at link time. - This means, a Release build can have debugging-information, and a Debug build may not have
debugging-information (no
/DEBUG linker switch, but _DEBUG macro defined). - A file with .PDB extension stores the debugging-information, which is generally
program-name.PDB, but it can be renamed in linker options. This file contains all source code
information stored - functions, classes, datatypes and so on.
- The linker puts small foot print about this .PDB file in image-header of the EXE/DLL generated. Since this
information is put into headers section, it does not impact the performance of generated binary at all.
Only the file size increases by few bytes/KBs.
To gain this debugging information, we need to use Sym* functions hosted inside
DbgHelp.DLL. This DLL is most important component for source-code level debugging. It
also hosts functions to walk the call stack, and to retrieve information about image (EXE/DLL). Click here to see all
functions exported by this DLL. The required header is Dbghelp.h, and required library is
DbgHelp.lib
To gain debugging information, we need to initialize Symbol Handler for the given process.
Since, the target process is the debuggee, we initialize with the process-handle of debuggee.To initialize symbol
handler, we need to call SymInitialize function:
BOOL bSuccess = SymInitialize(m_cProcessInfo.hProcess, NULL, false);
The first parameter is the handle of running process for which symbol-information is required. Second parameter
is semi-colon separated paths, which specifies where to look for symbol files (for us, the .PDB
files). The third parameter says if the symbol-handler should load the symbols for all modules automatically or
not. Since we need to show if debugging-information is found or not, we pass false.
The following text would make some sense:
'Debugger.exe': Loaded 'C:\Windows\SysWOW64\msvcrt.dll', Cannot find or open the PDB file
'Debugger.exe': Loaded 'C:\Windows\SysWOW64\mfc100ud.dll', Symbols loaded.
Visual Studio (2010) could not locate symbols for msvcrt.dll, thus the error. The DLL,
mfc10ud.dll has its debugging information available, therefore VS was able to load it. This
essentially means that, for MFC DLL, VS would show symbol information, viz source code, function/class names in
call-stack and so on. To explicitly load the symbol file for respective DLL/EXE we call
SymLoadModule64 / SymLoadModuleEx function.
Where should we call these functions for the debuggee? It took me lot of time to locate, since I was trying to
initialize and load symbols before the debugging-loop (i.e. before any debug-event, but after
CreateProcess). It does not work that way. We need to call it on
CREATE_PROCESS_DEBUG_EVENT debugging event. Since, we are saying "no" to automatic
symbol loading for the dependent modules, we need to call SymLoadModule64/Ex
for the EXE file just loaded. For upcoming LOAD_DLL_DEBUG_EVENTs, we also need to call this function
for the respective DLL being loaded. Depending on outcome of symbol-loading-for-image, we let the end user know if
debugging-information is available or not.
Sample code, that loads the module when a DLL-Load event is encountered. Function named
GetFileNameFromHandle is described in previous part (code available).
case LOAD_DLL_DEBUG_EVENT:
{
CStringA sDLLName;
sDLLName = GetFileNameFromHandle(debug_event.u.LoadDll.hFile);
DWORD64 dwBase = SymLoadModule64 (m_cProcessInfo.hProcess, NULL, sDLLName,
0, (DWORD64)debug_event.u.LoadDll.lpBaseOfDll, 0);
strEventMessage.Format(L"Loaded DLL '%s' at address %x.",
sDLLName, debug_event.u.LoadDll.lpBaseOfDll);
...
Of course, similar code goes for process-load event. A caveat: initializing the symbol header and loading the
respective module successfully does not mean source-code information is available! We need to call
SymGetModuleInfo64 to determine if symbols in PDB are available. Here is how we do it:
IMAGEHLP_MODULE64 module_info;
module_info.SizeOfStruct = sizeof(module_info);
BOOL bSuccess = SymGetModuleInfo64(m_cProcessInfo.hProcess,dwBase, &module_info);
if (bSuccess && module_info.SymType == SymPdb)
{
strEventMessage += ", Symbols Loaded";
}
else
{
strEventMessage +=", No debugging symbols found.";
}
I am very thankful to Jochen Kalmbach for his excellent article on Stack-Walking, which has helped
me in locating source code information and walking the call-stack.
When the symbol type is SymPdb, we have source-code information available. Remember, a successful
PDB load does not mean source-code is available, the PDB only contains information about source-
code, the source code (.H, .CPP and other files) should be available at given path to view! The PDB contains
symbols names, file names, line number information etc. Stack-walking (without source-code view) is perfectly
possible, with fully qualified function names.
Finally, when breakpoint event arrives we can retrieve the call stack and display it. To do this we need to use
StackWalk64 funtion. The following code is stripped version, which shows the usage of this function.
Please refer to the Stack-Walking article I mentioned above for complete details.
void RetrieveCallstack(HANDLE hThread)
{
STACKFRAME64 stack={0};
StackWalk64(IMAGE_FILE_MACHINE_I386, m_cProcessInfo.hProcess, hThread, &stack,
&context, _ProcessMemoryReader, SymFunctionTableAccess64,
SymGetModuleBase64, 0);
...
STACKFRAME64 is the data-structure that holds addresses from where call-
stack information is retrieved. It essentially tells that current instruction location in given thread. For x86, as
described by Jochen, we need to initialize following members of this structure before calling
StackWalk64 function:
CONTEXT context;
context.ContextFlags = CONTEXT_FULL;
GetThreadContext(hThread, &context);
stack.AddrPC.Offset = context.Eip;
stack.AddrPC.Mode = AddrModeFlat;
stack.AddrFrame.Offset = context.Ebp;
stack.AddrFrame.Mode = AddrModeFlat;
stack.AddrStack.Offset = context.Esp;
stack.AddrStack.Mode = AddrModeFlat;
In call to StackWalk64, the first constant specifies the machine type, which is x86. Second
argument is the process (the debuggee). Third is the thread whose call stack we need to retrieve (not necessarily
primary thread). Fourth parameter is in/out parameter, which is most important argument for this function-call.
Fifth is a context structure, having required addresses initialized. Function _ProcessMemoryReader is
user defined function, which does nothing except calling ReadProcessMemory. Other two
Sym* functions are from DbgHelp.DLL. The last parameter is also function-pointer, and we don't need
that.
Walking the call stack definitely requires a loop till stack-walk finishes. Whilst there are issues
like invalid call-stack, never ending call stack and things like that. I chose to keep it simple: run it till
Return-Address becomes zero, or till StackWalk64 fails. This is how we enumerate the call
stack (symbol-name retrieval not yet shown):
BOOL bSuccess;
do
{
bSuccess = StackWalk64(IMAGE_FILE_MACHINE_I386, ... ,0);
if(!bTempBool)
break;
}while ( stack.AddrReturn.Offset != 0 );
The symbol has few properties attached to it:
- The module (DLL or EXE name)
- The name of symbol - undecorated or decorated.
- The type of symbol - function, class, parameter, local variable etc.
- The virtual address of symbol.
Stack-walking also includes:
- Source-file
- Line number
- First instruction (machine instruction) on that line.
Though, we don't need machine-instruction, unless dis-assembling the code, we may need the displacement from
first instruction. At source-code level, this may happen if multiple instructions exist (like multiple function
calls), on the same line. For now, I am omitting it altogether.
Hence, we need the module name, the function call and the line number as a complete Stack-entry.
To retrieve module name, respective to the address on stack, we use
SymGetModuleInfo64. If you recollect, there was similar function to load the
module info - SymLoadModuleXX, which is required to be called previously for
SymGetModuleInfo64 to work. Following code (which is just after StackWalk64 call inside
the loop), demonstrates how to retrieve module information for given address:
IMAGEHLP_MODULE64 module={0};
module.SizeOfStruct = sizeof(module);
SymGetModuleInfo64(m_cProcessInfo.hProcess, (DWORD64)stack.AddrPC.Offset, &module);
The variable module.ModuleName would contain the name of module, without extension
or path. Member module.LoadedImageName would refer to full module
name with full path and extension. The member module.LineNumbers would tell if Line-
number information is available or not (1=available). There are other useful members too.
Next, we retrieve the function name for this stack-entry. We retrieve this information using
SymGetSymFromAddr64 or SymFromAddr. Former returns
information via PIMAGEHLP_SYMBOL64 having 6 members in structure, while the latter returns via
SYMBOL_INFO which returns rich symbol information. Both take four arguments, out of which first 3 are
same, and last argument is pointer to desired structure. Here is an example of first function:
IMAGEHLP_SYMBOL64 *pSymbol;
DWORD dwDisplacement;
pSymbol = (IMAGEHLP_SYMBOL64*)new BYTE[sizeof(IMAGEHLP_SYMBOL64)+MAX_SYM_NAME];
memset(pSymbol, 0, sizeof(IMAGEHLP_SYMBOL64) + MAX_SYM_NAME);
pSymbol->SizeOfStruct = sizeof(IMAGEHLP_SYMBOL64);
pSymbol->MaxNameLength = MAX_SYM_NAME;
SymGetSymFromAddr64(m_cProcessInfo.hProcess, stack.AddrPC.Offset,
&dwDisplacement, pSymbol);
About this wicked code:
- Symbol name (
Name field of structure) may be of variable length. Thus, we need to put more buffer
for this variable. MAX_SYM_NAME is predefined macro having value 2000. - Since DbgHelp.DLL and this structure may have different versions,
SizeOfStruct must be initialized
to represent structure size we use. - Assignment of
MaxNameLength is pretty obvious.
For us, the important member of this structure are: Name, which is a null-terminated string.
Address, which is virtual address of the symbol (including image' base-address).
Using SymFromAddr and initializing SYMBOL_INFO is very similar, and I prefer using this
new function. Though, as of now, for us, there is no extra information. I would point out usefulness of this
extended structure, as the need arrives.
Finally, to complete the stack-entry, we need to find out the source-file name and appropriate line
number in it. Reminding you, the PDB contains this information, and source-info retrieval - only if correct PDB is
loaded successfully. Also, the PDB contains only information about source-code, not source-code!
To retrieve line-number information, we use SymGetLineFromAddr64, passing it a
IMAGEHLP_LINE64 structure. This function also takes four arguments, and first three are similar to
functions described above. It requires only SizeOfStruct to be properly initialized with with
structure size. It goes like this:
IMAGEHLP_LINE64 line;
line.SizeOfStruct = sizeof(line);
bSuccess = SymGetLineFromAddr64(m_cProcessInfo.hProcess,
(DWORD)stack.AddrPC.Offset,
&dwDisplacement, &line);
if(bSuccess)
{
}
Symbol functions, or any other function from DbgHelp.DLL does not support loading and displaying the source. We
need to do it by ourself. If the line number information, or the original source code is not available, we cannot
show the source-code-view.
As of this writing [19-Dec-2010], I have not decided what to be displayed when source code is not
available to display. We can display set of instructions, but x86 instructions aren't of fixed size, the
"instruction" per se doesn't fit. But bunch of machine code instructions (like "
55 04 FF 76 78
AE
...") having fixed instructions in one line can be displayed. Or we can dis-assemble the instructions
and show them instead. Though, I do have source code of disassembling the x86 machine-code, it doesn't support
complete instruction set.
By now I have shown you the important steps to stop debugging on start-address. This includes obtaining the
start address, putting breakpoint at that address, handling that breakpoint, reverting original instruction,
obtaining registers, call-stack, source-code and registers, and basic idea on how to display all this
information to UI. I have also elaborated that we need to use Windows event for halting and resuming the suspended
debuggee, as per user request.
As explicated somewhere in this article, to suspend the debuggee (i.e. keep it suspended when some stoppable
debug event occurs), we just dont call ContinueDebugEvent. As per the design of debugging-system,
it also ensures that any other running threads in debuggee, remain suspended.
Here is the abstract view of how halt and continue is supposed to execute (UT=User-interface
thread, DT=Debugger thread):
- [UT] User initiates debugging a process through given UI. This operation would not freeze the
UI.
- [
DT] Initializes a Windows event object using CreateEvent. It is non-signaled. - [
DT] The debugger starts the debuggee using CreateProcess. It enters the debugger-
loop. - [
DT] It receive the breakpoint event, which asks UI to display information and it halts. - [
DT] It uses WaitForSingleObject on that event to keep DT suspended. - [UT] User initiates some debugging actions, like Continue, Stop-debugging or
StepIn.
- [UT] It calls appropriate function to Resume-Debugging with the debugging-action
flag. It need to call
SetEvent to wake-up that DT. - [
DT] Wakes up, inspects the user-action and continues the debugging loop appropriately,
or terminates debugging if Stop action was given.
Everything will get more clear when I would depict the debugging-interface (a class), that I designed. If your
memory and/or inquisitiveness is working well while reading the article, you should know that I did not cover two
things:
- Actual code to retreive the start address (
GetStartAddress function!). Reminding you,
CREATE_PROCESS_DEBUG_INFO::lpStartAddress is the start-address, but won't be always correct. - How to handle user-defined breakpoints, which must execute more than once? The start-address breakpoint I have
discussed so far is just hit-once breakpoint, therefore reverting original instruction does the require
job.
May be you need to take a break, and/or read the un-cached stuff again! ;)
Anyway, since I have covered DbgHelp.DLL and Sym* functions I can present the code that retrieves start-address
of a process. The function name is SymFromName, which takes the symbol-name and
returs information in SYMBOL_INFO. The similar old function is SymGetSymFromName64 which
returns information in PIMAGEHLP_SYMBOL64 structure. Following is code that retrieves address of
wWinMainCRTStartup, using SymFromName function:
DWORD GetStartAddress( HANDLE hProcess, HANDLE hThread )
{
SYMBOL_INFO *pSymbol;
pSymbol = (SYMBOL_INFO *)new BYTE[sizeof(SYMBOL_INFO )+MAX_SYM_NAME];
pSymbol->SizeOfStruct= sizeof(SYMBOL_INFO );
pSymbol->MaxNameLen = MAX_SYM_NAME;
SymFromName(hProcess,"wWinMainCRTStartup",pSymbol);
DWORD dwAddress = pSymbol->Address;
delete [](BYTE*)pSymbol;
return dwAddress;
}
Ofcourse, it retrieves address of only wWinMainCRTStartup, which may or may not be start routine.
Well, there is more to go in this article - like determining if EXE specified is valid, is 32-bit module, is
unmanaged EXE, if it is Unicode/ANSI build and things like that. Keep reading!
User-defined breakpoints? I will describe about the mentioned issue when I would elaborate on creating user-
defined breakpoints.
I wrote an abstract class, having few pure-virtual functions that forms the foundation for debugging. Unlike
previous article, which was tightly integrated to UI and MFC, I made this class to be independent. I have used
native Windows handles, STL and CString class in this class. Remember, CString class may
be directly used in non-MFC applications, just by including <atlstr.h>, no linking with MFC is
required at all. I have placed this include in header-file of this class. If you are still discontent about
CString usage, please use your favorite class for string handling and change code appropriately.
[Subject to Change] Here is the basic skeleton of CDebuggerCore class:
class CDebuggerCore
{
HANDLE m_hDebuggerThread;
HANDLE m_heResumeDebugging;
PROCESS_INFORMATION m_cProcessInfo;
public:
int StartDebugging(const CString& strExeFullPath);
int ResumeDebugging(EResumeMode);
void StopDebugging();
protected:
virtual void OnDebugOutput(const TDebugOutput&) = 0;
virtual void OnDllLoad(const TDllLoadEvent&) = 0;
virtual void OnUpdateRegisters(const TRegisters&) = 0;
virtual void OnUpdateCallStack(const TCallStack&) = 0;
virtual void OnHaltDebugging(EHaltReason) = 0;
};
For few readers, reading about this user-defined class may not be appeasing. But this is how it is - to explain
about the debugger' code I must explain the code I wrote!
Since this class is abstract, it must be inherited and all virtual methods (On*) must be
implemented. Needless to mention, these virtual function are called by core class, depending on different debug-
events. Not a single virtual function demands return value or argument modification - you may keep the
implementations empty.
Assume you have derived a class named CDebugger, and implemented all virtuals. You start debugging
by using following code:
CDebugger theDebugger;
theDebugger.StartDebugging("Path to executable");
Which would just initialize required variables to set debugging-state, create the event handle I described
above,and spawn the debugger-thread. It will then return - that means StartDebugging is asynchronous call.
The actual debugging-loop is in DebuggerThread method (not shown above). It creates the given
executable using CreateProcess, and then enters debuging-loop controlled by
WaitForDebugEvent and ContinueDebugEvent, having switch-cases for the debug events. On
different debug events it calls appropriate On* method passing appropriate arguments. For instance, if
OUTPUT_DEBUG_STRING_EVENT arrives, it calls OnDebugOutput with a string parameter. For
other debugging events, it calls appropriate virtual functions. The derived class is responsible for displaying it
the UI.
Few debugging events that halts the debugging, like breakpoint event, the debugger-loop would first
call appropriate On* function(s) and then it would call HaltDebugging with proper
reason-code. This function is private to CDebuggerCore, and has declration like this:
enum EHaltReason
{
};
private:
void HaltDebugging(EHaltReason);
The implementation of this method is something like below, which halts the debugger-thread:
void CDebuggerCore::HaltDebugging(EHaltReason eHaltReason)
{
OnHaltDebugging(eHaltReason);
WaitForSingleObject(m_heResumeDebugging,INFINITE);
}
Since the debugger-loop knows the exact reason of halting, it passes it to HaltDebugging
which delegates it to OnHaltDebugging. The override, OnHaltDebugging, is supposed to
intimate the end-user about this debugging event. The UI thread doesnt freeze, but it awaits further user action.
The DT remains suspended.
With proper UI, like menus, shortcuts keys etc, the UI thread then calls ResumeDebugging function
with the resume-mode (i.e. how user responded to this halt event - Continue, StepIn, Stop-debugging?). The
ResumeDebugging method which takes an EResumeMode flag, sets this flag to a member
variable in class (of EResumeType itself) and then calls SetEvent to signal the event. It
resumes the debugger-thread (which is in HaltDebugging).
Now, after HaltDebugging returns (as a result to user-action), the debugger-loop tests
what action did user perform. For the same, it checks the member variable m_eResumeMode (of type
EResumeType), which was set by ResumeDebugging and continues debugging
appropriately; or it terminates, if flag is to Stop-debugging. Just for illustration, enum EResumeMode is
something like:
enum EResumeMode
{
Continue,
Stop,
StepOver,
};
There is more about CDebuggerCore class, but I have covered the basic skeleton and data/control flow
that goes around this class. Please see the attached source files and comments in it.
In this section, I would elaborate different debugging actions like placing a user breakpoint at some source
code location (i.e. at a line in source file), disabling or deleting the breakpoint, continuing from breakpoint,
stepping though source code line by line and similar debugging actions. As you very well know all these
actions would require proper source files to be displayed to the end user. Therefore is is important to learn how
to enumerate relevant source files, load the files, enumerate lines of source files.
Definitely, as you know well, the debuggee - the running process, i.e. the executable files does not contain the
source-file information. It is contained in referenced .PDB file (though other formats also possible, other than
PDB, but I would still talk about .PDB). To enumerate all source files related to the executable we call
SymEnumSourceFiles function. We would call the function on Process-load, and
optionally on Dll-load events. We should call this function only when SymGetModuleInfo64 succeeds and
the loaded module info says the symbol-type is PDB. To recollect, this is how we test it, followed by
SymEnumSourceFiles call:
BOOL bSuccess = SymGetModuleInfo64(m_cProcessInfo.hProcess, dwBase, &module_info);
if ( bSucess && module_info.SymType == SymPdb)
{
SymEnumSourceFiles(m_cProcessInfo.hProcess, dwBase,
NULL, EnumSourceFilesProc, this);
}
The first two arguments are quite understandable: the process and the base-address of module for which source-file
information is required. The third argument specified the filter. The 4th argument is a call back function, that we
must write. The last argument is nothing but a void-pointer parameter that would be passed to our callback function
for each file retrieval.
The signature of call back has to be:
BOOL __stdcall EnumSourceFilesProc(
PSOURCEFILE pSourceFile,
PVOID UserContext
);
It would be an insult to your knowledge, if I tell you that this function name is just placeholder - you can
name it whatever you like! The second parameter is the same void-pointer, also refered as user-context.
This function will be called unless enumeration finishes, or the function itself returns FALSE. Thus,
we would return TRU<code>E so that all source files can be enumerated.
The structure SOURCEFILE, from dbhhelp.h, is declared like:
struct SOURCEFILE
{
DWORD64 ModBase;
CHAR* FileName;
};
Since filename comes from a shared address of DbgHelp.DLL, we must copy the buffer, and save it.
A simple test run has shown me that it enumerates all source files, including .res, .inl,
and manifest files and all predefined header files. To limit source file enumeration, we can use the
filter argument (3rd argument of SymEnumSourceFiles). For instance, to enumerate only
.CPP files, we can call it as:
SymEnumSourceFiles(m_cProcessInfo.hProcess,dwBase, "*.CPP", EnumSourceFilesProc, this);
Specifying multiple wild card isn't supported. We must call this function multiple times to enumerated different
extensions. (I don't have much time to explore this).
Anyway, using this function, in the callback function, we can store all required source files into a
vector or CString. Further to this, we can let user place breakpoints in any of these
source files. As of now, the our debugging-interface is designed such that, the user would be able to
locate these source files only after first break point is hit (i.e. main). In near future, I
would make changes to facilitate placing user breakpoints before actually starting the debugging.
Being a programmer, you are well aware that not everyline of source file is an executable line. Comments, Curly-
braces, blank lines, pre-processor directives are few elements that do not constitute a valid executable line. You
might have also observed that Visual Studio shifts ahead the misplaces breakpoints to next valid statement.
Therefore, it is necessary to enumerate lines that are valid executable lines.
To enumerate valid source-lines we can use SymEnumLines, which is
very similar to SymSnumSourceFile function. It requires process handle, base-address of module, a
filter to object file (.OBJ file), a filter to source file; and a call-back function and user-context (void-
pointer). First two arguments are same. We don't need third argument, that means we ask this function to enumerate
through all object-files. Fourth argument we pass is explicit filename with full path - the sourcefile. Since, we
have collected all source files with previous function, we have all source filenames. Here how it goes:
SymEnumLines(m_cProcessInfo.hProcess, dwBase, NULL, SourceFile, EnumLinesProc,this);
The 4th argument, is nothing but fullpath of a source file name. Assume this code is in a loop, where all
collected file names are being enumerated for valid lines. The sixth argument is user-context, which will be passed
to EnumLinesProc user-defined function. The declaration of EnumLinesProc must be as:
BOOL __stdcall EnumLinesProc(
PSRCCODEINFO LineInfo,
PVOID UserContext );
Other detail remain same for this call back. The SRCCODEINFO structure is declared
like:
struct SRCCODEINFO
{
DWORD64 ModBase;
DWORD64 ModBase;
WCHAR Obj[MAX_PATH + 1];
WCHAR FileName[MAX_PATH + 1];
DWORD LineNumber;
DWORD64 Address;
};
SymEnumLines calls our callback function for each valid/executable line till the current source file
enumeration is finished. Thus, Obj and FileName would be repeated. These two members will
be full-path to .OBJ file and source file respectively. The member LineNumber is important to us,
which will appear incrementing, and will only refer to valid line numbers. The last member is important for us -
the address of first instruction, which we will use to place breakpoints!
Once we have collected the source-code information using two of the functions enlightened above, we can now
facilitate end-user to place breakpoints directly from the source file. Till now, I have not shown any interface
(programming or UI) to show the source-file, but that's not important, it is just a matter of opening a text file
and displaying in some multiline edit/richedit control.
Visual Studio is smart enough to find more of invalid lines than we can do - VS would disable/delete
breakpoints placed at some nonsensical location (like on a pre-processor directive). We would apply simple
mechanism. Since, we have collected all source files and valid source lines, we first check if the line on which
breakpoint is placed is actually a valid line. If it is a valid line, then no issues - we happily make that address
a breakpoint (i.e. replace that instruction with 0xCC). If the line on which breakpoint
is placed is invalid, we find the next valid line (this would be trivial since we have the source line info).
Of course, there are cases when a module would be dynamically loaded by the process (via
LoadLibrary)
. For those cases, we need to allow any source file to be opened in our debugger, and also allow breakpoints
to be placed anywhere in any file. This is complex, yet important aspect; I would consider writing about it!
I know you want to see some action with "placing breakpoint", especially with user-breakpoints that
must be repeatable! What is a repeatable breakpoint, few of you might be confused. Let me refresh
your memory on breakpoints!
The breakpoint we placed at start-address is hit-once type of breakpoint - that code will not get
executed again, thus we just revert the (machine) code-byte. We don't care about preserving the breakpoint for
future hit. But with other breakpoints, you must ensure that breakpoint remain preserved. Therefore, after
breakpoint is hit, is it first reverted with original code, EIP reduced and actual (original) code gets executed.
Let me try to explicate it:
- End user puts a breakpoint at line
188 in source file MyApp.CPP. Let's say the
address is 0x0012345. - In the debugger, you grab what is at address
0x0012345, save it on some breakpoints-array. You
also save this address in some array. - You set the breakpoint instruction (
0xCC) at this location. For this, we use same set of
functions: Read/WriteProcessMemory and
FlushInstructionCache. - The break-point eventually arrives (
EXCEPTION_BREAKPOINT). You first check if it is user-
breakpoint. For this just search in breakpoints-addresses-array. If it is user-breakpoint, locate the original
code-byte, write it, flush it. Do EIP--, and SetThreadContext. - Continue debug event.
Break-points array? One more thing you don't understand? Just like you can place multiple breakpoints, the user
of your debugger can also! Ignore this array stuff, if you don't get it, you will understand it sooner or
later.
In abstract terms, if you understand the 5-step described above, you should know that as soon user-breakpoint is
hit, it won't hit again. You have reverted the instruction! To handle all this, you need to use sub-exception:
EXCEPTION_SINGLE_STEP (or STATUS_SINGLE_STEP, both are absolutely same).
Till now, we have been stopping program execution when break-point is hit (via EXCEPTION_BREAKPOINT),
and showing call stack, registers etc. But the correct way is to actually handle breakpoint in
EXCEPTION_SINGLE_STEP. You will understand why when you read following:
In EXCEPTION_BREAKPOINT event,
- Get thread context, save it.
- Reduce
EIP by one. - Set processor
trap flag for single stepping. - Set thread context.
- call
WriteProcessMemory, and FlushInstructionCache, as usual to revert
instruction.
In STATUS_BREAKPOINT event,
- Render the registers for the context saved in previous step.
- Enumerate call-stack from saved context.
- Halt debugging.
Now what is "trap flag"?
Trap flag, when set, asks the CPU to raise EXCEPTION_SINGLE_STEP for the instruction it is going to
execute. We set the trap-flag in EFlags member variable of CONTEXT. It is represented
by 8th bit of EFlags. Just use 0x100 or 256 to set it:
lcContext.ContextFlags = CONTEXT_ALL;
GetThreadContext(m_cProcessInfo.hThread, &lcContext);
lcContext.Eip--;
lcContext.EFlags |= 0x100;
SetThreadContext(m_cProcessInfo.hThread,&lcContext);
Remember, we reduce EIP by one, which essentially means we set the flag to current instruction - where the
breakpoint was placed. After above given code, we write and flush the original instruction. Therefore, as a result,
the next immediate exception arrives is EXCEPTION_SINGLE_STEP at the same instruction address. In
single-step processing, we dont reduce EIP, but we re-write breakpoint instruction (if it was actually a user-
defined breakpoint!). This essentially makes user-defined breakpoints repeatable!
As a final important note, EXCEPTION_SINGLE_STEP is not same as single-
stepping through the source code in your favorite debugger (F10/F11 in VS)! Also, the Trap-Flag is
automatically reset as soon as single-step exception arrives, which prevents this same debug-event to
arrive again. Therefore, you need not to reset this flag. Yes, of course, you can enable it everytime for
assembly/machine-code level debugging!
A good debugger should facilitate following code-stepping actions:
- Step-in to each and every line of at source-code level, this includes stepping-inside
the function calls. (F11 in Visual C++)
- Step-over, which is same as Step-in, but goes not steps-in to function calls. (Same
as F10)
- Step-out, which means coming out of currently executing function to the function which has
called this function. It essentially means popping-out current function from the Call-Stack. (Similar to Shift
+F11)
- Run-to-Cursor. Not exactly a code-stepping action. It means placing an invisible, hit-once
breakpoint to a given location. You can do the same with Ctrl+F10 in Visual C++ debugger, while debugging. (Look at
context menu while debugging).
- Set-next-Statement, which allows the debugger-user to set any line to be executed next. Terms
and conditions apply. In VS, it can be achieved through context menu (while debugging). The shortcut is Ctrl+Shift
+F10.
Surprisingly, all these debugging actions run around the core concepts that we have discussed so for:
- Replacing an instruction with 0xCC.
- Handling break-point exception. Adjusting EIP. Setting trap-flag.
- Handling single-step exception. Halt debugging, wait for user action.
Other than the last debugging action (Set-next-statement), all other actions would require invisible-
breakpoint. The instruction is same: 0xCC, handling is also same. The only difference is that
debuggers don't give any visual indication that it is actually a breakpoint. This is nothing but absence of Red-dot
on left of source-code in Visual Studio, or presence in 'Breakpoints' window (Alt+F9). Disabled, Invalid or any
other kind of user-specified breakpoints are not invisible-breakpoints - they are regular
breakpoints that user specified (or attempted to).
The start-address breakpoint, I had discussed before, is nothing but an invisible breakpoint. There is no visual
indication from debugger that it is actually a breakpoint. In VS, when you start program with F10 or F11, the
debugger would halt at main-function (like WinMain), but it is not actually a user-breakpoint
(no red-dot!).
In the debugger code, how we would differentiate between user-breakpoint and invisible-breakpoint? Quite simple.
The breakpoints-array, I discussed in last subsection, is for user-specified breakpoints. When a breakpoint is hit,
we find the exception-address in breakpoints-array. If found it is user-BP, otherwise it is invisible-BP. Though,
unless we provide visual or audio indication for "breakpoint", it doesn't make a difference.
In VS, the visual clue is the Red-icon on left and audio-clue can be enabled form Sounds
settings on Control Panel. In Sounds applet, goto Microsoft Visual Studio, specify a sound for
Breakpoint Hit entry. Restart Visual Studio. When a breakpoint is hit, the same sound would be
played. With this, I found out that user-breakpoint has priority over invisible breakpoint. Just place a breakpoint
to some line, and before that line press F10. The Step-over executes, but breakpoint-hit sound is also emitted! The
same goes for Run-to-cursor. I bet, you did not know this sound stuff!
Now, it is time to see some action. I am elaborating these debugging actions depending on complexity level
involved, simpler first. Please read them all.
Implementing Run-To-Cursor
For sure, it is nothing but an invisible, one-shot breakpoint instruction. For this, we just place a breakpoint
at given location in source code, and do not put this address in break-points array. When it is
hit, just halt the execution, show "Debugging" / "Debugging-halted" in some UI, wait for user-
action, and continue debugging as per user command.
It should be obvious to you that this action also requires 0xCC instruction to be placed at given address, be
saved, and then later reverted. Moreover, since the user is placing this invisible-breakpoint, we need to ensure
that source-file is valid, is loaded against Symbol-information, the line on which this command was given is valid
executable line. If line isn't valid executable line, we find next valid line and place this invisible-
breakpoint there. Consequently, it means the Run-to-cursor is adjusted appropriately.
Remember, user-breakpoints takes priority over invisible-breakpoints. Therefore, if a user-BP is hit before Run-
to-cursor (or any other invisible-BP), that IBP would now be invalid (To verify, in VS, just place a BP before the
location of Run-to-cursor). Thus, we need to disable IBPs when any BP is hit. Also, there cannot be more than one
IBP pending to be hit at any time, so it is quite trivial to disable IBP! It essentially means that we need exactly
one variable for storing all stepping actions (including start-address IBP!). Even when multiple threads are
running, only IBP can be pending. Draw some sketches on paper to understand this paragraph, and unless you
understand it, dont proceed further!
Implementing Step-Over
For simplicity, let me cover Step-Over only to current function; that means excluding the case
when current function ends and program-execution goes to caller. I would cover this implicit stepping-out from a
function when I would explicate on Step-Out implementation.
Let's have sample code for understanding:
int Max(int n1,int n2)
{
if(n1 > n2)
return n1;
else
return n2;
}
int main()
{
int a, b;
a = 10;
b = 20;
Max(20,30);
printf("Max is %d", Max(a,b));
return 0;
}
Here, for function main, only the lines marked with //* are valid
executable lines. These are the same lines returned by SymEnumLines function. Therefore, we would the
collect line information, store the line numbers and associated addresses. Let's say the line number information
(only for main) are enumerated as below:
Line Address
12 0x411400
14 0x41141e
15 0x411425
17 0x41142c
19 0x411438
21 0x411460
22 0x411462
You definitely need not to understand how these addresses are formed, it all depends on source code, compiler
and linker settings (optimizations, incremental linking, FPO etc) - Ignore it. All we need is to utilize these
lines and addresses for Step-over implementation. First assume that program execution is now sitting at line 12
(via start-address IBP mechanism). That means EIP is 0x411400 !
Debugger is waiting for user input (debugger-loop is on halted on WaitForSingleObject). Now,
debugger-user asks to Step-over.
- The UI-threads calls
CDebuggerCore::ResumeDebugging with EResumeFlag set to
StepOver. - This tells the debugger thread (having the debugger-loop) to put IBP on next line.
- The debugger-thread locates next executable line and address (
0x41141e), it
places an IBP on that location. - It calls then
ContinueDebugEvent, which tells the OS to continue running debuggee. - The BP is now hit, it passes through EXCEPTION_BREAKPOINT and reaches at EXCEPTION_SINGLE_STEP. Both these
steps are same, including instruction reversal, EIP reduction etc.
- It again calls HaltDebugging, which in turn, awaits user input.
And this process can go as long as user wishes, or program ends (or, of-course, till another exception occurs!).
One important aspect I did not cover, is to disable IBP on any normal BP occurrence, before this IBP is hit.
This means, if user has placed breakpoint somewhere in function Max, and the program execution is now
passing (in main) over this function. It would hit that UBP in Max, and then user might
hit F5 (Continue). Our buggy debugger, would halt at next line in main! I will de-bug this
issue soon.
Implementing Step-In
This isn't easy! This is the most difficult part of writing a debugger!
Whilst it would be similar to Step-Over implementation, we need to dis-assemble the code, and
to understand what next statement means (at assembly/machine-code level). Herein, I am attaching a
disclaimer, that I am not assembly expert! Therefore, the following text should be treated as
idea/concept/hint - refer to Intel's x86 instruction documentation for complete information about opcodes.
As I had commented before, the x86 instructions are not of fixed length. Each instruction can
be of 1 byte, or more than one bytes (I have seen max of 7-byte x86
instructions). The BP instruction, 0xCC, is a one byte instruction. The processor understands
all instructions opcodes, and their lengths, and it executes it as atomic instruction. For example, consider
following simple code:
Max(10,20);
Which is disassembled as:
6A 1E push 1Eh
6A 14 push 14h
E8 C2 FD FF FF call 00400E00
83 C4 08 add esp,8
I am not putting assembly jargons here, just about the above' code. First two x86 instructions are
pushing arguments to stack. The third line is making a call to function Max.
Therefore we need to hook the call instruction!
Hooking? Not exactly. We need to find the address where call instruction exists in instruction-set
of debuggee. We can use ReadProcessMemory for the same. And, on that address we place an IBP - and
rest of the things you already know.
When do we do it? When user says step-in (F11), we start searching for this instruction from current EIP, till
we find call instruction.
The toughest part is locating the call instruction. No, this is not as easy as searching for op-
code E8. Following are the reasons:
E8 is not the only instruction for function-calling, there are few others
too.- The x86 instructions are not of fixed size. As you can see from assembly code above, first two instructions are
of 2 bytes each (
push), the call instruction is of 5 bytes, and last instruction is of 3
bytes! - We need to dis-assemble code instructions properly. Dis-assembling is quite complicated task, and with more new
CPU instruction (SSE2 etc), it becomes more troublesome. For the same, it is mandatory that we know the instruction
size, at least, so that that unknown instruction can be ignored safely.
- Each
call instruction, including E8, is different, and they need appropriate
interpretation.
I do need to do further research and development, on this subject; and only after that I can present a practical
and workable solution. Till then, for completeness, I can outline how Step-In can be implemented.
- [When F11 is hit] From the current instruction location, ignoring the current complete-instruction,
read all instruction bytes till next valid executable line (collected via
SymEnumLines). - Do partial or full dis-assebmly, as applicable/possible.
- Analyze the assembly, locate one of the
call instructions.
- If found, place IBP at that location. The IBP processing goes as usual.
- If not found, just process as if it was Step-Over debugging-action.
The function, if call was found, would now be called, and call-stack would now be changed. The called
function may be in different source file. In either case, this function would eventually exit and program-control
would go back to caller. And this needs processing of Step-out, which is described below. Along with this, there
may be more than one call instructions in same executable source-code line. Following is an
example:
printf( "%d, %d", max(10,20), min(min(20,30),40) );
Implementing Step-Out
Stepping-out from a function is the nearly inverse of Step-In debugging action. If you are debugging in
Dis-assembly mode, Step-In (F11) will let you debug at instruction level; and from that point if you do Step-Out,
it would be stepping out from the high-level "function", as if you were performing Step-In in source-code
mode. That's why I said nearly!
To implement Step-Out debugging action, we need help from our friend function StakWalk64.
If you remember, stack-walking is achieved with loop; and in that loop we call StackWalk64 multiple
times till Return-address becomes zero:
STACKFRAME64 stack;
do
{
StackWalk64(..., &stack, ..);
} while(stack.AddrReturn.Offset != 0);
The variable AddrReturn, of type ADDRESS64, holds the return address where the program
control would go. Let's not go into how it is implemented at assembly level, but the return-address is
somehow stored, and program-control gets transferred when a function implicitly or explicitly
returns to its caller. The return-address is the next statement after the call statement.
Therefore, for the following pseudo-assembly code:
00401070 call 0x1234000
00401075 mov abc, xyz
which is calling the function 0x1234000, the return-address from function 0x1234000
would be 0040175 (and not 0040170).
Therefore, you just need to call StackWalk64 only once, note the return-address, and place a IBP
over there and your Step-Out is implemented!
If multiple function calls are involved in same source-code line, they would have multiple call
statements at assembly level, and they all would have respective return-addresses. Thus, it is quite possible for
debugger-user to hit F11, Shift+F10 (step-out) or F10 for same source-code line.
Though, we would be displaying only the source-code, in the debugger, we know where exactly the instruction
(EIP) is - the IBP, single-step exceptions, Debugging-APIs are assisting us for the same. Therefore, we need not to
bother if user hits F11, then returns from that function (implicitly or explicitly), and then hits F11 again for
source-line having more than one function calls (like in printf example given above).
Let's consider another case when user hits F10, after returning from first sub-function call (into which he/she
entered via Step-In). Here, the execution, at source-code level, is in midst - and at assembly level, few
calls are made, and few more instructions (including calls, if any) are pending for
execution. The user has hit F10! What should happen? Well, if you look back to the implementation of Step-Over, you
would find that Step-Over just looks for next executable line (at source-code level), and places an IBP on
next-instruction! Therefore, we need not to worry about this complicated case, either!
What if a user-BP is hit before function returns from F11/F10 debugging-action? That means, in following
function:
printf("Next prime: %d", NextPrime(1000));
Were NextPrime is supposed to return next prime number from given number, which, for example calls
IsPrime function. User has placed a BP somewhere in IsPrime. Now, when program control
comes over this printf line, user hits F11, which would Step-Into NextPrime; and then he/she
immediately hit Shift+F11. Where the program control should go: To next line of printf call, or
To that breakpoint in IsPrime?
Reminding you! User breakpoints have priority over any Invisible breakpoints. The program control would go to BP
in IsPrime, and IBP placed at return-address of NextPrime (which was placed by debugger
for Step-Out debugging-action), would be disabled by debugger!
What if user says Run-To-Cursor, in this complicated situation? Pardon me! Do you need same text to read again!
Analyze yourself! :)
Implementing Set-Next-Statement
Well, a single threaded implementation just needs to adjust EIP to the address of given line. That means, when
user says Set-next-statement (SNS), we look up the lines information we had collected. Verify if
given/selected line is valid executable line (if not just find the next valid line as we do for BP). Grab the
address of that line, and set EIP to that address using SetThreadContext (after
GetThreadContext).
Of course, just like VS Debugger does, we need to check if given line falls within same function, or it is from
different function. If it is from different function, we can ask the confirmation from user. My testings have
revealed that VS debugger, even in case of cross-function SNS action, just adjusts EIP appropriately and nothing
else!
Debuggers also provide placing conditional breakpoints, where condition can be combination of following:
If two or more categories are applied to same breakpoint, it depends on the debugger to trigger them with
AND or OR applied. That means if I place expression as well as filter
it, the debugger can see if both of these conditions are met, or any of these. Visual Studio debugger
applies AND.
Now the million-dollar question is: How do we implement conditional-breakpoint feature in our debugger?
The first type of CB implementation (expression) is of distant-future, since it involves knowing the
variables, data types, constants etc; that are in debuggee. The DbgHelp functions are not rich enough to support
querying such rich information. For this we have to use DIA (Debug Interface Access),
which I am not willing to discuss (or learn by myself) at this moment, unless I finish this article. Nevertheless,
the idea described below can be used for Expression CB implementation.
In our debugger, UBPs are stored in some breakpoints-array. Now, when a UBP is applied with a condition, Or a
brand new conditional BP is placed by debugger-user, we can put that UBP into another BP-array that would be
holding conditions. The data-structure or algorithm isn't important here, only the basic idea. We may use
maps, hash-maps to store breakpoints. Store a breakpoint information in some structure, whose condition
member would be null/empty when CB not set, or things like that.
When a breakpoint is hit, we instantly check if a condition is attached to it, and if it is true. If it is true,
we let user notify that BP is hit, otherwise we silently ContinueDebugEvent without user knowing
about. Irrespective of BP is hit or not, the BP magic must go around our debugger (0xCC, break-point
exception, EPP--, SetThreadContext, Single-step exception...). That means, if BP is
enabled it would always arrive in the debugger!
When a hit-count CB is applied, just count the hits, and break the debuggee on UI when specified hit-count
condition is hit. Again, programming elements we use inside debugger is not important here.
Similarly, constraints types of CB can be implemented quite easily. We just need to facilitate what are
the set of constraints. I may list few:
- Thread should match; or should not match.
- There should be more than; or less than N number of total threads running.
- Only after particular thread is loaded, not-loaded or unloaded from debuggee.
- Some constraints with the number of processes already running.
- Should hit only if called; or not called, from a specific function.
- Should hit when memory usage exceeds some value.
- Check the delay between two breakpoint hits, and notify only when some timeout condition is met. For example,
hit if there is 5 second or more delay hitting the same BP.
Implementing all these isn't difficult! We need to use few functions (API), employ some data-structures, code
some smart stuff and the work is done! Therefore, I am not elaborating them here.
While I still have not covered about multiple threads running in debuggee, I am straightaway jumping on
debugging
a running process. There is no strong reason of delaying the discussion of Multithreaded Debugging, I just
found this subject worth elaborating before MT debugging. The dialogbox Attach to
Process might be known to you, which you can launch either from Tools or
Debug menu (or by Ctrl+Alt+P):
Attach to Process
To debug a running process you need to call DebugActiveProcess function, with a process ID, and then it
enters the debugger-loop controlled by WaitForDebugEvent. Therefore, you can say that you are just
replacing CreateProcess with DebugActiveProcess and rest of debugger-loop part remain
same. There are, however, some differences:
- All threads in the process (debuggee) will be suspended.
- The process is already running, along with its threads. Thus, by design,
lpStartAddress member of CREATE_PROCESS_DEBUG_INFO and
CREATE_THREAD_DEBUG_INFO (not discussed yet) will be null. One event notifying process-start will be
delivered, and CREATE_THREAD_DEBUG event will be sent for each running thread. - For each DLL that is currently loaded in debuggee, either implicitly or explicitly, the debugger would receive
LOAD_DLL_DEBUG_EVENT.
- The debugger will now receive first-breakpoint instruction, which is always sent to a debugger (as you know!).
This would occur from the first thread of debuggee. The debugger would (should) continue from this point.
- All threads will now be resumed by system (of course, excluding the threads not suspended by debuggee
itself).
There are some constraints:
- The debugger must have appropriate permission to debug a particular process. If debugger is running as
normal/non-elevated process, it cannot debug a process having administrative/elevated token. This can be achieved
by running the debugger as elevated process. The Run As Administrator verb while launching the
debugger can be used. Or to run the debugger always as elevated process (for Vista or higher, on VS2008 and
higher), UAC linker flag can be set to
requireAdministrator. - Our 32-bit debugger cannot debug a 64-bit process, irrespective of its permission level.
- Since our debugger is native-code debugger, it cannot debug a managed processes. It can however, debug a mixed
mode process. More on this later.
For long we have discussed starting a process for debugging, and recently discussed how to debug a running
process. What about detaching this relationship? Is it always required to wait until
debuggee exits, or has to quit due to unhandled exception? Until now, the debugger design was to wait until process
exits by itself. We now cover two important aspects: Terminating the debuggee and
Detaching the debuggee.
Terminating the Debuggee
By design, as mentioned in DebugSetProcessKillOnExit function, the debuggee would terminate if the thread that created the
debuggee (i.e. the one having debugger-loop) exits. But I found this to be false. The debuggee does not end, if
debugger just says "bye-bye" asking the debuggee to do whatever it wants to do, by just
returning from the debugger-thread. It enters a Limbo state, doing nothing.
It also denies any other debugger to attach on it for debugging (yes, the OS enforces it, not debuggee). Using
Process Explorer, I found a valid call-stack, which clearly sounds-out that debuggee is waiting for
ContinueDebugEvent!
May be this is not as per current Operating Systems and MSDN is not modified to reflect this.
Therefore, to terminate the debuggee, we need to use TerminateProcess function. Doing this, when requested by
debugger-user, would ask for EXIT_PROCESS_DEBUG_EVENT to occur next. This goes true, irrespective
which thread calls TerminateProcess function. I have found that if we call this function as soon as
debuggee is launched, the system would still process all process-loading, dll-loading debugging events and then
send this event to debugger!
In Visual Studio, we achieve the same by Debug->Stop Debugging or using infamous
Shift+F5 keystroke. For any debugger, implementing stop-debugging would be same irrespective how
debuggee was launched/attached. Therefore, it is also possible to terminate a process which cannot be terminated
using TaskManager (not all, though)!
Detaching the Debuggee
I believe this is quite uncommon task the software engineers perform. The concept is simple: detach the
debugger-debuggee relationship and set debuggee free. This is not terminating the debuggee, nor putting the
debuggee into a limbo state. It is just unbinding the debuggee from debugger. After detaching from debuggee, any
next unhandled debugging event would be presented default crash handler (!!).
In Visual Studio, you can do the same by Debug->Detach All command, which will set
debuggee free! If you are in single stepping mode (i.e. actively debugging a program), and then you detach
from debuggee, it would simply release the debuggee from debugger and would continue from that point on. Try it
out!
Therefore, it is perfectly possible to do following:
- Start any process normally.
- Attach to it, start debugging.
- Perform debugging, even at source code level, if possible.
- Once you have done debugging, or analyzed how process is doing, you can detach from debuggee, and set it
free.
Of course, to perform debugging, you need to place some breakpoints (at source-code, or at assembly level). If
you want to just break wherever process is, use Debug->Break All, which will suspend
all threads and present you call stack of primary thread. Break-All is also applicable for processes you have
started. Break-All is only applicable if you are not actively debugging - since there is
nothing to break.
After long therotical session, here is the function you need: DebugActiveProcessStop, which just takes one parameter: the
Process-ID.
Depending on your Windows OS version and settings, when an application crashes, you may see one of the few
standard "Application has stopped working" dialog box. On Windows Vista and higher you can go to
Action Center and change the settings. You may encounter dialog like:
Or a delayed dialogbox like:
In both of the cases, you have the opportunity to Debug the crashing application. If you
carefully (or partially) reading this article, you can now understand what "Exception
Code" in the first dialog would mean. This is access-violation exception
(EXCEPTION_ACCESS_VIOLATION) that would arrive under EXCEPTION_DEBUG_EVENT.
So, what happens when user hits Debug? Well, it launches the default crash
handler, which must have been setup in registry. If it is not setup, you won't see the Debug button!
If you have installed any program that allows debugging, like WinDbg or Visual Studio, you would see the Debug
button. The Windows system keeps information about crash-handler at following location in registry:
- HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\AeDebug
If your OS is 64-bit, there would be additional entry at following location for debugging 32-bit crashing
processes:
- HKLM\SOFTWARE\Wow6432Node\Microsoft\Windows NT\CurrentVersion\AeDebug
I am not aware of what AE means in the key-name (or you can say I've not tried hard). While
there are few Values and Keys under this key; for us, Debugger string-value is of interest. The
Debugger value would have the full path of debugger and following two arguments:
-p %ld - Specifies the process identifier. The same process-Id we can use in
DebugActiveProcess to start debugging a running process. %ld is a placeholder where
the system would put the actual process-id while launching the debugger.-e %ld - Handle to Windows event object which will
be used to intimate the system that debugger has started debugging. This is not a debugging-event,
but an <code><code><code><code><code><code><code><code>EVENT
object. As soon as debugger start debugging (i.e. enters debugger-loop), it calls
SetEvent to let the system know that debugger has started debugging and can release the control to
debugger.- Any additional parameters the custom debugger takes.
By now you must have seen that Debugger entry is set to:
- "C:\Windows\system32\VSJitDebugger.exe"
-p %ld -e %ld
Which is self-explanatory. If you have multiple version of Visual Studio installed, "Just-in-Time
Debugger" dialogbox would be shown. Note that, by this time, the debugger is not attached - it would be
attached only when user confirms. For us, the JIT dialogbox, and how it enumerates installed VS debuggers, is of no
interest - it is relevant to VS and not to Windows OS for Debugging.
I can judge your intelligence, that you already deduced we just need to put the path of our debugger in
Debugger registry entry, along with required -e and -p parameters. And
at the debugger level, we need to check these arguments and act appropriately. We must have to call
SetEvent to the handle provided (of course by typecasting it to HANDLE), as soon as we
start debugging the crashing process.
On 64-bit OS, if a 64-bit process crashes, the default AeDebug entry will be read. If a 32-bit
process crashes the AeDebug entry under Wow6432Node will be read. A 64-bit debugger can debug
either type of process. A 32-bit debugger can debug only 32-bit process - and attempt to debug 64-bit process
(either via CreateProcess or DebugActiveProcess) would simply fail.
On 32-bit OS, there would only be default AeDebug entry which will be used to debug 32-bit
processes. I am not aware of 16-bit application crashes on 32-bit OS!
Therefore, our debugging kingdom is only limited to 32-bit OS, or to Wow6432Node on 64-bit OS.
What if we build our debugger as 64-bit process? Well... boy, that would not work because of CONTEXT
structure - there are architecture differences. The EIP register, for example, is not valid on 64-bit architecture.
Also, the 64-bit architecture is not consistent - x64 and Itanuims for example as different!
This is not same as either of two approaches:
- Using Attach to Process from your favourite debugger.
- Selecting 'Debug' on a crashing process
In the first approach, the debugger would enumerate all processes that can be debugged. Thus, when a debugger-
user selects a process, it passes the same process-id to DebugActiveProcess and debugger-loop
starts.
In second approach, the debugger starts debugging a process through -p
process-id, and notifies the system by signaling the received event (via -e).
The third approach can be used by any user from Task Manager, or Process Explorer. The user would select Debug
from context menu (or whatever user-interface the utility has provided). The process-viewer would look for Debugger
entry in AeDebug key and start the given process for debugging this process. Here, only
-
p
will be passed, since the selected process is running fine (i.e. no unhandled exception
occurred). The debugger will enter debugger-loop for the process-id received.
If 'Debugger' entry is missing, the process-viewer utility will disable or hide the Debug menu. Task
Manager hides it, while Process Explorer does not show the Debug entry in context menu, if this
information is missing in registry.
I have seen that for both 32-bit and 64-bit processes, both TM and PE use the default AeDebug key, and not the
key under Wow6432Node, for attaching the debugger. That means, even if process is 32-bit, still the 64-bit debugger
(by registry-definition) would be invoked.
Note: There can be only one debugger attached to a process, irrespective how the debugger-debuggee relationship is made. The second attempt may not be allowed by utility - if mistakenly allowed, the request to attach a debugger would simply be rejected by system.
...
Article is not complete yet. This is such an intricate subject, which requires time, research,
zillion-time debugging the debugger and what not! Since I wrote (and writing) this much, I could not resist myself
from publishing and sharing this information!
In my TODO list (I need to finish fast!):
- Placing user-breakpoints
- Showing call stack
- Allowing debugging actions (Stepping etc).
- Showing source code
- Multi threaded debugging
- Attaching to existing process (also, 'Attach Debugger' from task manager)
- Detaching from being-debugged process
- Making it the Crash-handler debugger.
- Showing dis-assembly when no source-code is available (probably not in this part).
- More!
For sure, a well-documented source code, and a sample Debugger would be attached, soon! Till then, you can
bug me with bug reports!
History
- December 16, 2010 - Initial public release
- December 18, 2010 - Symbol retrieval
- December 19, 2010 - Debuggee halt-resume functionality, CCoreDebugger class.
- December 22, 2010 - Source file enumeration, placing user breakpoint (CPU trap flag)
- December 25, 2010 - Stepping through the source-code
- December 29, 2010 - Step-Out, Set-next-statement and Conditional Breakpoints
- January 9, 2010 - Debugging a running process, default crash handler

