Table of Contents
Simple Code Examples
<Books>
<Book>
<Price>12.990000</Price>
</Book>
</Books>
To create the above XML, see the C++ code below:
Elmax::Element root;
root.SetDomDoc(pDoc); root[L"Books"][L"Book"][L"Price"] = 12.99f;
The third line of code detects that the three elements do not exist, and the float assignment will attempt to create those three elements and convert 12.99f to string and assign it to the Price element. To read the Price element, we just assign it to the float variable (see below):
Elmax::Element root;
root.SetDomDoc(pDoc); Elmax::Element elemPrice =
root[L"Books"][L"Book"][L"Price"];
if(elemPrice.Exists())
float price = elemPrice;
It is a good practice to check if the Price element exists, using Exists(), before reading it.
Introduction
Over the years in my profession as a C++ software developer, I had to infrequently maintain XML file formats for application project files. I found the DOM to be difficult to navigate and use. I have come across many articles and XML libraries which purported to be easy to use, but none is as easy as the internal XML library co-developed by my ex-coworkers, Srikumar Karaikudi Subramanian and Ali Akber Saifee. Srikumar wrote the first version which could only read from an XML file, and Ali later added the node creation capability which allowed the content to be saved in an XML file. However, that library is proprietary. After I left the company, I lost the use of a really-easy-to-use XML library. Unlike many talented programmers out there, I am an idiot; I need an idiot-proof XML library. Too bad, LINQ-to-XML (Xinq) is not available in C++/CLI! I decided to re-construct Srikumar's and Ali's XML library, and made it Open-Source! I dedicate this article to Srikumar Karaikudi Subramanian and Ali Akber Saifee!
XML vs. Binary Serialization
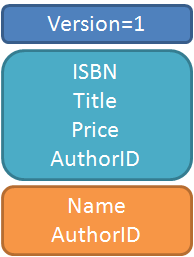
In this section, let us look first at the advantages of XML over binary serialization before we discuss Elmax. I'll not discuss XML serialization because I am not familiar with it. Below is the simplified (version 1) file format for an online bookstore:
Version=1
Books
Book*
ISBN
Title
Price
AuthorID
Authors
Author*
Name
AuthorID
The child elements are indented under the parent. The elements which can be more than 1 in quantity are appended with an asterisk(*). The diagram below shows what the (version 1) binary serialization file format will typically look like:
Let's say, in version 2, we add a Description under Book and a Biography under Author.
Version=2
Books
Book*
ISBN
Title
Price
AuthorID
Description(new)
Authors
Author*
Name
AuthorID
Biography(new)
The diagram below shows versions 1 and 2 of the binary serialization file format. The new additions in version 2 are in lighter colors.

Notice that versions 1 and 2 are binary incompatible? Below is how the binary (note: not binary serialization) file format would choose to implement it:
Version=2
Books
Book*
ISBN
Title
Price
AuthorID
Authors
Author*
Name
AuthorID
Description(new)*
Biography(new)*
This way, version 1 of the application still can read the version 2 binary file while ignoring the new additional parts at the back of the file. If XML is used and without doing any work, version 1 of the application still can read the version 2 XML file (forward compatible) while ignoring the new additional elements, provided that the data types of the original elements remain unchanged and not removed. And the version 2 application can read the version 1 XML file by using the old parsing code (backward compatible). The downside to XML parsing is that it is slower than the binary file format, and takes up more space, but XML files are self-describing.
Below is an example of how I would implement the file format in XML, which is followed by a code example to create the XML file:
="1.0"="UTF-8"
<All>
<Version>2</Version>
<Books>
<Book ISBN="1111-1111-1111">
<Title>How not to program!</Title>
<Price>12.990000</Price>
<Desc>Learn how not to program from the industry`s
worst programmers! Contains lots of code examples
which programmers should avoid! Treat it as reverse
education.</Desc>
<AuthorID>111</AuthorID>
</Book>
<Book ISBN="2222-2222-2222">
<Title>Caught with my pants down</Title>
<Price>10.000000</Price>
<Desc>Novel about extra-martial affairs</Desc>
<AuthorID>111</AuthorID>
</Book>
</Books>
<Authors>
<Author Name="Wong Shao Voon" AuthorID="111">
<Bio>World`s most funny author!</Bio>
</Author>
</Authors>
</All>
The code:
#import <msxml6.dll>
using namespace MSXML2;
HRESULT CTryoutDlg::CreateAndInitDom(
MSXML2::IXMLDOMDocumentPtr& pDoc)
{
HRESULT hr = pDoc.CreateInstance(__uuidof(MSXML2::DOMDocument30));
if (SUCCEEDED(hr))
{
pDoc->async = VARIANT_FALSE;
pDoc->validateOnParse = VARIANT_FALSE;
pDoc->resolveExternals = VARIANT_FALSE;
MSXML2::IXMLDOMProcessingInstructionPtr pi =
pDoc->createProcessingInstruction
(L"xml", L" version='1.0' encoding='UTF-8'");
pDoc->appendChild(pi);
}
return hr;
}
bool CTryoutDlg::SaveXml(
MSXML2::IXMLDOMDocumentPtr& pDoc,
const std::wstring& strFilename)
{
TCHAR szPath[MAX_PATH];
if(SUCCEEDED(SHGetFolderPath(NULL,
CSIDL_LOCAL_APPDATA|CSIDL_FLAG_CREATE,
NULL,
0,
szPath)))
{
PathAppend(szPath, strFilename.c_str());
}
variant_t varFile(szPath);
return SUCCEEDED(pDoc->save(varFile));
}
void CTryoutDlg::TestWrite()
{
MSXML2::IXMLDOMDocumentPtr pDoc;
HRESULT hr = CreateAndInitDom(pDoc);
if (SUCCEEDED(hr))
{
using namespace Elmax;
using namespace std;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element all = root[L"All"];
all[L"Version"] = 2;
Element books = all[L"Books"].CreateNew();
Element book1 = books[L"Book"].CreateNew();
book1.Attribute(L"ISBN") = L"1111-1111-1111";
book1[L"Title"] = L"How not to program!";
book1[L"Price"] = 12.99f;
book1[L"Desc"] = L"Learn how not to program from the industry`s
worst programmers! Contains lots of code examples which
programmers should avoid! Treat it as reverse education.";
book1[L"AuthorID"] = 111;
Element book2 = books[L"Book"].CreateNew();
book2.Attribute(L"ISBN") = L"2222-2222-2222";
book2[L"Title"] = L"Caught with my pants down";
book2[L"Price"] = 10.00f;
book2[L"Desc"] = L"Novel about extra-martial affairs";
book2[L"AuthorID"] = 111;
Element authors = all[L"Authors"].CreateNew();
Element author = authors[L"Author"].CreateNew();
author.Attribute(L"Name") = L"Wong Shao Voon";
author.Attribute(L"AuthorID") = 111;
author[L"Bio"] = L"World`s most funny author!";
std::wstring strFilename = L"Books.xml";
SaveXml(pDoc, strFilename);
}
}
Here is the code to read the XML which was saved in the previous code snippet. Some helper class (DebugPrint) and methods (CreateAndLoadXml and DeleteFile) are omitted to focus on the relevant code. The helper class and methods can be found in the Tryout project in the source code download.
void CTryoutDlg::TestRead()
{
DebugPrint dp;
MSXML2::IXMLDOMDocumentPtr pDoc;
std::wstring strFilename = L"Books.xml";
HRESULT hr = CreateAndLoadXml(pDoc, strFilename);
if (SUCCEEDED(hr))
{
using namespace Elmax;
using namespace std;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element all = root[L"All"];
if(all.Exists()==false)
{
dp.Print(L"Error: root does not exists!");
return;
}
dp.Print(L"Version : {0}\n\n",
all[L"Version"].GetInt32(0));
dp.Print(L"Books\n");
dp.Print(L"=====\n");
Element books = all[L"Books"];
if(books.Exists())
{
Element::collection_t vecBooks =
books.GetCollection(L"Book");
for(size_t i=0; i<vecBooks.size(); ++i)
{
dp.Print(L"ISBN: {0}\n",
vecBooks[i].Attribute(L"ISBN").GetString(L"Error"));
dp.Print(L"Title: {0}\n",
vecBooks[i][L"Title"].GetString(L"Error"));
dp.Print(L"Price: {0}\n",
vecBooks[i][L"Price"].GetFloat(0.0f));
dp.Print(L"Desc: {0}\n",
vecBooks[i][L"Desc"].GetString(L"Error"));
dp.Print(L"AuthorID: {0}\n\n",
vecBooks[i][L"AuthorID"].GetInt32(-1));
}
}
dp.Print(L"Authors\n");
dp.Print(L"=======\n");
Element authors = all[L"Authors"];
if(authors.Exists())
{
Element::collection_t vecAuthors =
authors.GetCollection(L"Author");
for(size_t i=0; i<vecAuthors.size(); ++i)
{
dp.Print(L"Name: {0}\n",
vecAuthors[i].Attribute(L"Name").GetString(L"Error"));
dp.Print(L"AuthorID: {0}\n",
vecAuthors[i].Attribute(L"AuthorID").GetInt32(-1));
dp.Print(L"Bio: {0}\n\n",
vecAuthors[i][L"Bio"].GetString(L"Error"));
}
}
}
DeleteFile(strFilename);
}
This is the output after the XML is read:
Version : 2
Books
=====
ISBN: 1111-1111-1111
Title: How not to program!
Price: 12.990000
Desc: Learn how not to program from the industry`s
worst programmers! Contains lots of code examples
which programmers should avoid! Treat it as reverse education.
AuthorID: 111
ISBN: 2222-2222-2222
Title: Caught with my pants down
Price: 10.000000
Desc: Novel about extra-martial affairs
AuthorID: 111
Authors
=======
Name: Wong Shao Voon
AuthorID: 111
Bio: World`s most funny author!
Library Usage
In the section, we'll look at how to use the Elmax library to perform creation, reading, update, and deletion (CRUD) on elements, attributes, CData sections, and comments. As you can see from the previous code sample, Elmax makes use of the Microsoft XML DOM library. That's because I do not wish to re-create all that XML functionality, for instance, XPath. Since Elmax depends on Microsoft XML, which in turn depends on COM, to work, we have to call CoInitialize(NULL); to initialize the COM runtime at the start of the application, and also call CoUninitialize(); to uninitialize it before the application ends. Elmax is an abstraction over DOM; however, it does not seek to replicate all the functionality of DOM. For example, the programmer cannot use Elmax to read element siblings. In the Elmax model, an element is a first class citizen. Attribute, CData section, and comment are children of an element! This is different from DOM, where they are nodes in their own right. The reason I designed CData section and comment to be children of element, is because CData section and comment are not identifiable by a name or ID.
Element Creation
Element all = root[L"All"];
all[L"Version"] = 1;
Element books = all[L"Books"].CreateNew();
Typically, we use CreateNew to create elements. There is also a Create method. The difference is the Create method will not create elements if they already exist. Notice that I did not use Create or CreateNew to create All and Version elements. That's because they are created automatically when I assign a value to the last element on the chain. Note that when you call CreateNew repeatedly, only the last element gets created. Let me show you a code example to explain this.
root[L"aa"][L"bb"][L"cc"].CreateNew();
root[L"aa"][L"bb"][L"cc"].CreateNew();
root[L"aa"][L"bb"][L"cc"].CreateNew();
In the first CreateNew call, elements aa, bb, and cc are created. In each subsequent call, only the element cc is created. This is the resultant XML created (and indented for easy reading):
<aa>
<bb>
<cc/>
<cc/>
<cc/>
</bb>
</aa>
Create and CreateNew have an optional std::wstring parameter to specify the namespace URI. If your element belongs to a namespace, then you must create it explicitly, using Create or CreateNew; this means you cannot rely on value assignment to create it automatically. More on this later. Note: when calling instance Element methods other than Create, CreateNew, setters, and accessors when the element(s) does not exist, Elmax will raise an exception! When do we use Create instead of CreateNew? One possible scenario is when the application loads an XML file, edits it, and saves it. In the edit stage, it does not check if an element exists in the original XML file before assigning it or adding nodes: call Create which will create it if it does not exist, otherwise Create does nothing.
Element Removal
using namespace Elmax;
Element elem;
Element elemChild = elem[L"Child"];
elem.RemoveNode(elemChild); elem.RemoveNode();
Note: For the AddNode method, you can only add a node which has been removed in the current version.
Element Value Assignment
In the beginning of the article, I showed how to create elements and assign a value to the last element at the same time. I'll repeat that code snippet here:
Elmax::Element root;
root.SetDomDoc(pDoc); root[L"Books"][L"Book"][L"Price"] = 12.99f;
It turns out that this example is dangerous as it uses an overloaded assignment operator determined by the compiler. What if you mean to assign a float but assigns an integer instead just because you forgot to add a .0 and append a f to the float value? Not much harm in this case, I suppose. In all scenarios, it is better to use the setter method to assign a value explicitly.
Elmax::Element root;
root.SetDomDoc(pDoc); root[L"Books"][L"Book"][L"Price"].SetFloat(12.99f);
Here is the list of setter methods available:
bool SetBool(bool val);
bool SetChar(char val);
bool SetShort(short val);
bool SetInt32(int val);
bool SetInt64(__int64 val);
bool SetUChar(unsigned char val);
bool SetUShort(unsigned short val);
bool SetUInt32(unsigned int val);
bool SetUInt64(unsigned __int64 val);
bool SetFloat(float val);
bool SetDouble(double val);
bool SetString(const std::wstring& val);
bool SetString(const std::string& val);
bool SetGUID(const GUID& val);
bool SetDate(const Elmax::Date& val);
bool SetDateTime(const Elmax::DateAndTime& val);
Element Value Reading
In the beginning of the article, I showed how to read a value from an element. I'll repeat the code snippet here:
Elmax::Element root;
root.SetDomDoc(pDoc); Elmax::Element elemPrice = root[L"Books"][L"Book"][L"Price"];
if(elemPrice.Exists())
float price = elemPrice;
This is the more correct version, using the GetFloat accessor to specify a default value.
Elmax::Element root;
root.SetDomDoc(pDoc); Elmax::Element elemPrice = root[L"Books"][L"Book"][L"Price"];
if(elemPrice.Exists())
float price = elemPrice.GetFloat(10.0f);
Price will get a default value of 10.0f if the value does not exist or is invalid, whereas the prior example before this, will get a 0.0f because a default value is not specified. But by default, Elmax does not know the string value is an improper float value in textual form, unless you use a Regular Expression to validate the string value. Set REGEX_CONV instead of NORMAL_CONV in the root element to use the Regular Expression type converter. As an alternative, you can use a schema or DTD to validate your XML before doing Elmax parsing. To learn about schema or DTD validation, please consult MSDN.
Elmax::Element root;
root.SetConverter(REGEX_CONV);
This is the declaration of the SetConverter method:
void SetConverter(CONVERTER conv, IConverter* pConv=NULL);
To use your own custom type converter, set the optional pConv pointer.
Elmax::Element root;
root.SetConverter(CUSTOM_CONV, pCustomTypeConv);
You are responsible for the deletion of pCustomTypeConv if it is allocated on the heap. There are locale type converters in Elmax, but they are not tested at this point because I am not sure how to test them, as in Asia, number representation is the same in all countries, unlike in Europe. Note: in version 0.9.0, data conversion is changed to use Boost lexical_cast; The option to use normal or regex conversion is removed. As a tip to readers who might be modifying Elmax, remember to run through all the 429 unit tests to make sure you did not break anything after a modification. The unit test is only available for running in Visual Studio 2010. Below is a list of value accessors available:
bool GetBool(bool defaultVal) const;
char GetChar(char defaultVal) const;
short GetShort(short defaultVal) const;
int GetInt32(int defaultVal) const;
__int64 GetInt64(__int64 defaultVal) const;
unsigned char GetUChar(unsigned char defaultVal) const;
unsigned short GetUShort(unsigned short defaultVal) const;
unsigned int GetUInt32(unsigned int defaultVal) const;
unsigned __int64 GetUInt64(unsigned __int64 defaultVal) const;
float GetFloat(float defaultVal) const;
double GetDouble(double defaultVal) const;
std::wstring GetString(const std::wstring& defaultVal) const;
std::string GetString(const std::string& defaultVal) const;
GUID GetGUID(const GUID& defaultVal) const;
Elmax::Date GetDate(const Elmax::Date& defaultVal) const;
Elmax::DateAndTime GetDateTime(const Elmax::DateAndTime& defaultVal) const;
For GetBool and the interpretation of a boolean value, true, yes, ok, and 1 evaluate to be true while false, no, cancel, and 0 evaluate to be false. They are not case-sensitive.
Namespace
To create an element under a namespace URI "http:www.yahoo.com", see below:
using namespace Elmax;
Element all = root[L"All"];
all[L"Version"] = 1;
Element books = all[L"Books"].CreateNew();
Element book1 = books[L"Book"].CreateNew(L"http://www.yahoo.com");
The XML output is as below:
="1.0"="UTF-8"
<All>
<Version>1</Version>
<Books>
<Book xmlns="http://www.yahoo.com"/>
</Books>
</All>
To create a bunch of elements and attributes under a namespace URI, see below:
using namespace Elmax;
Element all = root[L"All"];
all[L"Version"] = 1;
Element books = all[L"Books"].CreateNew();
Element book1 = books[L"Yahoo:Book"].CreateNew(L"http://www.yahoo.com");
book1.Attribute(L"Yahoo:ISBN").Create(L"http://www.yahoo.com");
book1.Attribute(L"Yahoo:ISBN") = L"1111-1111-1111";
book1[L"Yahoo:Title"].Create(L"http://www.yahoo.com");
book1[L"Yahoo:Title"] = L"How not to program!";
book1[L"Yahoo:Price"].Create(L"http://www.yahoo.com");
book1[L"Yahoo:Price"] = 12.99f;
book1[L"Yahoo:Desc"].Create(L"http://www.yahoo.com");
book1[L"Yahoo:Desc"] = L"Learn how not to program from the industry`s
worst programmers! Contains lots of code examples which programmers
should avoid! Treat it as reverse education.";
book1[L"Yahoo:AuthorID"].Create(L"http://www.yahoo.com");
book1[L"Yahoo:AuthorID"] = 111;
The XML output is as below:
<All>
<Version>1</Version>
<Books>
<Yahoo:Book xmlns:Yahoo="http://www.yahoo.com"
Yahoo:ISBN="1111-1111-1111">
<Yahoo:Title>How not to program!</Yahoo:Title>
<Yahoo:Price>12.990000</Yahoo:Price>
<Yahoo:Desc>Learn how not to program from the
industry`s worst programmers! Contains lots of code
examples which programmers should avoid! Treat it
as reverse education.</Yahoo:Desc>
<Yahoo:AuthorID>111</Yahoo:AuthorID>
</Yahoo:Book>
</Books>
</All>
Enumerating Elements with Same Names
You can use the AsCollection method to return siblings with the same name in a vector.
using namespace Elmax;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element elem1 = root[L"aa|bb|cc"].CreateNew();
elem1.SetInt32(11);
Element elem2 = root[L"aa|bb|cc"].CreateNew();
elem2.SetInt32(22);
Element elem3 = root[L"aa|bb|cc"].CreateNew();
elem3.SetInt32(33);
Element::collection_t vec = root[L"aa"][L"bb"][L"cc"].AsCollection();
for(size_t i=0;i<vec.size(); ++i)
{
int n = vec.at(i).GetInt32(10);
}
This overloaded form (below) of AsCollection allows you specify a predicate function object to determine which elements you want to be picked up.
typedef std::vector< Element > collection_t;
template<typename Predicate>
collection_t AsCollection(Predicate pred);
If you are using C++0x, you can supply a lambda (also known as anonymous function) for the predicate, as shown below:
Element::collection_t vec = root[L"aa"][L"bb"][L"cc"].AsCollection(
[](Elmax::Element elem)->bool
{
if(elem.Attribute("Price").GetDouble() > 10.0 )
{
return true;
}
return false;
}
);
Enumerating Child Elements with Same Names
You can use the GetCollection method to get children with the same names in a vector.
using namespace Elmax;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element elem1 = root[L"aa|bb|cc"].CreateNew();
elem1.SetInt32(11);
Element elem2 = root[L"aa|bb|cc"].CreateNew();
elem2.SetInt32(22);
Element elem3 = root[L"aa|bb|cc"].CreateNew();
elem3.SetInt32(33);
Element::collection_t vec = root[L"aa"][L"bb"].GetCollection(L"cc");
for(size_t i=0;i<vec.size(); ++i)
{
int n = vec.at(i).GetInt32(10);
}
This overloaded form (below) of GetCollection allows you specify a predicate function object to determine which elements you want to be picked up.
typedef std::vector< Element > collection_t;
template<typename Predicate>
collection_t GetCollection(const std::wstring& name, Predicate pred);
If you are using C++0x, you can supply a lambda (also known as anonymous function) for the predicate, as shown below:
Element::collection_t vec = root[L"aa"][L"bb"].GetCollection(
L"cc",
[](Elmax::Element elem)->bool
{
if(elem.Attribute("Price").GetDouble() > 10.0 )
{
return true;
}
return false;
}
);
Query Number of Element Children
To query the number of children for each name, you can use the QueryChildrenNum method.
using namespace Elmax;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element elem1 = root[L"aa|bb|qq"].CreateNew();
elem1.SetInt32(11);
Element elem2 = root[L"aa|bb|cc"].CreateNew();
elem2.SetInt32(22);
Element elem3 = root[L"aa|bb|cc"].CreateNew();
elem3.SetInt32(33);
Element elem4 = root[L"aa|bb|qq"].CreateNew();
elem4.SetInt32(44);
Element elem5 = root[L"aa|bb|cc"].CreateNew();
elem5.SetInt32(55);
Element::available_child_t acmap =
root[L"aa"][L"bb"].QueryChildrenNum();
assert(acmap[L"cc"] == (unsigned int)(3));
assert(acmap[L"qq"] == (unsigned int)(2));
There is also an overloaded form (below) of QueryChildrenNum which does not create a temporary vector before returning. Note: QueryChildrenNum can only query for elements, not attributes or CData sections or comments.
typedef std::map< std::wstring, size_t > available_child_t;
bool QueryChildrenNum(available_child_t& children);
Shortcuts to Avoid Temporary Element Creation
In the previous enumeration example, I used:
Elmax::Element elem1 = root[L"aa|bb|cc"].CreateNew();
instead of:
Elmax::Element elem1 = root[L"aa"][L"bb"][L"cc"].CreateNew();
because the second form creates temporary elements aa and bb on the stack which are not used. The first form saves some tedious typing, and only returns an element in the overloaded [] operator, not to say it is faster too. \\ and / can be used for delimiters as well. To speed up, use the below code which excessively uses temporaries:
if(root[L"aa"][L"bb"][L"cc"][L"dd"].Exists())
{
root[L"aa"][L"bb"][L"cc"][L"dd"][L"Title"] = L"Beer jokes";
root[L"aa"][L"bb"][L"cc"][L"dd"][L"Author"] = L"The joker";
root[L"aa"][L"bb"][L"cc"][L"dd"][L"Price"] = 10.0f;
}
You can assign it to a Element variable, and use that variable instead.
Elmax::Element elem1 = root[L"aa|bb|cc|dd"];
if(elem1.Exists())
{
elem1[L"Title"] = L"Beer jokes";
elem1[L"Author"] = L"The joker";
elem1[L"Price"] = 10.0f;
}
Root Element
The root element is created when you call SetDomDoc on the element. You should know by now that the [] operator is used to access the child element. For root elements, the [] operator accesses itself to see its name corresponds to the name in the [] operator.
Element root;
root.SetDomDoc(pDoc);
Element elem1 = root[L"aa|bb|cc"];
The aa element in the above example actually refers to the root, not the child of the root. If an element is not called with SetDomDoc, then aa refers to its child. When using the [] operator, please remember to prefix the (wide) string literal with L, e.g., elem[L"Hello"], else you will get a strange unhelpful error. Element objects are created directly or indirectly from the root. For example, the root creates the aa element, and the aa element has the ability to create other elements. If you instantiate your element not from the root, your element cannot create. This is the limitation of the Microsoft XML DOM in which only the DOM document creates nodes. Those elements which are created directly or indirectly from the root received their DOM document, thus the ability to create elements.
RootElement is the helper class contributed by PJ Arends to eliminate the need to call SetConverter and SetDomDoc. It inherits from Element class. To build this class successfully, you need to download and build C++ Boost FileSystem library. If user decides not to use RootElement class, he/she can exclude this class from the Elmax project and not include FileSystem Library.
The RootElement constructor takes in a file path and loads the XML file into the DOM if exists. Else the document is a empty DOM. When the user calls SaveFile, he/she can either specifies a new path or the constructor path is used.
using namespace Elmax;
std::wstring path = L"D:\\temp.xml";
RootElement root(path);
Element elem = root[L"aa"][L"bb"][L"cc"].CreateNew();
elem["dd"].SetBool(true);
root.SaveFile();
If user used an normal Element as root, the equivalent win32 code could be
MSXML2::IXMLDOMDocumentPtr pDoc;
HRESULT hr = pDoc.CreateInstance(__uuidof(MSXML2::DOMDocument30));
if (SUCCEEDED(hr))
{
pDoc->async = VARIANT_FALSE;
pDoc->validateOnParse = VARIANT_FALSE;
pDoc->resolveExternals = VARIANT_FALSE;
}
std::wstring path = L"D:\\temp.xml";
DWORD fileAttr;
fileAttr = GetFileAttributes(fileName);
if (0xFFFFFFFF != fileAttr) pDoc->LoadXml(path)
using namespace Elmax;
Element root;
root.SetConverter(REGEX_CONV);
root.SetDomDoc(doc);
Element elem = root[L"aa"][L"bb"][L"cc"].CreateNew();
elem[L"dd"].SetBool(true);
variant_t varFile(path.c_str());
pDoc->save(varFile);
HyperElement Joins
Some XML elements are related to some XML elements according to some criteria. You can join them together, using the HyperElement class. HyperElement only contains static methods.
static std::vector< std::pair<Elmax::Element, Elmax::Element> >
JoinOneToOne(
std::vector<Elmax::Element>& vecElem1,
const std::wstring& attrName1,
std::vector<Elmax::Element>& vecElem2,
const std::wstring& attrName2,
bool bCaseSensitive);
static std::vector< std::pair<Elmax::Element, std::vector<Elmax::Element> > >
JoinOneToMany(
std::vector<Elmax::Element>& vecElem1,
const std::wstring& attrName1,
std::vector<Elmax::Element>& vecElem2,
const std::wstring& attrName2,
bool bCaseSensitive);
The 1st method, JoinOneToOne takes in 2 vectors of elements which are returned from the AsCollection and GetCollection and do a textual comparison of the values of specified attribute names, if the attribute name is empty, then the value of the element is used instead. There is also a similar JoinOneToMany method which I would not go through here; the parameters are similar. These functions are great if you are just equating text, but if you are comparing float values or doing somewhat more complex comparison, supplying a predicate might just be the best thing to do here. Fortunately, there is a overload method which takes in a predicate function. Below is the JoinOneToMany example of finding the books which the sci-fic authors have written from the supplied XML file, Books.xml.
template<typename DoubleElementPredicate>
static std::vector< std::pair<Elmax::Element, Elmax::Element> >
JoinOneToOne(
std::vector<Elmax::Element>& vecElem1,
std::vector<Elmax::Element>& vecElem2,
DoubleElementPredicate pred);
template<typename DoubleElementPredicate>
static std::vector< std::pair<Elmax::Element, std::vector<Elmax::Element> > >
JoinOneToMany(
std::vector<Elmax::Element>& vecElem1,
std::vector<Elmax::Element>& vecElem2,
DoubleElementPredicate pred);
<All>
<Version>1</Version>
<Books>
<Book ISBN="1111-1111-1111">
<Title>2001: A Space Odyssey</Title>
<Price>12.990000</Price>
<AuthorID>111</AuthorID>
</Book>
<Book ISBN="2222-2222-2222">
<Title>Rendezvous with Rama</Title>
<Price>15.000000</Price>
<AuthorID>111</AuthorID>
</Book>
<Book ISBN="3333-3333-3333">
<Title>Foundation</Title>
<Price>10.000000</Price>
<AuthorID>222</AuthorID>
</Book>
<Book ISBN="4444-4444-4444">
<Title>Currents of Space</Title>
<Price>11.900000</Price>
<AuthorID>222</AuthorID>
</Book>
<Book ISBN="5555-5555-5555">
<Title>Pebbles in the Sky</Title>
<Price>14.000000</Price>
<AuthorID>222</AuthorID>
</Book>
</Books>
<Authors>
<Author Name="Arthur C. Clark" AuthorID="111">
<Bio>Sci-Fic author!</Bio>
</Author>
<Author Name="Isaac Asimov" AuthorID="222">
<Bio>Sci-Fic author!</Bio>
</Author>
</Authors>
</All>
DebugPrint dp;
MSXML2::IXMLDOMDocumentPtr pDoc;
std::wstring strFilename = L"Books.xml";
HRESULT hr = CreateAndLoadXml(pDoc, strFilename);
if (SUCCEEDED(hr))
{
using namespace Elmax;
using namespace std;
Element root;
root.SetConverter(NORMAL_CONV);
root.SetDomDoc(pDoc);
Element all = root[L"All"];
if(all.Exists()==false)
{
dp.Print(L"Error: root does not exists!");
return;
}
Element authors = all[L"Authors"];
auto vec = HyperElement::JoinOneToMany(authors.GetCollection(L"Author"),
books.GetCollection(L"Book"),
[](Elmax::Element x, Elmax::Element y)->bool
{
if(x.Attribute("AuthorID").GetString("a") == y[L"AuthorID"].GetString("b") )
{
return true;
}
return false;
});
for(size_t i=0; i< vec.size(); ++i)
{
dp.Print(L"List of books by {0}\n",
vec[i].first.Attribute(L"Name").GetString(""));
dp.Print(L"=============================================\n");
for(size_t j=0; j< vec[i].second.size(); ++j)
{
dp.Print(L"{0}\n", vec[i].second[j][L"Title"].GetString("None"));
}
dp.Print(L"\n");
}
}
This is the output from the above code:
List of books by Arthur C. Clark
=============================================
2001: A Space Odyssey
Rendezvous with Rama
List of books by Isaac Asimov
=============================================
Foundation
Currents of Space
Pebbles in the Sky
These HyperElement methods are just very simplistic functions which compare the elements in 2 vectors by looping.
Shared State in Multithreading
You might be using different Elmax Element objects in different threads without sharing them across threads. However, Element has static type converter objects which are shared with all Element objects. To overcome this problem, allocate a new type converter and use that in the root. Remember to delete the converter after use.
using namespace Elmax;
Element root;
root.SetDomDoc(pDoc);
RegexConverter* pRegex = new RegexConverter();
root.SetConverter(CUSTOM_CONV, pRegex);
By the way, you need to remember to call CoInitialize/CoUninitialize in your worker threads!
Save File Contents in XML
You can call SetFileContents to save a file's binary contents in Base64 format in the Element. You can specify to save its file name and file length in the attributes if you intended to save the contents back to a file with the same name on disk. We need to save the original file length as well because GetFileContents sometimes reports a longer length after the Base64 conversion!
bool SetFileContents(const std::wstring& filepath,
bool bSaveFilename, bool bSaveFileLength);
We use GetFileContents to get back the file content from Base64 conversion. filename is written, provided that you did specify to save the file name during SetFileContents. length is the length of the returned character array, not the saved file length attribute.
char* GetFileContents(std::wstring& filename, size_t& length);
Attribute
To create an attribute (if not exists) and assign a string to it, see example below:
book1.Attribute(L"ISBN") = L"1111-1111-1111";
To create an attribute with a namespace URI and assign a string to it, you have to create it explicitly.
book1.Attribute(L"Yahoo:ISBN").Create(L"http://www.yahoo.com");
book1.Attribute(L"Yahoo:ISBN") = L"1111-1111-1111";
To delete an attribute, use the Delete method.
book1.Attribute(L"ISBN").Delete();
To find out an attribute with the name exists, use the Exists method.
bool bExists = book1.Attribute(L"ISBN").Exists();
The list of Attribute setters and accessors are the same as that for Element. And they use the same type converter.
Comment
For your information, XML comments come in the form of <!--My example comments here-->. Below are a bunch of operations you can use with comments:
using namespace Elmax;
Element elem = root[L"aa"][L"bb"][L"cc"].CreateNew();
elem.AddComment(L"Can you see me?");
Comment comment = elem.GetComment(0);
comment.Update(L"Can you hear me?");
comment.Delete();
You can get a vector of Comment objects which are children of the element, using the GetCommentCollection method.
CData Section
For your information, an XML CData section comes in the form of <![CDATA[<IgnoredInCDataSection/>]]>. An XML CData section typically contains data which is not parsed by the parsers, therefore it can contain < and > and other invalid text characters. Some programmers prefer to store them in Base64 format (see next section). Below are a bunch of operations you can use with CData sections:
using namespace Elmax;
Element elem = root[L"aa"][L"bb"][L"cc"].CreateNew();
elem.AddCData(L"<<>>");
CData cdata = elem.GetCData(0);
cdata.Update(L">><<");
cdata.Delete();
You can get a vector of CData sections which are children of the element, using the GetCDataCollection method.
Base64
Some programmers prefer to store binary data in Base64 format under an element, instead of in the CData section, to easily identify and find it. The downside is Base64 format takes up more space, and data conversion takes time. This code example shows how to use Base64 conversion before assignment, and also convert back from Base64 to binary data after reading:
Elmax::Element elem1;
string strNormal = "@#$^*_+-|\~<>";
elem1 = Element::ConvToBase64(strNormal.c_str(), strNormal.length());
wstring strBase64 = elem1.GetString(L"ABC");
size_t len = 0;
Element::ConvFromBase64(strBase64, NULL, len);
char* p = new char[len+1];
memset(p, 0, len+1);
Element::ConvFromBase64(strBase64, p, len);
Structured Data
The StrUtil class in the StringUtils folder provides convenient helper methods to format strings (Format methods) (similar to .NET's String.Format) and split strings (Split methods) back to primitive types.
Formatting Strings
Formatting is basically done through the Format methods. Below is an example to format the a rectangle's information.
using namespace Elmax;
Element elem;
StrUtil util;
Rectangle rect(10, 20, 100, 200);
elem.SetString( util.Format(L"{0}, {1}, {2}, {3}", rect.X(), rect.Y(), rect.Width(), rect.Height()) );
Splitting Strings
Before a string is splitted, a strategy need to be selected first. Other than the C string strtok, Boost splitter and regular expression are available as alternative string splitter strategies.
using namespace Elmax;
Element elem;
StrUtil util;
StrtokStrategy strTok(L", ");
util.SetSplitStrategy(&strTok);
int x = 0;
int y = 0;
int width = 0;
int height = 0;
util.Split( elem.GetString(L""), x, y, width, height );
Rectangle rect(x, y, width, height);
Aggregation
The following SQL aggregation functions are provided: Count, Minimum, Maximum, Sum and Average. In terms of performance, it would still be better to read the values into your custom data structures and do the aggregation yourself. These functions are meant to be used for the future LINQ-like features. They are not meant to be used by end-users but they are there if user want to use them for aggregation. What is missing is the GroupBy functionality. OrderBy is covered by the Sort method.
Count, Minimum, Maximum, Sum and Average
The Minimum, Maximum, Sum and Average functions take in 2 string parameters. The 1st parameter is name of children and 2nd parameter is the attribute name. The user can leave the 2nd parameter blank if it is not attribute value which he/she wants to aggregate. Min, Max, Sum and Avg returns a 64 bit integer result while MinF, MaxF, SumF and AvgF returns a 32 bit float value and MinD, MaxD, SumD and AvgD returns a 64 bit float value.
using namespace Elmax;
Element elem = root[L"aa"][L"bb"];
__int64 nMax = elem.Max(L"cc|dd", L"attr");
This is the XML from which to get the maximum value.
<aa>
<bb>
<cc><dd>55</dd></cc>
<cc><dd>33</dd></cc>
<cc><dd>22</dd></cc>
</bb>
</aa>
Count function takes in a string parameter and a predicate parameter, and returns a unsigned integer. The predicate determines whether the element should be counted towards the total.
using namespace Elmax;
Element root;
Element elem1 = root[L"aa|bb|cc"].CreateNew();
elem1.SetInt32(11);
Element elem2 = root[L"aa|bb|cc"].CreateNew();
elem2.SetInt32(22);
Element elem3 = root[L"aa|bb|cc"].CreateNew();
elem3.SetInt32(33);
Pred pred;
unsigned int cnt = root[L"aa"][L"bb"].Count(L"cc", pred);
struct Pred : public std::unary_function<Elmax::Element, bool>
{
bool operator() (Elmax::Element& ele)
{
if(ele.GetInt32(0)<33)
return true;
return false;
}
};
Sort
Sorting is done through the Sort method. The 1st parameter is name of children and 2nd is the comparison predicate which can be a lambda. This is not an in-place sort due to MSXML limitation. In-place sort can only be implemented in cross-platform Elmax where the XML nodes are truly managed by Elmax.
using namespace Elmax;
Element elem;
collection_t vec =
elem.Sort(L"cc", [](Element elem1, Element elem2) -> bool
{
return elem1[L"dd"].GetInt32(0) < elem2[L"dd"].GetInt32(0);
});
C++0x Move Constructor
The Elmax library defines some C++0x move constructors and move assignments. In order to build the library in older Visual Studio versions prior to the 2010 version, you have to hide them by defining _HAS_CPP0X to be 0 in stdafx.h.
Building in Visual C++ 8.0 (Visual Studio 2005)
Elmax is available to be built in Visual Studio 2005/2008/2010. However, additional effort is required to build the Boost Regular Expression library for Visual Studio 2005. I did not realise how difficult it is for a user to build Elmax in Visual C++ 8.0 until my computer broke down two weeks ago; the old computer has Boost regex libraries prebuilt while the new computer doesn't. To get the regex library for your computer, you need to download Boost and add Boost the regex include folder path to the Visual Studio VC++ directories and build the Boost regex libraries, according to this Boost documentation. For Visual Studio 2008/2010 users, Elmax will use the C++0x TR1's regex library.
C# Library
Elmax has been ported to C# 2.0 and 87 unit tests have been added to test the C# library, this brings the total number of unit tests to 342. The C# library can be built in Visual Studio 2005/2008/2010. There are plans to port Elmax to C# 4.0 to take advantage of optional parameters. It is interesting to note that the C++ version has approximately 7365 lines of code while the C# version has 2622 lines! The C++ version has 10 classes while C# has 4 classes because the helper classes are already implemented in the .NET BCL libraries, so there is no need for me to write them. Because there are less classes, less unit tests are needed to test the C# version (87 versus 255). Just comparing Element.cpp and Element.cs, Element.cpp has 2200 lines of code while Element.cs has 1755 lines! Below is the code to write an element in C++ followed by the C# version. You can see that they are almost similar. However, the C# version of Elmax does not have the implicit assignment and reading of value types. Assignment and reading of elements has to be done through setters and accessors, for example, the SetFloat and GetFloat methods.
using namespace Elmax;
...
Element root;
root.SetDomDoc(pDoc); root[L"Books"][L"Book"][L"Price"].SetFloat(12.99f);
C#:
using Elmax;
...
Element root = new Element();
root.SetDomDoc(doc);
root["Books"]["Book"]["Price"].SetFloat(12.99f);
Below is the code to read an element in C++ followed by the C# version:
using namespace Elmax;
...
Element root;
root.SetDomDoc(pDoc); Element elemPrice = root[L"Books"][L"Book"][L"Price"];
if(elemPrice.Exists())
float price = elemPrice.GetFloat(10.0f);
C#:
using Elmax;
...
Element root = new Element();
root.SetDomDoc(doc);
Element elemPrice = root["Books"]["Book"]["Price"];
if(elemPrice.Exists)
float price = elemPrice.GetFloat(10.0f);
Future Development
Version 1 is feature complete. Work has begun on the next version, cross-platform Elmax which would be rewritten from ground up and not using any Microsoft specific technologies. Version 1 and version 2 will be developed and maintained concurrently. Version 1 and version 2 codebase will be merged at some point in time, meaning version 1 will eventually ditch MSXML and use the cross-platform parser in version 2 but version 1 would continue to provide convenient accessor and mutator for some Microsoft data types like GUID and MFC CString.
Bug Reports
For bug reports and feature requests, please file them here. When you file a bug report, please do include the sample code and XML file (if any) to reproduce the bug. The current Elmax is at version 0.65 beta. The Elmax CodePlex site is located at http://elmax.codeplex.com/.
Related articles
History
- 28/06/2022
- Removed Boost
lexical_cast. - Changed from
MSXML2::Document30 to MSXML2::Document60.
- 26/11/2013
- Updated the source code to use Boost
lexical_cast.
- 23/08/2012
- 19/04/2012
- Updated the source code to include C# version of RootElement class. Updated the Root Element section
- 10/04/2012
- Updated the source code that includes PJ Arends' RootElement class and Elmax.h header.
- 09/04/2012
- Updated the source code to latest version.
- 21/05/2011
- Added a
HyperElement section
- 11/02/2011:
- 10/01/2011
- Updated the source code (version 0.65 beta) to use ATL Base64 implementation, and changed the getter and setter methods not to raise exceptions because of
null type converter pointer, by using a valid static type converter object.
- 26/12/2010
- Added a
TestRead code snippet to show how to read an XML file - Updated the source code
- 24/12/2010
- Updated the VC2005 code to use Boost regex, instead of the bundled TR1 regex in newer VC
- Added ability to access Date, GUID, and file contents in XML
- 23/12/2010

