Introduction
I came across a few articles that discuss loading a tree from a DataSet, but none of the articles I found seemed to use the tree as the primary user interface control while behind the scenes, manipulating the DataSet itself. This article uses the XTree that I've written about previously, showing how an underlying DataSet and its tables are updated when editing the tree. Editing includes creating, deleting, and moving nodes. For this demonstration, I've selected a simple todo list as an example. The todo list consists of a collection of projects, each having tasks. Tasks can have subtasks without limit.
The Object Model
The underlying object model is a Model-View-Controller pattern, as illustrated by this diagram:

The View
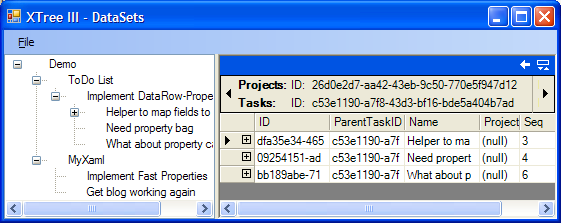
The View is the XTree control. This is the control the user interacts with, and events and callbacks to the controllers are initiated. The DataView that's on the form is just there for inspecting the project and task tables. The DataView is set up as a read-only control, as it is not intended that the user interact with the underlying tables themselves.
The Controllers
There are two controllers:
- The root node controller, necessary because it is responsible for returning an index of the project being moved.
- The row controller, responsible for the project/task/subtask node events.
Note that there is only one row controller regardless of the node type (project or task) or the associated table. More on this next.
The Model
The DataAccessLayer class wraps the DataSet instance, and provides the business logic for creating, adding, and moving project and task rows. Task rows can be moved within a project or subtask, as well as be promoted or demoted. The actual mechanics of how this is done is quite simple, as I will show later on.
The Tree Definition File
As described in my previous articles on the XTree, the XTree is controlled be an XML definition file. In this demo, the definition file is quite simple, describing the top level node, the project subnode, and recursive tasks that can be associated with a project or task/subtask.
="1.0"="utf-8"
<RootNode Name="Root">
<Nodes>
<NodeDef Name="Demo" Text="Demo" IsReadOnly="true" IsRequired="true"
TypeName="XTreeTasks.DemoController, XTreeTasks">
<Nodes>
<NodeDef Name="Project" Text="Project" IsReadOnly="false"
IsRequired="false"
TypeName="XTreeTasks.RowController, XTreeTasks"
TypeData="Projects">
<ParentPopupItems>
<Popup Text="Add Project" IsAdd="true" Tag="Add"/>
</ParentPopupItems>
<PopupItems>
<Popup Text="Delete Project" IsRemove="true"/>
</PopupItems>
<Nodes>
<NodeDef Name="Task" Text="Task" IsReadOnly="false" Recurse="true"
TypeName="XTreeTasks.RowController, XTreeTasks"
TypeData="Tasks">
<ParentPopupItems>
<Popup Text="Add Task" IsAdd="true" Tag="Add"/>
</ParentPopupItems>
<PopupItems>
<Popup Text="Delete Task" IsRemove="true"/>
</PopupItems>
</NodeDef>
</Nodes>
</NodeDef>
</Nodes>
</NodeDef>
</Nodes>
</RootNode>
Note the attributes TypeName and TypeData. The TypeName attribute is the qualified name of the controller that handles the View events/callbacks. Because I wanted a general purpose implementation for the tree, there is only one controller--the RowController--regardless of the table being manipulated. I needed some additional definition data to specify not only the kind of controller, but the table that it "controls". Rather than code a separate controller for the project and task nodes, there is an additional attribute, the TypeData attribute, which is saved as part of the controller instance. This metadata couples the general purpose row controller to the specific implementation requirements that we are achieving in the demo. In this particular case, the TypeData attribute value is also the table name that the controller manipulates--that makes it easy. Incidentally, the metadata is also necessary for the XTree to determine the node definition given by the controller, via the "controller-to-node dictionary", as illustrated in this code:
NodeDef nodeDef = null;
ControllerInfo ci = new ControllerInfo(inst.GetType(), inst.TypeData);
bool found = controllerToNodeDefMap.TryGetValue(ci, out nodeDef);
The Schema
The schema for the DataSet consists of two tables: Projects and Tasks:
A row in the Tasks table is either associated with a project, which therefore makes it a top-level task, or another task, which makes it a subtask. The schema is hardcoded in the DAL:
public void CreateSampleStructure()
{
DataTable dtProject = new DataTable("Projects");
DataColumn prjpk=new DataColumn("ID", typeof(Guid));
DataColumn prjName=new DataColumn("Name", typeof(string));
DataColumn prjSeq = new DataColumn("Seq", typeof(int));
dtProject.Columns.AddRange(new DataColumn[] { prjpk, prjName, prjSeq });
dtProject.PrimaryKey = new DataColumn[] { prjpk };
DataTable dtTask = new DataTable("Tasks");
DataColumn taskpk = new DataColumn("ID", typeof(Guid));
DataColumn taskParentID = new DataColumn("ParentTaskID", typeof(Guid));
DataColumn taskSeq = new DataColumn("Seq", typeof(int));
taskParentID.AllowDBNull = true;
DataColumn taskProjectID = new DataColumn("ProjectID", typeof(Guid));
taskProjectID.AllowDBNull = true;
DataColumn taskName = new DataColumn("Name", typeof(string));
dtTask.Columns.AddRange(new DataColumn[] { taskpk, taskParentID, taskName,
taskProjectID, taskSeq });
dtTask.PrimaryKey = new DataColumn[] { taskpk };
dataSet = new DataSet();
dataSet.Tables.AddRange(new DataTable[] { dtProject, dtTask });
dataSet.Relations.Add(new DataRelation("childTask", taskpk, taskParentID));
dataSet.Relations.Add(new DataRelation("projectTask", prjpk, taskProjectID));
}
Other Metadata
Ideally, two other pieces of information should be part of the metadata that defines the tree to data row association: the field names in the table that map to the tree node's text, and the field name that is used to order the tree's leaves. Rows in a table are usually unordered, however, in a todo list, being able to order the tasks and subtasks is pretty much a requirement, therefore the tables need to support preserving the user's ordering preference, hence the "Seq" field. In this demo, these two metadata items, the name field and the sequence field, are hardcoded during the construction of the DAL.
Implementation
The actual implementation was quite simple given the flexibility of the XTree. I had to make three modifications to the XTree itself--adding the TypeData property, using it to qualify the lookup of the node definition, and changing the AutoDeleteNode method in the controller to return a bool instead of being a void method.
The Row Controller
The row controller implementation is really nothing more than an interface point for the view events, which then calls the business rule methods in the model (the DAL). This is a classic MVC pattern. One thing that's a bit different though is that the controller instances keep a reference to the DataRow associated with the controller, which is of course associated with a specific tree node.
Properties
One of the most vital properties is of course the ability to edit the tree node's text. The row controller implements a Name property which the XTree control uses to get/set the name. Note that the behavior gets the default name if there is no associated row:
public override string Name
{
get
{
string ret = String.Empty;
if (dataRow==null)
{
ret = base.Name;
}
else
{
ret = dal.GetNameFieldValue(dataRow);
}
return ret;
}
set
{
if (dataRow==null)
{
base.Name = value;
}
else
{
dal.SetNameFieldValue(dataRow, value);
}
}
}
The controller also has a property for the DAL:
public DataAccessLayer DataAccessLayer
{
get { return dal; }
set { dal = value; }
}
Now a problem arises. How does the controller get a reference to the DAL instance, if it's the XTree that's instantiating the controller (rather non-MVC'ish in this case)? That question will be answered shortly.
There are more properties, but they are all equally trivial.
Methods
One of the most important internal methods is the Index property.
public override int Index(object item)
{
return dal.GetRowNum(((RowController)item).DataRow);
}
As described in the previous articles, the Index method returns the index of the child item in the controller's item collection. This is necessary for locating the item in the collection and moving it. In this particular case, the underlying collection consists of data rows, which are not quite the same thing. Nevertheless, the controller gets the index from the DAL, which returns the row index of the row as found in a sorted (by sequence) view.
When a node is added, the controller's AddNode method is called. We have a rather simple implementation here:
public override bool AddNode(IXtreeNode parentInstance, string tag)
{
this.parentInstance = parentInstance as RowController;
return true;
}
At this point, the controller doesn't have a reference to the DAL instance, so it can't do much. This gets us back to the problem I mentioned earlier, how does the controller get the DAL instance? One more thing (OK, that makes four) I added to the XTree was a NewNode event. The application that has a reference to the DAL uses this event to help out the newly created controller (this code is in the application, not the controller):
void OnNewNode(object sender, NewNodeEventArgs args)
{
RowController rowCtrl = ((RowController)args.InstanceNode);
rowCtrl.DataAccessLayer = dal;
rowCtrl.CreateRow(args.NodeDef);
}
Pretty simple. Give the controller a reference to the DAL and tell it to create the row. The controller then communicates with the DAL:
public void CreateRow(NodeDef nodeDef)
{
dataRow=dal.CreateRow(typeData);
dal.SetNameFieldValue(dataRow, nodeDef.Text);
if (parentInstance != null)
{
dal.SetParentID(dataRow, parentInstance.DataRow);
}
dal.AddRow(typeData, dataRow);
}
This is equally simple, except for that odd "if" statement, which verifies that the parent instance is actually another row controller (see the code for AddNode above).
Deleting a node and its associated row couldn't be easier:
public override bool DeleteNode(IXtreeNode parentInstance)
{
dal.DeleteRow(dataRow);
return true;
}
Actually, it could be easier. I could delete the DataRow instance directly, but I would prefer to work with the DAL as a common point for manipulating the rows and tables.
Inserting a node (and therefore the row) is simple as well (though this took some thought. Actually, all of this took considerable thought. It's amazing how code can hide the thinking that goes behind it):
public override void InsertNode(IXtreeNode parentInstance, int idx)
{
RowController parentController = parentInstance as RowController;
if (parentController == null)
{
dal.MoveNode(dataRow, idx);
}
else
{
dal.InsertNode(dataRow, parentController.DataRow, idx);
}
}
Note that the InsertNode call handles both moving a task within the same project or moving it to another project. Similarly, since we're using the controller for tasks, it handles moving a subtask within the same task or to another task. Or promoting/demoting the task within the task hierarchy. All this magic is done simply by changing the ParentTaskID field value given by the parent controller's DataRow instance. Very cool, if I may say so.
The Data Access Layer
The DAL has some interesting methods as well. The CreateRow method is responsible for creating the row in the appropriate table:
public DataRow CreateRow(string tableName)
{
DataTable dt = dataSet.Tables[tableName];
DataRow dataRow = dt.NewRow();
dataRow[dt.PrimaryKey[0]] = Guid.NewGuid();
return dataRow;
}
Note how it also establishes a unique ID for the primary key. The next step, after the rest of the data has been initialized, is to add the row to the table:
public void AddRow(string tableName, DataRow row)
{
DataTable dt = dataSet.Tables[tableName];
if (dt.Rows.Count == 0)
{
row[seqField] = 0;
}
else
{
DataView dv = new DataView(dt);
dv.Sort = seqField;
int seq = ((int)dv[dv.Count - 1][seqField]) + 1;
row[seqField] = seq;
}
dt.Rows.Add(row);
}
Here, the sequence field value is established. The code comments explain what's going on. The reason dt.Rows.Count can't be used is that holes are created in the sequence when rows are moved around both laterally and vertically. In part, this is due to my somewhat lame resequencing algorithm.
I don't think I need to show you the DeleteRow method, right? So, the next interesting method is SetParentID. Given the child row and the parent row, the table relationships are searched to determine which column is the foreign key in the child and which is the primary key in the parent. The child's foreign key column is then set appropriately:
public void SetParentID(DataRow dataRow, DataRow parentDataRow)
{
foreach (DataRelation rel in dataSet.Relations)
{
if (dataRow.Table.TableName == rel.ChildTable.TableName)
{
if (parentDataRow.Table.TableName == rel.ParentTable.TableName)
{
dataRow[rel.ChildColumns[0]] = parentDataRow[rel.ParentColumns[0]];
}
else
{
dataRow[rel.ChildColumns[0]] = DBNull.Value;
}
}
}
}
But, at the same time, any child columns that are foreign keys to a parent that is not this child's parent are set to null. This breaks the task-project relationship when a task becomes a subtask, or breaks a task-task relationship when a child becomes a top-level task. Interesting, isn't it? I'm also amused by the fact that there are about four lines of comments for every line of code in this method. It's simple and elegant, but not intuitive. As I said before, code does not often reflect the thinking that goes on behind the reason for the code.
I had discussed that the controller gets the row index of a specific row. That's done in this method:
public int GetRowNum(DataRow dataRow)
{
DataView dv = new DataView(dataRow.Table);
dv.Sort = seqField;
int idx = dv.Find(dataRow[seqField]);
return idx;
}
At this point, you may begin to wonder, why don't I create a DataView dictionary instead of instantiating a DataView every time I need one. Good question. Next!
Now, let's look at InsertNode:
public void InsertNode(DataRow row, DataRow parentRow, int idx)
{
SetParentID(row, parentRow);
MoveNode(row, idx);
}
Good grief! Two lines of code. But what it does is very, very powerful. It first updates the appropriate foreign key so that the row is now associated with the desired parent row. Then it moves that row to the appropriate location in the parent's row collection. All the work is being done in SetParentID, which you've seen, and in MoveNode:
public void MoveNode(DataRow row, int idx)
{
row.Table.AcceptChanges();
DataView dv = new DataView(row.Table);
dv.Sort = seqField;
int lastSeq = (int)dv[dv.Count-1][seqField]+1;
for (int i = dv.Count - 1; i >= idx; i--)
{
DataRowView drv = dv[i];
int seq = (int)drv[seqField];
lastSeq = seq;
drv[seqField] = seq+1;
}
row[seqField] = lastSeq;
}
This should be self-explanatory. Iterate backwards through the rows, incrementing the sequence values, until we get to the insertion point. Then set the row's sequence field value to the last, unbumped, sequence value.
Conclusion
What?!?! We're done??? Yes. That's it. The demo program includes a simple load/save feature that serializes the DataSet to XML, and everything else is handled by the XTree, which you can read about. Ideally, with just a little bit of metadata, you should be able to create complicated tree structures that can automatically manipulate the associated tables. The DAL that I implemented contains the core functionality, you will most likely need to enhance it to handle different name fields depending on the table, and possibly different sequence fields as well.

