Introduction
This article is about the full-text search capability of SQL Server 2000 (2005). It is an easy to use, very fast and extensible solution to index and search in various types of documents' content. For example in Word, Excel, Adobe portable document format (PDF) and HTML files.
Prerequisites
To go through with this example, you will need Microsoft SQL Server 2000 Server (at least) access, a database with DB owner right, and of course the client tools.
Creating a Table
In order to index files stored in a database table, we have to create two table fields. In the first field, we will store the content of the document in binary format, in the second we will store the extension of the file, for example ".doc" or ".xls".
It's a good idea to store the full name and the size information of the files, because probably you'll need these in real situations, but you won't need them for full-text indexing.
Storing the sizes of the files can be optional, because you can query them with the DataLength function, but this could take a long time, much longer than reading these values from a field.
So our create table script can be this:
CREATE TABLE [dbo].[Doc] (
[ID] uniqueidentifier ROWGUIDCOL NOT NULL ,
[Extension] [varchar] (10) NOT NULL ,
[Content] [image] NOT NULL ,
[FileSize] [int] NOT NULL ,
[FileName] [nvarchar] (500) NOT NULL ,
[Stamp] [timestamp] NOT NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[Doc] WITH NOCHECK ADD
CONSTRAINT [PK_Doc] PRIMARY KEY CLUSTERED
(
[ID]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Doc] ADD
CONSTRAINT [DF_Doc_ID] DEFAULT (newid()) FOR [ID]
GO
A simple idea is to use a unique identifier type as the primary key of the document table. It can be useful in many cases if you are a web developer. Maybe you would like to use this id in the URL (query string) when you make a download page, and you don't want to give the chance to your users to download all the documents without seeing all your advertisements, etc. by simply increasing a parameter at the end of the URL.
Please notice that a primary key has been created by the script. It is always very important because this can guarantee that you can't insert two records with the same id into the database (a table is a set of records, you can't make the difference between records with the same values, except with cursors), and a good clustered index can really improve the performance of the SELECT statements.
Also, there is a timestamp field – called stamp – on the table. It will be necessary for us and we will talk about it later.
Creating Full-text Index
I think nobody knows the proper format of the full-text index creation statement by head. So, we will create this index from Microsoft SQL Server Enterprise Manager.
First choose your server, then your database. Choose tables then on the right, search for the table you've created (Doc).
After right clicking on the table, choose "Define Full-Text indexing on a table" submenu from "Full-Text Index table" menu.
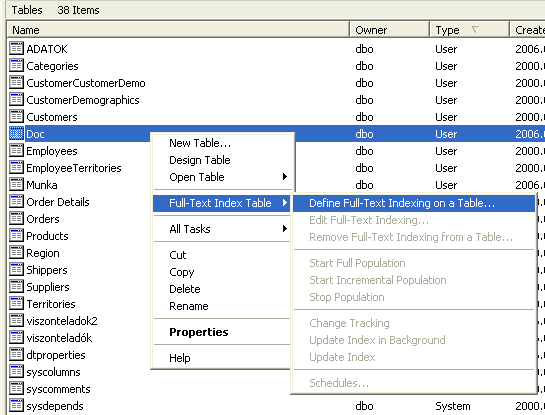
After these, a wizard will appear.
In the "Select an index step", choose your primary key. Later, when we query the table, we will get back this (unique) index's values from the full-text search engine as a result.
In the "Select Table Columns", step mark the "Content" column, and in that row in the document type column, choose the extension field. Then step away to another row, because the Next button will be activated only after you change the selection.

In this step, we gave the indexable column to the server and also defined the types of each document.
In the "Select a Catalog" step, you can create a new full-text catalog or choose an existing one. I offer that you make a new catalog for these data, because the collected indexes can be huge if the count of the documents increase.
In the "Select or Create Population Schedules", you can schedule the incremental and the full population of the catalog or the table. You can leave it empty in this case, because we will use the change tracking feature of the SQL Server. It means, we tell the SQL server to update its full-text catalog "immediately" after an insert or an update occurs.
In real situations, it is generally offered to make a full population every week or daily and an incremental daily or more often, but it depends on your server utilization.
The cause is that the change tracking and incremental update feature doesn't recognize if someone uses WriteText or UpdateText statements.
When we designed the table, we've put a timestamp field into it. The timestamp field is needed for incremental index updates, without that field all the incremental updates do full updates. The full-text index engine can find the updates on this property change. This is because the WriteText and UpdateText statements are not noticed by the full-text engine. These statements don't update the timestamp field like normal Insert and Update do.
So finish the wizard, by pressing the Next button few times and then Finish.
After the full-text index has been defined, we have to turn the change tracking functionality on. We can do it by right clicking on the table name in Enterprise Manager and then choose Change Tracking then the "Update index in background" from Full-Text Index Table menu. From this time, the full-text index engine will watch our table for changes and update its index if necessary.
An interesting result of our index creation:
if (select DATABASEPROPERTY(DB_NAME(), N'IsFullTextEnabled')) <> 1
exec sp_fulltext_database N'enable'
GO
if not exists (select * from dbo.sysfulltextcatalogs where name = N'Doc')
exec sp_fulltext_catalog N'Doc', N'create'
GO
exec sp_fulltext_table N'[dbo].[Doc]', N'create', N'Doc', N'PK_Doc'
GO
exec sp_fulltext_column N'[dbo].[Doc]', N'Content', N'add', 1033, N'Extension'
GO
exec sp_fulltext_table N'[dbo].[Doc]', N'activate'
GO
Testing
Now we insert some records and then we create a few select queries. Let's run this insert script in Query Analyzer:
INSERT INTO [DOC] ([Extension], [Content], [FileSize], [FileName])
VALUES ('.txt', 'Hello John! It''s me: Garfield!', 30, 'Cartoon1.txt')
INSERT INTO [Doc] ([Extension], [Content], [FileSize], [FileName])
VALUES ('.txt', 'Oh my god!', 30, 'Shout.txt')
INSERT INTO [DOC] ([Extension], [Content], [FileSize], [FileName])
VALUES ('.txt', 'NOWAN's web site: <a href="%22http://www.nowan.hu/'%22">http://www.nowan.hu/'</a>, 30, 'nowan.txt')
These are simple inserts, you can examine them yourself. After you inserted the records, you can run a SELECT statement to check the table:
SELECT * FROM [Doc]
Full-Text Search
To create a full-text query, you have to get closer with the next statements:
The first two statements have two parameters. The first is the column name and the second is the searched string. These functions give back Boolean values.
The second two statements are more interesting. These functions return tables that have two columns: Key and Rank. It means that we can get back the unique id of the searched record or records and also we can get back the hit probability (Rank):
SELECT * FROM ContainsTable([doc], Content, '"nowan"')
Another good trait of containstable and freetexttable is that you can give difficult expressions as searched string. For example, you can use "OR" and "AND" logical terms:
Of course, the result table of these statements can be joined to real tables. So if we would like to get the original data row from the original table, we could use a select statement like this:
SELECT Doc.* FROM [Doc]
INNER JOIN ContainsTable([doc], Content, '"nowan"') AS FT
ON Doc.ID = FT.[Key]
Indexed File Types
The SQL Server can create indexes typically from text files and Microsoft Office files. This type list is extensible by iFilters designed for the old Indexing Service. You can get an iFilter from Adobe too for indexing PDF files.
Hungarian Version
You can find the Hungarian version of this article here.

