
Introduction
People are more productive when they can work anywhere anytime without getting nagging messages like "unable to connect" or "server not found." Just ask Microsoft Outlook users how much they love the offline mode. Application developers agree that enabling their applications to work offline is a customer value-add and an attractive proposition. However, the challenges with building and managing a local cache on top of developing reliable synchronization algorithms are a major concern and a potential risk to product release plans. Truth is: developers' concerns are hardly overstated!
Microsoft Synchronization Services for ADO.NET is a new data synchronization framework that enables developers to build disconnected data applications using familiar concepts. In this document, I will give a quick overview of what the new synchronization framework is all about and how to use it to build occasionally connected applications.
Background
I've been working in Microsoft for over five years focusing on synchronization and replication technologies. I have to admit that I've never been more excited about new synchronization technology than I am with the Synchronization Services framework. The reason is simple: this technology is for developers and not an end-to-end solution that is tailored toward administrators. Anyhow, I thought that it would be a good idea to write an introductory document on this new framework and post it here on The Code Project. After all, you guys are the future users of this API and your feedback is the most important of all.
Disclaimer
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS DOCUMENT. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise) or for any purpose, without the express written permission of Microsoft Corporation. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property.
© 2007 Microsoft Corporation. All rights reserved.
Microsoft, MS-DOS, Windows, Windows Server, Windows Vista, SQL Server, Visual Studio are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. All other trademarks are property of their respective owners.
Download CTP and Documentation
The Synchronization Services for ADO.NET Beta 2 are available here. Please note that the package contains the SQL CE version 3.5. The documentation is available in a separate package; you can find it here.
Synchronization Services Overview
ADO.NET introduced a set of disconnected objects that allows you to examine data offline after fetching it from the server. The key to this model is the DataSet object, which encapsulates a host of other disconnected objects like DataTable, DataColumn, etc. Synchronization Services for ADO.NET extends this model by providing a persistent cache on the client. With the data stored on disk on the client machine, the client can examine the data and make modifications while offline and between application restarts. Changes to the data on the client and server are tracked by means of database triggers or through built-in support, as is the case with SQL CE. By using the Sync Services API, incremental changes made on the client and server are exchanged to bring the client cache in sync with the server. The diagram above shows the different components of the sync framework. Below is a brief description of each component:
SyncAgent
The sync agent is the synchronization maestro. Typically, it is located at the client side and runs the show in response to client application requests. The agent accepts two sync providers, one for the client database and the other for the server database.
SyncTable
Defines a table that the client wishes to synchronize. This includes the desired direction for the flow of changes, i.e. Snapshot, Downloadonly, Uploadonly or Bidirectional. The SyncTable object allows you to specify your preferred table creation option. When the sync relationship is established in the very first sync, the sync runtime will check the creation option for every table. It then decides how to proceed with the schema creation of the table. If needed, the agent will download the schema definition from the server and apply it on the local database.
ClientSyncProvider
The client sync provider abstracts away the underlying data store at the client side. Sync Services ships with ClientSyncProvider for SQL Server CE. SQL CE is a lightweight in-proc database with about a 2MB footprint. You don't have to worry about a thing when it comes to setting up the client. As you will see in the sample application, the tables' schema and all sync-tracking infrastructure are set up for you by the sync runtime.
ServerSyncProvider
The server sync provider is where you will write your commands. Sync Services ships with DbServerSyncProvider tailored towards relational stores. It allows you to interact with any database supported by ADO.NET. For each table you wish to synchronize, a SyncAdapter object is needed. SyncAdapter, as described in detail below, is where sync DB commands are located. The provider also exposes two extra commands of its own:
SelectNewAnchorCommand - the server provider uses this command to get the new sync marker. The new anchor obtained by this command, along with the old anchor obtained from the synchronizing client, define the window for new incremental changes to be enumerated. SelectClientIdCommand - when building a bidirectional sync application, each row needs to store which client made the last change to it. This information is needed, as you will see later. The server provider uses this command to map a client GUID to an ID of type integer. Each synchronizing client identifies itself by a GUID that is stored at the client. Using this command, you can build a simple map from GUID to int. This is typically done to save space. However, you are welcome to use the GUID itself and leave this command empty if you so choose.
SyncAdapter
The SyncAdapter is modeled after the DataAdapter, albeit with a different set of database commands for the sync processes:
InsertCommand - the server provider uses this command to apply inserts to the server database UpdateCommand - the server provider uses this command to apply updates to the server database DeleteCommand - the server provider uses this command to apply deletes to the server database SelectIncrementalInsertsCommand - the server provider uses this command to enumerate inserts that took place on the server database since the last time the client synchronized SelectIncrementalUpdatesCommand - the server provider uses this command to enumerate updates that took place on the server database since the last time the client synchronized SelectIncrementalDeletesCommand - the server provider uses this command to enumerate deletes that took place on the server since the last time the client synchronized SelectConflictUpdatedRowsCommand - the server provider uses this command to get hold of the existing row that led to the failure of the insert or update command. This command will look up the conflicting row in the base table SelectConflictDeletedRowsCommand - the server provider uses this command to get hold of the existing row that led to the failure of insert, update or delete command. This command will look up the conflicting row in the tombstone table
Although there are more commands on the SyncAdapter compared to DataAdapter, you should not be worried, as not all commands are needed. For example, if you are implementing a download-only scenario, only the three SelectIncremental commands are needed. Moreover, if you just want to get started quickly, the SqlSyncAdapterBuilder can help you generate adapters on the fly at runtime! Some restrictions apply, of course.
Deployment Scenarios
Synchronization services can be deployed in different set-ups:
Two-tier Deployment
In two-tier set-up, the ClientSyncProvider, SyncAgent and ServerSyncProvider run on the same process or node. In this case, the application will have a direct connection with the back-end database.
N-tier Deployment
In n-tier set-ups, as in the diagram above, the ClientSyncProvider and SyncAgent run in the same process on the client side. The ServerSyncProvider resides on the mid-tier. The sync proxy is a thin wrapper that implements the ServerSyncProvider interface in order to plug seamlessly into the SyncAgent and relay calls to the web service.
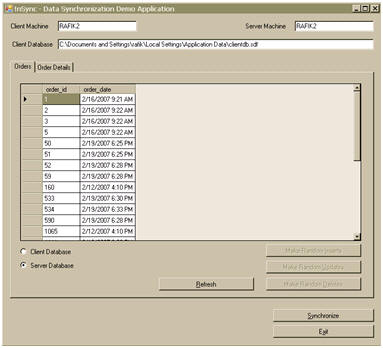
Sample Application Overview
Let us put the sync services to work. For this sample, I am developing a line of business applications (LOB) for sales personnel in the field. I want to enable them to enter orders while on the go, using their laptops. At the end of the day, each sales agent connects to the corporate network to synchronize his or her local changes and also receive orders made by other sales agents. That said, I need bidirectional synchronization. For simplicity's sake, I choose to focus on two tables only: order and order_details. The schema for the tables is as follows:
CREATE DATABASE pub
GO
CREATE TABLE pub..orders(
order_id int NOT NULL primary key,
order_date datetime NULL)
GO
CREATE TABLE pub..order_details(
order_id int NOT NULL primary key,
order_details_id int NOT NULL,
product nvarchar(100) NULL,
quantity int NULL)
GO
Enable Change Tracking
Take a quick look again at the orders and order_details table definitions. There is no way I can bring incremental changes down to the client. I need to be able to write a simple select statement to enumerate changes that occurred since the last time the client synchronized. To do this, I need to add extra columns to track changes such that I can easily identify new changes that the client has not seen before.
Tracking Inserts and Updates
To track inserts and updates, I need the following columns:
create_timestamp: this column tells me when the row was created. It is of type bigint since only one column per table is allowed to be of the timestamp type, which I reserve for the next column. I use a default value for this column as shown in the code below. update_timestamp: this column reflects the timestamp of the last update. It is updated automatically by the SQL Server engine. update_originator_id: this is an integer column that identifies who made the last change. I give the server_id a value of 0. Each client will have its own ID. This column is needed for a very good reason. Let's say a client just uploaded its changes and then it goes to download server changes. Without the ID column, the same changes just uploaded will come back to the client. I've no way to distinguish this client change from other clients' in my incremental select statements. By using the update_orginator_id column, I can select changes made by other clients or by the server itself.
ALTER TABLE pub..orders add create_timestamp bigint default @@DBTS+1
ALTER TABLE pub..order_details add create_timestamp bigint default @@DBTS+1
GO
ALTER TABLE pub..orders add update_timestamp timestamp
ALTER TABLE pub..order_details add update_timestamp timestamp
GO
ALTER TABLE pub..orders add update_originator_id int null default 0
ALTER TABLE pub..order_details add update_originator_id int null default 0
GO
Setting and updating the values of the tracking columns is another matter. The create_timestamp value is only set at insert time and the default constraint should take care of it. The update_timestamp is of type timestamp. This means that SQL server maintains the value for inserts and updates.
The update_originator_id, however, needs a little bit of work. Please note that sync runtime will take care of updating the originator_id column, but if the changes were made outside of sync -- i.e. a user fires up SQL management studio and makes some changes -- then we need to do some fix-up behind the scenes. The desired behavior is to set the value to server_id if a new row is inserted. This is taken care of by the default constraint. If a row is updated, then we need to reset the originator_id back to server_id if and only if the change was not made by sync runtime. To achieve that, I need an update trigger for each table, as shown in the code below:
USE pub
GO
CREATE TRIGGER orders_update_trigger on orders FOR UPDATE
AS
UPDATE o
SET o.update_originator_id = 0
FROM [orders] o JOIN [inserted] i on o.order_id = i.order_id
WHERE NOT UPDATE(update_originator_id)
GO
CREATE TRIGGER order_details_update_trigger ON order_details FOR UPDATE
AS
UPDATE o
SET o.update_originator_id = 0
FROM [order_details] o JOIN [inserted] i on o.order_id = i.order_id
WHERE NOT UPDATE(update_originator_id)
GO
Tracking Deletes
With tracking inserts and updates taken care of, what about deletes? For deletes, I will need a 'tombstone' table to store deleted rows. Tombstone is a term commonly used in synchronization and replication literature. Of course, you can still call it 'deleted table' or anything that works for you. Here are the TSQL statements for creating the tombstone tables:
CREATE TABLE pub..orders_tombstone(
order_id int NOT NULL primary key,
order_date datetime NULL,
update_originator_id int default 0,
update_timestamp timestamp,
create_timestamp bigint)
CREATE TABLE pub..order_details_tombstone(
order_id int NOT NULL primary key,
order_details_id int NOT NULL,
product nvarchar(100) NULL,
quantity int NULL,
update_originator_id int default 0,
update_timestamp timestamp,
create_timestamp bigint)
GO
While I only need to store the PK to identify the row that was deleted, I prefer to copy the entire row. My reasoning is that later on, when I implement conflict detection and resolution logic (not shown in this sample; see my blog), I would want to represent the deleted row to the end user to resolve the conflict. Showing only the PK is not a great help. Notice that the same tracking columns added to the base tables are created in the tombstone table, too. For the next step -- I bet you figured it already -- we need a delete trigger to copy deletes to the tombstone tables. Here it is:
CREATE TRIGGER orders_delete_trigger ON orders FOR DELETE
AS
INSERT INTO into pub..orders_tombstone (order_id, order_date, _
create_timestamp, update_originator_id)
SELECT order_id, order_date, create_timestamp, 0 FROM DELETED
GO
CREATE TRIGGER order_details_delete_trigger ON order_details FOR DELETE
AS
INSERT INTO pub..order_details_tombstone (order_id, order_details_id,_
product, quantity, create_timestamp, update_originator_id)
SELECT order_id, order_details_id, product, quantity, create_timestamp,_
0 FROM DELETED
GO
With that, change tracking is complete and we are set for bidirectional synchronization.
Code Walkthrough
In this example, I am building a two-tier offline application. This means that the client will have a direct connection to the server database to execute queries. The changes made to the back-end tables to track changes conclude the server-side work. Now we switch gears to the client side.
Initialization
In two-tier set up, the SyncAgent, ClientSyncProvider and ServerSyncProvider will run on the client application. The initialization code below shows the wiring of these three components.
SyncAgent syncAgent = new SyncAgent();
DbServerSyncProvider serverSyncProvider = new DbServerSyncProvider();
SqlConnectionStringBuilder builder = new SqlConnectionStringBuilder();
builder["Data Source"] = textServerMachine.Text;
builder["integrated Security"] = true;
builder["Initial Catalog"] = "pub";
SqlConnection serverConnection = new SqlConnection(builder.ConnectionString);
serverSyncProvider.Connection = serverConnection;
SyncAgent.ServerSyncProvider = serverSyncProvider;
string connString = "Data Source=" + dbPathTextBox.Text;
if (false == File.Exists(dbPathTextBox.Text))
{
SqlCeEngine clientEngine = new SqlCeEngine(connString);
clientEngine.CreateDatabase();
clientEngine.Dispose();
}
SqlCeClientSyncProvider clientSyncProvider =
new SqlCeClientSyncProvider(connString);
syncAgent.ClientSyncProvider = (ClientSyncProvider)clientSyncProvider;
Configuring Sync Tables
To configure a table for synchronization, a SyncTable object needs to be created and set up with desired properties:
TableCreationOption tells the agent how to initialize the new table in the local database. In the code below, I chose DropExistingOrCreateNewTable to instruct the runtime to delete an existing table in the client database, if any, and create a new one. This process takes place in the very first sync only. SyncDirection is how changes flow with respect to the client {Download, Upload, Bidirectional or Snapshot}
To synchronize changes for both tables in one go, I need to use a common SyncGroup object. This is important if the tables have a PK-FK relationship. Grouping will ensure that an FK change won't be applied before its PK is applied.
SyncTable tableOrders = new SyncTable("orders");
tableOrders.CreationOption =
TableCreationOption.DropExistingOrCreateNewTable;
tableOrders.SyncDirection = SyncDirection.Bidirectional;
SyncTable tableOrderDetails = new SyncTable("order_details");
tableOrderDetails.CreationOption =
TableCreationOption.DropExistingOrCreateNewTable;
tableOrderDetails.SyncDirection = SyncDirection.Bidirectional;
SyncGroup orderGroup = new SyncGroup("AllChanges");
tableOrders.SyncGroup = orderGroup;
tableOrderDetails.SyncGroup = orderGroup;
syncAgent.SyncTables.Add(tableOrders);
syncAgent.SyncTables.Add(tableOrderDetails);
Configuring Sync Adapters
In this step, I need to build a SyncAdapter for the orders and order_details tables and attach it to the DbServerSyncProvider instance. Here, I will make use of the tracking columns in each table. While I can go ahead and author each adapter manually, I will use SqlSyncAdapterBuilder to do it instead. All I need to do is feed the builder with the names of the tracking columns, along with the tombstone table name, and it will generate a SyncAdapter for me. The code below shows this process for both tables.
While the SqlSyncAdapterBuilder is a cool tool to get started quickly, it is not intended for production code usage since it makes extra calls to the back-end database to learn about the schema of the tables and data types. This process is repeated in every sync, adding unnecessary overhead.
SqlSyncAdapterBuilder ordersBuilder = new SqlSyncAdapterBuilder();
ordersBuilder.Connection = serverConnection;
ordersBuilder.SyncDirection = SyncDirection.Bidirectional;
ordersBuilder.TableName = "orders";
ordersBuilder.DataColumns.Add("order_id");
ordersBuilder.DataColumns.Add("order_date");
ordersBuilder.TombstoneTableName = "orders_tombstone";
ordersBuilder.TombstoneDataColumns.Add("order_id");
ordersBuilder.TombstoneDataColumns.Add("order_date");
ordersBuilder.CreationTrackingColumn = "create_timestamp";
ordersBuilder.UpdateTrackingColumn = "update_timestamp";
ordersBuilder.DeletionTrackingColumn = "update_timestamp";
ordersBuilder.UpdateOriginatorIdColumn = "update_originator_id";
SyncAdapter ordersSyncAdapter = ordersBuilder.ToSyncAdapter();
((SqlParameter)ordersSyncAdapter.SelectIncrementalInsertsCommand.Parameters[
"@sync_last_received_anchor"]).DbType = DbType.Binary;
((SqlParameter)ordersSyncAdapter.SelectIncrementalInsertsCommand.Parameters[
"@sync_new_received_anchor"]).DbType = DbType.Binary;
serverSyncProvider.SyncAdapters.Add(ordersSyncAdapter);
SqlSyncAdapterBuilder orderDetailsBuilder = new SqlSyncAdapterBuilder();
orderDetailsBuilder.SyncDirection = SyncDirection.Bidirectional;
orderDetailsBuilder.Connection = serverConnection;
orderDetailsBuilder.TableName = "order_details";
orderDetailsBuilder.DataColumns.Add("order_id");
orderDetailsBuilder.DataColumns.Add("order_details_id");
orderDetailsBuilder.DataColumns.Add("product");
orderDetailsBuilder.DataColumns.Add("quantity");
orderDetailsBuilder.TombstoneTableName = "order_details_tombstone";
orderDetailsBuilder.TombstoneDataColumns.Add("order_id");
orderDetailsBuilder.TombstoneDataColumns.Add("order_details_id");
orderDetailsBuilder.TombstoneDataColumns.Add("product");
orderDetailsBuilder.TombstoneDataColumns.Add("quantity");
orderDetailsBuilder.CreationTrackingColumn = "create_timestamp";
orderDetailsBuilder.UpdateTrackingColumn = "update_timestamp";
orderDetailsBuilder.DeletionTrackingColumn = "update_timestamp";
orderDetailsBuilder.UpdateOriginatorIdColumn = "update_originator_id";
SyncAdapter orderDetailsSyncAdapter = orderDetailsBuilder.ToSyncAdapter();
((SqlParameter)
orderDetailsSyncAdapter.SelectIncrementalInsertsCommand.Parameters[
"@sync_last_received_anchor"]).DbType = DbType.Binary;
((SqlParameter)
orderDetailsSyncAdapter.SelectIncrementalInsertsCommand.Parameters[
"@sync_new_received_anchor"]).DbType = DbType.Binary;
serverSyncProvider.SyncAdapters.Add(orderDetailsSyncAdapter);
Configuring Anchor and ClientID Commands
As I mentioned before, the DbServerSyncProvider has two more commands. Let's see how to configure them:
SelectNewAnchorCommand: Returns a new high watermark for current sync. This value is stored at the client and used as the low watermark in the next sync. The old and new anchor values define the window where new changes will be collected by the SelectIncremental commands. The value returned must be of the same type as the tracking columns used on the server. That said, we need a timestamp value. I therefore use "Select @@DBTS" to get the most recent timestamp for the database. SelectClientIdCommand: Finds out the client ID on the server. This command helps avoid downloading changes that the client had made before and applied to the server. Basically, it breaks the loop. There are several ways to set this value with varying complexity. The simplest approach is to assign a value of 1 to the client ID.
SqlCommand anchorCmd = new SqlCommand();
anchorCmd.CommandType = CommandType.Text;
anchorCmd.CommandText =
"Select @" + SyncSession.SyncNewReceivedAnchor + " = @@DBTS";
anchorCmd.Parameters.Add("@" + SyncSession.SyncNewReceivedAnchor,
SqlDbType.Timestamp).Direction = ParameterDirection.Output;
serverSyncProvider.SelectNewAnchorCommand = anchorCmd;
SqlCommand clientIdCmd = new SqlCommand();
clientIdCmd.CommandType = CommandType.Text;
clientIdCmd.CommandText = "SELECT @" + SyncSession.SyncOriginatorId + " = 1";
clientIdCmd.Parameters.Add("@" + SyncSession.SyncOriginatorId,
SqlDbType.Int).Direction = ParameterDirection.Output;
serverSyncProvider.SelectClientIdCommand = clientIdCmd;
The client ID of 1 works fine if there is only one client. This is just to get you started quickly. But what should you do to handle multiple clients? In this case, you need a unique new number for every client. To do this without writing a lot of code, you can use yet another built-in session parameter called sync_client_id. This parameter is of the type GUID that is generated by the client when it is initialized in the very first sync. While using GUID as the update_originator_id is possible, it is not a very attractive idea as it increases the size of the table unnecessarily. All I really need is an integer and that's why I chose that from the beginning. The best solution is to implement a simple mapping table {identity, client_guid} and maintain it on the server. To do that, the SelectClientIdCommand would implement the following semantics:
- Given a GUID, find the corresponding identity value
- If the identity does not exist, add a new row to the map and return the new assigned identity
You get the idea. Luckily for us, the framework provides a simple way to avoid doing that while in experimental phase. This is done by passing the hash value of the GUID, which is of type integer. Of course, there is a possibility of a hash collision but again, this is for testing purposes only. The code would look like the following:
SqlCommand clientIdCmd = new SqlCommand();
clientIdCmd.CommandType = CommandType.Text;
clientIdCmd.CommandText =
"SELECT @" + SyncSession.SyncOriginatorId + " = @sync_client_id_hash";
clientIdCmd.Parameters.Add("@sync_client_id_hash", SqlType.Int);
clientIdCmd.Parameters.Add("@" + SyncSession.SyncOriginatorId,
SqlDbType.Int).Direction = ParameterDirection.Output;
serverSyncProvider.SelectClientIdCommand = clientIdCmd;
Synchronize!
Now we are set to kick off synchronization. Before that, I'd like to subscribe to SyncProgressEvent on both providers so that I can show a progress dialog while synchronization is underway.
clientSyncProvider.SyncProgress += new
EventHandler<SyncProgressEventArgs>(ShowProgress);
serverSyncProvider.SyncProgress += new
EventHandler<SyncProgressEventArgs>(ShowProgress);
SyncStatistics syncStats = syncAgent.Synchronize();
Conclusion
The interest in offline experience is growing rapidly, fueled by a new breed of rich internet applications. The vision of software as a service where the application has a web component and a desktop component stresses the need for synchronization as the glue that ties these components together. However, synchronization technologies have not become mainstream yet. Few developers have the know-how to build sync-enabled applications. With Microsoft Synchronization Services for ADO.NET, developers have a starting point to get into sync algorithms and learn how to extend their data applications with offline components.
What's Next
In this document, I shared with you the first demo application of a series of demos that I prepared to showcase the new API. The rest of the demos are posted on my blog and website. Each demo builds on the previous one and shows a new feature of the API. Here is a quick overview of the demo series:
Feedback
I'd appreciate if people can post issues, requests, questions, etc. in the public forum. The forum is monitored by many people in the sync team and is thus a more effective way of communication. I also hope that I was able to introduce the new framework to you through this article. The only way I will know if you like it is by rating it. Please vote when you can. You can also contact me through my blog.
History
- 3/15/2007: Initial Release - Sample is based on Synchronization Services for ADO.NET CTP 1
- 5/01/2007: Fixed
update trigger. Expanded on the SelectClientId logic. Added link to demo VI - 5/28/2007: Updated the project to work with Beta 1 bits; added link to demo VII
- 8/17/2007: Updated the project to work with Beta 2 bits
- 11/27/2007: Update with the release of Sync Services for ADO.NET final bits
- 1/2/2008: Add link to demo VIII

