Introduction
In the previous article: Improving the performance of queries using SQL Server: Part 1, we discussed using SQL Profiler to identify queries that need looking at, to see if performance can be improved. We learned how to set the criteria that allow us to focus on the queries that are most likely to give us performance gains if we fix them.
In this article, we are going to look at how to take the information we gleaned from the SQL Profiler and use it to enhance our queries so that they are more performant.
Starting out
Before we dive into looking at indexes and execution plans, we need to consider whether or not a query is well written or not. There's no point in wasting time looking at plans if the fundamental query is so badly written that we would be better off rewriting it.
This query is a prime example of a badly written query that needs a serious kick up the backside before we even consider the plan:
CREATE PROCEDURE dbo.BadSelectUsingCursor
@StartQTY INT,
@EndQTY INT
AS
DECLARE @userID INT
DECLARE @forename NVARCHAR(30)
DECLARE @surname NVARCHAR(30)
DECLARE @qty INT
DECLARE @Price MONEY
DECLARE @ProductID INT
SET NOCOUNT ON
CREATE TABLE #Output
(
Forename NVARCHAR(30),
Surname NVARCHAR(30),
Qty INT,
TotalPrice MONEY
)
DECLARE getOrders_Cursor CURSOR FOR
SELECT Qty, UserId, productID FROM userOrders WHERE
Qty BETWEEN @StartQty AND @EndQty
OPEN getOrders_Cursor
FETCH NEXT FROM getOrders_Cursor INTO @Qty, @userID, @productID
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE userOrders_Cursor CURSOR FOR
SELECT forename, surname FROM [user]
WHERE [ID] = @userID
OPEN userOrders_Cursor
FETCH NEXT FROM userOrders_Cursor
INTO @forename, @surname
SELECT @Price = Cost FROM
Product WHERE Id = @productID
SET @Price = @Price * @Qty
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO #Output
VALUES (@Forename, @Surname, @Qty, @Price)
FETCH NEXT FROM userOrders_Cursor
INTO @forename, @surname
END
CLOSE userOrders_Cursor
DEALLOCATE userOrders_Cursor
FETCH NEXT FROM getOrders_Cursor INTO @Qty, @userID, @productID
END
CLOSE getOrders_Cursor
DEALLOCATE getOrders_Cursor
SELECT * FROM #Output
As we can see, the big problem with this query is that it is just badly written. It uses cursors and temporary tables completely unnecessarily. By the way, this is a version of a query that I had to rewrite a couple of years ago. Rewriting it saw performance gains of nearly 1500% - yes, that's right, 1500%.
Right, the first thing that we need to do then is to rewrite the query so that it cuts out the unnecessary work that it is doing. By reading through this query, we discover that it needs to return the customer first and last name, the quantity of goods they have ordered, and the total price based on a quantity range. Armed with this information, we rewrite this query as:
CREATE PROCEDURE dbo.BadSelectUsingCursor
@StartQTY INT,
@EndQTY INT
AS
SELECT
forename,
surname,
qty,
qty * Cost as TotalPrice
FROM
[user] a
INNER JOIN
userorders
ON
userid = a.[id]
INNER JOIN
product p
ON
productId = p.[id]
WHERE
qty BETWEEN @StartQTY AND @EndQty
GO
Now, when this query runs, it returns the data far faster. In my test environment, the first version returns all of the records in 16 seconds, and the rewritten version returns the same records in less than a second.
At this point, we need to consider whether or not it is worth continuing to seek improvements in our query. Rerunning this query through SQL Profiler is a good way to see if we need to worry about this query.
Let's assume that we're done with this query now and move onto a query that appears to be well written.
Execution plans
Before we go any further, it's worth getting an understanding of what an execution plan is and why we should be bothered about it.
Basically speaking, an execution plan (sometimes called a query plan or query execution plan) is the series of steps the database will use to access information. Since the language that we use to access this data, SQL, is declarative, there are usually multiple ways to execute a query. Each method will have a different performance associated with it, and this is known as the cost.
It is the responsibility of the database engine to consider the different methods for determining which approach is the best. As developers, it is up to us to help the database choose the best method by making our queries as efficient as possible.
Right, now that we have a common understanding of what the execution plan is used for, how do we actually find out what the database is actually doing? If you remember, in the first article, we traced what SQL was being run on the database. The good news is that we can take this trace information and run it directly against the database. (In my examples, I'm using the Northwind database on SQL Server 2000 with Query Analyzer, but the results should be similar running this in SSIS and SQL Server 2005.)
The first query that we are going to look at is:
SELECT
Title,
FirstName,
LastName
FROM
Employees emp
LEFT JOIN
Orders ord
ON
emp.EmployeeId = ord.EmployeeId
INNER JOIN
Shippers ship
ON
ShipVia = ShipperID
WHERE
Title LIKE 'Sales%' AND
ShipName LIKE 'Chop%'
This is a fairly trivial query, but it yields an interesting plan. To run it, we copy it into Query Analyzer. Before we run the query, it is worth seeing what the database engine thinks the query will need to do. To get at this information, we will display the estimated execution plan. This can be found in Query > Display Estimated Execution Plan. This is the plan of this query:
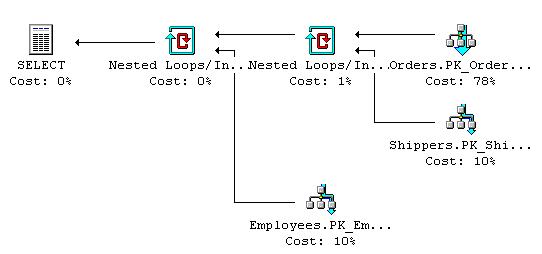
Let's take a look at what this actually means.
Orders.PK_Order
This is a clustered index scan. A clustered index scan performs a scan on the clustered index (cunningly enough). In this case, the clustered index is the primary key on the orders table. Interestingly enough, there is a where clause that must be further considered by the engine here, which is the ShipName LIKE 'Chop%' portion of the query.
If the argument portion of this scan contains an item that is present in an ORDER BY clause, then the query engine must return the rows in the order which the clustered index has stored it. If it isn't present in the ORDER BY clause, then the engine is free to generate another (possibly better) approach to scan the index, which might not be sorted.
Shippers.PK_Shi and Employees.PK_Em
These are both clustered index seeks. They differ from the scan because they can use the ability of the RDBMS to seek indexes to retrieve rows from a clustered index. Similar to the scan, the where clause leads to the database engine determining which rows satisfy the seek condition, and then evaluates the rows that match the where condition from these. Like the scan, the presence of the item in an ORDER BY statement can affect the way that it is evaluated.
Nested loops
These are the physical ways in which join conditions are actually satisfied. They work by looping through the top query item and scanning the bottom row for matching rows. The database may, optionally, perform a sort first to improve the performance of the scanning because it will try to use indexes to match where possible.
The last part of the execution plan is the select. This is the physical act of retrieving the rows from the database.
At this point, we can run the query and see how it performs. If we want to see the execution plan that the database engine finally settled on, we just need to select Query > Show Execution Plan. When we run the query, the actual execution plan will be displayed. All being well, it shouldn't look much different to the estimated execution plan.
Index Tuning Wizard
With our query still showing in Query Analyzer, select Query > Index Tuning Wizard. This wizard will analyze the query to determine what indexes are needed to improve the performance of our query, and it should tell us what percentage performance gain we will get if we accept its recommendations.
Select Next > to get to the first real page of the wizard. Here we can choose the server and database that we want to analyze, plus how we want to manage existing indexes.

If we deselect Keep all existing indexes, the query engine has the chance to really change the way that the current query is optimized. Current indexes may be removed and new ones may be added to improve the performance, so at first glance, this seems to be an attractive option as it can generally recommend changes that offer more improvement than if you leave the indexes as they are. But we must beware of the temptation this offers. If we remove indexes to improve the performance of one query, we can end up ruining other queries that are running acceptably. Like so much else in life, just because we can do it doesn't mean that we should.
Right, we are going to select Thorough tuning and then Next >. The workload screen allows us to choose the query we are going to optimize. In this case, leave it set to SQL Query Analyzer selection, and then click Next >. This brings us to the table selection screen:
Choose Select All Tables and then click Next > again. The tuning wizard will now search analyze the query and recommend the indexes that are needed to improve the performance.
In our sample, we should see a 21% improvement, which isn't too shabby. Click Next > again, and we get the chance to save the changes or apply them immediately. Check the Apply changes box and then Next > again. Finally, select Finish to actually perform the update.
If we display the execution plan again, we can see that it differs from our original with the introduction of an Indexed Seek on Orders.Orders5. This means that it is now seeking on the index rather than performing the clustered index scan.
Now, we are going to move onto another more complex query.
SELECT DISTINCT
Title,
FirstName,
LastName,
ProductName,
(dets.UnitPrice * dets.Quantity)
FROM
Employees emp
LEFT JOIN
Orders ord
ON
emp.EmployeeId = ord.EmployeeId
INNER JOIN
[Order Details] dets
ON
ord.OrderID = dets.OrderID
INNER JOIN
Products prod
ON
prod.ProductID = dets.ProductID
INNER JOIN
Shippers ship
ON
ShipVia = ShipperID
WHERE
(dets.UnitPrice * dets.Quantity) > 200
As you can see, we are picking up more tables, and the criteria is a little bit more complex. So, what does the database engine think of this? Well, this is the execution plan that this produces:
We can see that this looks pretty similar to the previous query. The only new things to look at are Compute Scalar and Sort/Distinct.
Compute Scalar
With the introduction of the calculation in the query, the optimizer knows that it needs to perform operations to return a calculated result. Here, we have used the same calculation in two places, so the optimizer knows that it can use the same scalar value in both locations.
Sort/Distinct
By adding the distinct keyword to the query, we tell the optimizer that it needs to sort the input so that it can remove duplicate rows.
If we run the Index Tuning Wizard on this query, following the same steps outlined above, we end up again with an estimated 21% improvement.
Running the query again gives us the following plan:
Hash Match/Inner Join
Note that we now have a different filter criteria added. We now have a Hash Match/Inner Join. This basically uses the top table to build the hash table, and the bottom table is compared against it to see if there are matches.
Gotchas
At this stage, you might think that the best thing that you can do is add an index to every field and that way the database engine will always query against the index.
It's tempting, but you should really avoid going this route because indexes must be maintained. This means that every time you do an insert, update, or delete, the indexes must be modified. The more indexes you have, the more that has to be done to maintain them. So, while selects may start to return quicker, you may find that all other operations degrade. Plus, as an added gotcha, indexes have a maximum size of 900 bytes. So, you can't index a Unicode field like this: NVARCHAR(500).
Conclusion
Using tools like SQL Profiler, Query Analyzer (or SSIS), and SQL Profiler, we can identify what the likely causes of slowdowns on our systems are. We can take long running queries and improve their performance, by rewriting or by tuning the indexes.
We haven't covered all types of execution plan operators, such as Sequential Scans, but I hope that I've presented enough information for you to want to explore this topic further.

