Introduction
MySQL has a non-standard extension to operators called null-safe equal to operator, <=>. The operator compares two values and if they are identical, returns 1.
The difference from the normal equal to operator is that if both of the operands are null, the result is 1 instead of null.
Before jumping into the implementation
So why is null handled differently from other values anyway? ANSI standard defines a null value as unknown. When comparing
a null to a null, they are not equal, ever. To be more specific, they are not unequal either, one null is never less than another
null and so on. Since the real value of null is unknown, any comparison result is unknown by definition, we simply don't know the result.
From a design point of view, null represents a missing piece of information and it should always be handled that way. Typically, if you need to find records where
null matches a null, the best thing is to sit down, put your legs on the table, and figure out the root cause. When found, it should be fixed if possible.
So why write this article at all? I thought about it a lot before publishing this. One reason was to raise discussions about null equality and the other was
that there still are cases where this kind of comparison may be justified. One example could be a reporting application where dynamic conditions are used. In such
an application, null along any other value may be a valid criteria defined by the user to find records. In such a case, this comparison may simplify the query building process.
Long story short: before using this, think about the situation carefully and if you still are convinced that this is the correct way, then hopefully this article saves some work.
Implementing in SQL Server
Since SQL Server doesn’t have this kind of operator, the typical solution is to use two separate conditions, for example:
…
WHERE Column1 = Column2
OR (Column1 IS NULL AND Column2 IS NULL)
Another solution is to create a user defined function which handles the comparison. In order to manage different data types, it’s easiest to use the sql_variant data
type for the parameters. Sql_variant can receive most of the other data types except:
- timestamp
- image
- ntext
- text
- xml
- hierarchyid
- and CLR UDT
In the simplest form, the function would evaluate the equality of the operands or null values directly, so the function body would look something like:
CREATE FUNCTION NullSafeEqual_incomplete(
@left sql_variant, @right sql_variant) RETURNS smallint
AS
BEGIN
DECLARE @conversionDone smallint = 0;
DECLARE @returnValue smallint = 0;
IF (@left IS NULL AND @right IS NULL) BEGIN
SET @returnValue = 1;
SET @conversionDone = 1;
END;
IF (@left IS NULL AND @right IS NOT NULL) BEGIN
SET @returnValue = 0;
SET @conversionDone = 1;
END;
IF (@left IS NOT NULL AND @right IS NULL) BEGIN
SET @returnValue = 0;
SET @conversionDone = 1;
END;
IF (@conversionDone = 0 AND @left = @right) BEGIN
SET @returnValue = 1;
SET @conversionDone = 1;
END;
RETURN (@returnValue);
END;
The function first checks if both of the operands are null. If that’s true, 1 is returned. If not it checks if either one of the parameters is null
and the other isn’t, and at last, the equality is tested. Now, let’s test this with a simple query with integer values:
SELECT dbo.NullSafeEqual_incomplete (1, 1) AS Comparison1,
dbo.NullSafeEqual_incomplete (1, null) AS Comparison2,
dbo.NullSafeEqual_incomplete (null, null) AS Comparison3;
The results are:
Comparison1 Comparison2 Comparison3
----------- ----------- -----------
1 0 1
So 1 is equal to 1 but also null is equal to null. What if other data types are used or data types are mixed?
SELECT dbo.NullSafeEqual_incomplete('A', 'A') AS Comparison1,
dbo.NullSafeEqual_incomplete('A', null) AS Comparison2,
dbo.NullSafeEqual_incomplete(1, '1') AS Comparison3;
Results then are:
Comparison1 Comparison2 Comparison3
----------- ----------- -----------
1 0 0
Everything else seems fine, but the comparison 3 is incorrect. If a condition 1 = '1' is evaluated, for example, in a WHERE clause,
it results to true. However, the function returned 0. This is because the sql_variant values are different. Even though they seemingly contain the same value,
it’s a different data type and no automatic conversion takes place. This actually means that the function won’t return correct results if data types are mixed.
SQL Server has a function called SQL_VARIANT_PROPERTY, which returns the actual underlying data type. In order to do this comparison properly, the data needs
to be cast to the actual data type and then compared using the same rules that apply when actual data types are used.
This means that each data type has to be checked individually. One way of doing this is to list all the combinations for different data types. So the function can, for example,
have a logic like:
DECLARE @conversionDone smallint = 0;
DECLARE @returnValue smallint = 0;
DECLARE @leftdatatype nvarchar(100) =
CONVERT(nvarchar, SQL_VARIANT_PROPERTY(@left, 'BaseType'));
DECLARE @rightdatatype nvarchar(100) =
CONVERT(nvarchar, SQL_VARIANT_PROPERTY(@right, 'BaseType'));
IF (@left IS NULL AND @right IS NULL) BEGIN
SET @returnValue = 1;
SET @conversionDone = 1;
END;
IF (@left IS NULL AND @right IS NOT NULL) BEGIN
SET @returnValue = 0;
SET @conversionDone = 1;
END;
IF (@left IS NOT NULL AND @right IS NULL) BEGIN
SET @returnValue = 0;
SET @conversionDone = 1;
END;
IF (@conversionDone = 0 AND @left = @right) BEGIN
SET @returnValue = 1;
SET @conversionDone = 1;
END;
IF (@conversionDone = 0) BEGIN
IF (@conversionDone = 0 AND @leftdatatype = N'int') BEGIN
IF (@conversionDone = 0 AND @rightdatatype = N'binary') BEGIN
IF CONVERT(int, @left) = CONVERT(binary, @right) BEGIN
SET @returnValue = 1;
END;
SET @conversionDone = 1;
END;
IF (@conversionDone = 0 AND @rightdatatype = N'varbinary') BEGIN
IF CONVERT(int, @left) = CONVERT(varbinary, @right) BEGIN
SET @returnValue = 1;
END;
SET @conversionDone = 1;
END;
… etc.
I know the implementation isn't very fancy, but actually this was very easy to generate.
Also note that not all of the possible data type combinations are listed in the function, for example, if equal comparison isn't allowed between the two data types.
Now, let’s run the same test with the complete function:
SELECT dbo.NullSafeEqual('A', 'A') AS Comparison1,
dbo.NullSafeEqual('A', null) AS Comparison2,
dbo.NullSafeEqual(1, '1') AS Comparison3;
The result is:
Comparison1 Comparison2 Comparison3
----------- ----------- -----------
1 0 1
So now the equality check also works with mixed data types.
The function can receive valid parameter data types for sql_variant but the comparison between these data types isn’t valid and an error has to be raised
in such situations. However, RAISERROR cannot be used in functions, so this limitation has been overcome by causing a casting error like the following:
SET @returnValue = N'Incompatible datatype conversion from ' +
@leftdatatype + N' to ' + @rightdatatype;
Let’s test the error handling. If we execute the following:
SELECT dbo.NullSafeEqual( convert(money,5), NEWID()) AS Comparison1;
An error is generated:
Msg 245, Level 16, State 1, Line 1
Conversion failed when converting the nvarchar value
'Incompatible datatype conversion from money to uniqueidentifier'
to data type smallint.
The run-time error is the conversion from nvarchar to smallint, but the trick here is that the actual error message for incompatible
parameters is embedded into the error message; What cannot be converted: 'Incompatible datatype conversion from money to uniqueidentifier'.
Another type of error is a conversion error detected by SQL Server. For example, if a varchar and date are compared,
the varchar is converted to a date if possible. If this fails, an error occurs:
SELECT dbo.NullSafeEqual(CURRENT_TIMESTAMP, 'This is not a date') AS Comparison1;
When the above is run, a conversion error is returned:
Msg 241, Level 16, State 1, Line 2
Conversion failed when converting date and/or time from character string.
So no additional tests in the function are needed to test if the conversion itself succeeds.
Some further investigations
Single table queries
So how can this be used in SQL queries? First, let’s create a small table:
CREATE TABLE Table1 (
T1_Col1 int not null identity(1,1),
T1_Col2 int,
T1_Col3 int,
CONSTRAINT pk_Table1 PRIMARY KEY (T1_Col1)
);
And some data:
INSERT INTO Table1 (T1_Col2, T1_Col3) VALUES (1, 1);
INSERT INTO Table1 (T1_Col2, T1_Col3) VALUES (1, null);
INSERT INTO Table1 (T1_Col2, T1_Col3) VALUES (null, null);
INSERT INTO Table1 (T1_Col2, T1_Col3) VALUES (2, null);
Now if we want to get all the rows where T1_Col2 is equal to T1_Col3, the query would look like:
SELECT *
FROM Table1 t
WHERE dbo.NullSafeEqual(t.T1_Col2, t.T1_Col3) = 1
And the results would be:
T1_Col1 T1_Col2 T1_Col3
------- ------- -------
1 1 1
3 NULL NULL
So both rows are found.
Joins
What about joins then? First, let’s create a child table:
CREATE TABLE Table2 (
T2_Col1 int not null identity(1,1),
T2_Col2 int,
CONSTRAINT pk_Table2 PRIMARY KEY (T2_Col1)
);
And some data again:
INSERT INTO Table2 (T2_Col2) VALUES (1);
INSERT INTO Table2 (T2_Col2) VALUES (null);
INSERT INTO Table2 (T2_Col2) VALUES (null);
INSERT INTO Table2 (T2_Col2) VALUES (2);
If we want to get matching records from these tables based on T1_Col2 and T2_Col2, the query could look like:
SELECT *
FROM Table1 t1,
Table2 t2
WHERE dbo.NullSafeEqual(t1.T1_Col2, t2.T2_Col2) = 1
ORDER BY t1.T1_Col1, t2.T2_Col1;
And the results:
T1_Col1 T1_Col2 T1_Col3 T2_Col1 T2_Col2
------- ------- ------- ------- -------
1 1 1 1 1
2 1 NULL 1 1
3 NULL NULL 2 NULL
3 NULL NULL 3 NULL
4 2 NULL 4 2
It’s important to notice that Cartesian product is applied both ways, null doesn’t make an exception in this case when the function is used. Row 1 in Table 2
is repeated twice since it has two parents but also Row 3 in Table1 is repeated twice since it has two children.
The query above could also be written using the standard Join syntax:
SELECT *
FROM Table1 t1 inner join Table2 t2
ON dbo.NullSafeEqual(t1.T1_Col2, t2.T2_Col2) = 1
ORDER BY t1.T1_Col1, t2.T2_Col1;
Performance
What about performance then? If we create another test table:
CREATE TABLE Table3 (
T3_Col1 int not null identity(1,1),
T3_Col2 int
CONSTRAINT pk_Table3 PRIMARY KEY (T3_Col1)
);
And fill it with 200,000 rows of some random data and a few null rows:
SET NOCOUNT ON
DECLARE @counter int = 0;
BEGIN
INSERT INTO Table3 (T3_Col2) VALUES (NULL);
INSERT INTO Table3 (T3_Col2) VALUES (NULL);
WHILE (@counter < 200000) BEGIN
INSERT INTO Table3 (T3_Col2)
SELECT RAND( (DATEPART(mm, GETDATE()) * 100000 )
+ (DATEPART(ss, GETDATE()) * 1000 )
+ DATEPART(ms, GETDATE())) * 100000;
SET @counter = @counter + 1;
END;
INSERT INTO Table3 (T3_Col2) VALUES (NULL);
INSERT INTO Table3 (T3_Col2) VALUES (NULL);
END;
Let’s get a look at some rows:
SELECT * FROM Table3;
With my test run, the results started like:
T3_Col1 T3_Col2
------- -------
1 NULL
2 NULL
3 52343
4 52343
5 52349
6 52349
7 52349
8 52349
9 52349
10 52362
The next step is to create an index on T3_Col2:
CREATE INDEX X_Table3_T3Col2 ON Table3 (T3_Col2);
If a traditional select is used, for example, to fetch the nulls, the query would look like:
SELECT * FROM Table3 WHERE T3_Col2 IS NULL;
But more importantly, the execution plan shows that the index is used in order to fetch the data:
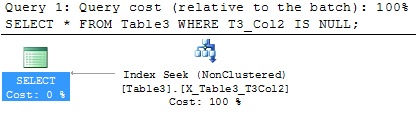
Now if the same is executed with the newly created function:
SELECT * FROM Table3 WHERE dbo.NullSafeEqual(T3_Col2, NULL) = 1;
The results are the same but there’s a big difference in the execution plan:

So actually SQL Server has to read through all the records and pass the value from T3_Col2 to the function in order to know if the condition is true.
This has a performance penalty so be careful when using this with larger sets of data.
History
- September 20, 2011: Created.
- September 20, 2011: Added the "Before jumping into implementation" chapter based on a good discussion with Mel Padden.

