Introduction
I've been looking for a solid (and granular) auditing solution that would keep track of the changes made to data in my SQL Server database for quite some time,
and have not been able to find one (other than commercial solutions). What I was looking for was simple: every time a record was inserted, deleted, or updated in one of the tables,
I wanted an audit of some sort to show what action was taken, by whom, when, and what the exact changes were (i.e., show both the before and after values for any affected field).
MS seems to have realized that this is badly needed since they apparently included something like it in SQL Server 2008, but for all I can tell, this only logs the actual
statement executed against the tables and does not keep track of the before/after values. The latter is critical for any good log or audit.
While looking around, I saw a few attempts at writing SQL triggers that would show this info, but while I can appreciate that SQL triggers can be quite efficient, I don't
like the fact that when they get long and complex, they become hard to maintain and in some cases unreadable. I saw that SQL triggers could make use of items
like COLUMNS_UPDATED, but these are not very straightforward to use. In essence, I was looking for something that would do the logging properly, be easy to maintain,
and - very important - be elegant. Enter CLR triggers.
I found out that you can create .NET triggers and attach them to the server, and they have access to the same objects and tables you would were you using a regular
SQL trigger. I also found a good starter article (http://social.msdn.microsoft.com/Forums/en-US/sqlnetfx/thread/60ed909b-51ac-425c-8e00-4d7978f39f70/)
that dealt with writing a CLR trigger for auditing, and my article is roughly based on it.
Prerequisites
Before you begin using this, a few things need to be taken into account:
- Execution of CLR objects must be enabled on the server. Enable this by executing the following statements within Enterprise Manager:
exec sp_configure 'clr enabled', 1
reconfigure
exec sp_configure
As far as I can tell, CLR triggers are supported in SQL Server 2005 and above. Not sure about earlier versions.Database projects are not supported by Visual Studio Express.The project must be configured to use .NET Framework 3.5.
Table structures
The sample table I'm working with is called Customers, and is quite straightforward. Here is the CREATE statement for it:
CREATE TABLE [dbo].[Customers]
(
[ID] [INT] IDENTITY(1, 1) NOT NULL,
[Name] [NVARCHAR](50) NOT NULL,
[Address1] [NVARCHAR](100) NULL,
[Address2] [NVARCHAR](100) NULL,
[City] [NVARCHAR](100) NULL,
[Zip] [NVARCHAR](100) NULL,
[Country] [NVARCHAR](100) NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ( [ID] ASC )
)
For the audit, the data has been normalized and is kept in a pair of header and detail tables. The header contains the table name, primary key values
for the affected record, a batch identifier that helps see which records were affected as part of the same INSERT/UPDATE/DELETE statement,
the user name and date, and finally a note field to keep track of exceptional cases (see further below for more details on these).
The details table then holds the before and after values of the affected fields.
Audit header table structure:
CREATE TABLE [dbo].[AuditHeader]
(
[AuditHeaderID] [INT] IDENTITY(1, 1) NOT NULL,
[Action] [NVARCHAR](5) NOT NULL,
[BatchID] [NVARCHAR](MAX) NOT NULL,
[TableName] [NVARCHAR](MAX) NOT NULL,
[PrimaryKey] [NVARCHAR](MAX) NOT NULL,
[Note] [NVARCHAR](MAX) NULL,
[UpdateDate] [DATETIME] NOT NULL,
[UpdateUserName] [NVARCHAR](MAX) NOT NULL,
CONSTRAINT [PK_AuditHeader] PRIMARY KEY CLUSTERED ( [AuditHeaderID] ASC )
)
Audit detail table structure:
CREATE TABLE [dbo].[AuditDetail]
(
[AuditHeaderID] [INT] NOT NULL,
[AuditDetailID] [INT] IDENTITY(1, 1) NOT NULL,
[FieldName] [NVARCHAR](100) NOT NULL,
[OldValue] [NVARCHAR](MAX) NULL,
[NewValue] [NVARCHAR](MAX) NULL,
CONSTRAINT [PK_AuditDetail] PRIMARY KEY CLUSTERED ( [AuditDetailID] ASC )
)
ALTER TABLE [dbo].[AuditDetail] WITH CHECK ADD CONSTRAINT
[FK_AuditDetail_AuditHeader] FOREIGN KEY([AuditHeaderID]) REFERENCES
[dbo].[AuditHeader] ([AuditHeaderID])
An important note on efficiency
For the SQL purists amongst you, I'm sure you started rolling your eyes as soon as you saw the words "CLR" and "trigger" in the article.
I don't blame you. Writing pure SQL triggers is probably the fastest type of trigger you can create, but it does come at a significant price - you're severely limited
in the type of code you can write, the available debugging features are minimal (when compared to debugging .NET applications), the lack of advantages offered by object
orientation is serious, etc. So I chose to go the CLR route, but did run a few metrics on how long things take when the audit is maintained this way. The findings are not surprising.
My tests were run on an average desktop running Windows 7 on a dual core CPU. With the auditing turned off, inserting 20,000 records into the Customers table took
an average of 10 seconds. Once I turned the CLR trigger on, it ballooned to 10 minutes. But by removing the most expensive statement I found in the trigger
(see option #3 right below), the time goes down to a much more reasonable minute and 40 seconds. Now to be fair, I did not have a similar trigger written in SQL,
so I don't know how long it would have taken. The SQL trigger would still have to fetch the same info about the table name, primary key values, auto incrementing
values from the header audit table, etc. My gut feeling is that it would have been somewhere between the two numbers.
To bring the execution time down, there are a few options
- Multithreading - once inside the trigger, a separate thread would be launched to do all the auditing, in essence making the whole thing asynchronous.
The time needed would, in theory, go back down to something close to the original 10 seconds. Looking into this, though, I found there were several complications
regarding security that need to be taken into account, and this just makes the whole thing a bit too complex to manage. Remember, I'm looking for an elegant
solution; not one that takes 5 developers and 2 administrators to manage.
- Message queues - this seems to be the best alternative so far. Instead of processing all the auditing logic on the spot, the contents of the DELETED
and INSERTED tables, along with an extra couple pieces of info, are serialized to XML and written to a queue. I played around with this one, and the time
for the 20,000 records goes down to about 30 seconds. This is definitely a good option, but you then need to build a service that is constantly monitoring
the queue, extracting the serialized data from it, and processing it for insertion into the Audit tables. This is most probably the route I'll be taking.
- I found one particular statement to be the cause of a huge cost in execution time - the one responsible for retrieving the table name. Taking this one
out shaved whole minutes (about seven) off the overall time. I have not found a suitable replacement for this, and SQL Server does not seem to make this info
available to the trigger. You would assume that
SqlTriggerContext.EventData would have this info, but as per MSDN, it only contains data when running
Data Definition Language triggers (DDL, i.e., CREATE, ALTER, etc) and not Data Manipulation Language triggers (DML, i.e., INSERT,
UPDATE, etc). Why they would leave this out is beyond me. Maybe it's a work in progress? One way to get around this statement is by making multiple public triggers (one per table),
and hard-coding the table name in the method itself (see sample under "diving into the code").
The bottom line
The CLR trigger is definitely powerful and has a lot of promise. Execution time does suffer at high numbers of altered records though,
if you want your trigger to be truly dynamic. So I would think twice before implementing this in a system where a lot of data is routinely manipulated (or implement it,
but use table-specific triggers as described further down below). But if you're working on a system that at most sees dozens (or even hundreds) of records being changed
at a time, the extra lag is barely noticeable and so the auditing advantages certainly pay themselves off.
Setting up
One of the beauties of CLR triggers is that you can manage the compiling, deploying, and testing all from within Visual Studio.
Compiling is straightforward - just open the solution and compile as usual. To deploy, you'll need to first set up your database connection settings, which is done
by going to the project's properties and setting up the connection string in the Database tab.
Testing is also simple - under the "Test Scripts" folder of the project, you'll find Test.Sql. Add the SQL statement you want to test, set your breakpoints
in the code (or on the SQL statements), and hit F5. The project will be compiled, deployed to the server, and then the test SQL statement will be executed.
One important thing to note, however, is that the SqlTrigger attribute on the main AuditTrigger method expects three parameters when the code is being
debugged: Name (the trigger name as it will be created in the database), Event (the events for which the trigger will fire), and Target (the table to which
the trigger will be attached). The last parameter is essential if testing the trigger from Visual Studio, but should be left out if your trigger is to be generic
and attached to multiple tables.
If the trigger is generic, then once your tests are complete, just remove the Target parameter and recompile the project by clicking on "Build"\"Build Audit".
Do not try to deploy it, as you'll get an error because the target is missing. You'll then need to attach the trigger to the tables that need it from within Enterprise Manager
as follows (note that you should run them one at a time and not in one shot, as the CREATE TRIGGER needs to be the first statement run within a batch):
IF EXISTS (SELECT *
FROM sys.triggers
WHERE object_id = Object_id(N'[dbo].[AuditTrigger]'))
DROP TRIGGER [dbo].[AuditTrigger]
IF EXISTS (SELECT *
FROM sys.assemblies asms
WHERE asms.name = N'Audit'
AND is_user_defined = 1)
DROP ASSEMBLY [Audit]
CREATE ASSEMBLY audit FROM '[your solution's path]\Audit\bin\Debug\Audit.dll' WITH permission_set
= safe
CREATE TRIGGER [dbo].[AuditTrigger]
ON [dbo].[Customers]
AFTER INSERT, DELETE, UPDATE
AS
external name [Audit].[Triggers].[AuditTrigger]
EXEC sys.Sp_addextendedproperty
@name=N'SqlAssemblyFile',
@value=N'Trigger.cs',
@level0type=N'SCHEMA',
@level0name=N'dbo',
@level1type=N'TABLE',
@level1name=N'Customers',
@level2type=N'TRIGGER',
@level2name=N'AuditTrigger'
EXEC sys.Sp_addextendedproperty
@name=N'SqlAssemblyFileLine',
@value=N'21',
@level0type=N'SCHEMA',
@level0name=N'dbo',
@level1type=N'TABLE',
@level1name=N'Customers',
@level2type=N'TRIGGER',
@level2name=N'AuditTrigger'
What the audit looks like
The audit shows the history of all actions taken against the table, be they deletes, inserts, or updates. The data is stored in two tables: header and details.
AuditHeader structure
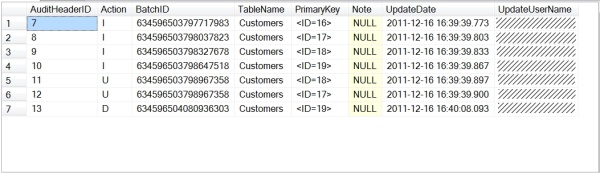
- AuditHeaderID - The table's primary key (just an auto incrementing field). Serves as a foreign key to AuditDetail.
- Action - "I", "D", or "U". Denotes if the action taken was an
INSERT, DELETE, or UPDATE. - BatchID - The value captured in the column is meaningless in itself, but serves to link to other audit records that were generated as part
of the same
INSERT/DELETE/UPDATE statement. For example, if performing an UPDATE with a WHERE clause
that affects 100 customer records, all 100 AuditHeader records will have the same BatchID value. A more useful value to capture would be the transaction ID, but that one has a few security
concerns that need to be dealt with (see "Future improvements" section further below). - TableName - The table on which the database actions were taken.
- PrimaryKey - Comma separated list of the primary key field names and values of the affected record.
- Note - If there was an issue generating the audit records for a particular case, this field will contain a message about it.
Currently, two cases exist where an explanation note will be generated (for both cases, refer to the "Logging an INSERT or UPDATE" section
further below for more details):
- If an
UPDATE statement resulted in a change to the primary key columns, the trigger is unable to generate AuditDetail records containing the changes. - If the table affected has no primary key defined, the trigger is unable to generate AuditDetail records containing the changes.
- UpdateDate - Date on which the change occurred.
- UpdateUserName - User name that made the change.
Sample screenshot:
AuditDetail
AuditDetail will contain details about the records and the specific changes they went through. Note that only columns that have had their values altered are logged.
- AuditHeaderID - The AuditHeader's primary key. Serves as a foreign key to the current table.
- AuditDetailID - The table's primary key (just an auto incrementing field).
- FieldName - Name of the affected field.
- OldValue - Value of the field before the change.
- NewValue - Value of the field after the change.
Sample screenshot (note that there are more entries for AuditHeaderID 13 that were not captured in the image):

Diving into the code
The trigger uses DataTables to store and manipulate both the altered and audit data, and uses DataAdapters to quickly fill them or flush them back to the database.
It also uses SqlCommandBuilder to automatically generate the INSERT statements for the Audit tables, based on the
SELECT statements in the DataAdapters.
Since the primary key on AuditHeader is an auto generating field, and AuditDetail needs this value as a foreign key, we need to retrieve the value generated
by the database so that it can be stored in AuditDetail. To do this, the RowUpdated event on AuditHeaderAdapter is trapped, the generated primary key is retrieved
and is then stored in the AuditHeader DataTable. This makes it available for the DataTable updates for AuditDetail.
SqlDataAdapter AuditHeaderAdapter = new SqlDataAdapter("SELECT * FROM AuditHeader WHERE 1=0", conn);
...
AuditHeaderAdapter.RowUpdated += delegate(object sender, SqlRowUpdatedEventArgs args)
{
int newRecordNumber = 0;
SqlCommand idCmd = new SqlCommand("SELECT @@IDENTITY", conn);
if (args.StatementType == StatementType.Insert)
{
newRecordNumber = int.Parse(idCmd.ExecuteScalar().ToString());
args.Row["AuditHeaderID"] = newRecordNumber;
}
};
Getting the name of the affected table, as mentioned earlier, is one of the most expensive items in the execution of the trigger, as is done with the following query:
SqlCommand cmd = new SqlCommand("SELECT object_name(resource_associated_entity_id)" +
" FROM sys.dm_tran_locks WHERE request_session_id = @@spid and resource_type = 'OBJECT'", conn);
affectedTableName = cmd.ExecuteScalar().ToString();
I have not found another way to do this, other than creating one public trigger method per table, and having each one of them call the same private method
and pass the table name in as a parameter:
[Microsoft.SqlServer.Server.SqlTrigger(Name = "AuditTrigger",
Event = "FOR INSERT, UPDATE, DELETE", Target = "Customers")]
public static void AuditTrigger()
{
UpdateAuditTables("Customers");
}
[Microsoft.SqlServer.Server.SqlTrigger(Name = "AuditTrigger",
Event = "FOR INSERT, UPDATE, DELETE", Target = "Customers")]
public static void AuditTrigger()
{
UpdateAuditTables("Clients");
}
private static void UpdateAuditTables(string tableName)
{
...
}
Getting the user name is a fairly straightforward item:
SqlCommand curUserCommand = new SqlCommand("SELECT system_user", conn);
affectingUserName = curUserCommand.ExecuteScalar().ToString();
Retrieving the list of fields that make up the primary key of the affected table is done with the following query. It basically stores the field names
in a DataTable and makes it available to the auditing code later on so that the record's key can be documented and we can find the old/new values:
SqlDataAdapter PKTableAdapter = new SqlDataAdapter(@"SELECT c.COLUMN_NAME
from INFORMATION_SCHEMA.TABLE_CONSTRAINTS pk ,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE c
where pk.TABLE_NAME = '" + affectedTableName + @"'
and CONSTRAINT_TYPE = 'PRIMARY KEY'
and c.TABLE_NAME = pk.TABLE_NAME
and c.CONSTRAINT_NAME = pk.CONSTRAINT_NAME", conn);
DataTable primaryKeyTable = new DataTable();
PKTableAdapter.Fill(primaryKeyTable);
Logging a DELETE
These statements are fairly straightforward, as all their data is found in the DELETED table. We simply loop through all the rows (since more than one could
be deleted in a single statement), and for each one, create a AuditHeader record and AuditDetail records (where the column values are not null).
Logging an INSERT or UPDATE
These two actions are similar in that both of them store the new set of data in the INSERTED table.
Additionally, the UPDATE command will store the old data in the DELETED table.
For INSERT cases, the job is simple and follows the exact same logic as with deleted records, except that the data is found in the INSERTED table.
For UPDATE cases though, it gets tricky. Each of the records in INSERTED will have a counterpart in the DELETED table holding the old values, and they need
to be matched up in order for the audit to show the old and new values of each record. The easiest way to do this is by adding a primary key to the two DataTables,
and then adding a ChildRelationship from the INSERTED to the DELETED table. Then, as you loop through the INSERTED rows, just get the child rows and you're done.
The only problem with this is, once again, the cost of execution. Following this method adds several more minutes to the above mentioned test because
of the behind-the-scenes work involved in creating primary key objects, table relationships, etc. The code to work with these relationships is available
in the project for curiosity's sake, but is commented out:
DataColumn[] insertedPrimaryKeyColumns = new DataColumn[primaryKeyTable.Rows.Count];
DataColumn[] deletedPrimaryKeyColumns = new DataColumn[primaryKeyTable.Rows.Count];
int colCtr = 0;
foreach (DataRow primaryKeyRow in primaryKeyTable.Rows)
{
insertedPrimaryKeyColumns[colCtr] = inserted.Columns[primaryKeyRow[0].ToString()];
deletedPrimaryKeyColumns[colCtr] = deleted.Columns[primaryKeyRow[0].ToString()];
}
inserted.PrimaryKey = insertedPrimaryKeyColumns;
deleted.PrimaryKey = deletedPrimaryKeyColumns;
inserted.ChildRelations.Add("FK_HeaderDetailRelation",
insertedPrimaryKeyColumns, deletedPrimaryKeyColumns);
DataRow[] childDeletedRows = insertedRow.GetChildRows("FK_HeaderDetailRelation");
if (childDeletedRows.Length == 0)
{
auditHeaderRow["Note"] = "Unable to log field level changes " +
"because the primary key of the record may have changed.";
}
else if (childDeletedRows.Length > 1)
{
auditHeaderRow["Note"] = "Unable to log field level changes " +
"because a distinct match between INSERTED and DELETED could not be made.";
}
else
{
deletedRow = childDeletedRows[0];
}
Instead, the matches are found in a slightly more complex (but faster) method. We create an index list that keeps track of all the record positions
in the deleted table. We then loop through the fields in the primary key table, and compare each deleted row in the index list to each inserted row,
removing from the index list any deleted row that does not match:
List<int> matchingDeletedRows = new List<int>();
for (int ctr = 0; ctr < deleted.Rows.Count; ctr++)
{
matchingDeletedRows.Add(ctr);
}
foreach (DataRow primaryKeyRow in primaryKeyTable.Rows)
{
for (int ctr = 0; ctr < matchingDeletedRows.Count; ctr++)
{
int deleteRowIndex = matchingDeletedRows[ctr];
string deletedPrimaryKeyValue =
deleted.Rows[deleteRowIndex][primaryKeyRow[0].ToString()].ToString();
string insertedPrimaryKeyValue =
insertedRow[primaryKeyRow[0].ToString()].ToString();
if (deletedPrimaryKeyValue != insertedPrimaryKeyValue)
{
matchingDeletedRows.RemoveAt(ctr);
ctr--;
}
}
}
When all the primary key fields have been compared, we should be left with one of three scenarios:
- If the index list is empty, no matching DELETED records were found. This is likely due to the
UPDATE statement having changed one of the primary key fields,
so we cannot find a match. Add a message to AuditHeader.Note and skip documenting the field changes. - If the index contains more than one value, somehow more than one match was found, so once again we cannot document field changes. I'm not sure what scenario
this could arise in, but you never know. We add a message to this effect to
AuditHeader.Note and move on. - One entry is left in
matchingDeletedRows, meaning that we have a match. Use this index to get the proper record from the DELETED table and document
the differences between it and the current INSERTED record.
A couple other notes ...
If no primary key info is available for the table, the comparison between INSERTED and DELETED cannot be made so a note to that effect is left
on the AuditHeader record and the AuditDetail part is skipped.
Also, if both INSERTED and DELETED have one record in them, we don't bother trying to match up the records and just assume they're related and document
them as such. I can't think of a scenario where they would not be related, but if anyone can, please let me know.
Future improvements
At the moment, there are two improvements I'd like to look into:
- Finding a faster and more efficient way to get the name of the affected table.
- Storing the transaction ID at the header level so all associated changes can be reviewed together. This has some security settings that need to be reviewed,
as by default non-admin users apparently don't have access to the system tables containing the transaction info.
Conclusion
As mentioned in the beginning, this approach has some very big advantages but also some drawbacks. If you're looking to implement an audit
on a small/medium database, where you don't usually affect large numbers of records in one shot, then this method will work just fine.
If, however, you do, then you can implement it but I would seriously suggest replacing the code that gets the affected table name with individual per-table
triggers that already have the table name hardcoded in them. It's not elegant, but until MS fixes the issue of SqlTriggerContext.EventData being null
for DML statements, I don't see another workaround.
If anyone has any suggestions on improving this code, by all means let me know. I would be most interested in finding other ways to get the affected table name if you can think of one.
Some good links and reference material

