Introduction
Suppose you need to test a piece of software, and the software expects a set of values that vary in a particular way, but you want to generate long test sequences and be able repeat them for debug. In that case you need something like a random number generator, that isn’t random, a random sequence generator.
The “rand” functions provide a value usually calculated off of the time clock, such that no rand result maps directly from the time, and the value is different every time and appears random. Really it is a sequence and it gets seeded and re-seeded in a hidden manner. For this reason, “rand” isn’t always useful for testing some things.
Background
This style of algorithm can be used to create easy repeatable tests for IPv4 addresses, digital filters, image tracking, etc. With it you can create a test bench and walk through a specific example calculation by calculation, if statement for if statement. After that you can then change the "seed" value to create a whole new test case and hunt for corner cases. For example, you might run 100k tests, and have your test framework spit out the seed values for tests that fail, and then run those tests with logging on in the debugger.
Using the Code
The code is relatively easy to use, just create a class instance and then ask the class for the next value.
Random r = new Random();
r.Seed = (long)numericUpDown1.Value;
double randomDouble = r.NextDouble;
r.NextGuass_Double(5, 1.5);
r.NextFlat_Int(100, 150);
Requirements
These are of course, informal requirements, but worth listing.
- Random walk (no obvious pattern) sequence
- Random distribution of values (flat histogram)
- Sequence repeats if seed is the same
- Fast enough run time
- Support variety of types simply (
byte, char, int, float, etc.) - Support computing a random value between a min and max (white aka flat noise)
- Support Gaussian like noise (measurement like noise)
Design
The key is to make a random generator and extend it for all interfaces without breaking it.
The following is a hash, a randomization of the value we extract bits from.
protected virtual ushort compute_NoSeedChange()
{
long[] v = {0x73ae2743a3eab13c, 0x53a75d3f2123bda1, 0x42a3bcba71a72843};
long rv = Seed;
for (int i = 0; i < v.Length; i++)
{
rv += v[i];
rv -= rv << 3;
rv ^= (v[i] >> 7);
rv ^= rv >> 11;
}
return (ushort)(rv & 0xFFFF);
}
Testing
The source code test package uses the .NET graphing data visualization class to provide a simple basic test framework.
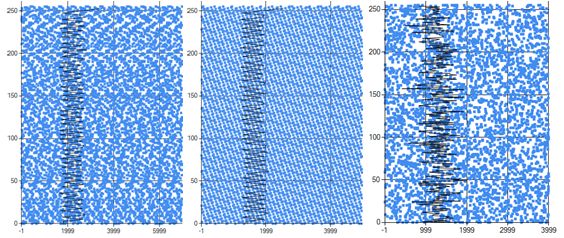
1. Random Walk (No Obvious Pattern) Sequence
If the sequence had a tendency to repeat, a scatter plot of the value would be mottled or have a pattern, or the histogram would have a pattern because certain values would get hit more often than others.
The first two images below are failures (during development), but the third (finished code) passes.

2. Random Distribution of Values (Flat Histogram)
Given enough values the histogram should look flat, and when repeated with a different seed also look flat but have a slightly different shape.
3. Sequence repeats if seed is the same.
5. Support variety of types simply (byte, char, int, float, etc.)
6. Support computing a random value between a min and max (white aka flat noise).
3, 5, 6 were tested by inspection.
4. Fast enough run time.
Bytes 100k 0.5 seconds 1 = 0.005 milliseconds
Double 10k 0.2 seconds 1 = 0.02 milliseconds
Guass 100k 3.2 seconds 1 = 0.032 milliseconds
This is reasonably fast, left to the reader to optimize if they want to.
7. Support Gaussian like noise (measurement like noise)
With enough samples (100,000) the histogram (black line) should be flat. For a random guassian, it should look like a bell curve that drops off quickly within +/- 3 standard deviations. The following is 5 with +/- 1.5 = 1 standard deviation (1 sigma = 1.5):
That means between 3.5 and 6.5 roughly 63% of the values should be present, and roughly full containment in 3 sigma (99%), and the center peak is at 5. The red line is the ideal, and the black line is what the code produces. A cumulative probability distribution re-mapping of the random double to the correct distribution could have been done but instead the code averages four random values which in turn create a Gaussian like distribution.
To Do
I’ve done this before in the past in C++ but can’t remember how I did it, it only took a few days to do. These things are left to the reader for fun.
- Make it faster.
- Add CDF style distributions for shaped distributions (Poisson, etc.).

