Contents
Introduction
Previous articles
These articles will guide you through the series so far:
What's New
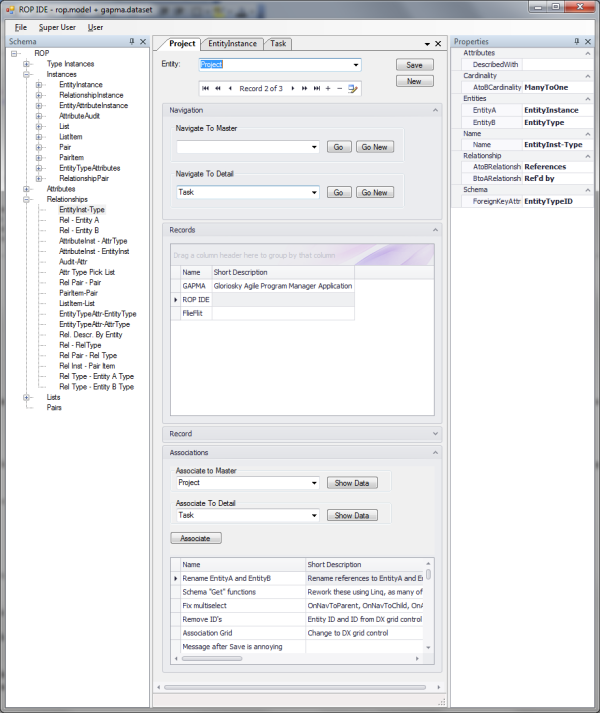
Welcome to the Relationship Oriented Programming IDE (ROP IDE), as illustrated above. This takes the previous work (I would recommend at
least perusing the previous articles if you are encountering this article for the first time) which
was a loose collection of screens, and puts them together into a more cohesive development and deployment framework. There are several features:
- Dockable windows (courtesy of DockPanel Suite)
- Meta-model tree and properties windows for creating the Meta-model
- Super-user meta-model instance editor (as described previously)
- A new user entity instance editor, supporting both DevExpress and .NET components (though the DevExpress version looks nicer, it has its own set of issues,
especially with the collapsible panels)
What is missing at the moment is the discrete control generation that I described previously - I've been primarily focusing on improving the usability
of the ROP in the GAPMA application itself. Of course there are a lot of other features missing as well, hopefully most of which, that I can think of,
I've documented as user stories or tasks using the ROP IDE itself.
Requirements:
For this article (see below regarding .NET and DevExpress based UI's), you will need to install:
As I mention below, the next article will support the System.Windows.Forms controls as well.
If you have problems running the IDE because of missing components, please contact me directly.
What are we going to accomplish in this article?
Besides the introduction of an actual IDE, this article will cover the following:
- A review and formalization of ROP
- Formal definition of Agile terms as I define them
- Formal description of the Relationship entity
- UI support for selecting a username
- Application-specific menus, defined in the dataset
- Application-specific variables
- Default values when new rows are created
- Automatic joining of 1:1 associations
Three Aspects, One Application
This article series really involves three aspects:
- The ROP IDE as a design tool and application data editor
- Meta-modeling (for which an Agile Program Management application is the test case)
- Relationship oriented programming as a concept to explore with the first two aspects
Supporting .NET and DevExpress based UI's
My main reason for moving to DevExpress controls (though there are a variety of options out there, this is the one I've paid for a while back) is because
there are things I want to be able to do in terms of presentation that just aren't available in the control suite that comes out of the box with the .NET
framework. In particular, I wanted to have control over the different sections of the UI so that I could hide certain sections, thus maximizing the
space available for other sections. For example, compare the above screenshot with this one, which takes advantage of the DockPanel Suite and the
collapsible LayoutControlItem objects that DevExpress provides:

I found it essential, as the user of GAPMA, to be able to control the interface to focus on the task at hand, whether it was straight data entry,
drilling into associations, or creating new associations. Similarly, when I implement the discrete control feature (which will go in the "Record" group),
the user will be able to easily toggle between viewing the data in a grid, in discrete controls, or both.
In .NET, the primary UI issue feature (collapsible panels) that DevExpress provides has been mirrored using a home-grown expandable panel and group box,
for those that don't want to use DevExpress.
Important: This feature will be fully implemented in the next article. It's a bit too much, after taking a month to write this
article, to finish the System.Windows.Forms control support at this point. The whole architecture is in place, I just need to write the resizing panel and
use the collapsible groupbox here which I'm sort of waiting
for the author to write the horizontal collapse.
Declarative UIs
When I posed the question in the Lounge regarding the use of a commercial third party suite, the answers were mixed - some were fine with the idea, others
not. For that reason, I decided to support both DevExpress and .NET controls. Doing so was relatively easy (the nuances of the grid controls
in each framework resulted in the greatest complexity of all the controls), and configuring the application for one or the other is straight forward.
Because the UI's are generated from XML, I have two separate folder paths, and picking one instantiates the controls in the desired framework:
protected static string UI = "dotnet\\";
or:
protected static string UI = "devexpress\\";
and in the XML, the desired sub-classed control library is specified with either:
xmlns:ui="UI.DotNet, UI.DotNet"
or
xmlns:ui="UI.DX, UI.DX"
I had originally planned on using exactly the same XML for both frameworks, but there are hierarchy issues in the nuances of the panels that I chose not to
abstract out, so for the moment, there are two separate XML files for each UI.
Review Of ROP concepts and
terminology
If you're stumbling upon this article first, it would be a good time to review ROP concepts.
Terminology
I get myself confused when dealing with essentially three concepts:
- The ROP schema itself
- The application's schema
- The application's entity instances
I've written most of this article at this point and am just getting some clarity on these three critical concepts. So here's a definition of the
three terms which are useful when thinking about ROP. Here's a confusing drawing representing these three concepts:
Schema
In the context of the ROP, I want to use this term to exclusively represent the schema used to define the types (entities and attributes) that are
used to build the application model. I may not be successful in this yet. The schema is edited in the "Schema" tree control.
Model
The "Model" defines the application schema. These are the instances of schema types. Since the schema (as defined above) is a
general purpose schema for any kind of application, we define the application's types as instances in the schema. Got it?
The model is edited in the "Super User" menu.
Application
The "application" is an editor in which model type instances are created, edited, and associated to other application entity instances. The
application is edited in the "User" menu. I should rename that menu item to "Application", but the original concept was that the "super-user" would edit
the model, and the "user" would edit the application. Hopefully that makes sense.
Schema Editor
The ROP IDE provides a simple schema editor. The schema editor provides containers for 5 concepts:
- Attributes (Fields)
- Entities (Tables)
- Relationships (The foreign key "glue" between entities
- Lists - collections of "name" items
- Pairs - collections of "name-name" items
The first three - attributes, entities, and relationships - are means of describing a schema which is implemented in physical tables. Although the
schema is serialized in XML, when a DataSet is created, the entities, attributes and relationships are implemented as physical tables. From this
perspective, you could use the ROP schema editor to work with a typical database implementation, though a lot of features found in a database, such as multiple
primary keys, multi-field foreign keys, attributes on fields like nullable, are missing (intentionally.)
ROP and Application Schemas
The ROP schema (in the file rop.model) is a specific schema used by the ROP IDE for constructing the application schema. In the previous article, and
in this one, I use a schema specifically designed to implement the Gloiroksy Agile Project Management Application (GAPMA). It defined in XML and
physically instantiated (at least for now) as a DataSet with a collection of DataTable objects and relationships. The definition is XML and is
persisted in files ending with ".model". The physical instantiation is persisted as a serialized DataSet in files ending with ".dataset".
With the ROP IDE, you can load the model and the dataset separately or both at the same time, and you can save the model and dataset separately or both at the same time as well.
ROP Model
The ROP model is a meta-schema. It is a schema in which the "virtual" application schema
can be defined, and as such, the "data" associated with the ROP schema is itself a schema. You can see the difference here:
On the left, in the tree view, we have collections of "instances" -- in the DataSet, these are concrete implementations of the "type" defined in the ROP
schema, hence the name "Instance." However, the ROP schema defines types that are themselves used to describe the application schema, the
entities of which are shown in the grid on the right for the GAPMA application. Another way to visualize this is:
Model (Application Schema) - The Super User Editor
The application schema consists of all the entities, their types, and their relationships used for a specific application, in this case the GAPMA. The
application schema is manipulated in the "Super User" model editor. This includes, similar to the schema editor tree, the ability to define entities,
attributes, and relationships between entities.
However, unlike the ROP schema in which there are primary key and foreign key fields, you do not define these attributes for application entities - the
primary keys are managed internally, and the foreign key associations are not hard-wired but rather allowable relationships are defined as records in the ROP
schema's RelationshipType entity. So, for example, in the ROP schema, the EntityTypeAttributes entity, which defines the attributes that an entity:
has the following fields:
- ID: a primary key
- EntityTypeID: a foreign key to the entity type
- AttributeTypeID: a foreign key to the attribute type
- Ordinality: the order in which the attributes are defined
Contrast this to the application schema for a task:
which defines only two attributes, "Name" and "Short Description".
ROP Relationships
In the ROP schema's "Relationships" section, we describe the participating tables, their
cardinality, and the foreign key of a relationship between a table-field child and a table (the primary key is implied) of the physical model. For example:
the above describes the relationship between the EntityInstance and EntityType entities (or if you wish, tables, since these become concrete Table objects).
Application Relationships
In the application schema, a relationship is established between any two entities using the RelationshipType ROP schema table:
This defines the allowable types of relationships between application entities.
Internally, when two entity instances are associated, an entry is made in the RelationshipInstance table (which can be inspected in the
RelationshipInstance entity in the ROP model editor) associating the primary keys (internally implemented) of the two
application entity instances. The RelationshipInstance table implements a composite association table.
Application - The User Data Editor
Just as we have a "Super User" model editor for the physical model, we need a "User" data editor for the application schema. Here we can take advantage
of the auto-generation of the "virtual" tables, their columns and supporting discrete controls. We can also provide UI elements that allow the user to
navigate the associations between entity instances, which, because the UI "knows" the model, can be done generically for all associations.
A typical grid-based view of an application entity looks like this:
This is dynamically generated from the attributes defining the application entity, in this case the Project entity.
Why, Why, Why?
Some answers:
Why Meta-Modeling?
Meta-modeling provides a way to define entities, attributes, and their relationships without touching a database schema or
writing application-specific code. It also solves a problem I frequently encounter, in that the relationship "field" is not rich enough to describe the
kinds of relationships between entities that user needs, which basically forces the requirement for an association table. This is
particularly the case in arenas of rich data sets, such as law enforcement.
Why Meta-Model Relationships?
In a classical implementation, if you create a new association between two entities, you now have to go back and touch the UI's of those entities, adding
functionality to allow the user to navigate the associations. With the ROP IDE, the user is presented with all current associations to which he/she can navigate and all allowable association
types to which he/she can create an association. It gives the power back to the user, rather than forcing the user to work within the constraints of the
application at the time it was implemented. As we all have probably experienced, applications slowly becomes obsolete, like a used car.
Why Use a Composite Association Table?
In a typical implementation, the "User Story" entity illustrated above might be concretely defined as:
Notice this table has 5 foreign key fields. Problems:
- Will we ever need other associations, requiring us to update the database model?
- How easy is it to write a query that asks "where is this user story referenced?"
- In the above case, the user story can be associated with only one foreign key entity of each type. What if you wanted to put the user
story into several groups, or perhaps the tasks for the user story are spread across several sprints, and thus the user story can be associated with multiple sprints?
- What if we didn't define all the associations up front, and new associations were discovered as the application was developed?
- What about useful information about the association itself, such as who created it, when, it's lifetime?
Items 3 and 5 above could be addressed with an association table, for example (I removed the other FK's for brevity):
But here we have another problem: for every many-to-many association, we need a separate association table. In my opinion this is quite ridiculous and
would only be done (perhaps) for performance reasons. Conversely, if we had a composite association table (a CAT), we could create the association between any
two entities. In the process we lose foreign key constraint benefits and the question of performance comes up. I believe both of these issues can
be handled well by 1) not relying on the database to perform cascading updates/deletes, and 2) the proper indexing of the CAT.
Still, the relationship implicit in the association table loses some information, which I will describe in detail later on - but what we want to
preserve are the answer to the following questions:
- Does the relationship type always exist, even if the relationship itself might not exist due to missing knowledge?
- Does the relationship sometimes exist, dependent on how the user want to create the association?
- Does the relationship describe a static association, never changing in time unless erroneously created?
- Does the relationship describe a dynamic association, existing potentially for only a particular period of time?
These are vital pieces of information that should be explicitly captured in a first class relationship citizen.
Why Meta-Model Entities and Attributes?
One of the things I frequently encounter in large databases are entities and fields that are not documented. In the above schema diagram, there are
attributes such as "ID", "Name", "Descr", and so forth. I prefer a more formalized approach to entities and attributes, one in which the entities, their
attributes, and their relationships can be documented. And if the documentation can be auto-generated from the schema, then you have a powerful
tool. Who actually uses the documentation facilities built into databases?
Are We Querying Data Or Relationships?
With the ROP, relationships are data. This is what makes a relationship a first class citizen. In a traditional database
architecture, relationships are foreign keys, which is not data, unless expressed in an association table, which most of the time we don't do because a
foreign key establishes a many-to-one association, which for the majority of associations is sufficient. Thus, we lose the "data" aspect of the relationship.
It is useful exercise to train ourselves to thinking about the differences between querying data vs. relationships. Obviously, a lot of what we do
requires using relationships to obtain data - the point I'm trying to make here is to tease apart the relationship from the data and determine if the fact that
a relationship exists is of value in-and-of itself.
Querying Data
This would look like "What is the name of this person?" or "What is the state of these tasks?" The salient point here is that one is obtaining
information stored in the attributes (fields) of the entity (table).
Querying Relationships
This would look something like: "What are all the things associated with this user story?" or "Does this specification have any associated documentation?" or
"is there a tool that we use for this task?" Here, the salient point is not obtaining information stored in the attributes, but determining the
existence of something in relation to something else. This becomes really important when mining vast amounts of data. For example, in a medical
library, we might want to know all the diseases in which a particular symptom might be an indicator of.
Formalizing Agile Project Management
This is going to be a bit of a rehash of the previous article's description of Agile, but I think it is well worth formalizing the concepts here so that we
have a dictionary of terms to work with in the future, as well as defining more concisely what Agile development really encompasses, which seem to be lacking in
the Agile community. The relationships between concepts is fundamental, and since this series is on relationship oriented programming, it makes sense to
emphasize relationships rather than discrete terms. Mind you, the relationships are not required--these are relationships that you can create
dynamically rather than being forced into them.
For the purposes of the formalization, the section headers are divided into individual entities, with sub-sections describing the child entity to parent
entity relationship, as currently programmed into the GAMPA meta-model. One of the things that becomes explicit when we look at relationships is that
the meaning of the entities involved in the relationship can vary depending on the relationship context. For example, a Task associated with a User Story
has a different meaning than a Task associated with a Bug. And meaning is information, possibly useful information, so we want to keep that in mind as a useful attribute of ROP.
What you will notice here are a lot of entities that you would find in classical software development that Agile methodologies have ignored. I
believe one of the criticisms of Agile is the result of these missing entities, which I think are crucial in a successful project development, especially large scale
developments. The advantage of the Agile approach though is that not everything has to be defined up front -- we can figure out the details as we go,
which more accurately mirrors real life efforts.
A few things:
- The entities and relationships that I've created here are concepts that I found useful. You may want to add your own entities, relationships,
and attributes to meet your needs;
- The subsections describe the entity-parent relationships that I've defined in the meta-model;
- The graphs for each entity show all the parent-child relationships for that entity based on the complete definition of relationships;
- As mentioned later on again, all entity types have an automatic relationship with the Note and Document types.
Here we go!
Project
The Project entity is the container for all other entities in the Agile model that are involved in the specification, development, testing, and release of the
application. Depending on your needs, you may have additional higher level entities, such as Department (different departments in the company will have
different projects under development) and Company (if you're a consulting agency, you might be working on several different projects for different
companies). These are but two examples of higher level entities.
User Story
A User Story is a descriptive narrative of how the application should work, how data needs to be moved about, how data is to be reported, and so forth.
These can range from high-level narratives to (for example) detailed descriptions of workflow, user interaction, UI requirements, rules, etc.
Associations:
| User Story - Project | User stories are associated with a project. |
| User Story - User Story | User stories can be recursive, providing further
refinement. |
| User Story - Iteration | User stories often belong to an iteration. See
below for the description of an Iteration. |
| User Story - Sprint | User stories are frequently associated with a Sprint
(see description of a Sprint below.) Ideally, user stories should
always end up associated with a Sprint. |
| User Story - Group | User stories can be grouped. |
Group
A Group is an arbitrary concept for organizing user stories. Organization however is useful. For example, we might want to look at all
the user stories related to a particular screen, or a particular set of rules. The point of a Group is to allow you to organize many of the entities under a
single umbrella--for example, what are all the tasks related to the development of the transport layer between the client and server.
Emphasizing the relationships between entities, there are no rules here - entities can belong to any number of groups. It's simply a mechanism that
allows you to organize information. I discovered the need for this because, in the ROP IDE, I would have a lot of tasks but would get lost in the
noise when what I really wanted was the ability to group tasks so I could focus on a particular set of behaviors, screens, etc.
Associations:
| User Story - Group | User stories can be grouped. |
| Requirement - Group | Requirements can be grouped. See below for the description of a Requirement. |
| Specification - Group | Specifications can be grouped. See below for the description of a Specification. |
| Task - Group | Tasks can be groups. See below for the description of a Task. |
| Test - Group | Tests can belong to a group, for example, all the tests associated with offline transaction management. See below for the description of a Test. |
| Bug - Group | Bugs can be grouped. See below for the description of a Bug. |
Requirement
A Requirement defines some fine-grained details about the User Story. This can involve performance issues (response time or number of concurrent users
or number of transactions per second or redundancy), data management issues (handling dirty data, automatic client synchronization, offline usage, etc),
security, rules, and so forth. Requirement entities should take the User Story narrative and reduce it down to single line items that reveal "hidden"
assumptions and implications in the User Story. Sometimes a User Story can sound like a Requirement if the User Story is of sufficient detail. An
example would be "the date field should default to the current date." If that happens, it becomes a bit arbitrary as to whether a detailed user story
should instead be described in a Requirement or duplicated in a Requirement.
Associations:
| Requirement - Project | A Requirement can be associated with a Project. This should be considered to be a placeholder when a User Story doesn't exist yet. |
| Requirement - User Story | Requirements are derived from a User Story. |
| Requirement - Requirement | I don't encounter this too often, but the idea is that requirements can be associated with other requirements in either a sibling association (one
requirement referencing another) or in a master/detail relationship. |
Specification
A Specification details how the User Story, Task, or Requirement is to be implemented. A Specification describes the actual implementation approach
in terms of technologies, algorithms, etc. For example, a requirement to compress video might have the Specification of a certain algorithm.
The same Specification might be associated to the Task of implementing that algorithm, or, if using a third party library, interfacing to that library.
Specifications though can also be documents, like schemas, communication protocols, web services, etc.
It's important to understand the difference between a Requirement and a Specification. A Requirement describes "what", and a Specification
describes "how". In GAPMA, for example, I have the requirement that screens need to support both DevExpress and .NET-based controls.
The Specification for this says that the screens will be implemented in XML and be instantiated with MyXaml. The latter is not a requirement - it merely
specifies how the requirement will be met.
The best practice here is to ask yourself to questions:
- What are the concrete requirements that come out of the User Story (this is a Requirement)
- How will the requirement be implemented (this is a Specification)
Associations:
| Specification - Project | A Specification can be associated with a Project. This isn't recommended, but can be used as placeholder for further refinement in what
entity the Specification should be associated with at a later date. |
| Specification - User Story | A Specification can be associated with a User Story. For example, the user may specify what database technology should be used, such as Oracle. |
| Specification - Requirement | A Specification is most usually associated with a Requirement. Given a Requirement, what technologies, tools, etc. should be used to meet the requirement? |
| Specification - Specification | Like the Requirement, a Specification can reference another Specification or be a detail to a master Specification. |
Task
A task defines the work that needs to be done.
Associations:
| Task - Project | A Task can be assigned to a Project. This is the most general association which I found useful when I discovered something that needed to be
done but there was no User Story, Bug, or Requirement entity to associate it with. A Task might also be descriptive, such as "Checking out the code from the
repository?" or "Building the project" or "Running the unit tests." Yes, these are also candidates for a separate Document, but we can be flexible! |
| Task - User Story | A Task can be derived from a User Story. Given a narrative, what is the
work that needs to be done? This doesn't necessarily mean programming
work. Tasks can be all sorts of things: get some screenshots from Dave,
get more details about the User Story, write some documentation, research prior
art, consider patenting this approach. |
| Task -Requirement | A Task can be associated to a Requirement. Given the Requirement, what
are the tasks necessary to implement the requirement? Usually, tasks will
be associated with a Requirement rather than a User Story, but since these
relationships are all arbitrary (often determined by the scale of the project)
you may feel that associating tasks directly to user stories meets your needs. |
| Task - Task (subtask) | A Task can have sub-tasks, which further refine the description of the work
to be done. |
| Task - Task (dependency) | What are the dependencies? These typically involve the completion of one task in order to proceed with another task. Dependencies can be more
abstract too--a dependency to have one department provide the schema for a database (a task) before a task depending on that Specification can be completed.
Dependencies are necessary in order to sequence tasks. We typically perform tasks in a particular order, which implies a dependency between tasks.
Instead of providing a "sequence" attribute in the Task entity, we can provide more meaning by actually describing the dependencies. |
| Task - Iteration | Tasks can belong to an iteration. See below for the description of an Iteration. |
| Task - Sprint | A Task is associated with a Sprint. Ideally, tasks should always be associated with a Sprint, either directly or indirectly through a Task's
association to a User Story. |
Test
How do we test the components of the project?
Associations:
| Test - Project | Probably not a good idea, because you're not testing against something specific, but perhaps a useful placeholder when in a meeting and someone asks
"hey, have we actually tested the data transfer over a 14400 baud modem?" |
| Test - User Story | We may want to write a test for a user story. This is where the
Acceptance Test" concept applies the most, as an Acceptance Test will describe a
series of steps to take that demonstrate meeting the requirements in the user
story. |
| Test - Requirement (test against a requirement) | A Test can be written to determine that a Requirement is met. When we
fire up a screen, is the date field populated with today's date? Does a
country pick list auto-select the user's country based on some OS registration
information? |
| Test - Requirement (test has a requirement) | What are the setup requirements in order to perform the test? Here's a
different meaning to the Requirement entity based on the relationship usage (I
talk about this later in the article.) |
| Test - Task | Tests associated with tasks can be both acceptance tests or unit tests, or
both, or something else. It pretty much depends on the task. |
| Test - Bug | Tests associated with a bug should typically describe how the bug fix was
tested. |
| Test - Test (master/detail) | Tests can be recursive, in the sense that "Test that plane flies" will
probably involve a lot of sub-tests before the pilot takes the aircraft down the
runway at high speeds. |
| Test - Test (dependency) | It's often useful to describe dependencies between tests. For example,
testing that a transaction can be posted is dependent on whether the test
succeeds for first connecting to the server. I don't like to see a hundred
failed unit tests simply because a test failed on which all the other tests
depend upon. That creates an unnecessary amount of panic. |
| Test - Task (dependency) | Here's an interesting concept--do we have a test that is dependent upon the
completion of task? Meaning, if the task isn't done, well, then
obviously there's nothing to test yet. Just a thought. |
Bug
Bugs can be a hard failure of the application, a missing feature, an incorrectly working feature, and so forth. As I mentioned in a previous
article, one person's bug might be another person's "working as designed."
Associations:
| Bug - Project | In testing, bugs most often come up that are completely decoupled from any
particular user story or task. I found this to often be the case when
using the ROP IDE -- "hey, look at that weird behavior!" So, at a minimum,
bugs are attached to the project itself. |
| Bug - User Story | In testing, the user may report a bug with a particular user story, which we
want to capture. The tester will most likely not report a bug for a task,
as internal tasks tend to be hidden. But, if he/she is testing a
particular implementation based on a user story and something unexpected
happens, this is where the user will associate the bug (and will want to retest
it later). |
| Bug - Task | Bugs can be associated with a task, usually a completed task. |
| Bug - Test | Tests can be buggy too! |
| Bug - Group | Bugs can be grouped together. For example, there may be a set of bugs
all related to a particular UI element. |
Resolution
Years later, you might want to know how a task was actually implemented (especially if there are no requirements or specifications!) Predominantly
though, the Resolution describes how a task associated to a bug was corrected (or if it was corrected, maybe it was deferred to another iteration/release.)
Associations:
| Resolution - Task | Tasks are of course not all "fix this." It might be "implement this
feature", for which it may be useful to document how the implementation was
resolved. |
| Resolution - Bug | In this case, the resolution documents how the bug was fixed (or if it didn't
need to be fixed, maybe the program is designed to behave that way.) |
Iteration
An iteration is comprised primarily of user stories. It answers the question, what collection of User Story items do we want to implement in the
next "release", where the concept of release can be internal or external (delivered to the user.) For planning purposes, an iteration may simply be
a placeholder. An iteration is essentially some arbitrary scheduled (or not) milestone. It can represent a delivery on which payment is dependent
upon, or it can represent the completion of some functionality. An Iteration should not be confused with a Group even though an Iteration is a
grouping of sorts of user stories and/or tasks. A Group is simply some sort of collection, whereas an Iteration includes the concept of completion.
Associations:
| Iteration - Project | Iterations belong to a project. |
Sprint
A sprint describes user stories and/or tasks that are to be accomplished in a small period of time, typically two weeks. A Sprint embodies the concept of
completion. As sprints are completed, the "velocity" of the project can be measured by correlating the tasks in a sprint with the number of tasks, actual
time taken to complete a task vs. estimated time, and so forth.
Associations:
| Sprint - Project | Sprints belong to a project. |
| Sprint - Group | Sprints might be grouped in some arbitrary fashion. This should be different from an Iteration. For example, you might have several sprints
all associated to an implementation, such as a communication layer. |
Progress
What Does Completed Mean?
One of the problems with a "completed" flag is that, while it's clear what it means when it's checked, it isn't clear what it means when it's not checked.
For example, an unchecked "completed" box may mean that work on the task hasn't even started, or that work as started but it's not finished. Or that it's
finished but nobody has marked it as completed yet (maybe it's being tested, and while the task itself is done, other requirements in the workflow are not.)
What we want is clarity in what the state of an object is actually in. This is particularly true for tasks--from the perspective
of Kanban, we want to be able to see which tasks are unassigned, which ones are assigned (work in
progress), and which ones are completed. I'm going to modify this concept a bit:
- not ready
- unassigned
- assigned but work not started
- assigned and work in progress
- work completed
As you can see, the "Completed" concept now have five states! Therefore, to improve clarity, we replace the concept of "completeness" with a
more precise concept: Progress.
Why a Separate Entity?
With the Progress entity (as well as the Review and Approval entities described below) one might say, why aren't these just flags in desired entities?
This is a reasonable question, and the answer is that the Progress entity is in a 1:1 relationship with the other entities, so from the perspective of the user,
the relationship is always created and the fields (in this case, the progress state) is always presented as a field in the entity to which Progress is
associated. It is also possible that you may want the Progress entity to have other fields, besides the progress state. The name of the person
assigned to the work might be an attribute, but as we will see, this is actually implemented with an association to a Name entity.
Associations (all of the entities on the right can have a Progress entity associated to them):
| Progress - Project |
| Progress - User Story |
| Progress - Task |
| Progress - Sprint |
| Progress - Iteration |
| Progress - Document |
| Progress - Review |
| Progress - Approval |
Note how Progress is related to the Review and Approval entities, which are described below. We obviously want to track where something is in the
review and approval process as well!
Review
Sometimes I really loathe working in teams because the quality of the code varies wildly. A formal review process is a good thing, and in a
high-paced (meaning chaotic) Agile environment, stepping back and reviewing the work that has been done is a Good Thing. A review has accepted and
rejected flags along with a description that the reviewer can add, typically for why the entity was rejected. For this reason, Bug entities also have a
Review association. A Review entity is always in a 1:1 relationship with other entities.
The Review entity can have three states:
- N/A (for an incomplete approval)
- Approved
- Rejected
Associations (all of the entities on the right can have a Progress entity associated to them):
| Review - Project |
| Review - User Story |
| Review - Task |
| Review - Requirement |
| Review - Specification |
| Review - Sprint |
| Review - Iteration |
| Review - Document |
Approval
Whoever reviews and accepts the User Story, Bug, or Task may not be the same person that has final approval (heaven help you if review and approval is done
by committee). Approval might be owned by the customer, for example. Approval is always in a 1:1 relationship with its associated entities.
As with the Review entity, the Approval entity can have the same states:
- N/A (for an incomplete approval)
- Approved
- Rejected
Obviously, the entities that have an association with Review should also have an association with Approval:
Associations:
| Approval - Project |
| Approval - User Story |
| Approval - Task |
| Approval - Requirement |
| Approval - Specification |
| Approval - Sprint |
| Approval - Iteration |
| Approval - Document |
Note
A Note entity is an internal piece of text (contrast with Document below). A Note can be associated with all entities, in a 1:many relationship (entity -
Note) - we can have a several of notes for each entity instance - even with itself. Who knows, you might want to be able to make annotations (notes) in a hierarchical manner.
Associations: All entities.
Document
A Document entity references an external document: text, images, videos, audio, web pages, databases, etc. A Document might be a screenshot or
movie of a bug, or an existing implementation in an existing or competing product, or some references to existing patents, an audio recording of a
meeting, an example of an external database to which we need to interface, a third party specification or schema, etc. Just ideas. Like a Note, a
Document entity can be associated with all entities, and exists in a 1:many relationship (entity - Document).
Associations: All entities.
Person
A Person can describe many important associations. For a User Story, who "owns" the story - as in, who is the Person who originated the story that we
might need to go back to if we have questions? Who is the Person assigned to the User Story to create the tasks? From the perspective of workflow
(see below), who is the Person that will Review the User Story, which may be different from the person who has final Approval of the User Story.
Essentially, a Person can be in associated to all other entities in some type of relationship, whether it is the assignee of a Task, the person overseeing
a Sprint, the author of a Document, and so forth. About the only entity that a use case cannot be created for is the Progress entity, because both
Person and Progress would be associated with the same parent entity.
A Person also doesn't have to describe a person - it could be a group of people. For example, describe a project in terms of the people involved:
you have the customer and various people at the customer site that are responsible for different aspects (User Story instances) of the project.
Who are all the junior programmers on the project? Who are all the senior programmers? Who are the UI designers? Who are the testers?
You can see that the Group entity is useful in relation with the Person entity.
You might think it would be useful to assign something, say a Task, to a group of people, like a committee. For the purposes of the GAPMA, my
concept is that ultimately a single person is the one that does the work. This may not be true at the review/approval level. It may not be true if
you want everyone to get together and sing "Alleluia" when the project is complete. Because the ROP is flexible, you can of course create your own
relationships and new entities as you see fit!
Types:
I would suggest creating relationship types for the various roles people take on in a project. Some suggestions:
- Owner
- Designer
- Lead
- Manager
- Reviewer
- Developer
- Tester
Associations (the descriptions are intended to be examples only):
| Person - Project | Associates people to projects. Who are all the people involved in a project? |
| Person - User Story | Who are all the stakeholders, reviewers, etc., of a User
Story |
| Person - Task | Who is the task assigned to? |
| Person - Bug | Who reported the bug? |
| Person - Resolution | Who resolved the issue? |
| Person - Iteration | Who own the oversight of the iteration? |
| Person - Sprint | Who is the lead on the Sprint? |
| Person - Group | What are the different groups of personnel? |
| Person - Requirement | Who authors the requirement? Who is responsible
for maintaining it? |
| Person - Specification | Who authors the spec? |
| Person - Test | Is there someone specifically that has the gear to run
the test? |
| Person - Review | Who is the reviewer? |
| Person - Approval | Who is the approver? |
| Person - Note | Who authored the note? |
| Person - Document | Who authored the document? |
| Person - Tool | Who wrote the tool? Who maintains it? |
Tool
In my previous article, I wrote that it is often useful to describe the tools used for a particular Task or Test. Thus, we have a Tool entity.
Yes, this could be captured in a note or document, but formalizing the entity gets people to think about it.
Associations:
| Tool - Project | Describes the tools used in creating and maintaining the project. |
| Tool - User Story | Describes a tool that may be necessary to demonstrate a User Story.
|
| Tool - Task | A Task might require a particular tool to accomplish. |
| Tool - Test | A test might require a specific tool (in addition to the
unit test tool) |
| Tool - Document | I like tools that generate useful documentation, whether it's a diagram or text. For example, I wish I had a tool that
generated the text for all of these entities and relationships. |
| Tool - Group | You may want to group tools: development tools, testing tools, documentation tools, etc. |
Term
In real use, I've discovered that user stories are full of terminology that is specific to the domain in which the user works. To add more complexity,
I often discover that the same term means different things by different people, departments, domains, etc. I find it very useful to have a glossary of
terms and their meanings associated to with a project.
Associations:
| Term - Project | Describes the terminology used in a project. |
| Term - User Story | One might create this association for convenience, to be
able to immediately reference a term used in a particular user story. |
| Term - Requirement | Requirements often use terminology we might want to
create a direct association with. |
| Term - Specification | Specifications often use terminology we might want to
create a direct association with. |
| Term - Tool | Same with tools. |
| Term - Group | Grouping terms is often useful. |
Relationship Oriented Programming Practices
Another required formalization is to define best practices in working with an ROP architecture. Following are a few best practices that I've come up with so far.
Overloaded Attribute Meaning and Duplicate Attributes
When we assign an attribute to an entity, consider whether the attribute describes logically a concept that physically could take on specific contextual
meaning if specified in a separate entity. Also consider that when an attribute is duplicated across several entities, it might be better to promote
it as an entity. For example, if Task has a Completed attribute, and no other entity has this attribute, then the user might be forced to overload the
meaning of this attribute. An example of this is, the user might choose to use this flag to indicate that the whole workflow of Task -> Resolution -> Test ->
Review -> Approve is "completed", simply because the designer of the schema didn't provide the ability to specify "completed" in other entities. How often
have we mentally assigned a new meaning to a field because the intended concept didn't fit our actual requirements? So, instead, the practice is:
- providing meaning in the context of the relationship with other entities
Ideally, the logical meaning of an entity should be concise but abstract whereas the physical
meaning, when in relationship with another entity, should be equally concise but concrete within the context of the relationship.
Entity Attributes Should Be Fundamental Types
The attribute of an entity should be considered in terms of the attribute to entity relationship, which is implicit in the fact that entities have attributes.
For example, the relationship between Name and Person can give you a clue that perhaps the attribute Name should actually be an
entity because Name is not a fundamental data type. A more subtle example is the Completed attribute of a Task. It's subtle because we might want to attach additional attributes to the concept
of state: when did the state occur, and by whom?
Therefore, when assigning attributes to an entity, consider:
- Is this attribute truly a fundamental data type, never to have any attributes of its own?
- Is this attribute describing state which itself can have additional attributes?
- Use the guidance regarding overloading meaning and duplicate attributes to determine if the attribute, even if it is a fundamental data type, should be a separate entity.
If you answer yes to either of any of these questions, then the guidance would be to create the attribute as an entity and also define all the allowable entity relationships,
which of course can expand as the application requirements change. For this reason, the concept of Completed is handled in a separate entity.
How Do I Want To Query The Data?
Another guidance is how you might want to query the resulting dataset. As an example, do you only ever want to query completed tasks, or will the user be interested
in the completion of all sorts of different entities? Will you want to know if a bug is completed? Will the manager want to know if
implementation has been reviewed? Will the technical lead want to know what tasks are completed and pending his/her review? These all inspect the
completion state of various entities. It is worthwhile to explore the possible ways the data will be queried, as this provides guidance as to how you
want to create the attributes of an entity and whether an attribute should be promoted to an entity. If the same attribute, in its
logical meaning, will be used repeatedly in different physical representations which vary only in their physical meaning but not the logical meaning,
then this is guidance that the attribute should be a separate entity.
Create Relationships That Have Meaning
A Key Concept
Most of the GAPMA relationships are defined simply to describe a hierarchy. For this reason, GAPMA is a poor example for the power of ROP.
We've gotten used to thinking of relationships in terms of foreign keys, which essentially describes a hierarchy. Because every relationship is
shoehorned into the concept of a foreign key, the information that would normally be carried in the relationship itself is expressed in the foreign key
field. For example, a Person might have a MarriedToID field. This is incredibly limiting though as it fails to capture multiple marriages and more
generally, the variety of partnerships one can have with another person. Therefore, it behooves us to start thinking of relationships as having meaning
in and of themselves. One of the key concepts of ROP is that this meaning is preserved in the relationship rather being expressed in the foreign key field
of a table or, slightly better, a specific association table.
Besides hierarchical relationships which are primarily static, we also have relationships between entities that describe the occurrence of an event (a birth, a crime,
a death, etc.) And event is something that occurs at a specific point in time. There are also relationships that have beginning
and potential ending times (i.e., a marriage, residency, job, etc). These kind of relationship technically describe two events (ie. marriage and divorce,
employment and termination, etc) but it's useful to abstract the physical concepts into a single composition of beginning and ending points, in which the
meaning of the beginning and ending point is determined by the context of the relationship.
Therefore, in order to glean the meaning of a relationship, it's useful to determine which of the three forms a relationship fits in:
- associating hierarchical information (which tends to be static, as we see in GAPMA)
- associating entities due to an external event which is static
- associations that have potential closure (completion) and are usually more dynamic in nature
Here's an example involving all three of these relationships: an investigation of missing money leads to the discovery that a son has been
stealing money from his father's wallet. Here we have the three relationship forms:
- hierarchical: parent-child relationship
- external event: a crime (money was found missing) at a particular date and time, expressed in the relationship person (victim) - crime (money stolen)
- transitory event: an investigator investigates the crime. This is an person (investigator) - crime relationship that has a beginning and ending date/time.
Relationships
In the previous article, I basically ignored the key concepts of relationships that I originally wrote about when I started this series.
It's time to go back to those concepts and work with them more formally! Unfortunately, the GAPMA is not the best example because relationships in the
GAPMA tend to be static, as opposed to say, a law enforcement database, in which relationships are very dynamic. None-the-less, I will endeavor to extract
some value out of GAPMA in terms of relationships.
In the previous section, I described the three forms of relationships:
- association for hierarchical purposes
- association as the result of an event
- association to describe a transitory relationship
We are now going to look at attributes that provide useful meaning for each of these three forms.
Meaningful Relationship Attributes
Common to all relationships are at least two attributes:
- when was the relationship created
- who created the relationship
It should be fairly self-evident that this is useful information associated with a relationship instance. What is less obvious is that the
entity types in a relationship are often indicators of the type of relationship: hierarchical, event, or transitory. This is not a hard rule--a
Person-Person relationship might be hierarchical (parent, child, friend of, etc) but may also be event (murdered) or transitory (friended on Jan 1st, unfriended on Jan 2nd).
Hierarchical Relationship Attributes
Hierarchical relationships are implicit in any relationship between two entities. In a hierarchical relationship, the only attribute necessary to
describe the relationship can be determined by the entity types: a Bug "is associated" with a Project, a User Story "is comprised of" Tasks, Tasks
"comprise" an Iteration. Therefore the relationship of the entity types can provide more concrete meaning beyond "has a" and "is a".
This is expressed in ROP when we create the relationship between two entity types.
Event Based Relationships
Event-based relationships, such as Person-Location describing birth, death, crime scene, etc., have a date/time "occurred on" attribute and type descriptor
attribute for the relationship instance that involves the entity instances. Contrast this to the hierarchical relationship attributes
described above, which is a descriptor of the relationship type involving entity types. We would typically want to provide a pick list
of allowable type descriptors based on the entity types involved in the relationship.
The date/time of the event should not be confused with the date/time in which the relationship is created.
Transitory Relationships
Rather than a "occurred" at attribute, this relationship has a "starting on date/time" and "ending on date/time" attributes. Similar to event-based
relationships, there is a type descriptor and we should have a pick list, but these are implemented as descriptor pairs, for example, "hired - terminated", "moved in - moved
out", "married - divorced", "married - widowed", and so forth.
GAPMA Relationships
We can see these three types of relationships at work in GAPMA:
- user stories associated to a project are hierarchical;
- a Task-Bug relationship is transitory, hopefully the task has a starting and completion time;
- the relationship between a project and a bug could be considered to event-based, as the bug "occurs on" a particular point in time. More concretely,
the general "occurs on" value could, in this context, be a "report on" description.
However, there is ambiguity here as to where the date/time attributes are best located, which I explore in detail next.
Event-based Relationships and Date/Time Attributes
One of the places where confusion arises with ROP is where to put date/time attributes. For example, it seems reasonable that the Bug entity has a
"reported on" Date/Time attribute, but what if you wanted a "reported on" and a "discovered on" date/time? A somewhat contrived example, but
still useful for illustrative purposes. As a more concrete question, in a Person-Location relationship that describes birth place, should the "Born On" attribute go in
Person or the relationship?
These questions deserve some thought, therefore, let's look at these questions with two different examples.
Example 1: The "Born On" Attribute
In the first option, the Person entity does not have a "Born On" attribute. At some point, we create a relationship type Person-Location, and one of the
"event" types that we can use to describe this relationship is "birthplace". It would be reasonable then to use the event relationship's "Occurred On"
attribute to represent the date/time of birth. But it would also be reasonable that, when the person record is displayed, we look at event-based
relationship instances and automatically add a "Born On" field to the Person displayed record if a "birthplace" relationship descriptor exists.
In the second option, the Person entity has been created with a "Born On" attribute. Again, at some point, we create a relationship type
Person-Location with a descriptor "Birth Place". In this case, when we view the Person-Location relationships, it would seem reasonable to populate the
"Occurred On" field with the value of the Person "Born On" attribute.
In this particular case, it seems absurd to use the Person-Location relationship instance to populate the "Born On" attribute - this, after all, is
a 1:1 "relationship" between a person and his/her date of birth. However, if we were to inspect Person-Location relationship instances that describe
"birthplace", it would be meaningful to associate the "Born On" attribute of the
person with the relationship's "Occurred On" attribute, thus we could display the date of birth as part of the relationship data.
This is a key point: being able to associate an event relationship with a field in one of the entities in the relationship. The best practices are:
- Does the event (the date/time) always exists (even if not known, we know it exists) with the entity?
- Is the abstraction of the attribute a primitive data type? If so, it seems reasonable that it exists as attribute of the entity rather than in a separate entity.
- Does the abstracted data type describe a structure that represents more than just the decomposition of the primitive data type? (DateTime can
be decomposed into Date and Time, but that doesn't add any additional value)
As a side note, if the initial requirements did not call for a "date of birth" field in the Person entity, we can add it later simply by adding the
attribute to the Person entity. The UI's will automatically show this new field - no need to rework them with auto-UI generation that the ROP IDE provides.
Conversely, it would be a best practice if the "birthplace" attribute were expressed in terms of a Person-Location relationship, for several reasons:
- Birthplace is not a temporal quantity
- Birthplace might have numerous fields that describe it: City, State, geocode, etc.
- Birthplace can be abstracted to a Location entity, whereas "Born On" can only be abstracted to a date/time, which is itself a primitive data type.
Example 2: The "Reported Crime On" Attribute
Here we have an attribute that does not always exist. A person may go through life and never have reported a crime. Furthermore, the usage of the attribute is
dependant on the existence of a relationship (Person-Crime). In this case, the "Occurred On" attribute of the relationship type (Person-Crime) with the
type descriptor "Report" (as opposed to, say, "Victim" or "Perpetrator", which are not event relationships but hierarchical relationships) can be described with
the text "Reported Crime On". The best practice here is:
- Is the event (the date/time) optional - it does not always exist?
- Does it come into existence only when an event relationship is created?
- Can the relationship be 1:many as opposed to always 1:1
These kind of relationships tend to be 1 to many: a Person may have reported many crimes (a Person does not have many birthdates, unless using aliases, which
should be clear that they are described with an Alias entity.)
Transitory Relationships
Transitory relationships are also different - these involve entities already created, in which a new relationship is established.
For example, an investigator (a Person entity instance) will have a beginning and ending date of a crime investigation. A Task associated with a bug will
have a "started work on" and "ended work on" date range.
One could argue that a Task should intrinsically have "started work on" and "ended work on" attributes. I will make the counter argument that a Task
only makes sense in relationship to the reason for the task (being assigned to a Sprint, Bug, Iteration, and so forth.) For this reason, the start/end
dates of the work have meaning to both entities (this is most pronounced for the Sprint or Bug entities.) So, the best practice here is, to ask yourself:
- Does the beginning and ending date of the relationship have meaning to both entities involved in the relationship?
- When we query the data, will it be useful to look at the parent entity from the perspective of all the start/end dates of associated child entities
(in other words, the lifetime of each transitory relationship from the perspective of the parent?)
If any relationship in which an entity is involved in has a "yes" to those questions, then it most likely makes sense to use the transitory relationship's
attributes rather than creating specific attributes in the entity. For a query, we can graph the beginning and ending dates of all entities involved in
transitory relationships with the Sprint entity, and thus easily visualize where the work peaks, what child entities took the shortest time, the longest time,
etc. In other words, we can easily report the lifetime of the relationship from the parent entity's perspective.
Relationship Type and Instance Attributes
From the above discussion (which could be called user stories), we can surmise a small set of attributes required in defining a relationship type and a relationship
instance. We've already described that all relationship instances have a minimum of two attributes:
These can in fact be auto-populated when the relationship instance is created. We can now describe additional attributes of the relationship type and relationship instance.
Relationship Type Attributes
The relationship type should contain a descriptor has to what type it is:
- hierarchical
- event
- transitory
Hierarchical Relationships Types
A hierarchical relationship type has attributes:
- the physical description of entity type A to entity type B
- the physical description of Entity type B to entity type A
"Is a" and "has a" are the general concepts, but we usually want to provide a more specific descriptor based on the relationship type. An example:
All terms have a hierarchical relationship to other entities.
Event Relationship Types
For event relationships types, we have the additional attributes:
- Entity type name mapping to the date/time field
- Entity attribute type name mapping to the entity's date/time field
These are populated only for "always exists" date-time fields of the entity.
An example of event relationships in GAPMA:
Bugs, except for a group of bugs, are event based, in which the "Reported On" field is the event date/time. I can't think of a good example of a
descriptor of the event--perhaps you can.
Transitory Relationship Types
For transitory relationships (see below), we have the additional attributes:
- The physical description for the logical "Began On" concept based on the type descriptor. For example "Married On"
- The physical description for the logical "Ended On" concept based on the type descriptor. For example, "Divorced On"
- Optionally, a pick list of physical descriptor pairs to choose from at the time the relationship is instantiated, for example, "Divorced On", "Widowed On",
"Separated On".
Example:
Tasks are transitory - they have a beginning and an end. Same with project sprints. Note that in the above screenshot, a "Task-Task"
relationship has a descriptor type, which I've designated as a pick list of either "dependency" or "sub-task."
Relationship Instance Attributes
The following describes instance attributes for the three kinds of relationship instances.
Hierarchical Relationship Instances
These do not have any additional instance attributes.
Event Relationship Instances
For event-based relationship instances, we have the additional attributes:
- "Occurred On" date-time value for "when the relationship is created" -- the attribute does not always exist
- Descriptor instance
Which describes, usually from a pick list, the event (birth, death, marriage, accident, etc). In the GAPMA, there really isn't any particular
description to add to an "event" like a Bug-Project association--even describing this association as an event is a bit questionable except in the context of
"reported on".
Transitory Relationship Instances
For transitory relationships, we have the additional attributes:
Implementation
The following section describes the implementation for all the features I discussed above.
- Event Relationship Attributes
- Transitory Relationship Attributes
- Default Values
- Joining 1:1 associations
Supporting Relationship Created On and Created By
In the ROP schema, there are two attributes assigned to the RelationshipInstance entity: "CreatedOn" (a date-time) and "CreatedByID",
a reference to the user. To provide the desired behavior, we have to implement a some new features in the ROP.
The "Created On" Attribute
The attribute "CreatedOn" presents the problem of defining a default value for this attribute (or any attribute, actually).
Implementing an Attribute Default Value
First, we add the DefaultValue property to the Attribute class:
[Category("Options")]
[XmlAttribute()]
[Description("The default value assigned when an instance using this attribute is created.")]
public string DefaultValue { get; set; }
Assigning the Default Value When a New Row is Created
Now, when we create instances (in the model), we can assign the default value. This could be accomplished with two lines of code in the creation of the DataSet,
by initializing the DataColumn's DefaultValue property:
if (ropAttr.HasDefaultValue)
{
dc.DefaultValue = ropAttr.DefaultValue;
}
However, for fields like dates and times, we also add the ability to provide a "macro" capability to resolve default values, and furthermore, for fields like
date/time, this needs to be resolved at the time the record is created, not at the time the DataSet is instantiated. The above code won't work if the
default value is a macro, like "@Now". Therefore, we first want to make the DataColumn class smarter:
public class DefaultValueResolverDataColumn : DataColumn
{
new public string DefaultValue { get; set; }
public DefaultValueResolverDataColumn(string name, Type colType)
: base(name, colType)
{
}
}
The DataSet is now created with DefaultValueDataColumn columns, where we initialize the DefaultValue:
ROPLib.Attribute ropAttr = Schema.Instance.GetAttribute(attr.Name);
dc = new DefaultValueDataColumn(attr.FieldNameOrName, dataTypeMap[ropAttr.DataType]);
if (attr.IsPrimaryKey)
{
primaryKey = dc;
dc.AutoIncrement = true;
}
dc.DefaultValue = ropAttr.DefaultValue;
Then we intercept the TableNewRow event to assign the default values ourselves:
dt.TableNewRow += new DataTableNewRowEventHandler(OnTableNewRow);
dataSet.Tables.Add(dt);
and the implementation (this is really bare bones with regard to the macro evaluation!) is:
protected void OnTableNewRow(object sender, DataTableNewRowEventArgs e)
{
foreach (DefaultValueDataColumn dc in e.Row.Table.Columns)
{
if (!String.IsNullOrEmpty(dc.DefaultValue))
{
object val = dc.DefaultValue;
string strval = dc.DefaultValue;
if (strval[0] == '@')
{
if (strval[1] != '@')
{
val = GetMacroValue(strval);
}
else
{
val = strval.Substring(1);
}
}
e.Row[dc] = val;
}
}
}
protected object GetMacroValue(string macro)
{
switch (macro.ToUpper())
{
case "@NOW":
return DateTime.Now;
}
throw new ApplicationException("The macro " + macro + " is not supported.");
}
The result is a date/time value in our relationship records whenever a new record is created:
The "Created By" Attribute: Menus, Vars, and Supporting Code
The second issue, the CreatedByID attribute, presents an interesting problem: the schema is referencing application instance data rather than model instance data.
In other words, CreatedByID will reference the ID of a specific record in the Person entity, but the Person instance entity doesn't exist at the model level
(like an entity type or entity instance) but rather at the application data level. We already have an example of this in the RelationshipInstance
class - the EntityAID and EntityBID fields are references to application instance entities. The management of this is implicit in the way the code is written
when creating a relationship instance, for example:
int parentID = (int)child["EntityID"];
int childID = (int)parent["EntityID"];
entityProvider.AssociateParentWithChild(childID, parentID);
With regards to the "CreatedByID", the model can't make any assumptions about what entity the person ID is in (we could hard-code the assumption,
but that wouldn't be a good idea.) This means we need a login dialog, but again, this is application specific. Furthermore, we need to be able to specify
some kind of "variable" that holds the ID value of the current user which is specified as the default value when the instance is created.
The value of this variable is determined at runtime when the user logs in. So, we're going to take several steps backward to accomplish a major leap forward:
- Support application-specific UI's
- Support application-specific menus to invoke those UI's
- Implement the concept of a var
- Implement some initial smarts to populate the var's value from a selection list of application data
- Map the var as a macro to the default value of a column
I've created a simple concept that application-specific UI's can be invoked from an application specified menu structure. The menus are
loaded at runtime based on the dataset that is loaded, and the forms, being MyXaml files, are instantiated at runtime as well.
Attributes Needed for the Menu Entity
First, let's create a few attributes we need for our menu system in the schema itself:
Next, we create a Menu instance entity:
Creating the Menu - Parent Menu Relationship
And the relationship between ParentMenuID and ID:
We can now define a simple top level menu, "Application", that has a sub-menu called "Log In" that loads the form "login.myxaml":
Appending the Application Menu at Runtime
Now we just add the smarts to the ROP application to look for a Menu entity
in the dataset and to dynamically instantiate this menu in addition to the standard menu items in the application:
protected void UpdateMenus()
{
RemoveCustomMenus();
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
if (dataSet.Tables.Contains("Menu"))
{
DataTable dtMenu = dataSet.Tables["Menu"];
topLevelMenuItems = CreateMenu(dtMenu, DBNull.Value);
foreach (ToolStripMenuItem tsmi in topLevelMenuItems)
{
menuStrip.Items.Add(tsmi);
}
}
}
protected List<ToolStripMenuItem> CreateMenu(DataTable dtMenu, object parentID)
{
List<ToolStripMenuItem> menuItems = new List<ToolStripMenuItem>();
var items = from item in dtMenu.AsEnumerable()
where item["ParentMenuID"].Equals(parentID)
select new
{
ID=item.Field<int>("ID"),
Name = item.Field<string>("Name"),
Form=item.Field<string>("Form"),
ParentID = item["ParentMenuID"],
};
foreach (var item in items)
{
ToolStripMenuItem tsmi = new ToolStripMenuItem(item.Name);
if (!String.IsNullOrEmpty(item.Form))
{
tsmi.Tag = item.Form;
tsmi.Click += new EventHandler(OnApplicationMenuClick);
}
menuItems.Add(tsmi);
List<ToolStripMenuItem> childMenuItems = CreateMenu(dtMenu, item.ID);
foreach(ToolStripMenuItem childItem in childMenuItems)
{
tsmi.DropDownItems.Add(childItem);
}
}
return menuItems;
}
protected void RemoveCustomMenus()
{
foreach (ToolStripMenuItem tsmi in topLevelMenuItems)
{
menuStrip.Items.Remove(tsmi);
}
}
protected void OnApplicationMenuClick(object sender, EventArgs e)
{
ToolStripMenuItem tsmi = (ToolStripMenuItem)sender;
string formName = (string)tsmi.Tag;
Parser p = new Parser();
p.AddReference("App", this);
Form form = (Form)p.Instantiate(UI + formName, "*");
form.ShowDialog();
}
The end result is that we can add application-specific menus, where the application is determined by the dataset, and therefore the application specific menus are carried in the dataset.
The beauty of doing this declaratively is that any application-specific behavior can be instantiated in the XML by referencing a plug-in module,
instantiating the necessary classes, and wiring event handlers to that class at runtime. It's a very simple way to implement an Inversion of Control
design pattern - you don't need a massive IoC framework--I've never understood why I need a bloated IoC framework.
Ideally, it would be nice to specify where the menu gets inserted, but that can be left for a later version.
Variables - A Place to Stuff Application Values
But we're not done. As I mentioned above, we need a concept of a "variable". The user will be selecting his/her username (we could extend
this to a login, but that's not necessary at the moment). Several things need to happen:
- The selected ID needs to go into a variable
- The variable value needs to be used as the default value when creating the relationship
- The model editor needs to be smart enough to use application data (not the model data) to resolve the lookup
- The ROP Attribute class needs to have additional properties to support this feature
- There needs to be some backing code to support the creating of a login UI that maps to an attribute to a lookup control (combobox) and stuffs the selected value into the var.
The Var Entity and Attributes
To begin with, let's add an entity called "Var" with the attributes of "Name" and "Value" to the schema:
Then, in the model editor, we'll add a single entry, for Username (at the end of this discussion you will discover that this should have been called "UsernameID"):
A Smart ComboBox That Sets The Var Value
Next, we're going to create a smart control that knows how to assign a selected value from a combobox into this variable:
public class SwfDataComboBox : ComboBox, ISupportInitialize
{
public DataSet DataSet { get; set; }
public string EntityName { get; set; }
public string VarName { get; set; }
new public string DisplayMember { get; set; }
protected bool initialized = false;
protected EntityProvider entityProvider;
public SwfDataComboBox()
{
SelectedValueChanged += new EventHandler(OnSelectedValueChanged);
}
public void BeginInit() { }
public void EndInit()
{
entityProvider = new EntityProvider(DataSet);
entityProvider.InitializeWithEntity(EntityName);
entityProvider.LoadTable();
base.DisplayMember = entityProvider.GetColumnNameMapping(DisplayMember);
DataSource = entityProvider.DataTable;
initialized = true;
Update();
}
protected void OnSelectedValueChanged(object sender, EventArgs e)
{
if (initialized)
{
UpdateVar();
}
}
protected void UpdateVar()
{
DataTable dtVar = DataSet.Tables["Var"];
dtVar.Select("Name='" + VarName + "'")[0]["Value"] = SelectedValue;
}
}
Example: Adding a Couple Person Instances
Next, let's add a couple users in the entity editor, since "Person" is an entity defined in the application model:
A Login Form to Set The Username
Now we just need to login form that provides the necessary declarative information to our custom combobox to wire up the application entity instance and the variable:
="1.0"="utf-8"
<MyXaml xmlns="System.Windows.Forms, System.Windows.Forms,
Version=2.0.0000.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
xmlns:ui="UI.DotNet, UI.DotNet"
xmlns:def="Definition"
xmlns:ref="Reference">
<Form Name="Login"
FormBorderStyle="FixedDialog"
AcceptButton="{btnOK}"
Text="Login"
ClientSize="400, 80"
StartPosition="CenterScreen">
<Controls>
<Label Location="10, 12" Size="70, 15" Text="Username:"/>
<ui:SwfDataComboBox Location="85, 10" Size="200, 20" DataSet="{DataSet}" EntityName="Person"
DisplayMember="Username" ValueMember="ID" VarName="Username"/>
<Button def:Name="btnOK" Location="300, 8" Size="80, 25" Text="OK" Click="{App.CloseForm}"/>
</Controls>
</Form>
</MyXaml>
Now, when we select a user:
The variable "Username" is updated:
The interesting thing about this is that selection is saved in our dataset. This means we could automatically select the last username. While useful
(for example, configuration information, form position, last used field values, etc.), this behavior is probably not desirable in all cases. Something to
enhance later (you notice I say that a lot.) But the idea here is that we have a good start at some very general purpose functionality, which we can enhance later as needed.
Using the Var's Value as a Default Value for the New Row
Next, when a relationship instance is created, we need to specify that this var's value is to be used, so we add a new macro, @VAR:
protected object GetMacroValue(string macro)
{
switch (macro.ToUpper().LeftOf('('))
{
case "@NOW":
return DateTime.Now;
case "@VAR":
{
string varName = macro.Between('(', ')');
object val = dataSet.Tables["Var"].Select("Name='" + varName + "'")[0]["Value"];
return val;
}
}
}
Specifying the Var as the Default Value of an Attribute
We specify this value as the default value for the CreatedByID attribute:
...and now, when we create a relationship instance, both the date and user ID are populated:
Now, ideally, this variable name should have been "UsernameID", which I'll fix in the demo dataset (honestly, I'm too lazy to redo all the screenshots!)
However, changing this doesn't affect code--only the declarative code is affected.
Mapping Application Records
There's one last detail: we'd like the model editor to be smart enough to display the name of the user, not the ID. In fact, this should be a
pick-list so the "super-user" can change this selection.
Adding Some More Properties to the Attribute Class to Support Mapping
For this, we have to back to the schema's Attribute class and add some additional properties to help the model editor figure out what entity is represented by this field and
what the display and value members are:
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The name of the application entity that " +
"populates the list of allowable values for this field.")]
public string EntityName { get; set; }
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The field that is displayed as the human-readable value.")]
public string DisplayMember { get; set; }
[Category("Application Lookup")]
[XmlAttribute()]
[Description("The field that represents the internal ID.")]
public string ValueMember { get; set; }
Setting the New Properties of the CreatedByID Attribute
The CreatedByID attribute properties are set accordingly:
Adding the Intelligence to the Grid to use the Mapped Application Records in a Lookup Field
The creation of the model grid is then modified accordingly (this is in the InitializeColumns method of the ModelEditor):
ROPLib.Attribute attr = Schema.Instance.GetAttribute(dc.ColumnName);
if (attr.HasApplicationLookup)
{
EntityProvider entityProvider = new EntityProvider(dataSet);
entityProvider.InitializeWithEntity(attr.EntityName);
entityProvider.LoadTable();
string displayMember = entityProvider.GetColumnNameMapping(attr.DisplayMember);
string valueMember = attr.ValueMember;
DataTable dtSource = entityProvider.DataTable;
DataView dvSource = new DataView(dtSource);
dvSource.Sort = displayMember;
dgvModel.AddLookupColumn(dvSource, valueMember, displayMember, dc);
isLookup = true;
}
Now, when we create a relationship, the CreatedByID is set to a lookup control:
And we can declare success!
Exposing the Relationship Type Descriptor
Entity relationships like Task-Task have a type descriptor -- in GAPMA the Task-Task can be a sub-task or dependency relationship type. The pick list
should be filtered by the items of the list specified in the relationship type definition. We want to expose this picklist so the user can select the
relationship type when creating an association. This list should only be selectable when the relationship type defines a type descriptor. For this
particular example, we're going to set up a pick list that is defined in the model, as opposed to the schema.
First, we define an attribute, "RelationshipTypeDescriptor":
With the following properties:
Note that the pick list is determined from the model's List entity. Don't ask why I chose Name as the ValueMember.
This describes the relationship type, and in GAPMA, we have the following relationship types:
- Task-Task
- Subtask
- Dependency
- Test-Test
- Sub-test
- Dependency
- Test-Requirement
- Test that is against a requirement
- Test that has a requirement
Next, we add this attribute to the RelationshipType entity defined in the schema:
Then, in the Model editor, we edit our List entity and add the three relationship description types described above:
And the pick list items:
Finally, in our model relationship types, we can describe the pick list that we want to expose to the user when they create one of these particular associations:
Lastly, we need a RelationshipTypeDescriptorID property in the RelationshipInstance entity of the schema, to which we will assign the
user-selected type descriptor. Note that there is something very sneaky happening here. The ID that will eventually be assigned is guaranteed to
be unique because it is determined from a filtered list of ListItem records, which are all the items for all lists managed by the model's List
entity. This is something to keep in mind and also explains why we don't need both the List ID and the ListItem ID. For this reason, we can
associate the property directly to the model's ListItem entity:
We could manually (in the model) select the descriptor type ID:
but that is obviously not the preferred method. Note that the list is not being qualified by the relationship descriptor list. This could be
something we add later on, but involves creating a unique lookup control for each row in the grid, since the pick list changes depending on the type
descriptor, something I don't want to tackle at the moment.
The Association UI
We now need to add a UI element to the Association section that allows the user to select the relationship type for a given instance. First, we'll
add a combobox for selecting this value to the entity editor:
<Label Text="Rel. Type:" Location="360, 4" Size="60, 15"/>
<ComboBox def:Name="cbRelTypeDescr"
Location="420, 0" Size="100, 20"
ValueMember="ID" DisplayMember="Name"
Enabled="false"
SelectedIndexChanged="{EventHandlers.OnDescrTypeIDChanged}"/>
and in the EventHandlers class (poorly named, as this is the class that handles events for the entity editor!), we auto-initialize the combobox field:
[MyXamlAutoInitialize]
ComboBox cbRelTypeDescr = null;
When either a "show parent data" or "show child data" for relationship type is selected, we can call the method to populate the descriptor list:
protected void OnShowParentData(object sender, EventArgs eventArgs)
{
parentEntityTypeID = (int)cbParentEntities.SelectedValue;
associating = Associating.Parent;
ShowEntityInstances(parentEntityTypeID);
PopulateRelationshipTypeDescriptorList(entityTypeID, parentEntityTypeID);
}
protected void OnShowChildData(object sender, EventArgs eventArgs)
{
childEntityTypeID = (int)cbChildEntities.SelectedValue;
associating = Associating.Child;
ShowEntityInstances(childEntityTypeID);
PopulateRelationshipTypeDescriptorList(childEntityTypeID, entityTypeID);
}
which involves getting the relationship type ID...
public int GetRelationshipTypeIDFromEntityTypeIDs(int entityATypeID, int entityBTypeID)
{
var id = from row in dataSet.Tables["RelationshipType"].AsEnumerable()
where (row.Field<int>("EntityATypeID") == entityATypeID) &&
(row.Field<int>("EntityBTypeID")==entityBTypeID)
select row.Field<int>("ID");
return (int)id.First();
}
...and looking up to see if there is an associated relationship type descriptor list to populate the combobox with the descriptor items:
protected void PopulateRelationshipTypeDescriptorList(int entityATypeID, int entityBTypeID)
{
int relType = entityProvider.GetRelationshipTypeIDFromEntityTypeIDs(entityATypeID, entityBTypeID);
string typeDescrListName = (from row in entityProvider.DataSet.Tables["RelationshipType"].AsEnumerable()
where row.Field<int>("ID") == relType
select row.Field<string>("RelationshipTypeDescriptor")).FirstOrDefault();
if (!String.IsNullOrEmpty(typeDescrListName))
{
int listID = (from row in entityProvider.DataSet.Tables["List"].AsEnumerable()
where row.Field<string>("Name") == typeDescrListName
select row.Field<int>("ID")).First();
var items = (from row in entityProvider.DataSet.Tables["ListItem"].AsEnumerable()
where row.Field<int>("ListID") == listID
orderby row.Field<int>("Ordinality")
select new { ID = row.Field<int>("ID"), IsDefault =
row.Field<bool?>("IsDefault"), Name=row.Field<string>("Name") }).ToList();
cbRelTypeDescr.DataSource = items;
var defaultItem = items.FirstOrDefault(t => t.IsDefault == true);
if (defaultItem != null)
{
cbRelTypeDescr.SelectedValue = defaultItem.ID;
}
cbRelTypeDescr.Enabled = true;
}
else
{
cbRelTypeDescr.SelectedValue = -1;
cbRelTypeDescr.Enabled = false;
}
}
Now, when we pick a relationship association for which we have a type descriptor, we get a pick list of descriptors as defined by the descriptor type list:
The, we "merely" assign the ID of the selected relationship type when the association is made:
protected void OnDescrTypeIDChanged(object sender, EventArgs args)
{
relTypeDescrID = cbRelTypeDescr.SelectedValue as int?;
}
and:
...
row["RelationshipTypeDescriptorID"] = relTypeDescrID;
...
We can see the result by inspecting the RelationshipInstance entity in the model:
Exposing The Relationship Event Descriptor
In GAPMA, there is only one event descriptor for Bug events, and it simply is "Occurred On" (you can add others if you think of any.) We want to expose
the event descriptor pick list so that when we create the association, we can specify the relationship event descriptor. This list should be selectable
for event relationship types.
In our ROP model, we add an attribute called EventDescriptorID:
The pick list for this is going to come from the application data, so we map the lookup for this entity to an entity of the application:
We add this attribute to the model's RelationshipInstance:
We add the application entity type by editing the EntityType collection in our application model:
and associate the attribute "Name" to the newly created entity type:
Lastly, we add the "Occurred On" descriptor in our application data via the "User -> Edit Application Data" menu:
Now, when we use the model to inspect our relationship instances, we observe that there is an "Event Descriptor" model column whose pick list is
derived from application data:
This illustrates a different implementation than the Relationship Type Descriptor, which uses model data as the picklist rather than
application data. I have no particular guidance on which is better, there are pros and cons to each approach:
- pros for linking to model data: the pick list is in the model and is therefore carried by the model.
- pros for linking to the application data: the pick list is in the data which the model references, so the application must implement the referenced entity.
For the moment, I simply wanted to illustrate the two approaches.
The Association UI
As with the relationship type descriptor, I want this property exposed in the association section of the application entity form. This essentially involves hard-coding the knowledge of this
entity in the form. The process is very similar to the relationship type descriptor. In the MyXaml, because the list of items comes from the
EventDescriptors list, we can populate the combobox from that entity:
<dotnet:SwfDataComboBox
def:Name="cbEventDescr"
Location="420, 35"
Size="100, 20"
DataSet="{dataset}"
EntityName="EventDescriptors"
ValueMember="ID"
DisplayMember="Name"
Enabled="false"
SelectedIndexChanged="{EventHandlers.OnEventTypeChanged}"/>
Which gives us a pick list for "event" relationships, such as Bug-Project:
And we can see the selection by inspecting the relationship instance in the model:
Exposing the Began On and Ended On Properties
At the moment, because there aren't any rule triggers, we want to allow the user to edit the Began On and Ended On properties for transitory relationship
types. Thus, at a bare minimum, we need a UI that lists just transitory relationships and lets the user enter one or both of these values. In more
complicated applications we would want to expose these properties in a more sophisticated manner, or even automate them with some rule triggers, but I'll
leave that for the future.
The "Began On" and "Ended On" attributes are added to the model's attribute list and have the data type "DateTime":
They are then added to the model's RelationshipInstance entity:
And we observe that the RelationshipInstance entity now has these attributes:
The code, incidentally, for setting up this property in the DevExpress grid is:
case "DATETIME":
editor = new RepositoryItemDateEdit();
((RepositoryItemDateEdit)editor).EditMask = "MM/dd/yyyy hh:mm tt";
((RepositoryItemDateEdit)editor).Mask.UseMaskAsDisplayFormat = true;
break;
The Association UI
Again, this involves hard-coding the UI for these attributes, whose values are assigned when the association is made. The MyXaml portion:
<Label Text="Began:" Location="350, 74" Size="70, 15"/>
<ui:DxDateTimeEdit def:Name="dtBeganOn" Location="420, 70" Size="100, 20" EditMask="MM/dd/yyyy hh:mm tt"/>
<Label Text="Ended:" Location="350, 109" Size="70, 15"/>
<ui:DxDateTimeEdit def:Name="dtEndedOn" Location="420, 105" Size="100, 20" EditMask="MM/dd/yyyy hh:mm tt"/>
Which gives us the ability to enter Began On and Ended On datetime information for transitory events (the controls are disabled and nulled when not a transitory event):
And we can see the BeganOn and EndedOn attributes of the relationship instance set when a transitory relationship association is made:
Summary of Pick Lists
Sadly, I've created a bit of a rats nest when it comes to pick lists. There are three supported flavors of pick lists:
- Lists whose collection of items encoded into the meta-model (the tree on the left), for example, the "Relationship Type"--Hierarchical, Event,
Transitory--and thus the model (schema.)
- Lists whose collection of items is contained in the model's List entity, for example the Relationship Type Descriptor, and thus the
application's serialized dataset.
- Lists whose collection of items is contained in an application entity, and thus the application's serialized dataset.
My excuse is the incremental approach to building this application. Clearly, a "best practice" for schema information (such as the relationship
type) belongs in the schema. However, as I mentioned above, where to place application pick lists is not clear, especially when the schema refers to
either model or application entities. This is a confusing snarl of implementation that I hope to resolve at some point.
However, for the time being, here is the following guidance:
- A description of type that is static (not application dependent) can go in a schema List collection;
- A description of type that is application specific but that further defines a model type (a schema instance) can go in the model's List collection;
- A description of an application entity instance is associated to an application entity.
Hopefully that makes some sense.
Auto-Creating "With All Other Entities" Relationships
This applies to the Note and Document entities described above. What we want to do is automatically create the relationship types for entities that are
in a relationship with all other entities. This allows the user to pick from one of these other entities without the "super user" creating each and
every relationship type manually. In the current implementation, this "fixup" occurs when the model is loaded. The fixup entails creating any missing relationships:
protected void FixupRelationshipTypesOfAll()
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
var assocToAll = from et in dataSet.Tables["EntityType"].AsEnumerable()
where et.Field<bool?>("AssociateWithAllEntities") == true
select new { Name = et.Field<string>("Name"), ID = et.Field<int>("ID") };
foreach (var assocToAllEntity in assocToAll)
{
var unassoc = from et in dataSet.Tables["EntityType"].AsEnumerable()
where !(dataSet.Tables["RelationshipType"].AsEnumerable().Any(
rt => (rt.Field<int>("EntityATypeID") == assocToAllEntity.ID)
&& (rt.Field<int>("EntityBTypeID") == et.Field<int>("ID"))))
select new { Name = et.Field<string>("Name"), ID = et.Field<int>("ID") };
foreach (var unassocEntity in unassoc)
{
DataRow row = dtRelType.NewRow();
row["Name"] = assocToAllEntity.Name + " - " + unassocEntity.Name;
row["EntityATypeID"] = assocToAllEntity.ID;
row["EntityBTypeID"] = unassocEntity.ID;
row["Cardinality"] = "n:1";
row["RelationshipType"]="Hierarchical";
dtRelType.Rows.Add(row);
}
}
}
The above code first gets all the "associate to all" entities, then, by inspecting the relationship types, finds unassociated entities for each of the
"associate to all" entities. For each unassociated entity (the relationship type is missing), the association is explicitly created as a
many-to-one hierarchical relationship type.
Looking at the above code, you are probably wondering why I'm not using a strongly typed DataSet. I think that's a valid question and one that will
probably be addressed in some future version.
1:1 Relationships
So far, what we've been implementing has been fairly simple. 1:1 relationships are much more interesting because of the visualization and behaviors that are desirable. These are:
- auto-creating the child entities that are in a 1:1 relationship with the parent when the parent instance is created.
- auto-creating the child entities when a new entity type is designated as being in a 1:1 relationship with a parent.
- automatically adding in the 1:1 child entity attributes for a parent entity.
- managing the persistence of values that ultimately are handled by separate tables.
In GAMPA, there are a variety of 1:1 relationship. For example, there is a 1:1 relationship between the entities Task and Progress. We'll work
with this particular instance and see how the code develops to support the above requirements.
Application Lookup Columns
First, we have to implement a feature that currently doesn't exist: lookup fields in application data. For example, the progress state is a lookup,
but the IDE currently shows a simple textbox edit control in the grid:
This is not what we want! The problem is in this code, which blindly assigns the DataView of the selected entity to the grid without regard for lookup controls:
protected void InitializeGrid()
{
BindingSource bs = new BindingSource();
bs.DataSource = entityProvider.DataView;
dgvData.DataSource = bs;
GridInfo.BindingSource = bs;
}
What we need is something smarter:
...
InitializeGridData();
InitializeGridColumns();
}
protected void InitializeGridColumns()
{
dgvData.ClearColumns();
DataTable dt = entityProvider.DataTable;
int n = 0;
foreach (DataColumn dc in dt.Columns)
{
if (dc.ColumnMapping != MappingType.Hidden)
{
AttributeInfo attr = entityProvider.Attributes[n];
if (attr.PickListID == null)
{
dgvData.AddColumn(dc);
}
else
{
List<ItemList> items =
(from item in entityProvider.DataSet.Tables["ListItem"].AsEnumerable()
where item.Field<int>("ListID") == attr.PickListID
orderby item.Field<int>("Ordinality")
select new ItemList { ID = item.Field<int>("ID"),
Name = item.Field<string>("Name") }).ToList();
DataView dv = new DataView(items.ToDataTable());
dgvData.AddLookupColumn(dv, "ID", "Name", dc);
}
}
else
{
dgvData.AddColumn(dc);
}
++n;
}
}
Which yields a lovely dropdown box:
Automatically Including the Fields of All Entities in a 1:1 Relationship
First, we want to add the fields of all child entities in a 1:1 relationship. The determination of the field order is arbitrary. From a visualization
perspective, we could also use DevExpress' grid feature of creating a "group column" to make it clearer to the user with regards to the field organization,
however I'll leave that for a later implementation (nor is it something you will ever see in the .NET grid control since it doesn't have this capability and I
don't want to try to code it.)
The entity fields are currently populated by the method PopulateEntityTypeAttributes in EntityProvider.cs:
protected void PopulateEntityTypeAttributes(int entityTypeID)
{
attributes =
(from eta in dataSet.Tables["EntityTypeAttributes"].AsEnumerable()
where eta.Field<int>("EntityTypeID") == entityTypeID
join at in dataSet.Tables["AttributeType"].AsEnumerable()
on eta.Field<int>("AttributeTypeID") equals at.Field<int>("ID")
orderby eta.Field<int>("Ordinality")
select new AttributeInfo
{
ID=at.Field<int>("ID"),
EntityTypeID=eta.Field<int>("EntityTypeID"),
Name = at.Field<string>("Name"),
DataType = at.Field<string>("DataType"),
Length = at.Field<int>("Length"),
}).ToList();
}
We want to merge in the fields from all entities that we are in a 1:1 relationship with,
which involves inspecting the Cardinality field of the RelationshipType instance:
protected void PopulateEntityTypeAttributes(int entityTypeID)
{
attributes = GetAttributes(entityTypeID, null);
MergeOneToOneEntityTypeFields(attributes, entityTypeID);
}
protected void MergeOneToOneEntityTypeFields(List<AttributeInfo> attributes, int entityTypeID)
{
var oneToOneEntityTypes =
from er in dataSet.Tables["RelationshipType"].AsEnumerable()
where (er.Field<int>("EntityBTypeID") ==
entityTypeID) && (er.Field<string>("Cardinality") == "1:1")
select er.Field<int>("EntityATypeID");
oneToOneEntityTypes.ForEach(t=>attributes.AddRange(GetAttributes(t, entityTypeID)));
}
protected List<AttributeInfo> GetAttributes(int entityTypeID, int? parentEntityTypeID=null)
{
List<AttributeInfo> attributes =
(from eta in dataSet.Tables["EntityTypeAttributes"].AsEnumerable()
where eta.Field<int>("EntityTypeID") == entityTypeID
join at in dataSet.Tables["AttributeType"].AsEnumerable()
on eta.Field<int>("AttributeTypeID") equals at.Field<int>("ID")
orderby eta.Field<int>("Ordinality")
select new AttributeInfo
{
ID=at.Field<int>("ID"),
EntityTypeID=eta.Field<int>("EntityTypeID"),
ParentEntityTypeID=parentEntityTypeID,
Name = at.Field<string>("Name"),
DataType = at.Field<string>("DataType"),
Length = at.Field<int>("Length"),
PickListID = at.Field<int?>("PickListID"),
}).ToList();
return attributes;
}
Pay attention to the ParentEntityTypeID assignment. This information will be used when persisting 1:1 instance values.
Now we get the additional columns of all child entities in a 1:1 relationship with the selected parent:
Fixups When New 1:1 Entities are Created and Auto-Creating 1:1 Relationships
There are three considerations:
- if we have existing entity instances and we add some new entity types that are in a 1:1 relationship, we want to automatically create the
instances and relationships for all existing entities in the new relationship;
- we add a parent with 1:1 child relationships, we also want to create the related 1:1 child entities whenever the parent entity is created;
- on program startup, we want to verify that all the 1:1 child entities actually exist, and if not, create them. This is the situation at the moment.
We'll write the "fixup the existing data", scenario 3 above, which will actually result in solving the other two scenarios as well--the recursive
requirement means that we can re-use the code that creates the 1:1 relationship for a given entity type.
protected void FixupOneToOneRelationships()
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
List<AssociationInfo> assocTypes = (from rt in dtRelType.AsEnumerable()
join entityAType in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityATypeID") equals entityAType.Field<int>("ID")
where rt.Field<string>("Cardinality") == "1:1"
select new AssociationInfo()
{
RelationshipTypeID = rt.Field<int>("ID"),
EntityATypeID = rt.Field<int>("EntityATypeID"),
EntityBTypeID = rt.Field<int>("EntityBTypeID"),
EntityATypeName = entityAType.Field<string>("Name")
}).ToList();
CreateMissingRelationshipInstances(assocTypes);
}
protected void CreateMissingRelationshipInstances(int entityTypeID)
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtRelType = dataSet.Tables["RelationshipType"];
List<AssociationInfo> assocTypes = (from rt in dtRelType.AsEnumerable()
join entityAType in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityATypeID") equals entityAType.Field<int>("ID")
where (rt.Field<string>("Cardinality")) == "1:1" &&
(rt.Field<int>("EntityBTypeID")==entityTypeID)
select new AssociationInfo()
{
RelationshipTypeID = rt.Field<int>("ID"),
EntityATypeID = rt.Field<int>("EntityATypeID"),
EntityBTypeID = rt.Field<int>("EntityBTypeID"),
EntityATypeName = entityAType.Field<string>("Name")
}).ToList();
CreateMissingRelationshipInstances(assocTypes);
}
protected void CreateMissingRelationshipInstances(List<AssociationInfo> assocTypes)
{
DataSet dataSet = ((DataSetProvider)dsp).DataSet;
DataTable dtEntityInst = dataSet.Tables["EntityInstance"];
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
foreach (var assoc in assocTypes)
{
var childParentEntityInstances = from ri in dtRelInst.AsEnumerable()
join entityAInst in dtEntityInst.AsEnumerable()
on ri.Field<int>("EntityAID") equals entityAInst.Field<int>("ID")
join entityBInst in dtEntityInst.AsEnumerable()
on ri.Field<int>("EntityBID") equals entityBInst.Field<int>("ID")
where (entityBInst.Field<int>("EntityTypeID") == assoc.EntityBTypeID)
select new {A = entityAInst, B = entityBInst};
var allParentInstances = (from ei in dtEntityInst.AsEnumerable()
where ei.Field<int>("EntityTypeID") == assoc.EntityBTypeID
select ei).ToList();
foreach (var parentInst in allParentInstances)
{
if (!childParentEntityInstances.Any(t =>
(t.A.Field<int>("EntityTypeID") == assoc.EntityATypeID) &&
(t.B.Field<int>("ID") == parentInst.Field<int>("ID"))))
{
DataRow instance = dtEntityInst.NewRow();
instance["EntityTypeID"] = assoc.EntityATypeID;
instance["Comment"] = assoc.EntityATypeName;
dtEntityInst.Rows.Add(instance);
DataRow relInst = dtRelInst.NewRow();
relInst["EntityAID"] = instance["ID"];
relInst["EntityBID"] = parentInst.Field<int>("ID");
relInst["RelationshipTypeID"] = assoc.RelationshipTypeID;
relInst["CreatedOn"] = DateTime.Now;
dtRelInst.Rows.Add(relInst);
CreateMissingRelationshipInstances(assoc.EntityATypeID);
}
}
}
}
If we save the above changes, the state values don't get persisted because they don't actually belong to the Project entity. Instead, we need
to determine the actual entity instance in the 1:1 relationship. This utilizes the ParentEntityTypeID that we preserved in the AttributeInfo
collection when merging in the 1:1 entity types. With this information, we can identify the correct entity instance ID, which however requires recursively
perusing the 1:1 relationship instances to get the right child entity instance:
case DataTableTransactionRecord.RecordType.ChangeField:
{
AttributeInfo attr = columnAttributeInfoMap[dttr.ColumnName];
if (attr.ParentEntityTypeID != null)
{
entityID = dttr.Row.Field<int>("EntityID");
entityID = GetAssociatedParentEntity(entityID, attr.EntityTypeID,
attr.ParentEntityTypeID.Value).Item1;
}
else
{
entityID = dttr.Row.Field<int>("EntityID");
}
...
and:
protected Tuple<int, bool> GetAssociatedParentEntity(int entityID,
int entityTypeID, int parentEntityTypeID)
{
Tuple<int, bool> ret = new Tuple<int, bool>(-1, false);
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtRelationshipType = dataSet.Tables["RelationshipType"];
var assocTypes = from rel in dtRelInst.AsEnumerable()
join relType in dtRelationshipType.AsEnumerable()
on rel.Field<int>("RelationshipTypeID") equals relType.Field<int>("ID")
where (relType.Field<string>("Cardinality") == "1:1") &&
(rel.Field<int>("EntityBID")==entityID)
select new
{
EntityATypeID = relType.Field<int>("EntityATypeID"),
EntityBTypeID = relType.Field<int>("EntityBTypeID"),
EntityAID = rel.Field<int>("EntityAID"),
EntityBID = rel.Field<int>("EntityBID"),
};
if (!assocTypes.Any(t => (t.EntityATypeID == entityTypeID) &&
(t.EntityBTypeID == parentEntityTypeID)))
{
foreach (var assoc in assocTypes)
{
Tuple<int, bool> ret2 = GetAssociatedParentEntity(
assoc.EntityAID, entityTypeID, parentEntityTypeID);
if (ret2.Item2)
{
return ret2;
}
}
}
else
{
entityID = assocTypes.Single(t => (t.EntityATypeID ==
entityTypeID) && (t.EntityBTypeID == parentEntityTypeID)).EntityAID;
ret = new Tuple<int, bool>(entityID, true);
}
return ret;
}
This happy piece of code above now extracts the correct entity instance for a 1:1 relationship which is then ready for saving the attribute value.
Create Child 1:1 Entity Instances When Parent Is Created
We also need to create the child entity instance. For this, we can re-use some of the code written in the fixup routine and add one line of code to the
existing "NewRow" case:
case DataTableTransactionRecord.RecordType.NewRow:
{
DataRow newEntityRow = dtEntityInstance.NewRow();
newEntityRow["EntityTypeID"] = entityTypeID;
dtEntityInstance.Rows.Add(newEntityRow);
entityID = newEntityRow.Field<int>("ID");
dttr.Row["EntityID"] = entityID;
CreateMissingRelationshipInstances(entityTypeID);
break;
}
Deleting 1:1 Entity Instances
When a parent entity is deleted, all entities in a 1:1 relationship with that parent (recursively) need to be deleted:
protected void DeleteAssociatedOneToOneInstances(int entityID)
{
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtRelationshipType = dataSet.Tables["RelationshipType"];
var entityAList = from rel in dtRelInst.AsEnumerable()
join relType in dtRelationshipType.AsEnumerable()
on rel.Field<int>("RelationshipTypeID") equals relType.Field<int>("ID")
join A in dtEntityInstance.AsEnumerable()
on rel.Field<int>("EntityAID") equals A.Field<int>("ID")
where (relType.Field<string>("Cardinality") == "1:1") &&
(rel.Field<int>("EntityBID") == entityID)
select A;
foreach (var entityA in entityAList)
{
int childEntityID = entityA.Field<int>("ID");
dtEntityInstance.Rows.Remove(entityA);
DeleteRowAttributes(childEntityID);
DeleteAssociatedOneToOneInstances(childEntityID);
DeleteRelationshipInstances(childEntityID);
}
}
protected void DeleteRelationshipInstances(int entityID)
{
DataTable dtRel = dataSet.Tables["RelationshipInstance"];
var relInstances = from relInst in dtRel.AsEnumerable()
where (relInst.Field<int>("EntityAID") == entityID) ||
(relInst.Field<int>("EntityBID") == entityID)
select relInst;
foreach (var relInst in relInstances)
{
dtRel.Rows.Remove(relInst);
}
}
protected void DeleteRowAttributes(int entityID)
{
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
foreach (DataRow row in dtEntityInstance.Select("ID = " + entityID))
{
row.Delete();
DeleteAssociatedOneToOneInstances(entityID);
}
}
Loading The Field Values Of Entity Attributes in a 1:1 Relationship
We now need the complement--loading the values into the physical table for child entities in a 1:1 relationship with the parent. This involves refactoring (I still think
that's a stupid word, why not call a spade a spade, it's reworking, fixing, changing, I mean, "refactor" isn't even a word, though
oddly "refactoring" is, in the "Computer Dictionary", at least call it "factoring", as this means "the act or process of separating an equation,
formula, cryptogram, etc., into its component parts" which is at least what is going on here, but I digress) the PopulatePhysicalTable method, adding one line:
...
foreach (DataRow entityInstance in entityInstances)
{
...
PopulateOneToOneEntityAttributes(row, entityID, entityTypeID);
...
}
Where the method does all the work of getting the child instance, the type's attributes, and setting the row column's field (if one exists):
protected void PopulateOneToOneEntityAttributes(DataRow row, int entityID, int entityTypeID)
{
var oneToOneFields = attributes.Where(t => t.ParentEntityTypeID == entityTypeID);
DataTable dtAttributeType = dataSet.Tables["AttributeType"];
DataTable dtEntityAttributeInstance = dataSet.Tables["EntityAttributeInstance"];
DataTable dtEntityInst = dataSet.Tables["EntityInstance"];
DataTable dtRelInst = dataSet.Tables["RelationshipInstance"];
foreach (AttributeInfo ai in oneToOneFields)
{
int childEntityID = (from rel in dtRelInst.AsEnumerable()
join entityA in dtEntityInst.AsEnumerable()
on rel.Field<int>("EntityAID") equals entityA.Field<int>("ID")
join entityB in dtEntityInst.AsEnumerable()
on rel.Field<int>("EntityBID") equals entityB.Field<int>("ID")
where entityB.Field<int>("EntityTypeID") == ai.ParentEntityTypeID &&
entityA.Field<int>("EntityTypeID") == ai.EntityTypeID &&
rel.Field<int>("EntityBID") == entityID
select rel.Field<int>("EntityAID")).Single();
DataRow[] attributeValues = dtEntityAttributeInstance.Select(
"EntityID=" + childEntityID + " and AttributeTypeID=" + ai.ID);
if (attributeValues.Length == 1)
{
row[ai.ColumnName] = attributeValues[0]["Value"];
}
PopulateOneToOneEntityAttributes(row, childEntityID, ai.EntityTypeID);
}
}
Yes, all those "dt..." initializations could be removed.
Other Features
Orphan entities and a simple Project - Tasks report are two additional features in the current implementation.
Orphan Entities
The ROP doesn't enforce that an entity instance must be in relationship with another entity instance. Furthermore, if you delete an entity instance,
while any relationship instances are deleted, it can result in orphaned records, so it's useful to be able to inspect orphans. Orphaned entities are easily determined:
protected void InternalLoadOrphanTable()
{
List<int?> entityIDs = (from row in dataSet.Tables["RelationshipInstance"].AsEnumerable()
select row.Field<int?>("EntityAID")).Distinct().ToList();
entityIDs.AddRange((from row in dataSet.Tables["RelationshipInstance"].AsEnumerable()
select row.Field<int?>("EntityBID")).Distinct().ToList());
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataRow[] entityInstances = (from row in dtEntityInstance.AsEnumerable()
where row.Field<int?>("EntityTypeID") == entityTypeID &&
!entityIDs.Contains(row.Field<int>("ID"))
select row).ToArray();
PopulatePhysicalTable(entityInstances);
}
The above code gets all the entity ID's involved in relationships (entity A + entity B) and then returns all the entity instances that are not found in that
list. The resulting row collection are all the entity instances not in a relationship with another entity instance -- orphan entities, in other words.
A simpler UI allows the user to associate these entities:
The above screenshot shows orphan tasks that I might want to associate to a project.
Reports
OK, I really wanted some a "project tasks" report for something else that I'm working on, so I put together a report using OpenXML that generates a Word
document. (This was quite a struggle figuring out how to create a simple document with a style, fortunately there's a lot of examples online.) The queries are quite fun
and illustrate the difference between model data and application data.
We first create the concrete Project table:
EntityProvider epProject = new EntityProvider(dataSet);
epProject.InitializeWithApplicationEntity("Project");
epProject.LoadTable();
And also the concrete Task table:
EntityProvider epTask = new EntityProvider(dataSet);
epTask.InitializeWithApplicationEntity("Task");
epTask.LoadTable();
These are "application" tables (represented abstractly in the dataset by the EntityInstance, EntityType, EntityAttributeInstance and AttributeType physical
tables), whereas the relationship table is a concrete table in the dataset itself:
DataTable dtRel = dataSet.Tables["RelationshipInstance"];
We then iterate through each project:
foreach (var project in
from proj in epProject.DataTable.AsEnumerable()
orderby proj.Field<string>(epProject.GetColumnNameMapping("Name"))
select new
{
ID = proj.Field<int>("ID"),
EntityID = proj.Field<int>("EntityID"),
Name = proj.Field<string>(epProject.GetColumnNameMapping("Name"))})
and then query the relationship for tasks associated to the project:
var tasks =
from r in dtRel.AsEnumerable() where r.Field<int>("EntityBID") == project.EntityID
join t in epTask.DataTable.AsEnumerable() on r.Field<int>("EntityAID") equals t.Field<int>("EntityID")
orderby t.Field<string>(epTask.GetColumnNameMapping("Name"))
select new
{
ID = t.Field<int>("ID"),
Name = t.Field<string>(epTask.GetColumnNameMapping("Name")),
Descr = t.Field<string>(epTask.GetColumnNameMapping("Short Description")) };
The above selects the relationships where the project is the "master" (Entity B) and joins to the task table where the "detail" (Entity A) is a task, thus we
get tasks belonging to a specific project. This query joins both application tables (generated at runtime from the model data) and model tables. There are other ways to skin
this cat (for example, a single query could be written where the tasks are grouped by projects), but I wanted to keep the queries clean so I could more
easily debug them.
Lastly, we iterate the tasks:
foreach (var task in tasks)
{
para = body.AppendChild(new Paragraph());
run = para.AppendChild(new Run());
text = new Text(task.Descr ?? task.Name);
run.AppendChild(text);
}
The result is a docx file that looks like this:
This is a really useful prototype for how a report generator would have to query the model and the application dataset to navigate the entity hierarchy and attributes.
Just for Giggles
The current model entity relationship diagram (ERD) -- this has been horizontally compressed:
The GAPMA ERD, severely compressed, click here for a full size version.
This is not often what you would see in a typical ERD given that there are only 18 entities. I think it illustrates the richness of relationships using ROP.
Conclusion
What continues to surprise me about the ROP concept is how easy it is to add entities and attributes that enhance the target application immediately and in a
productive way. It also really helps in the thinking process of how entities should relate to other entities, which is one of the key points of the
ROP, the Relationship. I also am noticing that the code required for the implementation of specific features is usually comes in small packages (my
organization however is lacking!)
Next Concepts
Possibly unifying the hierarchical layout issues with wrapper code so that a single UI, but for the instantiation of the wrapper, can be used.
Automatic audit trail - tracking changes in attribute values.
Filter Presets
Where and how are filter presets, such as filtering to a specific Project instance, applied? How is this handled when the reference to the entity
being filtered (such as Project) might be several hops away from the current collection of entity instances? For example, if we have the following associations:
Project -> User Story -> Task -> Bug
How do we filter just bugs associated to a Project instance?
Querying
especially queries filtered by fields (like Project) that are determined through associated entities.
Workflow
For example, we might define a workflow as the completion of each steps in Task -> Test -> Review -> Approve.
Rules
As we saw above, there are rules that essentially define a workflow. For example:
We now come across something important: when an association is made (a task is assigned to someone) this should automatically change the state of the
associated Progress entity.
When a Task is completed, the Progress state of the Review associated with the Task can be set to "unassigned" from "not ready." Similarly with the
Approval entity. Conversely, when an Approval entity state is set to "Approved" on a User Story to which it is associated, the Task entities
associated with the User Story can be put into an "unassigned" state. Even more interestingly, you might have a single project lead that does all the
reviews, so he could be automatically assigned and the Progress state changed to "Assigned but work not started."
Some more examples: when all the tasks in a Sprint have been assigned, there might be a rule that changes the Progress state associated with the Sprint.
Same idea with the Iteration. When all tasks are done, the state could change again to "completed."
Cascade Deletes
A flag in the relationship type should be created to determine whether deleting an entity instance should also:
- delete any child instances
- or only child instances referenced only by that relationship
- or additional exceptions
For example:
- If a project is deleted, should all tasks, bugs, iterations, etc. also be deleted?
- If a user story is deleted, should all tasks for that user story be deleted even if the task references a project?
- If a bug is deleted, should all requirements also be deleted even if the requirement has an associated document?
- If a user story is deleted, should all tasks be deleted even if the task belongs to a group?
- What do we do with a group if it's orphaned?
These scenarios should all be handled by explicit, declaratively stated, rules. The salient point here is that we have to consciously think about
these cascade rules rather than blindly make assumptions, and by exposing the rules declaratively, we can modify the behavior of the application without
affecting the code.
Deleting Relationships
There are rules as well to deleting relationships, entities that are orphaned, and so forth.
Changing a Relationship
Similarly, there are rules to changing a relationship and the orphans that a change might create.
Excel Export / Import
It would be useful to export/import to/from Excel for the different model and application datasets.
Clean Up the Pick List Issue
Enough said on this embarrassing issue.
Other Nits
One of the annoying things so far is that when editing the application data, I have to remember to click the Save button to persist the "virtual" table data
back to the ROP entity-attribute tables.
Another nit is that when I edit the schema or the model, I have to re-load the dataset so that the schema and model entity and attributes are reflected in the .NET DataSet.
Also, the orphan entity editor needs to be a derived class of the entity editor - right now it is missing some features that I've added to the entity
editor, and there's a huge amount of code duplication in its behavior.
There is a restriction right now that an entity cannot have two or more attributes of the same type, because this would result in the same name being
mapped to multiple virtual columns in the physical table. You can see this occurring in the nameColumnMap dictionary with the "state" attributes in the 1:1
relationships to entities like Task. This isn't an issue in the 1:1 relationship scenario because the nameColumnMap isn't used in this case, but it
is a bigger issue that needs to be addressed with aliased field names and column headers.
Meeting Classic Relationship Modeling in RDMS's Half Way
Even if you decide to create custom tables and UI's for the final application, the ROP IDE is an excellent modeling tool of your schema for proof
of concept work and to provide the user with an initial tool for exploring use cases--user stories in Agile terminology. This brings up a point I want to
mention: most developers (if not all) will (or even should) balk at the idea of using a single table as a container for all instance entities and their
attributes. Similarly, using a single table as a container for all associations is equally questionable in terms of performance. The first
issue can be addressed by altering the ROP meta-model so that it can work with individual tables, which is fairly easily done and which I want to explore
further in the future. Separate tables with primary keys, unique keys, and other index columns would improve performance. However, in order to take
advantage of the ROP's flexibility, these tables would not have foreign keys, necessitating a separate pooled association table or discrete association
tables. Again, this is something I want to explore in the future to hopefully address performance issues of enterprise-level application data.
That is It For Now Folks
A ridiculously long article, but it takes care of key features that I wanted to implement for this iteration of the ROP IDE.

