This article provides a simple C++ WIN32 tool to perform diffs on arbitrary files. It also features a nice and workable HTML output.
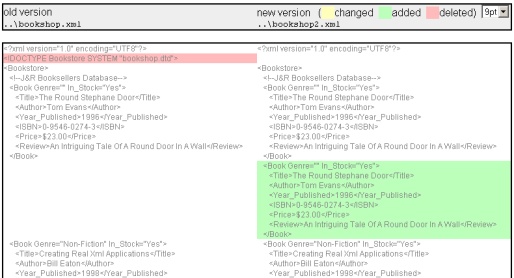
A simple yet useful diff tool with HTML frontend
1. Diff Tools
So you tell me why the hell should I need a diff tool while I already have windiff in the devstudio package? windiff is great when you have nothing else to do your work, but heck this tool leaves a lot to be desired, especially the unproductive way of how the diffs are presented.
After all, if the diffs are so badly presented that you spend time just to figure them out, why shouldn't windiff be upgraded to something better.
That said, if you are interested in merging as well as diffing, you can buy a third party tool such as Araxis[^], or a free tool such as Winmerge[^]. If you are focused on XML content, MS lets you play with the XML diff patch[^], a C#-based diff tool specialized with XML.
I was urged to produce this tool since I have to do it with configuration files that change over time, and I wanted not only something to show me the diffs over time, I wanted it to be nicely integrated in the automation chain. This requirement in fact excluded third parties, because none were providing both the API I needed and the appropriate rendering format. I also loved the idea that diff algorithms and associated techniques were something new to me.
So I took the keyboard and wrote that simple tool. The engine itself took me a couple hours. It means that a diff tool can't be that hard to build. Ok, what do we have then:
- Ability to start the tool by double-click (GUI), with a multiple-file selection
- Ability to start the tool in batch mode
- Fast and simple algorithms
- Custom options such like disabling case sensitiveness, and indent
- Side-by-side HTML rendering, with key diff coloring
- Blank lines used to sync content from both source files
2. Using It
It's important to note that, although the picture above shows a diff between XML files, this tool can be used for ALL possible text file formats you might think of. It's an agnostic diff tool.
2.1. Interactive Mode
Simply double-click on the executable, then choose two files to compare in the multi-selection File dialog. The HTML rendering is automatically displayed by your default browser as soon as the diff engine has finished the job.

2.2. Command Line Mode
In batch mode, the syntax is : diff.exe <file1> <file2> <htmlfile>. For instance, if you have two different versions of Bookshop.xml, namely Bookshop.4.xml and Bookshop.5.xml, then the diff can be built with this command line : diff.exe "c:\...\Bookshop.4.xml" "c:\...\Bookshop.5.xml" diff.html.
For those of you expecting to pipe the output somewhere else, I have provided another project file, diffstdoutput.dsp, which is a console application with stdout output.
2.3. Using Options
By default, the diff tool is case sensitive and also watches indent. Depending on the need, it's of interest to disable either. In interactive mode, just uncheck the boxes. In command line mode, add -c or -i in the command line. In the code itself, you can play around the CFileOptions class which is instantiated at the top-level, and whose behavior is watched by all rows while doing the diff.
3. Compiling It
Although the main diff.dsp project file uses MFC (Open-File dialog, CString, CFile), the diff engine itself does not require it. In fact, I have provided a separate diffengine.dsp project which produces a static library and is only relying on WIN32 (I have added to it my own CString and CFile classes).
Tested on 9X/2K. Both VC++6 and VC++7 workspaces are provided.
4. Developing It
4.1. The Diff Engine
I have always thought that producing a diff was a difficult engineering problem. I was wrong. Against all odds, the design I had on first thought perfectly worked through time. Basically, what I have is a structure which, for each line of both source files, attaches a signature and a status.
The signature is a precalculated token that lets me compare strings from the two source files very fast, without actually going through strcmp stuff or anything that might be wrapped around:
BOOL CFilePartition::PreProcess(CString &szFilename,
CFileOptions &options)
{
ASSERT( !szFilename.IsEmpty() );
if (szFilename.IsEmpty())
{
OutputDebugString("error : empty input filename\r\n");
return FALSE;
}
SetName(szFilename);
SetOptions(options);
CStdioFile f;
if ( !f.Open(szFilename, CFile::modeRead) )
{
TCHAR szError[MAX_PATH];
sprintf(szError, "error : cannot open %s\r\n", szFilename.GetBuffer(0));
OutputDebugString(szError);
return FALSE;
}
CString s;
while ( f.ReadString(s) )
AddString(s);
f.Close();
return TRUE;
}
void CFilePartition::AddString(CString &s, long i)
{
CFileLine *p = new CFileLine();
ASSERT(p);
if (p)
{
m_arrTokens.Add( p->SetLine(s, m_options) );
m_arrLines.Add( p );
}
}
long CFileLine::SetLine(CString &s, CFileOptions &o)
{
m_s = s;
CString so = GetLineWithOptions(s,o);
long nToken = 0;
long nLength = so.GetLength();
TCHAR *lpString = so.GetBuffer(0);
for (long i=0; i<nLength; i++)
nToken += 2*Token + *(lpString++);
return nToken;
}
The status is an enum which is the result of what was found out of the two source files: I want to know what was changed, what was added, and what was deleted.
Once tokens are all ready, what I do is go through all content lines of the first source file, namely by the way the reference file. All lines are matched against the other source file's content. Anytime a line is matched, it is straight forward to know whether the dual line in the other source file is at the same "height" or not. And if it's below, it's because a block has been added. Hence one of the things I am interesting in: the added status for this block. The algorithm is as follows:
BOOL CDiffEngine::Diff( CFilePartition &f1, CFilePartition &f2,
CFilePartition &f1_bis,
CFilePartition &f2_bis)
{
long nbf1Lines = f1.GetNBLines();
long i = 0;
long nf2CurrentLine = 0;
while ( i<nbf1Lines )
{
long nLinef2 = nf2CurrentLine;
if ( f1.MatchLine(i,f2,nLinef2) )
{
if (nLinef2 > nf2CurrentLine)
{
long j = nLinef2 - nf2CurrentLine;
while ( j>0 )
{
f1_bis.AddBlankLine();
f2_bis.AddString( f2.GetRawLine(nLinef2-j), Added );
j--;
}
}
f1_bis.AddString( f1.GetRawLine(i), Normal);
f2_bis.AddString( f2.GetRawLine(nLinef2), Normal);
nf2CurrentLine = nLinef2 + 1;
}
else
{
...
}
i++;
}
return TRUE;
}
Then funny things begin to happen. Matching the other source file against the reference file gives only the first half of the cake. Since both files play a dual role, it is worth taking advantage of relations built out of the other file being now the reference file. Especially when the resulting algorithm cross references alternatively, much like in a DNA shape (or whatever you might think of at the moment). That's how the ... dots above get their implementation:
long nLinef1 = i;
if ( f2.MatchLine(nLinef2, f1, nLinef1) )
{
f1_bis.AddString( f1.GetLine(i), Deleted);
f2_bis.AddBlankLine();
if (nLinef1>i+1)
{
long j = nLinef1 - (i+1);
while ( j>0 )
{
i++;
f1_bis.AddString( f1.GetRawLine(i), Deleted);
f2_bis.AddBlankLine();
j--;
}
}
}
else
{
f1_bis.AddString( f1.GetRawLine(i), Changed);
f2_bis.AddString( f2.GetRawLine(nLinef2), Changed);
nf2CurrentLine = nLinef2 + 1;
}
Please note that within the process, we are adding blank lines in either the reference or the other file anytime a line is flagged as added or deleted. That's because we want to make sure that when the results get presented, we have a perfect row match between the source files. Of course, we are doing our work on virtual file objects, CFilePartition instances, not the actual source files. (left untouched).
That's pretty much all about it. This code is below the 500-line threshold!
Be sure to note that algorithms presented here may have flaws, or may be uselessly lengthy. Especially if you happen to have been working on such algorithms for a while. That's a 1.0 release. Please feel free to contribute.
4.2. The HTML Renderer
I wanted something nice to show, fast to produce, and easy to work with. This simple renderer is simply the result of these requirements.
Being nice means that I wanted windiff to be purged out of my mind for the rest of my life. I have had enough of that horizontal view with overlapped files especially when, adding to the frustration, it's obvious that horizontal views are against intuition when it comes to comparing files. Having a vertical non overlapped view was numero uno requirement, and was easy to come up with by using HTML cell table tags.
Next to it, I wanted it to be produced fast. There is actually not much to say about it. The output of the diff engine is two virtual file instances where the status is known for each line of content of actual files. To produce the diff, I only have to choose colors for a given status and use CSS HTML styles to to override the row formatting. Using styles exemplifies a de facto factorization. Think about it the next time you create ASP code!
In addition, I didn't want to miss the opportunity to let the report be customized. Here is a simple API:
void SetTitles(CString &szHeader, CString &szFooter);
void SetColorStyles(CString &szText, CString &szBackground,
CString &szChanged, CString &szAdded,
CString &szDeleted);
Finally, being easy to work with was a result of the blank lines added to dual files when lines are flagged as added or deleted. Doing so, we ensure that code blocks perfectly match after small or big changes. The resulting diff is easy to browse.
CString CDiffEngine::Serialize(CFilePartition &f1,
CFilePartition &f2)
{
CString s =
"<!DOCTYPE HTML PUBLIC '-//W3C//DTD HTML 4.0 Transitional//EN'>\r\n" \
"<!-- diff html gen, (c) Stephane Rodriguez - feb 2003 -->\r\n" \
"<HTML>\r\n" \
"<HEAD>\r\n" \
"<TITLE> File Diff </TITLE>\r\n" \
"<style type='text/css'>\r\n"\
"<!--\r\n" \
".N { background-color:white; }\r\n" \
".C { background-color:" + m_szColorChanged + "; }\r\n" \
".A { background-color:" + m_szColorAdded + "; }\r\n" \
".D { background-color:" + m_szColorDeleted + "; }\r\n" \
"-->\r\n" \
"</style>\r\n" \
"</HEAD>\r\n" \
"\r\n" \
"<BODY BGCOLOR='#FFFFFF'>\r\n" \
"\r\n" + m_szHeader + \
"<table border=0 bgcolor=0 cellpadding=1 cellspacing=1 width=100%>" \
"<tr><td>\r\n" \
"<table width=100% bgcolor=white border=0 cellpadding=0 cellspacing=0>"\
"\r\n<tr bgColor='#EEEEEE' style='color:0'><td width=50%>" \
"old version</td><td width=50%>new version" \
" (<b style='background-color:" + m_szColorChanged + \
";width:20'> </b>changed " \
"<b style='background-color:" + m_szColorAdded + ";width:20'> </b>"\
"added <b style='background-color:" + \
m_szColorDeleted + ";width:20'> </b>deleted) " \
"<FORM ACTION='' style='display:inline'><SELECT id='fontoptions' " \
"onchange='maintable.style.fontSize=this.options[this.selectedIndex]"\
".value'>" \
"<option value='6pt'>6pt<option value='7pt'>7pt<option value='8pt'>8pt" \
"<option value='9pt' selected>9pt</SELECT>" \
"</FORM></td></tr>\r\n" \
"<tr bgColor='#EEEEEE' style='color:0'><td width=50%><code>" \
+ f1.GetName() + "</code></td><td width=50%><code>" + \
f2.GetName() + "</code></td></tr>" \
"</table>\r\n" \
"</td></tr>\r\n" \
"</table>\r\n" \
"\r\n" \
"<br>\r\n" \
"\r\n" ;
long nbLines = f1.GetNBLines();
if (nbLines==0)
{
s += "<br>empty files";
}
else
{
s += "<table border=0 bgcolor=0 cellpadding=1 cellspacing=1 width=100%>"\
"<tr><td>" \
"<table id='maintable' width=100% bgcolor='" + m_szColorBackground +\
"' border=0 style='color:" + m_szColorText + \
";font-family: Arial, Helvetica, sans-serif; font-size: 9pt'>\r\n";
}
char *arrStatus[4] = {
"",
" class='C'",
" class='A'",
" class='D'" };
CString sc;
for (long i=0; i<nbLines; i++)
{
sc += "<tr><td width=50%" + CString(arrStatus[ f1.GetStatusLine(i) ]) +
">" + Escape(f1.GetRawLine(i)) + "</td>";
sc += "<td width=50%" + CString(arrStatus[ f2.GetStatusLine(i) ]) +
">" + Escape(f2.GetRawLine(i)) + "</td></tr>";
}
s += sc;
if (nbLines>0)
s += "</table>" \
"</td></tr></table>\r\n";
s += m_szFooter + "</BODY>\r\n" \
"</HTML>\r\n";
return s;
}
CString CDiffEngine::Escape(CString &s)
{
CString o;
long nSize = s.GetLength();
if (nSize==0) return CString(" ");
TCHAR c;
BOOL bIndentation = TRUE;
for (long i=0; i<nSize; i++)
{
c = s.GetAt(i);
if (bIndentation && (c==' ' || c=='\t'))
{
if (c==' ')
o += " ";
else
o += " ";
continue;
}
bIndentation = FALSE;
if (c=='<')
o += "<";
else if (c=='>')
o += ">";
else if (c=='&')
o += "&";
else
o += c;
}
return o;
}
4.3. Wrap Up
Finally, here is how to use the API:
CString szFile1 = "...";
CString szFile2 = "...";
CString szOutfile = "...";
CFileOptions o;
if (!bCaseOption) o.SetOption( CString("case"), CString("no") );
if (!bIndentOption) o.SetOption( CString("indent"), CString("no") );
CFilePartition f1;
f1.PreProcess( szFile1, o );
CFilePartition f2;
f2.PreProcess( szFile2, o );
CFilePartition f1_bis, f2_bis;
CDiffEngine d;
d.Diff(f1,f2,f1_bis,f2_bis);
d.ExportAsHtml(szOutfile, d.Serialize(f1_bis, f2_bis));
5. Update History
- 16th Feb, 2003 - Initial release
- 23rd February, 2003 - Added:
- Diff options (
CFileOptions class): case sensitiveness can be disabled, as well as indent - Added the ability to use
stdout to pipe the output somewhere else - Dynamic font size selection
- 10th May, 2003 - Added the following features:
- Folder support: difftool now builds a report of entire folders. The use case is the ability to track changes by comparing the last modified dates of each file pairs.
- Added line numbers, changed the font for better readibility
License
This article has no explicit license attached to it, but may contain usage terms in the article text or the download files themselves. If in doubt, please contact the author via the discussion board below.
A list of licenses authors might use can be found here.

