 | The Document Store Database Engine |
Preface
The code for RaptorDB is on github https://github.com/mgholam/RaptorDB-Document, I will be actively maintaining and adding features to this project as I believe very strongly in it. I will keep this article and the source code in sync.
RaptorDB is also on nuget : PM> Install-Package RaptorDB_doc
Introduction
This article is the natural progression from my previous article about a persisted dictionary to a full blown NoSql document store database. While a key/value store is useful, it's not as useful to everybody as a "real" database with "columns" and "tables". RaptorDB uses the following articles:
Some advanced R&D (for more than a year) went into RaptorDB, in regards to the hybrid bitmap index. Similar technology is being used by Microsoft's Power Pivot for Excel and US Department of Energy Berkeley labs project called fastBit to track terabytes of information from particle simulations. Only the geeks among us care about this stuff and the normal person just prefer to sit in the Bugatti Veyron and drive, instead of marvel at the technological underpinnings.
To get here was quite a journey for me as I had to create a lot of technology from scratch, hopefully RaptorDB will be a prominent alternative, built on the .net platform to other document databases which are either java or c++ based.
RaptorDB puts the joy back into programming, as you can see in the sample application section.
Why?
The main driving force behind the development of
RaptorDB is making the developer's and support jobs easier, developing software products is hard enough without complete requirements which becomes even harder when requirements and minds change as they only do in the real world. The benefits of
RaptorDB can be summarized as :
- Development easier : writing less code means less bugs and less testing.
- Making changes faster : no need to edit database schema's with all the hassle of using other tools.
- Knowledge requirements lowest : you don't need to know the SQL language, indexing techniques, configuration parameters, just plain old c# (vb.net) will do.
- Maintenance simpler : changes are isolated so you are free to make them without worrying about breaking things elsewhere.
- Setup time & cost minimal : to get up and running you just need the .net framework and an IDE, no setting up database servers, running scripts, editing config files etc. (even on netbooks).
- Very fast execution : all this is done with speeds that put expensive servers to shame on mere laptops and netbooks.
Why another database?
Some people have said why create another database while you can use what exists or just write a driver in .net for the "X" database, to this I answer the following:
- I believe that you can do a better job in pure .net like operating at 80% hard disk speed.
- Writing drivers and marshaling across process boundaries can have a performance hit.
- Implementing fundamental algorithms is an educational process.
- We have to push the boundaries of what is possible too see that the only limitation is our imagination and resolve.
- Someone will find it useful and who knows it might become one of the "big boys", they all started as "little boys" anyway.
Possible Uses
You can use the Document Store version of RaptorDB in the following scenarios:
- The back-end store for your web based :
- Forums
- Blogs
- Wikis
- Content management systems
- Web sites
- Easily build a SharePoint clone.
- Stand-alone applications that require storage ( no more installing SQL Server for a phone book app).
- Real world business applications (with caveats).
How we use data
Before getting to the heart of document databases, let us examine how we use data in the first place as this will give us a better understanding of were we stand and how we can better utilize non relational technology.
- Viewing lists of things (list of customers, products, inventory transaction,...)
- Filtering lists of things (customer in country X)
- Aggregating lists of things (sum of qty in stock)
- Searching for things (much like filtering but may span multiple lists)
- Viewing a document (open the invoice number 123)
- Pivoting lists or building intelligence reports
Except for reporting all the others are essentially just the following :
- Filtering lists
- Aggregating lists
What is a Document Store database?
Document databases or stores are a class of storage systems which save the whole object hierarchy to disk and retrieve the same without the use of relational tables. To aid the searching in such databases most Document store databases have a map function which extracts the data needed and saves that as a "view" for later browsing and searching. These databases do away with the notion of transactions and locking mechanism in the traditional sense and offer high data through-put and "eventually consistent" data views. This means that the save pipeline is not blocked for insert operations and reading data will eventually reflect the inserts done ( allowing the mapping functions and indexers time to work).
There is some very appealing consequences for going this way:
- Schema less design (just save it mentality) :
- You don't need to define tables and columns before hand.
- Your application can evolve and expand as needed without schema pains.
- Operational speed :
- You read the data as it was saved the first time, so you can read in one disk operation and have the whole object hierarchy without multiple reads to tables and patching an object with data retrieved.
- Does away with locks and deadlocks, so its much faster and scales better.
- Simplicity in application design :
- The data access layer for the application is orders of magnitude simpler.
- Changes to the application can be made anytime and on-site to the customers requirements.
- Lower development costs : Simpler and less code means development and testing is faster, easier with lower knowledge requirements for developers and maintainers.
- Historical data : Ability to have history of changes (essential for business applications).
- Easy and simple replication : Because the data is already encapsulated (the original document) replication is simple and painless as you just transfer the document and save it at the other end, without the pains of inconsistent tables like relational models.
- Operational cost savings : not requiring RDBM server licenses could offer considerable savings especially for web hosted and cloud based applications.
Foul ! the relational purists cry...
Most people who have worked with relational database will scream in horror here, at the thought of data being
eventually consistent and not having tables.
Most businesses have a lot of flexibility in regards to data validity and not all data items require the same granularity and in which case they have processes in place for "exceptional" cases and work perfectly fine.
For example if you have sold 10 items and go to the warehouse and see that the items were damaged in a the rain last night under a leaky roof, the business tries to find another 10 items otherwise calls the customer and explains their order might be delayed. So having an up to the millisecond record of the inventory is good, but the business can do fine without it.
This mindset takes a bit of getting used to for people who have been under the influence of "relational database" thinking and have not been exposed to actual running businesses, and they will freak out at the thought. Much of what has been drilled into us for the past 40 or so years since the advent of relational model has been a notion of data normalization which forces the breaking up of data in to discrete chunks of the same things. This was primarily done for the reason of shortage of data storage capacity and has stuck ever since, which forces a huge burden on the poor database engines to optimize joins and query plans to get back to what was put in, in the first place. Also the notion of normalization is a misnomer as you are perfectly allowed to have duplicated data as long as you ensure that they are in sync with one another.
Most of the relational model thinking has changed in recent years as the "Database Server" is not stand-alone and is part of the application and is accessed via the application and not called directly. This is the tiered mindset in application development which creates a layer for data access which can be isolated and controlled easily. This change, releases the burden of security settings, normalization requirements etc. from the RDBM server, as all this is done from the application service front end, case in point would be an API for Facebook which abstracts the usage of the site and you don't access tables directly. So much of what was built into RDBM servers goes unused for modern applications, and you can get away with embedding the database within the application as a layer not a separate process.
Is it for everybody?
With all the benefits stated, documents store databases are not for every body and every situation. The main point in divergence is if you require up to the millisecond data consistency across everything ( the cornerstone RDBM systems). If data validity is not an issue or your perfectly fine having the result valid at a certain point in time like the inventory count is valid for today at 9:00am then in my experience and you can get away with it for most web based application and probably 90% of business applications (this does not mean that these databases are consistent after hours but typically seconds) .
If your not willing to sacrifice this level of timed concurrency, then NoSql / document store databases are not for you. In my experience not being willing, is more a psychological barrier of the developers/designers than a technical requirement of the application and users.
Features
RaptorDB has been built with the following features in mind:
- Core Features :
- Built on the algorithms of persisted dictionary version of
RaptorDB (so you get all the benefits of that). - Built on pure .net so there is considerable performance benefits of not marshaling data across process boundaries via drivers.
- Tiny size 194 KB (even smaller than the great Sqlite).
Strings are stored in UTF8 or Unicode format for views.- Documents can be stored as ASCII JSON, the JSON standard already encodes unicode in ASCII format or as Binary JSON for speed.
- Embedded design.
- Compressed data transfer over the network.
- Transaction support added in v1.6.
- View Storage :
- You don't need to specify column widths for
string columns and RaptorDB can handle any size string (indexing is however limited to max 255 bytes for normal string columns). - Views (output from map functions) save data as binary not JSON ( much faster for indexing).
- Primary list/View on object type definition for immediate access to the object saved (immediate call to a primary map function)
- Document Storage :
- Ability to save
byte[] data as well so you can save files etc. ( these are saved in a separate storage file).
- Indexing Engine :
- Support for special hybrid bitmap index for views using Word Aligned Hybrid (WAH) compression.
- Automatic indexing of views (self maintained no administration required).
- All columns are indexed with the
MGIndex. - Fast full text search support on
string columns (you choose normal or full text search of strings in your view) .
- LINQ Query Processor :
- Query Filter parser with nested parenthesis,
AND and OR expressions.
- Map Function Engine :
- Map functions are compiled .net code not JavaScript like competitors ( order of magnitude faster, see the performance tests).
- Map functions have access to an API for doing queries and document fetches (you can do complex business logic in them).
- Map functions type check the data saved, which makes reading the data easier and everything more consistent.
Limitations
The following limitations are in this release:
- Requires at least .net 4 (uses the Task library).
- Document and View Item count is limited to 4 billion items or
Int32. - This release is not code backward compatible with the key/value store version.
Aggregation on views.Standalone service version is not available at the moment.- Revision checking on documents is not supported at the moment.
- Sharding /
Replication is not supported at the moment. - Query filters only work with literal right hand sides (e.g.
Name='bob' not StatusColumn > LastStatusColumn referencing another column) In transaction mode, currently the active thread does not see it's own data changes.
Rules
To help you work with RaptorDB better, below are some rules which will help you:
- You must have a Primary View for each type you are going to save.
- If a view has
ConsistentView = True it will act like a Primary View. - If a Primary View has
TransactionMode = True then all operations on it and all views associated with it will be in a transaction and will Rollback if any view fails. BackgroudIndexing is turned off in transaction mode.- Queries in a transaction will only see their own updates.
The Competition
There are a number competing storage systems, a few of which I have looked at, are below:
- MongoDB (c++): Great database which I love and is the main inspiration behind RaptorDB, although I have issues with its 32bit 4Gb database size limit and the memory map file design which could potentially corrupt easily. (Polymorphism has a workaround in mongodb if anyone wants to know).
- CouchDB / CouchBase (erlang): Another standard in document databases. The design is elegant.
- RavenDB (.net): Work done by Ayende which is a .net document database built on the Windows ESENT storage system.
- OrientDB (java) : The performance specs are impressive.
Performance Tests
The test were all done on my notebook which is a AMD K625 1.5Ghz CPU, 4Gb DDR2 Ram, WD 5400rpm HDD, Win7 Home 64bit , Windows rating of 3.9.
Javascript vs .NET compiled map functions
Most of the document databases today use the javascript language as the language to write map functions, in RaptorDB we are using compiled .net code. A simple test of the performance benefits of using compiled code is the following example from the
http://www.silverlight.net/content/samples/sl2/silverlightchess/run/default.html site which is a chess application, this test is certainly not comprehensive but it does show a reasonable computation intensive comparison :
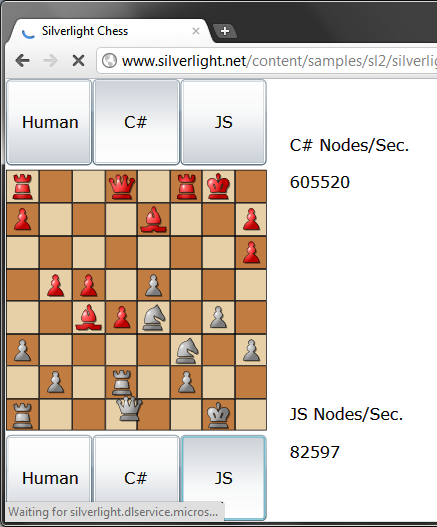
As you can see even in Google Chrome (V8 javascript engine) which arguably is the fastest javascript processor currently, is beaten by the .net code (in Silverlight, full .net version could be faster still) by a factor of about 8x.
With this non scientific test it's unreasonable to use anything but compiled code for map functions.
Insert object performance
Depending on the complexity of you documents and the views defined you can expect around 10,000 docs/sec throughput from
RaptorDB (based on my test system).
Query Performance
The real test to validate the use of a NoSql database is the query test, you have put the data in, how fast is it getting it out. RaptorDB will output query processing times to the log file, as you can see from the samples below most of the query time is taken by the actual fetching of the data and the query plan is executed in the milliseconds range (the power of the bitmap index).
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 40.0023
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 33.0019
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 300
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 1.0001
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 469.0268
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 25875
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 4.0002
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 6.0003
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 500
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 0
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 677.0387
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 50000
If you want to torture someone, make them write a LINQ Provider!
It took me around a month of intense research, debugging and tinkering to get my head around the LINQ provider interface and how it works, while the title of this section is a bit harsh but I hope it conveys the frustration I felt at the time.
To be fair what emerged is very clean, concise and elegant. Admittedly it is only the Expression evaluation part of LINQ and is a fraction of what you have to go through for a full LINQ provider. This was all I needed for RaptorDB so I will try to explain how it was done here for anybody wanting to continue as resources are very rare on this subject.
For RaptorDB we want a "where" clause parser in LINQ which will essentially filter the view data and give us the rows, this is done with the following command :
int j = 1000;
var result = db.Query(typeof(SalesInvoice),
(SalesInvoice s) => (s.Serial > j && s.CustomerName == "aaa")
);
The main part we are focusing on is the line :
(SalesInvoice s) => (s.Serial > j && s.CustomerName == "aaa")
From this we want to parse the expression which reads : given the SalesInvoice type (used for denoting the property/column names, and serves no other purpose) filter where the [serial number is greater than j and the customer name is "aaa"] or the count is greater than zero. From this the query engine must determine the "column names" used and fetch them from the index file and get the associated values from that index and apply logical arithmetic on the results to get what we want.
The quirks of LINQ parsing
There are two quirks in parsing LINQ queries :
- Variables (the j in the above example) are replaced with a compiler placeholder and not the value.
- All the work is done in the VisitBinary method, for logical expression parsing and clause evaluation, so you have to be able to distinguish and handle them both.
How the LINQ parser works in RaptorDB
In RaptorDB we want to be able to extract and query the index for each clause in the filter expression based on the order and logic of the expression. Because the indexes are built on the WAHBitArray the result will be a WAHBitArray. All this is done in the following very small code (compared to writing a language parser) :
delegate WAHBitArray QueryExpression(string colname, RDBExpression exp, object from);
internal class QueryVisitor : ExpressionVisitor
{
public QueryVisitor(QueryExpression express)
{
qexpression = express;
}
public Stack<object> _stack = new Stack<object>();
public Stack<object> _bitmap = new Stack<object>();
QueryExpression qexpression;
protected override Expression VisitBinary(BinaryExpression b)
{
this.Visit(b.Left);
ExpressionType t = b.NodeType;
if (t == ExpressionType.Equal || t == ExpressionType.LessThan || t == ExpressionType.LessThanOrEqual ||
t == ExpressionType.GreaterThan || t == ExpressionType.GreaterThanOrEqual)
_stack.Push(b.NodeType);
this.Visit(b.Right);
t = b.NodeType;
if (t == ExpressionType.Equal || t == ExpressionType.NotEqual ||
t == ExpressionType.LessThanOrEqual || t == ExpressionType.LessThan ||
t == ExpressionType.GreaterThanOrEqual || t == ExpressionType.GreaterThan)
{
object lv = _stack.Pop();
ExpressionType lo = (ExpressionType)_stack.Pop();
object ln = _stack.Pop();
RDBExpression exp = RDBExpression.Equal;
if (lo == ExpressionType.LessThan)
exp = RDBExpression.Less;
else if (lo == ExpressionType.LessThanOrEqual)
exp = RDBExpression.LessEqual;
else if (lo == ExpressionType.GreaterThan)
exp = RDBExpression.Greater;
else if (lo == ExpressionType.GreaterThanOrEqual)
exp = RDBExpression.GreaterEqual;
_bitmap.Push(qexpression("" + ln, exp, lv));
}
if (t == ExpressionType.And || t == ExpressionType.AndAlso ||
t == ExpressionType.Or || t == ExpressionType.OrElse)
{
WAHBitArray r = (WAHBitArray)_bitmap.Pop();
WAHBitArray l = (WAHBitArray)_bitmap.Pop();
if (t == ExpressionType.And || t == ExpressionType.AndAlso)
_bitmap.Push(r.And(l));
if (t == ExpressionType.Or || t == ExpressionType.OrElse)
_bitmap.Push(r.Or(l));
}
return b;
}
protected override Expression VisitMethodCall(MethodCallExpression m)
{
string s = m.ToString();
_stack.Push(s.Substring(s.IndexOf('.') + 1));
return m;
}
protected override Expression VisitMember(MemberExpression m)
{
var e = base.VisitMember(m);
var c = m.Expression as ConstantExpression;
if (c != null)
{
Type t = c.Value.GetType();
var x = t.InvokeMember(m.Member.Name, BindingFlags.GetField, null, c.Value, null);
_stack.Push(x);
}
if (m.Expression != null && m.Expression.NodeType == ExpressionType.Parameter)
{
_stack.Push(m.Member.Name);
return e;
}
return e;
}
protected override Expression VisitConstant(ConstantExpression c)
{
IQueryable q = c.Value as IQueryable;
if (q != null)
_stack.Push(q.ElementType.Name);
else if (c.Value == null)
_stack.Push(null);
else
{
_stack.Push(c.Value);
if (Type.GetTypeCode(c.Value.GetType()) == TypeCode.Object)
_stack.Pop();
}
return c;
}
}
Most of the work is done in the VisitBinary method (for evaluating logical [&& || ] operations and clauses [b>3] ) so to distinguish the two a stack is used store the clause values for further processing. VisitBinary will be called recursively for left and right sides of expressions so a stack of bitmap is also required for aggregating the results of the expression.
The constructor to the class takes two delegates which are supplied by the caller for handles to the underlying indexes which this class calls when a binary clause is completely parsed. The results are push onto the bitmap stack.
The VisitMember method is responsible for replacing the compiler generated code for constant values with the appropriate value ( the j in the above example).
The rest of the code is generally for extracting the "column names" without the prefixes (s.Serial -> Serial etc.).
A sample application
To work with RaptorDB all you need to do is follow these steps :
- Define your Entities (plain c# objects) as you would doing domain driven development.
- Create a Primary View for your base Entities.
- Register your views with RaptorDB.
- Save and query your data.
- Add new views based on your requirements.
As you will see below this is so easy and simple that it just happens and you don't need to learn anything new or worry about configurations or breaking things at runtime as the compiler will catch your error at compile time.
A great feature is the total absence of anything SQL related, the associated schema pains and having to switch to a database management product to define and check tables and columns as everything is in your source file.
1. Creating Entities
The first thing you should do is define your entities or data classes (referred to as domain driven development), these are plain c# (vb.net) classes or POCO's like the following :
public class LineItem
{
public decimal QTY { get; set; }
public string Product { get; set; }
public decimal Price { get; set; }
public decimal Discount { get; set; }
}
public class SalesInvoice
{
public SalesInvoice()
{
ID = Guid.NewGuid();
}
public Guid ID { get; set; }
public string CustomerName { get; set; }
public string Address { get; set; }
public List<LineItem> Items { get; set; }
public DateTime Date { get; set; }
public int Serial { get; set; }
public byte Status { get; set; }
}
There is nothing special about the above other than the lack of anything extra you need to do like adding attributes etc. (even Serializable) as they are not needed.
2. Creating Views
Next you create your primary view for your entities as follows :
public class SalesInvoiceView : View<SalesInvoice>
{
public class RowSchema
{
public NormalString CustomerName;
public DateTime InvoiceDate;
public string Address;
public int Serial;
public byte Status;
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.Mapper = (api, docid, doc) =>
{
api.Emit(docid, doc.CustomerName, doc.Date, doc.Address, doc.Serial, doc.Status);
};
}
}
This is pretty straight forward also.
- This view is for a
SalesInvoice object type. RowSchema is a class which defines the columns for this view
- You can name this class anything as long as you register it with the Schema property
- All value types are supported (
int, string, decimal etc.) NormalString is a special type which instructs the indexer to index this column as a string so you will have to specify all the string when querying.- If you specify a string property then RaptorDB will do full text indexing on that column, so you can search for words within that column when querying.
BackgroundIndexing controls how the indexer does it's work on this view (i.e. block saves until each document is indexed when false).AddFireOnTypes controls when this view is called based on the input document typeMapper is the map function which will populate this view (i.e. extract information from the input document), you can add logic here if you need it. The order of the items must be the same as the schema you defined.- With
api you can Fetch a document, log debug information and Query another view.
3. Registering Views
Registering a view is as simple as :
rap.RegisterView(new SalesInvoiceView());
RaptorDB will do some checks on your view and if everything is fine it will return true, which means you are good to go.
4. Saving and querying data
Now you can use RaptorDB and save documents as follows :
var inv = new SalesInvoice()
{
Date = FastDateTime.Now,
Serial = i % 10000,
CustomerName = "me " + i % 10,
Status = (byte)(i % 4),
Address = "df asd sdf asdf asdf"
};
inv.Items = new List<LineItem>();
for (int k = 0; k < 5; k++)
inv.Items.Add(new LineItem()
{ Product = "prod " + k, Discount = 0, Price = 10 + k, QTY = 1 + k });
rap.Save(inv.ID, inv);
Querying is as simple as writing LINQ predicates like the following:
var q = rap.Query(typeof(SalesInvoice),
(SalesInvoice s) => (s.Serial < j) && (s.Status == 1 || s.Status == 3));
q = rap.Query("SalesItemRows",
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
As you can see you can call the query in 2 ways by specifying the type of the view (or type of the document type for primary views) or by calling the string name of the view.
Screen Shots
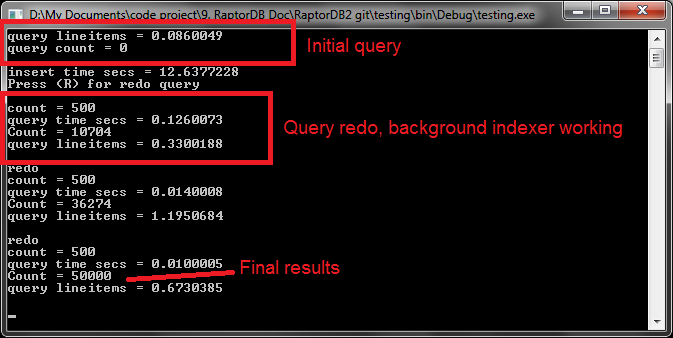
From the below image you can see the test application doing its work. RaptorDB was configured to do background indexing, so 100,000 documents were inserted in 12 secs and the primary view was populated (the query results for 500 items) and the background indexer is working on populating the other view defined, which after a couple of queries shows the final results of 50,000 items.
How It Works
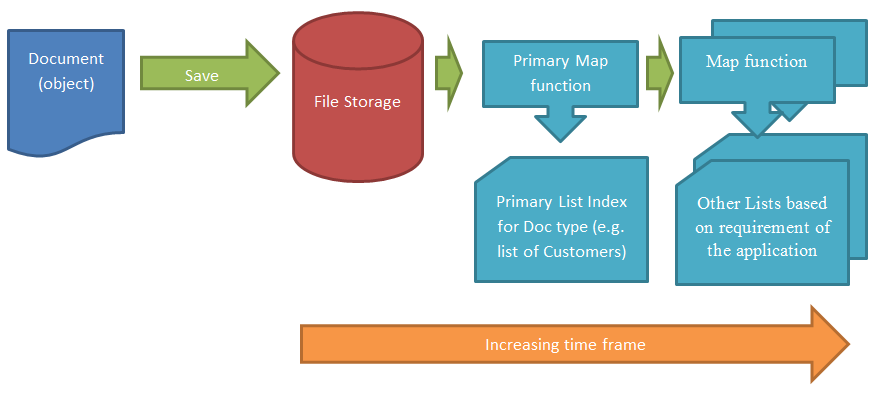
The diagram above shows a high level view of how RaptorDB works, a document is first inserted into the storage file then immediately a primary map function is called to generate a primary view for the document at which point control returns to the calling method. After a timer has elapsed other map functions are called to generate other views for that document.
There some term which you must be aware of when using RaptorDB document data store, these are the following:
- Document : is an object/entity which gets serialized as JSON
- DocID : is a Guid which uniquely identifies a document and must be given with the document
- View : is a like a standard database table
- Map Function : is a function that takes a document and emits values from that document into a view
- Index : is used to retrieve information when querying views.
What's a View?
A view is a list of values from a document which is bound to that document via a GUID property from that document. You can imagine a view as a 2 dimensional image of a multi dimensional document object usually created for a specific purpose.
For example if you have a invoice document one view would be a list of those invoices for the purpose of browsing them like:
{ invoice GUID, date, invoice number, status, salesman name }
Another view would be like below for the accounting department :
{ invoice GUID, date, total sales amount, total sales discounts, salesman name, customer name }
What's a map function?
A map function is a piece of code you write to take a document object and "emit" a list of values usually from that document (your are free to emit anything, but most times it will be somehow related to that document) to a "view".
What's a "Primary View" for?
A primary view is a view which will get it's map function called immediately after a document save and there is no delay. This is so you can get a list of those documents immediately and don't have to wait. To show the importance of this take the following example :
You have a sales application and sales persons add their invoices, you would want to see these invoices after a save for the simple reason that you want to start the sales workflow process on that item, so you have to see it and you don't want to wait for a map function to fire "eventually".
Obviously the map function should be minimal and only show what is needed, you can go overboard and emit a lot of data for this list but you would loose performance.
The Main Cast of Characters in RaptorDB
RaptorDB has the following parts:
- RaptorDB main interface : what your code sees and the main loader of other parts.
- Storage File : a fast and multi-threaded file storage mechanism used for both documents storage and view data.
- View : see below
- ViewManager : see below
- ViewHandler : see below
ViewHandler
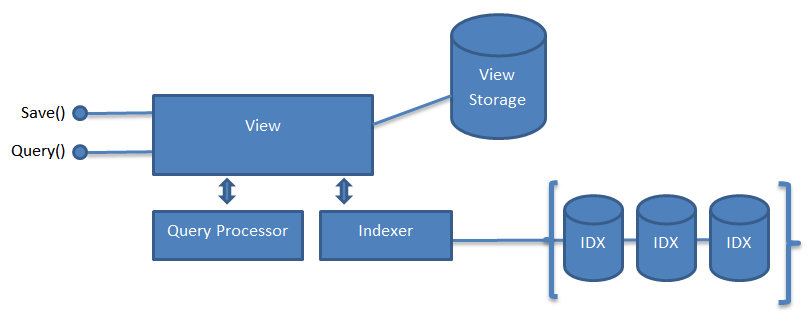 The View is the responsible for
The View is the responsible for
- Storing view data
- Indexing columns based on query use
ViewManager
The View Manager is responsible for the following :
- Loading and creating Views
- Compiling view map functions.
- Keeping track of mappings between the object types and views, or which view to send the object for inserting/updating.
- Keeping track of last documents sent to views and the storage record numbers.
- Periodic updating the views with new documents coming in
Query Executor
The query executor will do the following :
- Parse the LINQ expression.
- Check the column names exist in the view schema, validation error will be caught here.
- Check to see if indexes exist for the columns used in the filter
- Extract the bitmap indexes needed.
- Extract the Deleted records bitmap.
- Execute the filter and fetch the view rows from the view storage.
RaptorDB Setup
For RaptorDB to function you must follow these steps:
- Define a primary view for objects which will allow immediate access to inserted objects via a list, inherited objects are supported for simplicity so you can define one for the base class.
The Save Process
The save process follows the following steps:
GetPrimaryListForType() : will try to get the primary map function for the object type and recurs the hierarchy until found.SaveData() : saves the data to storage file, creates log entry in the log file and in memory log, the background indexer will process the log.SavePrimaryView() : will call the primary map function for this type.SaveInOtherViews() : will save to any other view that is defined.
The process will fail to save if any one of the steps fail.
Views and Map functions
A View is a list of data items from an object structure similar to a collection of rows in the table model. Map functions are responsible for taking an object and generating rows for views.
The premise behind map functions is that you precompute "queries" before-hand and just fetch the results when needed.
The map engine will do the following:
- Find the last DocID processed and increment.
FindMapFunctionsForType() : a list of map functions to execute for this object
ExecuteMapFunction() : on the object and retrieve the new view rows with a reference to the DocID.DeleteFromView(DocID) : flag delete the old values for DocID.InsertView(newData) : add the new data from the map function to the view.
- Find the next DocID and recurs the process.
The power of MGIndexs
Bitmap indexes are a form of index which stores the existence of a value in rows, in a series of bits. For example if you have a million records and you are searching for 'bob' in the Name column, then the b+tree for column Name might look like the picture below, and when you find the 'bob' in the leaf nodes you will get a BitArray representing the existence of 'bob' in that column indexed by record number. So if bit 3 of that BitArray is 1 then 'bob' is in the 3rd row etc. It is easy to see that this is extremely compact and efficient storage and retrieval mechanism.
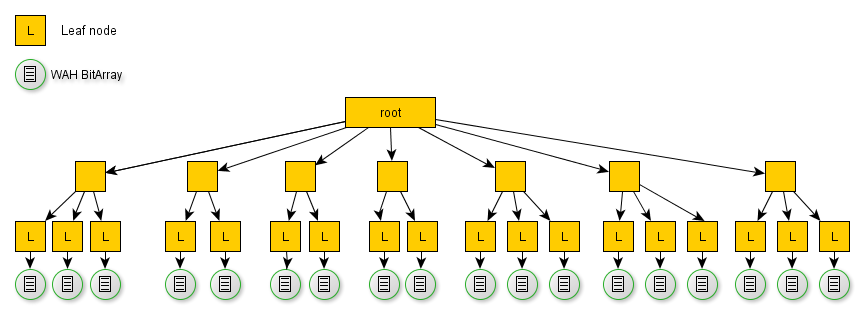
* The above picture shows a b+tree/bitmap index structure not the MGIndex which uses a dictionary, but the principle is the same.
The real power is shown in the example below where you want to query for the following "Name='bob' and Code=between(1,3)", the query processor will take the filter, parse the values for that filter and generate an execution plan like below:
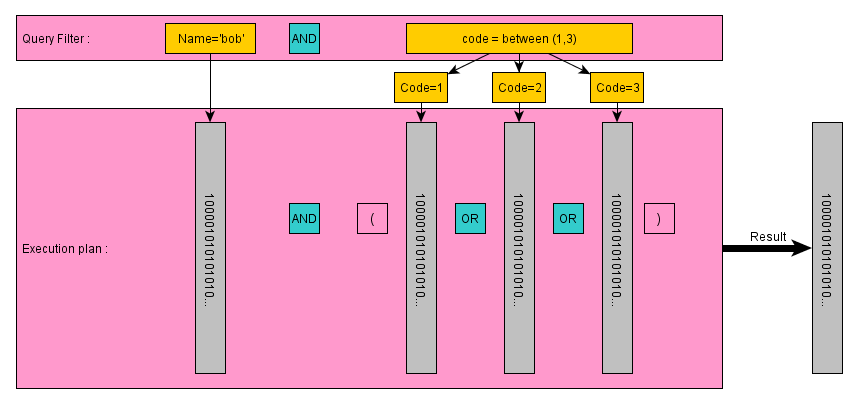
As you can see from the above diagram, the execution plan is a series of BitArrays and all you have to do to get the result is follow the bit arithmetic logic based on the parsed filter and {AND ,OR, NOT} the BitArrays together. These operations are typically in the sub millisecond range even for millions or rows in your database. The result is an position indexed row finder to the row contents which you read off disk, and send to the caller where 1 indicates read the row and 0 means skip the row contents (i.e. 100001... -> read record numbers :1,6,...)
Full Text Search
For
string columns
RaptorDB supports full text search for finding words in rows. To do this
RaptorDB uses the technology built into
hOOt the full text search engine.
On the cutting room floor
The following features were cut and might be incorporated in the next version:
- Paging of results.
LINQ based aggregation (sum, count, ...).- Compression support in storage.
- Usage statistics and monitoring information.
- Query caching.
View schema changes.- Revision checking for documents
Closing Remarks
This is a work in progress, I will be happy if anyone wants to join in.
Appendix v1.2
Some major features were added in this release so here they are:
- View Versioning
- Full text indexing attribute
- String queries
- Quering view types
View Versioning
In this version you can change the view schema or properties, and also add new views to existing documents and have the engine rebuild the view. This is controlled via a Version property in your view definition.
The responsiblity of incrementing this version number is up to you and you can decide when to do so and when it would make sense. RaptorDB will just check the verison numbers and act accordingly.
Full Text Indexing
A breaking change was the removal of the NormalString type in the schema of your view and replacing it with string and a [FullText] attribute, which is much more simpler and user friendly.
public class RowSchema
{
[FullText]
public string CustomerName;
public DateTime InvoiceDate;
public string Address;
public int Serial;
public byte Status;
}
String Queries
RaptorDB can now parse string LINQ queries and give you the results. This can be seen in the updated console application. You would probably want to stick to LINQ in your source code, but this might be useful if you need your users to generate filters in an UI for example.
This feature will be more prevalent in the server version as LINQ does not serialize accross boundries.
An interesting feature is that you can get near SQL syntax like :
var q = rap.Query(typeof(SalesItemRows),
"product = \"prod 1\" or product = \"prod 3\""));
Where column can be non cased and you can use single '=' and have 'or' instead of c# style '||' etc.
Quering View Types
You can now give the view type to the Query function for querying.
var q = rap.Query(typeof(SalesItemRows),
((LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
Appendix v1.3
Some major features were added in this version:
- Result Schema Rows
- Windows Query App
- Client side LINQ aggregate
- api.EmitObject
Windows Query App
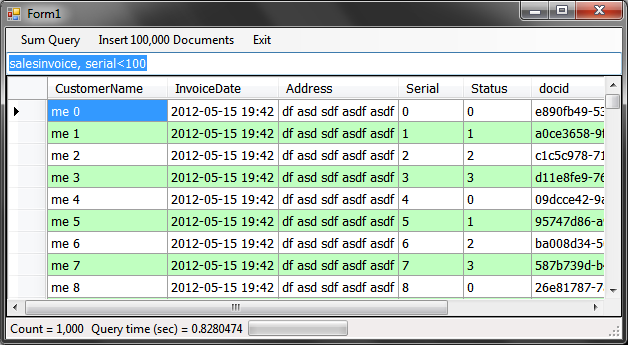
A windows application project was added to show case the data binding capabilities of RaptorDB. You can do the same functions of the console app but with visual feedback. To query the views just enter your view name and the query string in the text box and press enter.
In the menu a client side sum has been added which will give you the following results.
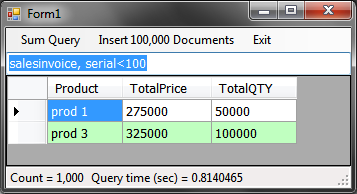
Client side LINQ aggregates
You can do client side aggregate queries like the following which is very powerful.
var q = rap.Query(typeof(SalesItemRowsView), (LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
List<SalesItemRowsView.RowSchema> list = q.Rows.Cast<SalesItemRowsView.RowSchema>().ToList();
var e = from item in list group item by item.Product into grouped
select new { Product = grouped.Key,
TotalPrice = grouped.Sum(product => product.Price),
TotalQTY = grouped.Sum(product => product.QTY)
};
The main point in the above is the Cast method which will give you the types so you can sum on.
api.EmitObject
To help you write less code you can use the api.EmitObject method in your mapper code which will match the object given to the view schema column names, you must make sure the names match.
this.Mapper = (api, docid, doc) =>
{
if (doc.Status == 3 && doc.Items != null)
foreach (var item in doc.Items)
api.EmitObject(docid, item);
};
Appendix v1.4
A lot of major changes were made in this release, some of which are :
Parameters
Here are some of the parameters in the Globals.cs file which control the workings of RaptorDB.
| Parameter | Default | Description |
<code>BitmapOffsetSwitchOverCount | 10 | Switch over point where duplicates are stored as a WAH bitmap opposed to a list of record numbers |
<code>PageItemCount | 10,000 | The number of items within a page |
<code>SaveIndexToDiskTimerSeconds | 60 | Background save index timer seconds ( e.g. save the index to disk every 60 seconds) |
<code>DefaultStringKeySize | 60 | Default string key size in bytes (stored as UTF8) |
<code>FlushStorageFileImmetiatley | false | Flush to storage file immediately |
<code>FreeBitmapMemoryOnSave | false | Compress and free bitmap index memory on saves |
SaveAsBinaryJSON | true | Save documents as binary JSON in the storage file. |
TaskCleanupTimerSeconds | 3 | Remove completed tasks timer (cleanup tasks queue) |
BackgroundSaveViewTimer | 1 | Save to other views timer seconds if enabled |
BackgroundViewSaveBatchSize | 1,000,000 | How many documents to process in a background view save event |
Tweaking, Performance and Consistency
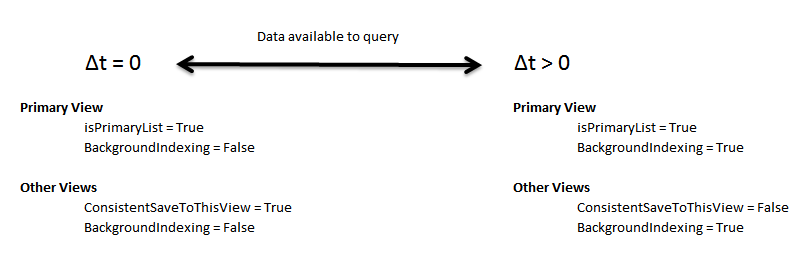
You can use RaptorDB from synchronous to eventually consistent manner by setting some parameters. You have the power to decide which parts of the data handling you need to be totally consistent to eventually consistent. This is done by some properties on your View definition.
BackgroundIndexingConsistentSaveToThisView
Obviously you will get less throughput when going synchronous.
Server Mode
In this release you can run RaptorDB in server mode which will take TCP connections from clients. Views in this release can be built into DLL files and deployed in the server's "Extensions" folder and the server will automatically read and use them on start-up. TCP Port numbers and data folder files are configurable.
RaptorDBServer.exe
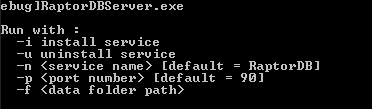
RaptorDBServer allows you to install RaptorDB as a windows service or run on the command line, with the -i parameter you can install multiple service instances which can be differentiated by the -n name and the -p port parameters.
Client Usage
Using RaptorDB on a client is as simple as the following:
RaptorDBClient db = new RaptorDB.RaptorDBClient("localhost", 90 , "admin", "admin");
All the functionality of the embedded version is available via this interface.
Server Usage
You can start RaptorDB in server mode within your own code via the following:
var server = new RaptorDBServer(90, @"..\..\..\RaptorDBdata");
IRaptorDB interface
To make the experience of using the embedded version or the client version seamless, like yo can start embedded then progress to the client server version based on your usage, the IRaptorDB interface was created to isolate you from changes. You can see this in action in the sample query executor program supplied.
Dog fooding
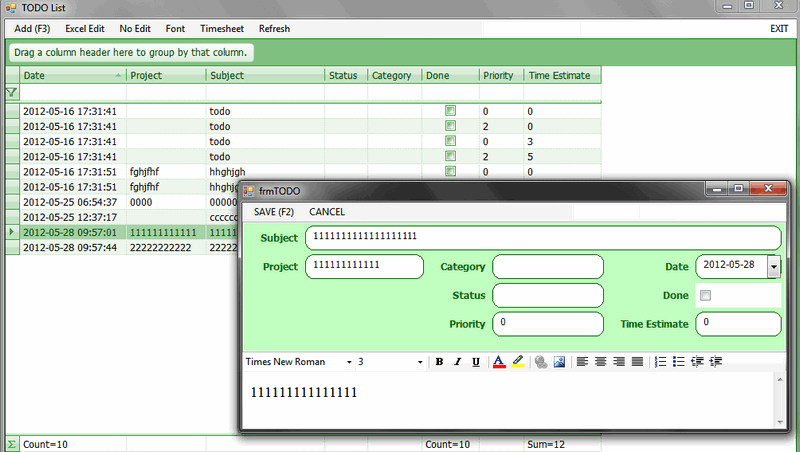
I did a Scrum Backlog/Todo List type of application while I was testing MongoDB, so I decided to port it to RaptorDB. The conversion process was very simple and trivial, mostly because of the nature of document databases. The only change was that MongoDB returns a list of actual objects while RaptorDB doesn't so you need to do a Fetch for an object when you need one.
Unfortunately, I used commercial components so I can't post the source code here. Below is the source code differences:
MongoDB Source
public partial class frmMain : Form
{
public frmMain()
{
InitializeComponent();
}
Mongo _mongo;
IMongoDatabase _db;
IMongoCollection<ToDo> _collection;
private void eXITToolStripMenuItem_Click(object sender, EventArgs e)
{
// TODO : message box here
this.Close();
}
private void exGrid1_RowDoubleClick(object sender, Janus.Windows.GridEX.RowActionEventArgs e)
{
openitem();
}
private void openitem()
{
var r = exGrid1.GetRow();
if (r != null)
{
ShowItem(r.DataRow as ToDo);
}
}
private void ShowItem(ToDo item)
{
frmTODO f = new frmTODO();
f.SetData(item);
var dr = f.ShowDialog();
if (dr == DialogResult.OK)
{
var o = f.GetData() as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
FillCollection();
}
}
private void frmMain_Load(object sender, EventArgs e)
{
_mongo = new Mongo();
_mongo.Connect();
_db = _mongo.GetDatabase("mytodo");
_collection = _db.GetCollection<ToDo>();
FillCollection();
exGrid1.AddContextMenu("delete", "Delete", null);
exGrid1.AddContextMenu("open", "Open", null);
exGrid1.ContextMenuClicked += new JanusGrid.ContextMenuClicked(exGrid1_ContextMenuClicked);
}
void exGrid1_ContextMenuClicked(object sender, JanusGrid.ContextMenuClickedEventArg e)
{
if (e.MenuItem == "delete")
{
DialogResult dr = MessageBox.Show("delete?", "DELETE",
MessageBoxButtons.YesNo, MessageBoxIcon.Stop,
MessageBoxDefaultButton.Button2);
if (dr == DialogResult.Yes)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
FillCollection();
}
}
if (e.MenuItem == "open")
openitem();
}
private void FillCollection()
{
var o = _collection.FindAll();
BindingSource bs = new BindingSource();
bs.AllowNew = true;
bs.AddingNew += new AddingNewEventHandler(bs_AddingNew);
bs.DataSource = o.Documents;
exGrid1.DataSource = bs;
exGrid1.AutoSizeColumns(true);
}
void bs_AddingNew(object sender, AddingNewEventArgs e)
{
e.NewObject = new ToDo();
}
private void addToolStripMenuItem_Click(object sender, EventArgs e)
{
ShowItem(new ToDo());
}
bool _editmode = false;
private void editInPlaceToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == false)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.AutoEdit = true;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.RecordUpdated += new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded += new EventHandler(exGrid1_RecordAdded);
_editmode = true;
}
}
void exGrid1_RecordAdded(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
}
void exGrid1_RecordUpdated(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
}
private void normalModeToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == true)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.RecordUpdated -= new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded -= new EventHandler(exGrid1_RecordAdded);
_editmode = false;
}
}
void FontToolStripMenuItemClick(object sender, EventArgs e)
{
FontDialog ofd = new FontDialog();
ofd.Font = this.Font;
if (ofd.ShowDialog() == DialogResult.OK)
{
this.Font = ofd.Font;
exGrid1.AutoSizeColumns(true);
}
}
private void designerToolStripMenuItem_Click(object sender, EventArgs e)
{
//try
{
JanusGrid.ExGrid grid = new JanusGrid.ExGrid();
grid.Name = "GridControl";
MemoryStream ms = new MemoryStream();
exGrid1.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
grid.LoadLayoutFile(ms);
Janus.Windows.GridEX.Design.GridEXDesigner gd = new Janus.Windows.GridEX.Design.GridEXDesigner();
//try
{
gd.Initialize(grid);
System.ComponentModel.Design.DesignerVerb dv = gd.Verbs[0];
dv.Invoke(grid);
}
//catch { }
gd.Dispose();
ms = new MemoryStream();
grid.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
exGrid1.LoadLayoutFile(ms);
exGrid1.ResumeLayout();
}
//catch { }
}
}
| RaptorDB Source
public partial class frmMain : Form
{
public frmMain()
{
InitializeComponent();
}
RaptorDB.RaptorDB rap;
private void eXITToolStripMenuItem_Click(object sender, EventArgs e)
{
rap.Shutdown();
this.Close();
}
private void exGrid1_RowDoubleClick(object sender, Janus.Windows.GridEX.RowActionEventArgs e)
{
openitem();
}
private void openitem()
{
var r = exGrid1.GetRow();
if (r != null)
{
ToDo t = (ToDo)rap.Fetch((r.DataRow as TodoView.RowSchema).docid);
ShowItem(t);
}
}
private void ShowItem(ToDo item)
{
frmTODO f = new frmTODO();
f.SetData(item);
var dr = f.ShowDialog();
if (dr == DialogResult.OK)
{
var o = f.GetData() as ToDo;
rap.Save(o.GUID, o);
FillCollection();
}
}
private void frmMain_Load(object sender, EventArgs e)
{
rap = RaptorDB.RaptorDB.Open("mytodo");
rap.RegisterView(new TodoView());
FillCollection();
exGrid1.AddContextMenu("delete", "Delete", null);
exGrid1.AddContextMenu("open", "Open", null);
exGrid1.ContextMenuClicked += new JanusGrid.ContextMenuClicked(exGrid1_ContextMenuClicked);
}
void exGrid1_ContextMenuClicked(object sender, JanusGrid.ContextMenuClickedEventArg e)
{
if (e.MenuItem == "delete")
{
DialogResult dr = MessageBox.Show("delete?", "DELETE", MessageBoxButtons.YesNo, MessageBoxIcon.Stop, MessageBoxDefaultButton.Button2);
if (dr == DialogResult.Yes)
{
var o = exGrid1.GetRow().DataRow as ToDo;
FillCollection();
}
}
if (e.MenuItem == "open")
openitem();
}
private void FillCollection()
{
var o = rap.Query(typeof(TodoView));
BindingSource bs = new BindingSource();
bs.AllowNew = true;
bs.AddingNew += new AddingNewEventHandler(bs_AddingNew);
bs.DataSource = o.Rows;
exGrid1.DataSource = bs;
exGrid1.AutoSizeColumns(true);
}
void bs_AddingNew(object sender, AddingNewEventArgs e)
{
e.NewObject = new TodoView.RowSchema();
}
private void addToolStripMenuItem_Click(object sender, EventArgs e)
{
ShowItem(new ToDo());
}
bool _editmode = false;
private void editInPlaceToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == false)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.AutoEdit = true;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.RecordUpdated += new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded += new EventHandler(exGrid1_RecordAdded);
_editmode = true;
}
}
void exGrid1_RecordAdded(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as TodoView.RowSchema;
ToDo t = new ToDo();
FillProperties(t, o);
rap.Save(t.GUID, t);
}
private void FillProperties(ToDo t, TodoView.RowSchema o)
{
t.Category = o.Category;
t.Date = o.Date;
t.Done = o.Done;
t.Priority = o.Priority;
t.Project = o.Project;
t.Status = o.Status;
t.Subject = o.Subject;
t.TimeEstimate = o.TimeEstimate;
}
void exGrid1_RecordUpdated(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as TodoView.RowSchema;
ToDo t = (ToDo)rap.Fetch(o.docid);
if (t == null) t = new ToDo();
FillProperties(t, o);
rap.Save(t.GUID, t);
}
private void normalModeToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == true)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.RecordUpdated -= new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded -= new EventHandler(exGrid1_RecordAdded);
_editmode = false;
}
}
void FontToolStripMenuItemClick(object sender, EventArgs e)
{
FontDialog ofd = new FontDialog();
ofd.Font = this.Font;
if (ofd.ShowDialog() == DialogResult.OK)
{
this.Font = ofd.Font;
exGrid1.AutoSizeColumns(true);
}
}
private void designerToolStripMenuItem_Click(object sender, EventArgs e)
{
{
JanusGrid.ExGrid grid = new JanusGrid.ExGrid();
grid.Name = "GridControl";
MemoryStream ms = new MemoryStream();
exGrid1.SaveLayoutFile(ms);
ms.Seek(0L, SeekOrigin.Begin);
grid.LoadLayoutFile(ms);
Janus.Windows.GridEX.Design.GridEXDesigner gd = new Janus.Windows.GridEX.Design.GridEXDesigner();
{
gd.Initialize(grid);
System.ComponentModel.Design.DesignerVerb dv = gd.Verbs[0];
dv.Invoke(grid);
}
gd.Dispose();
ms = new MemoryStream();
grid.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
exGrid1.LoadLayoutFile(ms);
exGrid1.ResumeLayout();
}
}
private void refreshToolStripMenuItem_Click(object sender, EventArgs e)
{
FillCollection();
}
private void frmMain_FormClosing(object sender, FormClosingEventArgs e)
{
rap.Shutdown();
}
}
|
And here is the view definition:
public class TodoView : RaptorDB.View<ToDo>
{
public class RowSchema : RaptorDB.RDBSchema
{
public DateTime Date;
public string Project;
public string Subject;
public string Status;
public string Category;
public bool Done;
public int Priority;
public int TimeEstimate;
}
public TodoView()
{
this.isPrimaryList = true;
this.Name = "Todolist";
this.isActive = true;
this.BackgroundIndexing = false;
this.Schema = typeof(RowSchema);
this.Mapper = (api, docid, doc) =>
{
api.EmitObject(docid, doc);
};
}
}
Consistent View
A notion of a Consistent View has been added since v1.3 which allows you to have non primary views act like primary views which will complete data insert and update within the Save call in RaptorDB.
This allows you to override the backround filling of the view, and have the views updated in real time. Obvoiusly there will be a performance hit when doing so.
All you need to do is set the ConsistentSaveToThisView property of the view to True.
Project Guidelines
You should be aware of some of the following guidelines which will help you getting the most out of RaptorDB and possibly your application design.
- Create a Entity project which will hold you data objects : because "entity/data" objects will be used all over your UI / Business Logic / Data storage, it is better to create a project for them which you can include in your other project, this will force you to use data only mentality and isolate you from including "forms" code in your entities and messing your references. (including a UI component reference in your data access code etc.)
- Include your View Schema definition in your Entities project : because the view row schema is being used in your views and your UI (for binding to the Result of your queries), it would be better to include this in your "entity" projects. You can put it in the View projects but you will have to include this project in your UI/Logic projects references and deploy accordingly.
Appendix v1.5
Some more major features were added to this version :
- Backup and Active Restore
- Users
- Delete document and delete files
- Misc
Backup and Active Restore
Backup and Restore feature was added in this version. Backups can be done manually or automaically in server mode at mid night every day (currently hardcoded).
Backups will be done incrementally from the previous backup set meaning that for every Backup call a incremental backup file will be created. The first Backup call will do a full backup to the last document in RaptorDB.
Backup files are created in the "Data\Backup" folder, these files are compressed typically up to 95%. A counter is maintained in that folder which will indicate the last backup position in the documents storage file.
Restore is done by calling the Restore method and RaptorDB will start processing the files in the "Data\Restore" folder. The restore process is non blocking and you can use RaptorDB in the meantime. Once a backup file is processed and restored it will be moved to the "Data\Restore\Done" folder.
Restoring documents is an additive process meaning that if an existing same GUID document exists then it will be revisioned, and will exist as a duplicate.
Users
Authenticating users will now check a users.config file for user names and password hashes.
You can add users or change passwords for users with a call to the AddUser method.
Delete
The ability to delete documents and files was added in this version which will flag the Guid as deleted (they still exist in the storage file). Deleted documents are now handled when rebuilding views and restoring backups.
Misc
To improve performance in server mode network traffic is compressed over a confguration limit of Param.CompressDataOver in the NetworkClient.cs file, this is set to 1Mb as a default meaning that any data over 1Mb will be compressed with MiniLZO for the client.
When filtering with a string query, RaptorDB now supports Guid and DateTime values, i.e.:
CreateDate = "2012/5/30 11:00" and docid = "f144c10f-0c9e-4068-a99a-1416098b5170"
Appendix v1.6 - Transactions
While normally transactions are not part of the Nosql movement, but by popular demand it is required for "business applications" where you need to control the flow of the data. In these circumstances, transactions make a lot of sense and add weight to the use of RaptorDB in such applications.
All you need to do is set the TransactionMode property of the primary view and all saves to that view and associated document type views will be handled consistently in a transaction. With-in your mapper method you can build complex business logic and Rollback if needed, if no rollback or exceptions occur then the transaction is automatically comitted.
On a rollback or exception no data is written to the docs file strorage and no updates are made to the indexes, so RaptorDB will be in a consistant state.
Example
Below is a sample view defintion with the properties set for transaction mode operation.
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public class RowSchema : RDBSchema
{
[FullText]
public string CustomerName;
public DateTime Date;
public string Address;
public int Serial;
public byte Status;
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.TransactionMode = true;
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.Mapper = (api, docid, doc) =>
{
if (doc.Serial == 0)
api.RollBack();
api.EmitObject(docid, doc);
};
}
}
Because this view is a Primary view then all other view updates will happen in this transaction so if an inner view Rollbacks then the whole transaction and updates will be rolled back. All the updates will be done consistently and in one thread.
Appendix v1.7 - Server Side Queries
Prior to v1.7 you had to do aggregate queries on the client side which meant that the data must be transfered to the client for this to work. Obvoiusly when you have a large number of data rows in your views then this would be time consuming and bandwidth intensive (even with automatic compression). To overcome this in this version you can create "stored procedure" like functions which you can deploy to your server and execute the aggregate queries on the server and only transfer the results to the client.
This is done by the following source code sample:
public class ServerSide
{
// so the result can be serialized and is not an anonymous type
// since this uses fields, derive from the BindableFields for data binding to work
public class sumtype : RaptorDB.BindableFields
{
public string Product;
public decimal TotalPrice;
public decimal TotalQTY;
}
public static List<object> Sum_Products_based_on_filter(IRaptorDB rap, string filter)
{
var q = rap.Query(typeof(SalesItemRowsView), filter);
List<SalesItemRowsView.RowSchema> list = q.Rows.Cast<SalesItemRowsView.RowSchema>().ToList();
var res = from item in list
group item by item.Product into grouped
select new sumtype // avoid anonymous types
{
Product = grouped.Key,
TotalPrice = grouped.Sum(product => product.Price),
TotalQTY = grouped.Sum(product => product.QTY)
};
return res.ToList<object>();
}
}
All you need to do is create a method with the parameter type structure which takes a IRaptorDB interface and a string filter property.
To call this method in your code all you need to do is the following :
var q = rap.ServerSide(Views.ServerSide.Sum_Products_based_on_filter,
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3")
).ToList();
dataGridView1.DataSource = qq;
The ServerSide method allows you to supply filters in LINQ or string format like normal Query calls.
Quirks
Normally aggregate queries use anonymous classes where the compiler generates the return class type at compile time and you magically have things work. Anonymous types can not be serialized and don't have a set method on them, so you must define the return type yourself when doing sum queries (an inconvieniece as you have to type more).
From the code sample above you can see that I have defined the sumtype class which encapsulates the sum query's data structure. Since I have defined the class with fields and not properties (no getter/setter), you must also derive the class from the RaptorDB.BindableFields type so databinding will work and the base class library controls can bind to it and show the data.
Again since ServerSide returns object[] and the BCL DataGrid doesn't understand this you need to convert the results to a generic list with ToList before data binding.
Appendix v1.8.3 Count and Paging
In this release I have added the ability to Count data on the server in an extreamly fast way and return the results, so you can do the following :
int c = rap.Count("SalesItemRows", "product = \"prod 1\"");
int cc = rap.Count(typeof(SalesItemRowsView),
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
Also you can now page the results returned from your queries for network performance so all the Query overloads now take start and count parameters:
Result q = rap.Query("SalesItemRows", "product = \"prod 1\"", 100, 1000);
Appendix logo designs
By popular demand I have added new logo proposals here which you can vote on:
| New logo | New logo | Proposed by : Bill Woodruff |
 |  |  |
Appendix v1.9.0
A lot of changes were made in this version the most important of which are :
- Support for MonoDroid
- A new Query model and typed results
- Bug fixes
MonoDroid Support
After getting my self a Asus TF700 Android tablet device, I decided to see if I could get RaptorDB working on it. The bad news was that MonoDroid does not support the CodeDOM, so I had to rewrite a very small part of RaptorDB using Reflection.Emit which turned out quite well. After compiling the code succesfully I found that it did not work on Android and when debugging I found that the problem was with the path separator character differences between Windows '\' and Unix '/' so I changed all the code to use Path.DirectorySeparatorChar.
This is a really exciting development and opens the door to use RaptorDB on mobile devices. I will write more on this in another article sometime.
New Query Model
Now you can write the following code :
int c = rap.Count<SalesInvoiceView.RowSchema>(x => x.Serial < 100);
var q = rap.Query<SalesInvoiceView.RowSchema>(x => x.Serial < 100, 0, 10);
dataGridView1.DataSource = q.Rows;
q= rap.Query<SalesInvoiceView.RowSchema>("serial <100");
string s = q.Rows[0].CustomerName;
As you can see you define the schema you want and write really short linq statements and RaptorDB will determine the view your schema belongs to and give you typed results so there is no need for casting. This means less typing which is always great. The old query model will still work.
Notes :
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public class RowSchema
{
public string CustomerName { get; set; }
public DateTime Date { get; set; }
public string Address { get; set; }
public int Serial { get; set; }
public byte Status { get; set; }
public bool Approved { get; set; }
public Guid docid { get; set; }
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 3;
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.FullTextColumns = new List<string> { "customername" };
this.Mapper = (api, docid, doc) =>
{
if (doc.Serial == 0)
api.RollBack();
api.EmitObject(docid, doc);
};
}
}
Bug Fixes
A lot of bug fixes and enhancments were made also, the most prominent being Not queries on bitmap indexes now expand to encompass all the view rows and deleted documents are handled correctly on a view rebuild. Unfortunately the storage file changed for the deleted file handling and is not backward compatible.
Appendix v1.9.2
Case insensitive column searching is now supported by setting the CaseInsensitive attribute on your schema column or by adding the column name to the CaseInsensitiveColumns property on the view (the latter is for the time when you don't want to propogate the dependancies to RaptorDB among your entity classes i.e. defining your entity classes and schema definitions as a standalone dll without depending on RaptorDB).
...
public class RowSchema : RDBSchema
{
[FullText]
public string CustomerName;
[CaseInsensitive]
public string NoCase;
public DateTime Date;
public string Address;
public int Serial;
public byte Status;
public bool Approved;
}
public SalesInvoiceView()
{
...
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.CaseInsensitiveColumns.Add("nocase");
Also the ability to query != or NotEqual in LINQ is now supported :
int c = rap.Count<SalesInvoiceView.RowSchema>(x => x.Serial != 100);
Appendix v2.0.0
In this release the ability to fulltext search the original document irrespective of views has been added, to support this and the ability to fetch document changes the storage file has been changed so existing data in the storage files will not work ( the ability for storage file upgrade has been omitted for now, if you need this please contact me).
To work with the new features all you need to do is :
int[] results = rap.FullTextSearch("search");
object o = rap.FetchVersion(results[0]);
To get a documents change history :
int[] history = rap.FetchHistory(guid);
object o = rap.FetchVersion(history[0]);
The same interfaces exist for file storage (bytes) : FetchBytesHistory() and FetchBytesVersion()
Appendix v2.0.5
In this version RaptorDB now supports memory limiting via the following configuration points:
Global.MemoryLimit : the default is 100 which means if the value of GC.GetTotalMemory() > 100mb then start freeing memory. You can increase this value to store more index data in memory for performance. GC.GetTotalMemory does not give the same values you get in the task manager (you will see higher values in the task manager).Global.FreeMemoryTimerSeconds : the default is 60 seconds and will fire to check memory usage and free up if needed.
Also to make things more robust the view index data will be saved to disk on a timer, which will speed up shutdowns.
Appendix v3.0.0 - Replication
A lot of changes went into this version, which can be considered a major upgrade, some of the changes are below:
- all data files are opened in shared read mode so you can copy backup a running server's data folder for online backup.
- cron scheduler has been added for timed jobs
- new storage format for data files
- operate in key/value mode with
Global.RequirePrimaryView = false - script views
- HQ-Branch replication
New Storage Format
To overcome a major shortcoming of flexibility and my bad initial decision of making the format too brittle I have changed the storage file format to the diagram below:
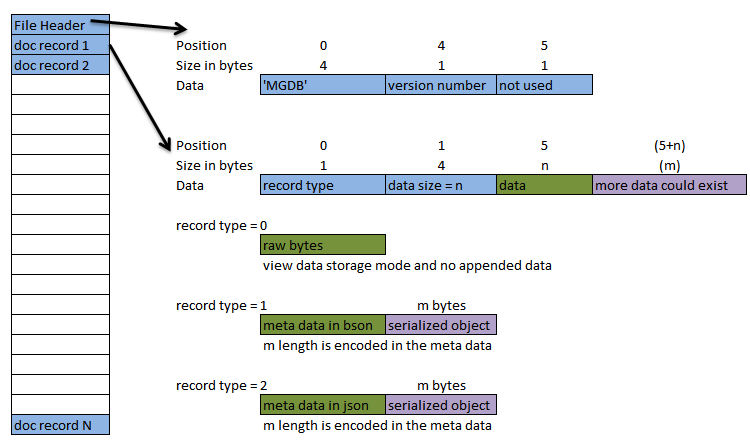
This new format will hopefully be the last breaking change since it is more flexible and robust than the previous
versions. The new format operates in the following 2 modes:
- meta data mode : each record has associated meta data
- raw mode : used for view data storage with no meta data
Meta data is stored in BinaryJSON format but you can choose between BinaryJSON or text JSON for object serialization, the deserializer will give you the correct format which ever you choose (within the same file). The meta data has the following properties at the moment (more may be added in the future without breaking):
- object type name (fully qualified)
- is deleted
- is replicated
- key value
- serialized object byte size
- date and time of save
Cron Schedules
A cron scheduling daemon has been added so you can control different aspects of the workings within RaptorDB. Cron can be daunting at first but once you get the hang of it it is really really powerful. To help you get started by example here is a quick start guide:
- cron has a resolution of a minute.
- cron string format is :
Minutes Hours Day_Of_Month Month_Of_Year Day_Of_Week - you enter numbers in the place holders
- you can enter an asterisk in the place holders which means "every"
- you can enter ranges with a dash (-) with no spaces :
0-10 means zero to ten - you can enter discrete values with a comma (,) with no spaces :
2,4,6 Day_Of_Week starts at 0=Sunday...- you specify a divisor with a slash (/)
- you can omit tailing values and (*) is assumed :
*/5 equals */5 * * * *
Examples :
* * * * * : every minute
*/10 * * * * : every 10 minutes
0 * * * * : every hour at the top of the hour
0 0 * * * : every day at midnight
* 0 * * * : every minute between midnight and 1am
15 * * * * : every hour at 15 minutes past the hour
0 12 * * 1,2,3,4,5 : every week day at 12 noon
*/2 * * * * : every even minute
0-30/3 9-17 * * * : every third minute at the top of each hour from 9am to 5pm
C# Script Views
You can now define views in script form and place them in the Views folder on the server and RaptorDB will automatically build and use them. This is a powerful feature which allows you to tweak view definitions at run-time with notepad (or any text editor of your choice).
- if you require a reference in your script file you can add the following at the top (usually to access entity classes i.e. SalesInvoice in the sample below) :
// ref : filename.dll - you can define a row schema within you script file for dynamic views (obviously if you require access to the properties from within your client side code i.e.
row.Name etc. then the row schema should be defined elsewhere and referenced on both client and server like a data entity class) - if the row schema is defined in the script file then upon use at run-time the script DLL file will be transferred to the client and loaded so deserialization will work and you see your data. This is a really powerful feature.
using System;
using System.Collections.Generic;
using RaptorDB;
namespace SampleViews
{
[RegisterView]
public class testing : View<SalesInvoice>
{
public class RowSchema : RDBSchema
{
public string Product;
public decimal QTY;
public decimal Price;
public decimal Discount;
}
public testing()
{
this.Name = "testing";
this.Description = "";
this.isPrimaryList = false;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 3;
this.Schema = typeof(RowSchema);
this.Mapper = (api, docid, doc) =>
{
foreach (var i in doc.Items)
api.EmitObject(docid, i);
};
}
}
}
Replication
A major feature in this version is the ability for RaptorDB to replicate data across process boundaries and servers. This allows you to create and maintain "Enterprise" applications in different locations. RaptorDB implements replication in semi-online headquarters/branch style where data is transferred between servers periodically.
- currently there is no high level security for the TCP connection so if you really need that then you are advised to setup a VPN connection between your servers first.
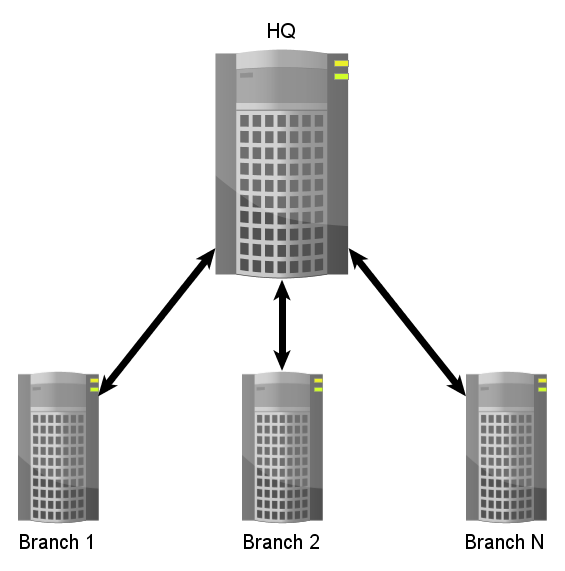
Replication can be considered to be the following:
- What : what you want to replicate, meaning the document types that need to be transferred.
- Where : where the data should go or the destination points
- When : when the data should be transferred or the frequency of moving data
- How : how the data should be transferred or the protocol used.
How is currently a TCP based data serialization protocol on a port number of your choice with the default being 9999. When is a cron based schedule.
Setting up Replication
For replication to work you need 1 master or headquarter server and at least 1 branch server. To setup replication you need to edit the RaptorDB-Replication.config file on your HQ server and edit the RaptorDB-Branch.config file on your other servers.
- All the action will take place in the Replication folder in RaptorDB's data directory.
- You can do replication in embedded mode also with the above files being configured.
- You can configure how many items to transfer in each package the default is 10,000 documents, this is to limit the file size to manageable amount for transfer over the wire.
- You would probably configure the cron job to do replication over a period of time say every 5 minutes from midnight to 1am for example if there is a potential for more than 10,000 documents generated on a server.
Troubleshooting
Failures can occur in the event that the documents saved in the data transfer package cannot be deserialized on the target machine.
- all operations and exceptions are logged in the log file in the data folder.
- if the replication inbox contains a file like "0000000n.error.txt" then an error occurred and the contents will show what went wrong along with the offending json.
- you can skip the offending document if you increment the "0000000n.counter" file (when you can't overcome the exception)
- in the event of failures you can selectively delete files in the replication folders or even delete the entire folder and the system will restart, and given that documents are transferred and are inherently re-entrant then all should be good.
All operations are resume-able and will continue from the last point on restarts or errors.
Config files
All the configuration files in this version have a "RaptorDB-" prefix so the "users.config" file in the previous versions is now "RaptorDB-Users.config".
- the engine starts-up and see there is no configuration file then it will create a sample file with a "-" prefix so you can edit it and restart from a template.
RaptorDB.config
Below is a sample for the general configuration file (in JSON format):
{
"BitmapOffsetSwitchOverCount" : 10,
"BackgroundSaveToOtherViews" : true,
"DefaultStringKeySize" : 60,
"FreeBitmapMemoryOnSave" : false,
"PageItemCount" : 10000,
"SaveIndexToDiskTimerSeconds" : 60,
"FlushStorageFileImmediatley" : false,
"SaveAsBinaryJSON" : true,
"TaskCleanupTimerSeconds" : 3,
"BackgroundSaveViewTimer" : 1,
"BackgroundViewSaveBatchSize" : 1000000,
"RestoreTimerSeconds" : 10,
"FullTextTimerSeconds" : 15,
"BackgroundFullIndexSize" : 10000,
"FreeMemoryTimerSeconds" : 60,
"MemoryLimit" : 100,
"BackupCronSchedule" : "0 1 * * *",
"RequirePrimaryView" : true,
"PackageSizeItemCountLimit" : 10000
}
This file is essentially the internal parameters for RaptorDB so you can fine tune the engine at runtime without recompiling the server.
- you are advised not to change these if you are not sure.
RaptorDB-Replication.config
Below is a sample for the server side replication configuration file (in JSON format) :
{
"ReplicationPort" : 9999,
"Where" :
[
{
"BranchName" : "b1",
"Password" : "xxxxx",
"What" : "default",
"When" : "0 * * * *"
},
{
"BranchName" : "b2",
"Password" : "yyyyy",
"What" : "b2",
"When" : "*/5 * * * *"
},
],
"What" :
[
{
"Name" : "default",
"Version" : 1,
"PropogateHQDeletes" : true,
"PackageItemLimit" : 10000,
"HQ2Btypes" : [""],
"B2HQtypes" : ["*"]
},
{
"Name" : "b2",
"Version" : 1,
"PropogateHQDeletes" : false,
"PackageItemLimit" : 0,
"HQ2Btypes" : [""],
"B2HQtypes" : ["namespaceX.type1", "namespaceY.*"]
}
]
}
There are 2 main sections "where" and "what" :
- you first define the where section for your branch servers which includes the "when" cron schedule and the "what" reference name the section below.
- you can define a "default" what configuration if you want or a branch named "what".
HQ2Btypes is the types you want to transfer from your HQ to branches.B2HQtypes is the types you want to transfer from you branches to HQ.- The types are defined as a list of .net type names.
"" in the type list means nothing* is a place holder for multiple types matching that definition so "*" means send everything and "namespaceX.*" means send everything matching the namespace "namespaceX" etc.- you can limit the package document count to a number or set it to 0 which means the global limit defined in "RaptorDB.config"
PropogateHQDeletes controls whether a document delete occurs on the branch servers if it was deleted on the HQ.- the password is stored as is without any encryption etc.
RaptorDB-Branch.config
Below is a sample for the branch configuration file (in JSON format) :
{
"ServerAddress" : "192.168.1.6",
"ServerReplicationPort" : 9999,
"Password" : "xxxxx",
"BranchName" : "b1"
}
Just complete the data for your branch server and you are good to go.
- the password is stored as is without encryption etc.
Folder Structures
DATA Folder
|
|- Replication > (branch mode)
| |-: branch.dat
| |
. |- Inbox >
| |-: 0000000n.mgdat.gz,
|
|- Outbox >
- if inbox contains a file like "0000000n.counter" then an error occurred and the text is in "0000000n.error.txt"
- you can skip the offending document if you increment the "counter" file (when you can't overcome the exception)
- files will be downloaded to the inbox folder in branch mode
- "branch.dat" in the "Replication" folder stores counter information for replication
DATA Folder
|
|- Replication > (HQ mode)
| |-
| |
| |- Inbox >
| | |
. | |- BranchName1 >
| | |-: 0000000n.mgdat.gz
| | |
|
|- Outbox >
| |
| |- BranchName1 >
| |- BranchName2 >
- if inbox contains : "0000000n.error.txt" then error occurred
- you can skip the offending document if you increment the "counter" file (when you can't overcome the exception)
- *.last files store the branch last document transferred counters
Appendix v3.1.0 - Query Sorting
In this version the old style query model (specifing types etc.) has been removed in favour of the new model where you have generic interfaces and specify the row schema.
Also a major update is the ability to sort your data on view columns which is needed when you do paging. So the overloads now support a "orderby" string parameter in which you specify the column you want to sort on. You can sort in decrementing order by appending a "desc" to the string.
var q = rap.Query<SalesInvoiceViewRowSchema>(x => x.Serial < 100, 0, 10, "serial desc");
Appendix v3.1.3 - Dog fooding and real world usage
I recently had the opportunity to practice what I preach and use RaptorDB in a real world setting and build a business application solely on it. The details I will omit since it is not as important as the concepts and best practices.
Most of what has changed in version 3.1.1 to 3.1.3 are a direct result of the insight gained in creating that application.
It is still astounding that the heart of the application is 2 DLL's of 200kb size which is peanuts compared to the whizbang UI components used (over 30mb).
Serials and row numbers
Most applications require a sort of unique incrementing number (row number, ID etc) which is generated in the database layer, so how can this be done in RaptorDB?
Say we have :
class Invoice { InvoiceNumber : int }
in the mapping function for the invoice view the following api method was added :
Mapper = (api, guid, doc) =>
{
if (doc.InvoiceNumber == 0)
doc.InvoiceNumber = api.NextRowNumber();
api.EmitObject(guid, doc);
};
now there is a side note here on how RaptorDB saves data:
- Generally
RaptorDB will save the document to doc storage first then save to views so in the case of the InvoiceNumber the doc will be saved with 0 and the row number will be lost when we fetch that invoice.
- Thankfully if you have enabled
Transactions on your primary view for that document then the save order is reversed as follows :
- call the relevant views first
- if all is ok (i.e. no
RollBack) then save the doc to disk. - So in the case of our
InvoiceNumber any changes to it (or any other properties) from calling map functions will be preserved and saved.
Deleting from Views
Now generally inserting and updating a view is easy but how do you delete from a view? Well if you have enabled DeleteBeforeInsert = true on your view then RaptorDB will delete the document by the Guid before inserting the new data so all you need to do is for an invoice with a delete flag :
Mapper = (api, guid, doc) =>
{
if (doc.isDeleted == false)
{
if (doc.InvoiceNumber == 0)
doc.InvoiceNumber = api.NextRowNumber();
api.EmitObject(guid, doc);
}
};
or you could save a subclass like DeleteSupplierRequest and have this mapper :
Mapper = (api, guid, doc) =>
{
if (doc.GetType() != typeof(DeleteSupplierRequest)) // otherwise it is deleted
{
doc.orgItem.Compute();
doc.Description = doc.orgItem.Description;
api.EmitObject(guid, doc);
}
};
both of the above are not outputting any rows to a view so in conjunction with DeleteBeforeInsert you have deleted data from a view.
A very important note here:
- we are not loosing any data since
RaptorDB is append only and stores all the documents you have saved regardless of deletes so if you need to you can change the mapper and rebuild the view for recovery etc and if you know the Guid for the document, get it's history with FetchHistory() or FetchHistoryInfo() which gives dates of change also.
Operations on other views
A design shortcoming of
RaptorDB is that you cannot directly change view data other than the view the document is assigned to work with, for example you cannot insert or change data in another view while in the map function (this may change in later releases but for now it is not there), and also you cannot assign non subclass (non related) objects to views so the only way is to programmatically do the saving yourself.
if (_raptorDB.Save(_invoice.GUID, _invoice))
{
var inv = (Invoice)_raptorDB.Fetch(_invoice.GUID);
if (inv == null)
return false;
_invoice = inv;
_invoice.Items.ForEach(x => _raptorDB.Save(x.id, x));
foreach (var i in _invoice.Items)
{
SupplierRequest s = new SupplierRequest(_invoice, i);
_raptorDB.Save(s.GUID, s);
}
return true;
}
Now arguably the above code would run on your server business layer but it would be cleaner if it were in the map function of the Invoice save.
Development tips
Here are a few useful development tips:
- While you can always increment the
view.Version number (and you must do so if you have deployed to a client) for view changes a quick workaround for debugging is just deleting the the views folder and RaptorDB will rebuild that view. - For business apps you should probably set
BackgroundIndexing = false and TransactionMode = true so you instantly see changes and document manipulation in view map functions are preserved. - Create separate Entity and View projects and put your schema definitions in the entity project, that way you can manipulate and work with the
Query() return values and have intellisense statement completion.
Appendix v3.1.4 - ViewDelete & ViewInsert
Continuing my dog fooding and real world usage, I was converting another app from MySql to RaptorDB and came across the need to be able to delete and insert directly into views since re-architecting the application to a document-orientated version was too much work, so now you can with the following :
int rowsdeleted = raptorDB.ViewDelete<PermissionsSchema>(x => x.Path == "there");
var c = new PermissionsSchema();
c.docid = Guid.NewGuid();
c.Path = "here";
raptorDB.ViewInsert<PermissionsSchema>(c.docid, c);
The above direct manipulations on views are fully rebuildable and are internally backed by a "document" in the main storage file, so it will be as if the operation was done normally and you have a log for it.
Appendix v3.1.6 - Split storage files
Continuing the dog-fooding in production, in this version you can split the document storage files by setting the Global.SplitStorageFilesMegaBytes configuration to a value (the default is 0 which is off).
This feature is for the devops/admins guys and enables them to take smaller incremental daily backups e.g. instead of taking a 100gb daily backup of the entire changed .mgdat file the backup will only be the daily changed amount which will allow to take more backups until the backup medium is full.
- You can set and unset this value any time and
RaptorDB will handle it correctly. - Once set the
.mgdat files will split to a new file around the size limit (it may go over the size since it will keep the last document in the same file and not split it into two files). - The last file will always be
.mgdat and the first will be .mgdat00000 - View rebuilds are uneffected and will work correctly.
Appendix v3.2.0 - High Frequency Storage File
Some significant changes were made in this version some of which are:
- You can now compress the documents with the
Global.CompressDocumentOverKiloBytes configuration the default is anything over 100kb - Views will now check for integrity on start-up and rebuild if needed (i.e. a failed Shutdown)
- A new Key/Value storage file has been added for high frequency update items that will recycle the disk space (i.e. not append-only)
Introduction
The new storage system is essentially defined as a Dictionary<string,object> key/value store with a string key which ensures the widest range of use-cases. You must note the following:
- Keys are currently limited to 255 bytes as a UTF8 string.
- Views are not effected by saving to this storage (no mapping will occur).
- You will not have previous values and old values will be over written.
- The storage file is implemented as a linked-list of disk blocks of size
Global.HighFrequencyKVDiskBlockSize which is set to a default of 2048 bytes (do not use anything below 512 unless you know what you are doing) see the File Format section below. - Deletes will immediately free all the blocks used by the key and set the start block of the old value to deleted.
The new storage file is good for rapid and periodic saving of the same key data like state information where you don't care about history of the data but the current value.
Data Integrity
Since the new storage file is recycling free space (as opposed to the append only model) the potential for data corruption is great. To ensure data integrity RaptorDB does the following :
- New items use the free space or append to the end of the file, then if the old key exists all it's blocks are marked as free. This ensures that in the case of a failure, at least the old values are not over written and can be recovered.
- In case of a non-clean Shutdown
RaptorDB will do an automatic rebuild of the key indexes and free block list from the contents of the storage file by going through each block.
File Format
A new file format has been created which is implemented as a linked list of disk blocks. Each block has a header section which contains information about how data is saved in the block as well as the next block, then the key bytes follow limited to 255 bytes after which the actual data is written up to the block size.
The header and key section is repeated for each block in the list to ensure data integrity.
The default block size is 2048 bytes and you should not go below 512 bytes unless you know exactly what kind of data values you are saving and the maximum key length you intend to use.
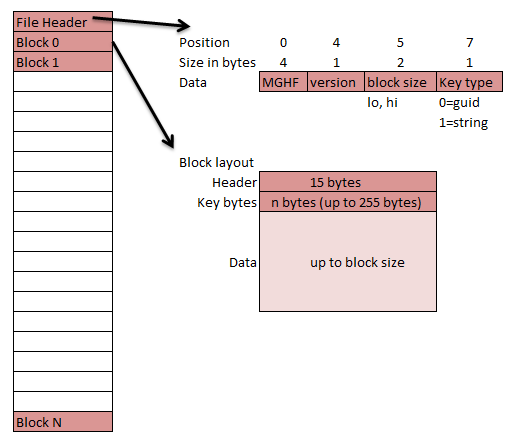
Some things to note:
- A block will be allocated regardless of the free bytes left in each block i.e. space within a block is lost if the data is smaller than the block size.
- Using a smaller block size may offer better/smaller file size at the expense of more seeks if the data is larger than the space for each block.
- Since the header is 15 bytes and the maximum key size is 255 then you cannot go below 270 bytes unless you are limiting the key length and your data is short.
- You can call
CompactStorageHF() anytime to reclaim storage space and reduce the storage file size. After compaction the original files are saved to the old folder.
Usage
You can get to the new features via the following interface:
var kv = rdb.GetKVHF();
The above interface has the following methods:
public interface IKeyStoreHF
{
object GetObjectHF(string key);
bool SetObjectHF(string key, object obj);
bool DeleteKeyHF(string key);
int CountHF();
bool ContainsHF(string key);
string[] GetKeysHF();
void CompactStorageHF();
}
The above interface is pretty self explanatory.
Advanced topics
On all writes a special file is created by the name of temp.$ which signifies a data changed operation so in the event of a system failure RaptorDB will know to rebuild indexes.
You can trigger a rebuild process by adding the above file to the view folder or the DataHF folder for the new key/value store.
On a different note
Continuing the testing on other platforms, below is an animated GIF of RaptorDB working as is on an Ubuntu virtual machine which I previously installed mono-complete on:
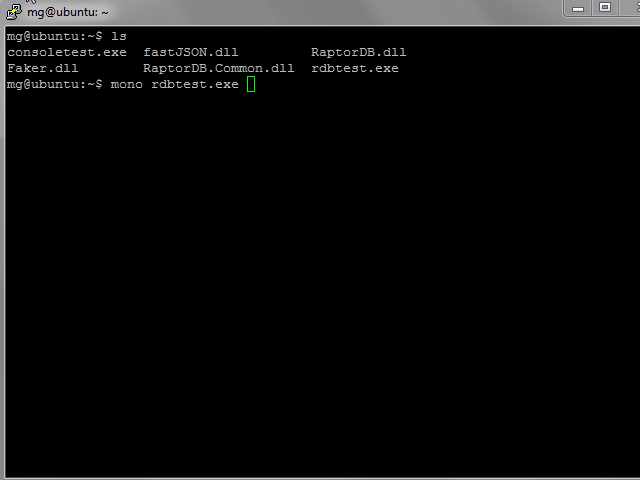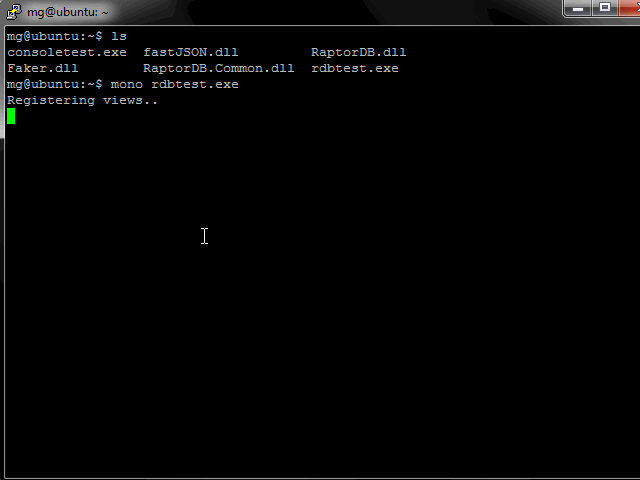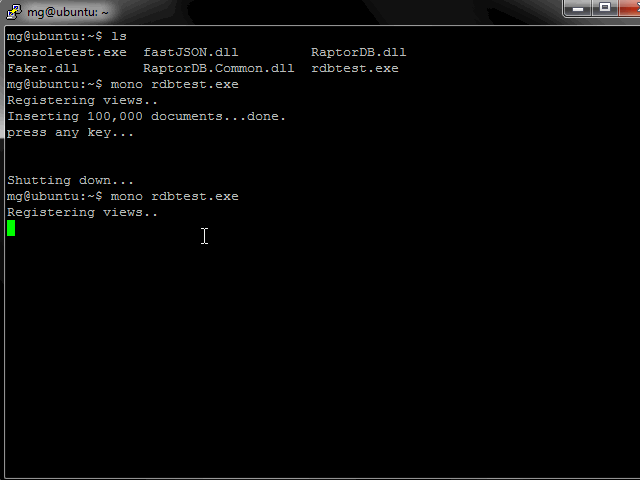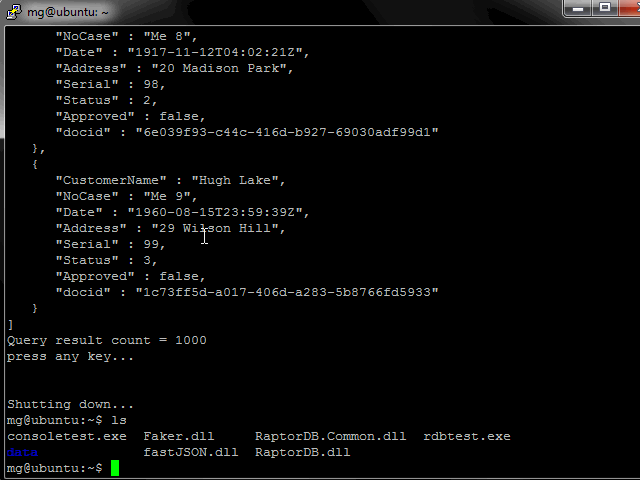
Appendix v3.2.5 - New String Indexes
One long time nagging problem was the storage cost of string indexes, since strings are variable in size, when you come to index them you are left no choice but to take the largest length possible and allocate storage for it regardless of it's actual size since you had to contend with variable length of index pages, which can get very messy.
So in this version and on the back of the new recycle-able storage file format MGIndex<string> type indexes will store the actual strings in an external MGHF file and store the reference in the IDX file which means huge storage size reduction for these types of indexes.
You can control the creation of this new file with the Global.EnableOptimizedStringIndex flag which is true by default, note :
- Previous style indexes still work and are backward compatible.
- New indexes will be built on
View rebuilds when required and the above flag allows it.
Appendix v3.2.14 - HFKV Increment() Decrement()
Continuing my real world usage of RaptorDB I have added atomic Increment/Decrement of int,decimal values to the high frequency key value store and RaptorDB ensures that updates will be atomic and consistent which can be used for :
- Counters
- Inventory values
Also fulltext search edge cases should be finally covered so you can do :
- address = "-oak -*l" = not oak and not ending in l ( not hill, laurel etc.)
Appendix v3.2.15 - Fulltext Search Changes
From this version on the way full text search is handled is changed so using + now means OR (this is a breaking change and hopefully makes more sense).
So :
"15 franklin" = 15 and franklin
"15 franklins" = 15 and franklins -> which will show no results since fanklins does not exist
"15 +franklin" = 15 or franklin
Appendix v3.3.0 - Web Studio
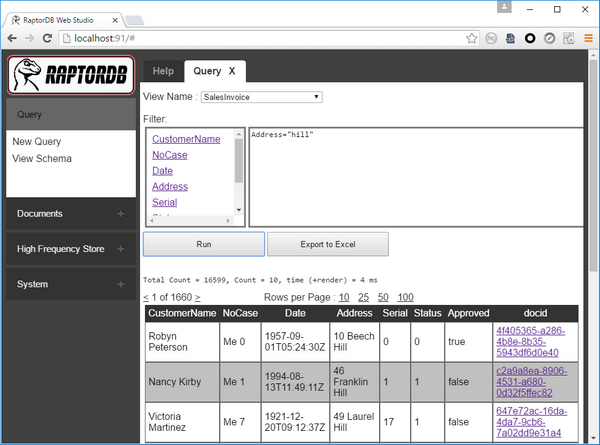
A longtime coming, but finally RaptorDB has a web interface. The wait was mainly for me to "get" javascript and web development which is still ongoing. Parts of this update are from the REST api article (http://www.codeproject.com/Articles/678295/RaptorDB-REST) which has been integrated into the main code base and will live on here.
Currently this web interface is readonly and does non-destructive operations and defaults to local machine only access for security reasons, his might change in the future when I get the access control to work.
This UI uses plain javascript and was written from scratch with no dependancies, even the '$' operation was written by me as a standin.
The javascript requires modern browsers and will work with IE10+ (IE8, IE9 were to much trouble and not worth the effort given I wrote everything from scatch).
The javascript gurus amoung you will probably complain about the code.
How to enable Web Studio
By default the web Studio UI is disabled and you can control it with the following config parameters:
"EnableWebStudio" : true,
"WebStudioPort" : 91,
For security reasons the web UI is local host only by default, you can enbale connection from any address by setting :
"LocalOnlyWebStudio" : false
What you can do
Most of the main features of RaptorDB are available through the Web UI like :
- Queries
- View Schema
- Document view and history
- System Information and logs
- High frequency key/value browse
Queries
You can get at your data with the query tab which supports paging, filtering, sorting and exporting to excel.
To filter a query you can click on the column name which will add it to your filter text box and add the filter you want, like :
Address = "hill" and serial < 100
or
Address = "hill -oak" and serial < 100
You can click on the column name for sorting the columns data. If you click on the link under the `docid` column then you will see the underlying document which is associated with the row.
Document view and history
You can view the actual document json and see any revisions which were made under the "Documents" menu. Full text searching of the original json documents is also supported.
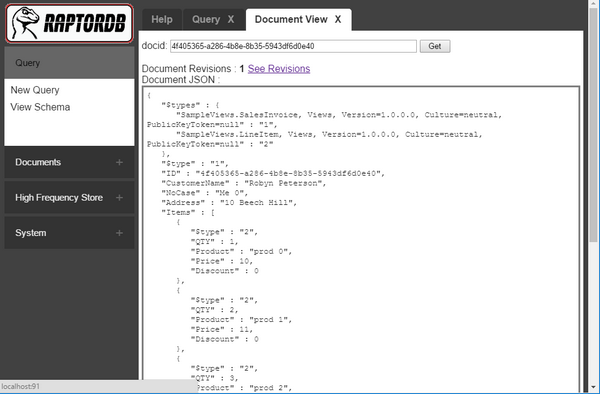
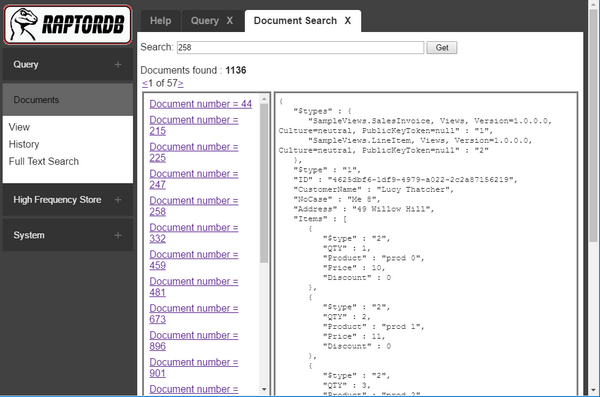
System Information
Under the system information menu you can see the last 100 log items along with debug information from the server and the current configuration parameters.
Under this tab you can also backup the current data and optimize the high frequency data store.
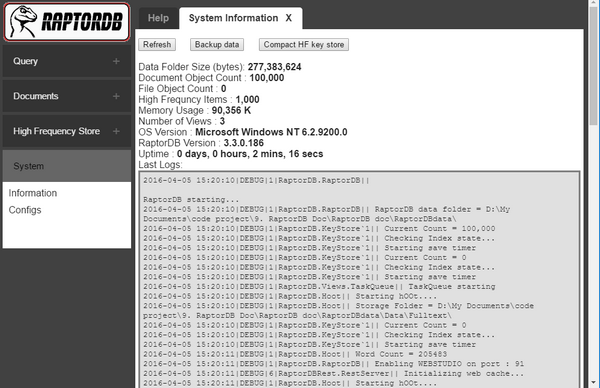
High frequency key store
Under this menu you can browse the high frequency key/value store and see the json representation of what you stored for each key.
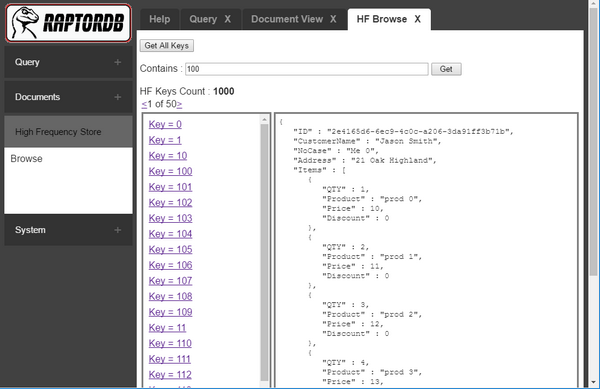
Getting started
Concepts
RaptorDB is a json based key value store with map functions which map documents to views for querying. So at its core you save a document entity with Save() and Fetch() the same.
A key value store is very useful, but for most applications you need to query and aggregate parts of documents, so you need to define views to extract information from those documents. Extracting information like this is done for performance reasons.
You can only have 1 instance of RaptorDB accessing the data folder (while files are opened in shared mode so you can take hot backups,
two instances cannot share the same files and folders).
While the noSql movement advocates "schema-less" designs, this does not mean the absence of a schema, but less dependency on a schema or schema isolation i.e. the ability to change things without breaking other parts, because to do anything with performance you will need to know your data types and structures otherwise queries would be a limited full text search (limited in the way that text data loses type information).
Installing
You can use RaptorDB in your projects by installing via
nuget and searching for RaptorDB_doc or by manually adding 2 DLL references :
- RaptorDB.dll : the main server code
- RaptorDB.Common.dll : common library for both embedded and client/server
Your first Project
The complete source code :
Cannot resolve file macro, invalid file name or id.
For demonstration purposes we will create a console application project (you can create any kind of app with Visual Studio). Our first project will use RaptorDB in embedded mode, meaning that the database will share the memory of the console process.
Since RaptorDB needs to keep a lot of state then we should create a global variable for it so we can access it from throughout our code and have 1 instance:
class Program
{
static RaptorDB.RaptorDB rdb;
static void Main(string[] args)
{
rdb = RaptorDB.RaptorDB.Open("data");
RaptorDB.Global.RequirePrimaryView = false;
DoWork();
Console.WriteLine("press any key...");
Console.ReadKey();
Console.WriteLine("\r\nShutting down...");
rdb.Shutdown();
}
...
Note that we are explicitly shutting down so RaptorDB can cleanly save data to disk (if you don't do this you might notice RaptorDB rebuilding the views as it didn't shutdown cleanly).
For the purpose of our first example we will disable the need to have primary views defined for our documents and essentially use RaptorDB as a key value store.
Now lets save some data:
static void DoWork()
{
Console.Write("Inserting 100,000 documents...");
int count = 100000;
for (int i = 0; i < count; i++)
{
var inv = CreateInvoice(i);
rdb.Save(inv.ID, inv);
}
Console.WriteLine("done.");
}
From the above code you can see that every document (SalesInvoice) has a Guid (ID) associated with it and we save that with the invoice and this is done with the Save() method which takes the ID and the document as parameters. For more user friendly data we are using Faker to generate the data in the CreateInvoice() method :
static SalesInvoice CreateInvoice(int counter)
{
var inv = new SalesInvoice()
{
Date = Faker.DateTimeFaker.BirthDay(),
Serial = counter % 10000,
CustomerName = Faker.NameFaker.Name(),
NoCase = "Me " + counter % 10,
Status = (byte)(counter % 4),
Address = Faker.LocationFaker.Street(),
Approved = counter % 100 == 0 ? true : false
};
inv.Items = new List<LineItem>();
for (int k = 0; k < 5; k++)
inv.Items.Add(new LineItem() { Product = "prod " + k, Discount = 0, Price = 10 + k, QTY = 1 + k });
return inv;
}
If we know a Guid then we can get the document with :
var obj = rdb.Fetch(known_guid);
Now obviously we want to be able to query with more than just a Guid that we know so we need to define a view on our SalesInvoice type, so our view is something like (we will skip what the code means for now):
public class SalesInvoiceViewRowSchema : RDBSchema
{
public string CustomerName;
public string NoCase;
public DateTime Date;
public string Address;
public int Serial;
}
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 1;
this.Schema = typeof(SalesInvoiceViewRowSchema);
this.Mapper = (api, docid, doc) =>
{
api.EmitObject(docid, doc);
};
}
}
and we register the view with RaptorDB on start-up :
static void Main(string[] args)
{
rdb = RaptorDB.RaptorDB.Open("data");
RaptorDB.Global.RequirePrimaryView = false;
Console.WriteLine("Registering views..");
rdb.RegisterView(new SalesInvoiceView());
...
our
<span class="codeInline">DoWork()</span> becomes :
static void DoWork()
{
long c = rdb.DocumentCount();
if (c > 0)
{
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial < 100);
Console.WriteLine(fastJSON.JSON.ToNiceJSON(result.Rows, new fastJSON.JSONParameters { UseExtensions = false, UseFastGuid = false }));
Console.WriteLine("Query result count = " + result.Count);
return;
}
Console.Write("Inserting 100,000 documents...");
int count = 100000;
for (int i = 0; i < count; i++)
{
var inv = CreateInvoice(i);
rdb.Save(inv.ID, inv);
}
Console.WriteLine("done.");
}
Some of things to notice :
- we are using the beautified output of fastJSON to show the data return which is built-in to RaptorDB.
- on re-running our changed code, the view was automatically rebuilt with the data we already saved, and our query works (you will have to rerun a second time for the query to show results since the engine will be rebuilding the view in the background and will not be available at the time the query is executed).
- we did nothing to define indexes and all that was taken care of for us.
- the data was returned to us in a typed format much like a typed DataSet if you are familiar with that.
- data was returned from the view we defined and not the original documents
- the entire process is type safe and the compiler will help you if a mistake was made, rather than at runtime much like string SQL queries (if you need dynamic queries you can use string filters also, but obviously the compiler can't help you with mistakes).
Now Query() has a few overloads to control paging and sorting based on a criteria :
public Result<object> Query(string viewname);
public Result<object> Query(string viewname, string filter);
public Result<object> Query(string viewname, int start, int count);
public Result<object> Query(string viewname, string filter, int start, int count);
public Result<object> Query(string viewname, string filter, int start, int count, string orderby);
public Result<TRowSchema> Query<TRowSchema>(string filter);
public Result<TRowSchema> Query<TRowSchema>(string filter, int start, int count);
public Result<TRowSchema> Query<TRowSchema>(string filter, int start, int count, string orderby);
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter);
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter, int start, int count);
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter, int start, int count, string orderby);
Oooops! things change
Now say we have underestimated what we need in our queries and much like life, requirements change, so what do we do?
Well! for RaptorDB it is simple, all we need to do is change our schema and view like below :
public class SalesInvoiceViewRowSchema : RDBSchema
{
public string CustomerName;
public string NoCase;
public DateTime Date;
public string Address;
public int Serial;
public byte Status;
public bool? Approved;
}
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 2;
this.Schema = typeof(SalesInvoiceViewRowSchema);
this.Mapper = (api, docid, doc) =>
{
if (doc.Status == 0)
return;
api.EmitObject(docid, doc);
};
}
}
The key is the Version property which tells RaptorDB to rebuild the view if it is older. On restarting our application the view is rebuilt and our queries reflect the changes.
Side Note
- The above view is primary list and we probably don't want to not save since there will be no reference to retrieve the SalesInvoice from, you would probably do this kind of filtering based on Status for example in other detail or summation views. The above is only for demonstration purposes.
- As you can see we can change the view schema and/or how documents are processed and all we need to do is change the Version number to let RaptorDB know when to rebuild the view's contents.
Appendix v3.3.8 - nscript.exe
In this release I have added nscript.exe tool which allows for easy running and testing of c# script files which I have had for a long time. This file will compile and run the script given. Also the sample.cs file is now part of the main zip and is now in the "test script" folder.
So now you can easily run any c# file like this:
# run any cs file
c:\rdb\test script> ..\tools\nscript.exe sample.cs
# or just run the batch file
c:\rdb\test script> run.cmd
The sample.cs file now contains a comment section at the top for specifing references used which will tell nscript.exe where to find the dll files:
using System;
using System.Collections.Generic;
...
Hopefully this will allow for easy testing and tinkering the sample given without going through the process of creating a project file which has been a stumbling block for some people.
Appendix v3.3.9 - Between() and Date Parts
In this release you can now do Between() on DateTime, int, long, decimal types like this:
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Between("2001-1-1", "2010-1-1") && x.Status == 2);
var d1 = DateTime.Parse("2001-1-1");
var d2 = DateTime.Parse("2010-1-1");
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Between(d1, d2));
var result = rdb.Query("salesinvoice", "date.between(\"2001-1-1\",\"2010-1-1\"");
var result = rdb.Query("salesinvoice", "serial.between(20,30)");
The same works for the WebStudio interface.
Also you can query any date column parts like this :
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Year == 2016 && x.Date.Month == 8);
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Hour < 10);
Appendix v3.3.12 - In()
In this release you can now use In() on column and date parts so :
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(1,3,5,7));
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(new int[] { 1,3,5,7 }));
var arr = new int[] {1,3,5,7};
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(arr));
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Year.In(2000, 2010));
var result = rdb.Query("salesinvoice", "serial.in(1,3,5,7)");
Also Between() has been extended to work with date parts :
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Hour.Between(12, 15);
Appendix v4.0.0 - MGRB
In this version I have replaced the WAHBitarray data structure with my rewritten MGRB bitarray structure which is based on Daniel Lemire's roaring bitmap (https://roaringbitmap.org/) for better memory usage. My version has the following added benifits (which I might write an article on) :
- ability to set bits outside of the consrtuctor
- sparse containers i.e. only encoding used blocks of bits
- inverted container for storing zeros in a block of ones
- optimized choosing of container blocks based on bits set
In the sample app the ininital memory usage for storing 100,000 docs from a blank database went down from 450Mb to 350Mb and the free memory works much better and optimizes in memory structures better.
The speed of saving and indexing is about the same.
Appendix v4.0.9 - Web Studio with Svelte
I recently came across Svelte which is similar to Vue I used and loved. I must say that I really like Svelte as it has the same concepts and capabilities of Vue but is much simpler and produces really tiny output without the "framework" library overhead.
The node_modules required and the rollup packager are also really tiny in comparison to others.
I decided to rewrite my old jQuery like Web Studio code that I wrote by hand (my first time writing javascript), in Svelte and the result was much smaller around 30% less output minified than my old code but infinitely more maintainable ( the actual code is about 50% less).
The thing which I really like and was a real pain and a source of many bugs, is that you don't need the this reference like in Vue.
To implement the tabs interface I needed some advanced features if Svelte which are :
- runtime creating components and setting
target and props on them in code - using
$on and $destroy on runtime components - using
<svelte:options accessors={true} /> for access to component internals
To allow debugging the code in action I needed to change the server URL to the actual RaptorDB server address and not the dev server on port 5000. To do this I added the debug.js file :
import './main.js'
window.ServerURL = "http://localhost:91/";
The main.js file has :
...
window.ServerURL = document.location.protocol + "//" +
document.location.hostname + ":" +
document.location.port + "/";
...
The default build commands built the code to the public folder which is not ideal. To remedy this I also changed the rollup.config.js file to differentiate debug and production builds and use the dist folder instead.
...
const production = !process.env.ROLLUP_WATCH;
const dir = production ? "dist" : "public";
export default {
input: production ? 'src/main.js' : 'src/debug.js',
...
The thing I couldn't get to work was using JavaScript's fetch() command and it gave me CORS errors when debugging so I used my old XMLHttpRequest() code and added them to the window object to use throughout the app.
All in all, I enjoyed the process and again Visual Studio Code is a delight to use.
Previous Versions
You can download previous versions here:
History
- Initial release v1.0 : 29th April 2012
- Update v1.1 : 4th May 2012
- fulltext indexing via attribute
- string query parser
- fix shutdown flusing indexes to disk
- rudementary console application
- lowercase viewnames for string queries
- fulltext search defaults to AND if + - characters not present in query
- query now works when suppling the view type
- save pauses indexer for better insert performance ~30% faster
- Update v1.2 : 11th May 2012
- View versioning and rebuild
- code cleanup
- removed indent logic from fastJSON
- added schema of the query to the Result
- Update v1.3 : 17th May 2012
Results.Rows are now row schema objects and bindable (even when fields)View.Schema must now derive from RaptorDB.RDBSchema- removed columns from
Result (not needed anymore) RegisterView throws exceptions instead of returning a Result- added a rudimentary query viewer project
- null values are ignored when indexing
- bool index filename will end in ".idx"
- sample apps will create data files in the main soultion folder for easy sharing
- you can now do aggregate queries on the results on the client side
- added
api.EmitObject for easier mapping (less code to write) - upgrade to fastJSON v1.9.8
- bug fix datetime in fastBinaryJSON
- Update v1.4 : 31st May 2012
- break up the source into projects
- created client, server dlls
- upgrade to fastBinaryJSON v1.1
- changed to
SafeSortedList for thread safe indexes - add auto installer RaptorDBServer service
- performance optimized tcp network layer
- added dual mode usage to the windows application (embedded, server)
- code cleanup
- added
IRaptorDB interface to allow you to switch between embedded and client seamlessly - load views from the Extensions folder in server mode
- Update v1.5 : 10th June 2012
- compressing network traffic over
Param.CompressDataOver limit with MiniLZO - added
Delete(docid) and DeleteBytes(fileid) - added ability to query Guid and DateTime in string form
- bug fix reading boolean indexes
- rebuild view and background indexer handles deleted docs
- added authentication via users.config file in server mode
- Backup & Restore data
AddUser() method for user- handle
isDeleted when restoring data and rebuilding View - Auto backup in server mode @ 00:00 time
- Update v1.6 : 30th June 2012
- query lambda caching
- transaction support
- bug in datetime serialization
- Rules section added to article
- Transaction section added to article
- Update v1.7 : 14th July 2012
- server side aggregate queries
- fixed the build script for views to copy the dll to the extensions folder
- server side queries can have filters
- login form default buttons fix
- Update v1.8.1 : 11th August 2012
- bug fix hoot index loadwords when file size is zero
- bug fix linq binding ServerSide -> c.val == stringvariable
- bug fix linq binding -> c.val == stringvariable
- bug fix reflection code in serializers
- speed increase WAH bitmap Set() code
- bug fix concurrent save bitmap index to disk
- upgrade to fastBinaryJSON v1.3
- upgrade to fastJSON v2.0.1
- Update v1.8.2 : 16th August 2012
- bug fix linq binding -> c.val == obj.property (Thanks to Joe Dluzen)
- added lock to the bitmap index for concurrency
- optimized $types output in JSON and BJSON
- bug fix null check for SafeSortedList.Remove
- bug fix server mode data transfer
- Update v1.8.3 : 23rd September 2012
- upgrade to fastJSON v2.0.6
- upgrade to fastBinaryJSON v1.3.4
- bug fix linq2string with date,guid parameters
- added double,float types to the indexer valid data types
- added a lock to the IndexFile for concurrency issues (thanks to Antonello Oliveri)
- fixed lock on _que in the logger for concurrency (thanks to Antonello Oliveri)
- fixed the reflection binding to the insert method (thanks to Antonello Oliveri)
- added Count() on views
- added support for paging of results
- the mapper can now see changes it has made in it's own thread in transaction mode while quering
- added a new logo section
- Update v1.9.0 : 26th November 2012
- speed increase writing bitmap indexes to disk
- bug fix hoot search with wildcards
- bug fix datetime indexing with UTC time (all times are localtime)
- upgrade to fastJSON v2.0.9
- upgrade to fastBinaryJSON v1.3.5
- changed CodeDOM to Reflection.Emit for MonoDroid compatibility
- more optimized bitmap storage format (save offsets if smaller than WAH)
- fixed path seperator character for monodroid and windows compatibility changed to
Path.DirectorySeparatorChar - new generic Query interface with typed results (thanks to seer_tenedos2)
- changed to Result<T>
- WAH bitcount speed increase
- bitmap index uses buffered stream for speed
- added between query (work in progress)
- bug fix storage file and deleted items
- new query model for mapper api interface
- you can now define your own schema for rows with caveats
- bug fix NOT on bitmap indexes to resize to the total row count first
- when defining your own schema you can define the fulltext columns in the view without attributes
- Update v1.9.1 : 30th December 2012
- bug fix edge case WAHBitarray
- sync code with changes in hOOt
- bug fix missing server mode
SaveBytes() - bug fix server side queries in server mode
- bug fix embedded guid in query : v => v.docid == new Guid("...")
- Update v1.9.2 : 6th April 2013
- SafeDictionary.Add() will update if item exists
- BitmapIndex using new lock mechanism
- CaseInsensitive attribute
- bug fix lowercase hoot indexing
- case insensitive string indexing and searching
- nocase samples
- fixed handling != (not equal) in linq query
- Update v2.0.0 : 28th April 2013
- added more method documentations
- * breaking change in doc storage file from hashed guid to guid keys *
- added
FetchHistory() and FetchVersion() for docs and files to get revisions - upgrade to fastJSON v2.0.14
- upgrade to fastBinaryJSON v1.3.7
- full text indexing and search for the entire original document
- bug fix linq query with boolean parameter
- Update v2.0.5 : 18th May 2013
- added FreeMemory to classes
- memory limiting and free memory timer added
- views background save indexes to disk on timer
- fixed RaptorDBServer.csproj to AnyCPU build
- Update v2.0.6 : 15th June 2013
- bug fix WAHBitArray
- upgrade to fastJSON v2.0.15
- bug fix hoot fulltext index on last word
- save deleted items bitmap on save timer
- Update v2.0.6.1 : 22nd June 2013
- Update v3.0.0 : 23rd August 2013
- index files are opened in share mode for online copy
- add cron daemon (thanks to Kevin Coylar)
- backups are now on a cron schedule
- restructured storage file for future proofing and replication support
- storage files now store meta data about objects stored
- * storage files are not backward compatible *
- dirty index pages are sorted on save for read performance
- restore is now resumable after a shutdown
- you can disable the primary view to be defined on save with
Global.RequirePrimaryView (K/V mode) - view rebuilds are now done in the background (non-blocking on restart)
- you can define views in c# script format (*.view) to be compiled at runtime in 'datafolder\views'
- row schema defined in script views will be transferred to the client if they don't exist
- fastJSON now serializes static properties
- upgrade to fastJSON v2.0.18
- upgrade to fastBinaryJSON v1.3.8
- added HQ-Branch replication feature
- automatic generate config files if they don't exist with a '-' prefix
- 'output' in the root of the solution folder is the new build destination of projects for easy access
- Update v3.0.1 : 6th October 2013
- upgrade to fastJSON v2.0.22
- upgrade to fastBinaryJSON v1.3.10
- detect process exit and shutdown cleanly so you can omit the explicit
Shutdown() - bug fix WAH bitarray
- Update v3.0.5 : 11th October 2013
- bug fix saving page list to disk for counts > 50 million items
- Update v3.0.6 : 2nd November 2013
Result.TotalCount reflects the original row count and differs from Result.Count when paging- internal changed
FireOnType to handle Type instead of strings Query() can now handle empty filter strings correctly- Upgrade to fastJSON v2.0.24
- Upgrade to fastBinaryJSON v1.3.11
- Update v3.1.0 : 5th December 2013
- added sort for queries
- removed extra query overloads in favour of the new model
- Update v3.1.2 : 17th May 2014
- added signed assemblies the assembly version will stay at 3.0.0.0 and the file version will increment
- added nuget build
- Upgrade to fastJSON v2.1.1
- Upgrade to fastBinaryJSON v1.4.1
- bug fixes in WAH and Query2 from Richard Hauer
- changed all singleton implementations
- bug fix indexing String.Empty
- *breaking change* removed FireOnType from view definitions
- Views can now correctly work with subclass of the T defined (i.e. SpecialInvoice : Invoice)
- bug fix index bitmap.Not(size)
- Update v3.1.3 : 27th May 2014
- added
FetchHistoryInfo() and FetchBytesHistoryInfo() with date change information - added
api.NextRowNumber() - moved all config files to the data folder which you should have write access to (thanks to Detlef Kroll)
- bug fixed delete before insert with no rows
- Update v3.1.4 : 21st June 2014
- added
StringIndexLength attribute for view schema to control string index size for the index file - added
ViewDelete() to delete directly from views - added
ViewInsert() to insert directly into views - added Faker.dll (http://faker.codeplex.com) to generate nicer data
FreeMemory() will save indexes to disk also- moved server mode files to output\server so you don't get conflicts loading views.dll
- page list is also saved to disk on
SaveIndex() - bug fix view schema when not inheriting from
RDBSchema - replaced T with more meaningful
TRowSchema in code intellisense
- Update v3.1.5 : 3rd January 2015
- added
View.NoIndexingColumns definition to override indexing of selected columns - Upgrade to fastJSON v2.1.7
- Upgrade to fastBinaryJSON v1.4.5
- added
DocumentCount() to get how many items in the storage file Shutdown() now waits for View rebuilds to finish- more intellisense help
- Update v3.1.6 : 9th January 2015
- document storage files can now be split with
Global.SplitStorageFilesMegaBytes configuration - refactoring StorageFile.cs
- Upgrade to fastJSON v2.1.8
- Upgrade to fastBinaryJSON v1.4.6
- bug fix .config files were not saved correctly
- Update v3.2.0 : 25th January 2015
- you can compress the documents in the storage file with
Global.CompressDocumentOverKiloBytes configuration - Upgrade to fastJSON v2.1.9
- added integrity check for views with auto rebuild if not shutdown cleanly
- bug fix disable timers before
Shutdown() - added high frequency update key/value storage file
- Update v3.2.5 : 6th February 2015
- new optimized for storage string
MGIndex file - added
Global.EnableOptimizedStringIndex flag to control the new index usage
- Update v3.2.6 : 27th February 2015
- optimizations done by Stainslav Lukeš
- upgrade to fastJSON v2.1.10
- upgrade to fastBinaryJSON v1.4.7
- bug fix bitmap indexes
- bug fix file name conflicts with deleted bitmap indexes
- added version checking of views and RaptorDB engine with auto rebuild for engine upgrades
- changed deleted bitmap indexes to
.deleted extension - changed version number files to text mode with
.version extension
- Update v3.2.7 : 27th February 2015
- bug fix wait on view rebuild while
Shutdown() was being cut off in 2 secs mid process (ProcessExit)
- Update v3.2.8 : 3rd March 2015
- bug fix duplicates showing in queries related to the deleted bitmap index
- Update v3.2.9 : 8th March 2015
- upgrade to fastJSON v2.1.11
- upgrade to fastBinaryJSON v1.4.8
- added support for vb.net string linq queries
- added vb test project
- Update v3.2.10 : 24th April 2015
- renamed
Form1 to frmMain - added sortable fulltext indexes
- fixed path names for linux systems
- changed default save and free memory timers to 30 min instead of 60 sec
- optimized query sorting with internal cache ~100x faster
- Update v3.2.11 : 25th April 2015
- Update v3.2.12 : 17th May 2015
- code cleanup
- bug fix full text searching with + - prefixes
- upgrade to fastJSON v2.1.13
- upgrade to fastBinaryJSON v1.4.10
- Update v3.2.13 : 31st May 2015
- code refactoring
- bug fix full text index search with leading not "-oak hill"
- fix time output in logs
- upgrade to fastJSON v2.1.14
- upgrade to fastBinaryJSON v1.4.11
- Update v3.2.14 : 6th August 2015
- server keeps track of connected clients count with auto clear every 30 secs
- added atomic
Increment() Decrement() to HFKV int,decimal values - bug fix wildcard search in full text indexes
- added not wildcard search in full text -> "-oak -*l"
- fulltext indexes break text on spaces and
char.IsPunctuation() api.NextRowNumber() blocks until rebuild finishes- view map functions has access to high frequency KV through the
api interface
- Update v3.2.15 : 13th September 2015
- *breaking change* + in full text search means OR now
- full text search bug fix edge case
- Update v3.2.16 : 26th January 2016
- added support for
ushort in views (thanks to dragosc) - bug fix
FetchHistory() return values in server mode (thanks to DrDeadCrash) - bug fix edge case bitmap index commits (thanks to dragosc)
- bug fix hOOt fulltext index shutdown
- bug fix
FullTextSerach() to filter out json characters before indexing
- Update v3.2.17 : 19th February 2016
- bug fix empty rows in
GenericResult() in client/server mode - bug fix if property/field defined in schema but not in entity hence null error when getting rows
- Update v3.2.18 : 15th March 2016
- usings cleanup
FreeMemory() in indexes, saves data first- added indexed word list to hOOt index
- hOOt optimize index saves data first
- hOOt optimize index will block until done
- hOOt
FindDocuments() is now generic - added server side function with
object[] args - added auto build number incrementor
- bug fix not equal
!= convert linq to string in queries - upgrade to fastJSON v2.1.15
- upgrade to fastBJSON v1.4.12
- Update v3.3.0 : 7th April 2016
- added WEB Studio interface
- logger keeps last 100 logs for recall
- bug fix HF storage file seek position overflow (thanks to ozzel)
- Update v3.3.1 : 14th April 2016
- bug fix mixed property and fields in view schema definition (invalid cast exception on query)
- Update v3.3.2 : 25th April 2016
- bug fix edge case duplicates showing in queries
- Update v3.3.3 : 6th May 2016
- bug fix
SafeSortedList.Add() - bug fix
WAHBitArray.FreeMemory()
- Update v3.3.4 : 20th May 2016
- streamlined shutdown process (no extra index saves)
- web ui content height set to browser height
- memory usage reduction in
BimapIndex (removed record cache) - memory usage reduction in
WAHBitArray (offset Dictionary -> SortedList) - memory usage reduction in
MGIndex (cache Dictionary -> SortedList) - memory usage reduction in
Hoot (words Dictionary -> SortedList) - log error if web server started when not run as administrator
- frmMain form close handles shutdown correctly
- changed default
Globals.FreeMemoryTimerSeconds to 5 mins from 30 mins
- Update v3.3.5 : 31st May 2016
- bug fix
!= in query return all rows if RH expression not found (thanks to Lutz Wellhausen) - linq
(x => true) predicate returns all rows - linq
(x => false) predicate returns no rows
- Update v3.3.6 : 25th July 2016
- upgrade to fastJSON v2.1.18
- upgrade to fastBinaryJSON v1.4.15
- changed default
view.ConsistentSaveToThisView = true - changed default
view.isPrimaryList = true - re-factored web server
- restructured
nav.js
- Update v3.3.8 : 12th August 2016
- synced with
hOOt - added
nscript.exe tool - added
sample.cs test script with command line run - changed log message types
- bug fix fulltext search
- fulltext
tokenizer breaks a.b.c words and numbers
- Update v3.3.9 : 14th August 2016
- query date parts e.g.
x => x.Date.Year == 2016 or "date.year = 2016" Between() for dates e.g. x => x.Date.Between("2000-1-1","2002-6-16")- optimized internal query engine for ranges
- internal query from to implementation
Between() for int, long, decimal
- Update v3.3.10 : 21st August 2016
- code cleanup
- generic
Between<T>() - bug fix
BitmapIndex.FreeMemory() - bug fix
MGIndex.FreeMemory() - added generic
Fetch<T>() (thanks to Norbert Haberl) - added
ZipStorer from [https://github.com/jaime-olivares/zipstorer] (thanks to Jaime Olivares) - added auto compress old log files
- Update v3.3.11 : 25th August 2016
- added query bitmap caching for faster queries
- Update v3.3.12 : 28th August 2016
- added
In<T>() e.g. x => x.Serial.In(1,3,5,7) or "serial.in(1,3,5,7)" - query cache for
Count() and all other overloads - code refactoring/cleanup in ViewHandler.cs
- date parts work with In() e.g.
x => x.Date.Year.In(2000,2001) - date parts work with Between() e.g.
x => x.Date.Year.Between(2000,2010)
- Update v3.3.13 : 3rd September 2016
- bug fix
x=>true predicate case - upgrade to fastJSON v2.1.19
- upgrade to fastBinaryJSON v1.4.16
- bug fix string keys indexes with
Global.EnableOptimizedStringIndex = true - ** incremented RaptorDBVersion ** will rebuild old index data if exists
- bug fix
WAHBitArray.Fill()
- Update v3.3.14 : 12th November 2016
- upgrade to fastJSON v2.1.21
- upgrade to fastBinaryJSON v1.4.18
- bug fix doc full text search results < paging count
- Update v3.3.15 : 6th June 2017
- upgrade to fastBinaryJSON v1.4.19
- bug fix logger zip file names
- bug fix local/UTC time in
FastDateTime - changed to public
WAHBitArray - changed to public Hoot
- changed to public CronDaemon
- Zipstorer default to UTF8 filenames
- bug fix
ViewInsert() and rebuild index *old data is not recoverable, rebuild your database if you can* - remove query bitmap cache because of incorrect results
- upgrade to fastJSON v2.1.25
- bug fix HFKV store rebuild on failed shutdown
- Update v3.3.16 : 7th June 2017
- Update v3.3.17 : 9th June 2017
- added
ITokenizer full text search overload to RaptorDB.Open() - tokenizer rewrite
- bug fix HFKV rebuild
- Update v3.3.19 : 25th January 2018
- upgrade to fastJSON v2.1.28
- upgrade to fastBinaryJSON v1.4.21
- support for .netcore 2.0 and netstandard 2.0
- Update v3.3.19.1 : 26th January 2018
- bug fix shutting down in .net core on ubuntu
- Update v4.0.0 : 5th October 2018
- upgrade to fastJSON v2.2.0
- upgrade to fastBinaryJSON v1.5.1
- changed to faster unicode <-> bytes conversion
- optimized view data bytes size without bjson typed arrays
- new sparse bitmap index for less memory usage (
MGRB based on roaring bitmap) - * possible breaking change if you are using High Frequency key store *
- bug fix full text search in columns for case insensitive words
- parallel shutdown indexes for better performance
- fixed .strings files kept growing
- Update v4.0.2 : 8th October 2018
- bug fix missing raptordb.version file in data folder
- bug fix
MGRB.Fill()
- Update v4.0.5 : 11th October 2018
- bug fix
MGRB.Fill(length) respect length value - bug fix
MGRB.CountOnes() when length = 0 MGRB added locks for integrityMGRB added InvertedContainer for better memory usageMGRB respect lengths in computations- truncate
StorageFileHF end free list data on read
- Update v4.0.6 : 17th December 2018
- upgrade to fastBinaryJSON v1.5.2
- bug fix loading empty hOOt words file
- bug fix query MGRB index with less than 64 rows
- Update v4.0.7 : 25th February 2019
- bug fix
StorageFileHF reloading free list from previous failed shutdown
- Update v4.0.8 : 23rd June 2019
- bug fix .string index files growing over time
- upgrade to
fastJSON v2.2.5 - upgrade to
fastBinaryJSON v1.5.3
- Update v4.0.9 : 24th July 2019
- rewritten the web studio with
Svelte

