Introduction
I wrote this article mostly for fun and as a candidate entry for The Code
Project's
Lean and Mean competition to write a text diffing tool. The library
and demo application are both written in C# using VS 2010 Beta and tested on a
64 bit Windows 7 RC machine. Some of the articles that have been submitted so
far do not really do a diff in the proper sense of the word and so that gave me
more of an impetus to write one that actually does a standard diff. I primarily
referred to the
Wikipedia entry on the LCS algorithm but also referred to
this
article (university lecture notes). I've called the class SimpleDiff<T>
because while it does do a proper LCS based diff, it could probably be further
optimized, though I've applied some bare optimizations of my own.
Performance/Memory info
The implementation is intended to be more mean than lean and
the primary objective was to write a reasonably fast diff-engine. This does not
mean it cannot be made faster, nor does it mean it cannot be made leaner without
losing out majorly on speed. For the test files provided by Code Project,
here're the timing results for five iterations, along with the average.
| 35.0069 ms | 33.3978 ms | 34.1942 ms | 34.9919 ms | 34.2274 ms |
Average : 34.3636 ms
The tests were performed on a 64-bit Core i7 machine with 12 GB RAM.
The memory usage (in bytes) is probably not as impressive as it may have been for a C++
app or for one that did not load both files into memory in their entirety.
| Paged memory | 6,492,160 |
| Virtual memory | 0 |
| Working set | 6,766,592 |
Not surprisingly (given the 12 GB ram), virtual memory usage was 0. But the
working set (delta) was 6.7 MB. The two biggest memory hogs are the fact that we
store both files in memory throughout the process, and the fact that the LCS
matrix can be pretty huge for files of any non-trivial size. I've considered a
version that never fully loaded either file but I couldn't think of a reasonable
way to avoid a performance fall (which invariably accompanies frequent disk
reads for fetching/seeking data).
Note on memory calculation
|
The memory consumption was calculated using the
Process
class's PeakWorkingSet64 and related
properties. I took the values once, invoked the code, and read the
values again and calculated the delta. To account for JIT memory, the
diff class was created once but not used prior to calculating the
memory. |
Using the demo app
The demo app takes 2 parameters, the source and target files (or the left and
right files as you may prefer). And it prints out all the lines, and uses a
++ prefix to indicate a line added to the left file, and a
-- prefix to denote a line removed from the left file. Here are
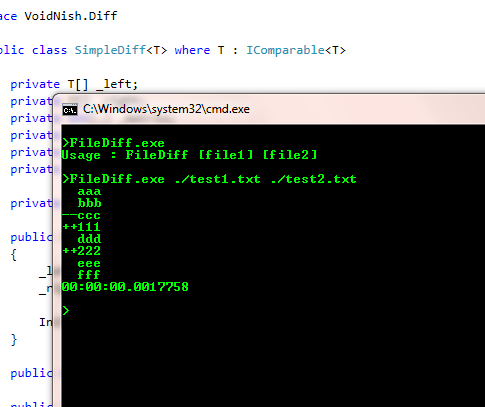
some screenshots that show it run against Chris M's sample files and also
against my simple test files.

Figure 1: The screenshot shows the left and right files as well as the
console output.
Figure 2: The screenshot shows a partial output of comparing the test files
provided by the competition creators.
If you are wondering about line numbers, note that this display is the
function of the calling program, my diff library does not really provide any
output - it just provides an event that callers can hook onto. For my console
app I chose to imitate the Unix diff program (though not identically), but it'd
be trivial to add line numbers. It'd be equally simple to write a WPF or
WinForms UI for this library.
Class design
It's a generic class where the generic argument specifies the type of the
comparable item. In our case, since we are comparing text files, this would be
System.String (representing a line of text). Using the class would
be something like :
leftLines = File.ReadAllLines(args[0]);
rightLines = File.ReadAllLines(args[1]);
var simpleDiff = new SimpleDiff<string>(leftLines, rightLines);
simpleDiff.LineUpdate += simpleDiff_LineUpdate;
simpleDiff.RunDiff();
Console.WriteLine(simpleDiff.ElapsedTime);
There is only one constructor and that takes two arrays - one for the left
entity and one for the right one.
public SimpleDiff(T[] left, T[] right)
{
_left = left;
_right = right;
InitializeCompareFunc();
}
InitializeCompareFunc sets the comparer delegate which is
defined as:
private Func<T, T, bool> _compareFunc;
I have special-cased for String so we get the most performant
comparison available.
private void InitializeCompareFunc()
{
if (typeof(T) == typeof(String))
{
_compareFunc = StringCompare;
}
else
{
_compareFunc = DefaultCompare;
}
}
private bool StringCompare(T left, T right)
{
return Object.Equals(left, right);
}
private bool DefaultCompare(T left, T right)
{
return left.CompareTo(right) == 0;
}
There's also a public event that's fired for each line :
public event EventHandler<DiffEventArgs<T>> LineUpdate;
public class DiffEventArgs<T> : EventArgs
{
public DiffType DiffType { get; set; }
public T LineValue { get; set; }
public DiffEventArgs(DiffType diffType, T lineValue)
{
this.DiffType = diffType;
this.LineValue = lineValue;
}
}
public enum DiffType
{
None = 0,
Add = 1,
Subtract = 2
}
And in the demo app it's handled in a awfully unfussy manner. But for a more
UI-ish app, the possibilities are boundless.
static void simpleDiff_LineUpdate(object sender, DiffEventArgs<string> e)
{
String indicator = " ";
switch (e.DiffType)
{
case DiffType.Add:
indicator = "++";
break;
case DiffType.Subtract:
indicator = "--";
break;
}
Console.WriteLine("{0}{1}", indicator, e.LineValue);
}
When RunDiff is called the first time, the most important and also the most
time consuming part of the code is executed, once. That's where we calculate the
LCS matrix for the two arrays. But prior to that, as an optimization there's
code that will look for any potential skip text at the beginning or end of the
diff-arrays. The reason we can safely do this is that if the identical lines are
removed from both ends, and the LCS calculated for the middle portion, then we
can add back the trimmed content to get the LCS for the original array-pair. If
that's not clear consider these two strings (imagine we are comparing characters
and not strings) :
<font color="#FF0000">abc</font>hijk<font color="#FF0000">xyz</font> and <font color="#FF0000">abc</font>hujkw<font color="#FF0000">xyz</font>
If we remove abc from the left, and xyz from the right for both
char arrays, we get :
hijk and hujkw.
The LCS for these two char arrays is hjk. Now add back the removed
items to both ends and we get :
abchjkxyz
which is the LCS for the original pair of char arrays. I've applied the same
concept here. This method calculates any items that can be skipped at the
beginning of the content :
private void CalculatePreSkip()
{
int leftLen = _left.Length;
int rightLen = _right.Length;
while (_preSkip < leftLen && _preSkip < rightLen &&
_compareFunc(_left[_preSkip], _right[_preSkip]))
{
_preSkip++;
}
}
Now the post-skip is calculated (carefully avoiding an overlap with the
pre-Skip which further improves performance).
private void CalculatePostSkip()
{
int leftLen = _left.Length;
int rightLen = _right.Length;
while (_postSkip < leftLen && _postSkip < rightLen &&
_postSkip < (leftLen - _preSkip) &&
_compareFunc(_left[leftLen - _postSkip - 1],
_right[rightLen - _postSkip - 1]))
{
_postSkip++;
}
}
Next we calculate the LCS matrix :
private void CreateLCSMatrix()
{
int totalSkip = _preSkip + _postSkip;
if (totalSkip >= _left.Length || totalSkip >= _right.Length)
return;
_matrix = new int[_left.Length - totalSkip + 1, _right.Length - totalSkip + 1];
for (int i = 1; i <= _left.Length - totalSkip; i++)
{
int leftIndex = _preSkip + i - 1;
for (int j = 1, rightIndex = _preSkip + 1;
j <= _right.Length - totalSkip; j++, rightIndex++)
{
_matrix[i, j] = _compareFunc(_left[leftIndex], _right[rightIndex - 1]) ?
_matrix[i - 1, j - 1] + 1 :
Math.Max(_matrix[i, j - 1], _matrix[i - 1, j]);
}
}
_matrixCreated = true;
}
The inline comments should be self explanatory. Interestingly my assumptions
about what the JIT optimizer would take care of turned out to be rather
inaccurate and hazy. Of course I did not run detailed enough tests to make any
serious conclusions, but to be safe it's probably best to do some level of
optimizing on your own instead of always thinking, hey the pre-JIT will catch
that one. Once the LCS is calculated, all that's left is to traverse the
matrix and fire the events as required, and also remembering to iterate through
the skipped entries if any :
for (int i = 0; i < _preSkip; i++)
{
FireLineUpdate(DiffType.None, _left[i]);
}
int totalSkip = _preSkip + _postSkip;
ShowDiff(_left.Length - totalSkip, _right.Length - totalSkip);
int leftLen = _left.Length;
for (int i = _postSkip; i > 0; i--)
{
FireLineUpdate(DiffType.None, _left[leftLen - i]);
}
I did not spent too much time trying to optimize ShowDiff since
my profiling showed that it was not anywhere near as time consuming as the LCS
calculation. 87% of the execution time was spent in the LCS matrix loops.
private void ShowDiff(int leftIndex, int rightIndex)
{
if (leftIndex > 0 && rightIndex > 0 &&
_compareFunc(_left[_preSkip + leftIndex - 1],
_right[_preSkip + rightIndex - 1]))
{
ShowDiff(leftIndex - 1, rightIndex - 1);
FireLineUpdate(DiffType.None, _left[_preSkip + leftIndex - 1]);
}
else
{
if (rightIndex > 0 &&
(leftIndex == 0 ||
_matrix[leftIndex, rightIndex - 1] >= _matrix[leftIndex - 1, rightIndex]))
{
ShowDiff(leftIndex, rightIndex - 1);
FireLineUpdate(DiffType.Add, _right[_preSkip + rightIndex - 1]);
}
else if (leftIndex > 0 &&
(rightIndex == 0 ||
_matrix[leftIndex, rightIndex - 1] < _matrix[leftIndex - 1, rightIndex]))
{
ShowDiff(leftIndex - 1, rightIndex);
FireLineUpdate(DiffType.Subtract, _left[_preSkip + leftIndex - 1]);
}
}
}
Note on hashing
Many C++ implementations compute the hash of items before comparing them. In
our case, since we are using .NET that'd actually be a de-optimization because
we'd lose out on the benefits of string interning. In most cases, the majority
of lines would be the same (in real life scenarios, only a small percentage of lines are
changed between file versions). And since we use Object.Equals
which does a reference comparison as the first step, and because identical
strings are interned, this comparison is extremely fast. Where we slow down on
is when we compare long lines that may differ by one character at the right end
of the line - that'd give us our worst case false-compare time.
Conclusion
I had initially thought of writing this in C++/CLI so I could mix types -
which'd specially be useful when creating the array. The .NET array's big
disadvantage is that it's zero-initialized, and while that's one of the fastest
operations any CPU can typically perform, it's still time consuming because of
the large size of the array. I could have avoided that by using a native array.
But the lack of intellisense drove me nuts after a few minutes and I gave up and
went back to C#. Maybe if I get time I'll write another version which may do
part of the calculations in native code and the C# code can P/Invoke it, though
that itself may bring in inefficiencies of its own. Anyway, any suggestions and
criticisms are extremely welcome.
History
- August 20, 2009
- August 24, 2009
- Added binary download
- Added timing/memory
usage stats

