If you need a Version Control, this beginner article will help you to choose a Version Control system for yourself.
Introduction
Do you need version control?
- I've never used version control before
- I think I might want to try version control
- I want version control to work for me
- I don't want to work for it
If that describes you then read on, hopefully this will help you choose a Version Control System for yourself and whilst I can't guarantee it'll make your life better, if you find one that does indeed 'work for you', then it won't make it harder and I'd wager a decent bet that you'll find benefits you weren't even looking for!
As a beginner, I would guess it's pretty common to not even think about version control for quite a while after you start (or in my case, begin again), but at some point, it's likely to come to you - that sudden realisation that your life would be easier if you could keep track of the various changes going on in your code. Hopefully, it's not the result of a disaster (that's sort of almost what happened for me, fortunately I spotted it coming in the nick of time) and I've since discovered a whole bunch of other good reasons to use version control.
So I spent some time with a few version control systems (VCS) trying to pick one and thought I'd share my experiences since for a beginner it can be a quite daunting idea to just pick one and run with it - after all you're on a steep learning curve already, why would you want to double your headache with learning a VCS at the same time? Though that's often the type of advice you get:
use this one [insert name of just about every system you can think of], learn the command line, it's brilliant
Not my idea of fun. I want it easy.
If you just want to jump straight to the comparison, then please do so.
If you are at all interested in my take on what all the terms mean, then I've tried to add my two penneth to the millions of explanations already out there. Why? Most of them are written by experts and whilst the first sentence is written in for dummies mode, it's immediately followed by several sentences in Einstein mode. It's not possible for me to slip into Einstein mode, I've only just started. So hopefully my version is more useful if you have the same level of knowledge I had a few weeks ago.
Table of Contents
Background
Some basic assumptions:
- You want to use a distributed version control system rather than the historically favoured approach of tools like Subversion.
- You want a GUI and don't want to learn the command line.
Why make these assumptions? In reverse order, if you're a command line guru, then you probably don't need my help picking a VCS. Distributed VCSs are all the rage, most of everything seems to be moving that way so if you ever wanted to get involved with an open-source project or make your project available to the world as open-source, then it's probably a better choice right now.
Concepts
If you understand the basics or just want to jump straight to the comparison, then you can do just that.
First off, some basic concepts about version control, I learnt these by trying, making mistakes, working out what I'd done wrong and learning by fixing my mistakes. If learning by reading works for you, then this may help make more sense of the section on choosing a VCS, otherwise pick one and start making mistakes, it's hard to totally &*%^ things up. I've tried to order them logically but it can get a bit circular at times.
This is my understanding, beginner to beginner. If it's fundamentally wrong then let me know, if it appears a bit over-simplified, then that's probably ok given the target audience for this. I suspect I will look back at this in several months / years and wonder at my miniscule level of knowledge, hopefully I won't look back and wonder how I got it so wrong!
Remember I'm focusing on Distributed Version Control here, the terms probably mean something different in the historical VCS's like Subversion.
On that note, I think all the different VCSs and DVCSs can sometimes use different terms for exactly the same thing, or at least very similar things; you might also find the same term being used for two different things - oh good, that makes it easier!
Repository
The collection of files that make up your project (with or without version control) plus the database maintained by your VCS. The VCS simply allows you to easily track changes, create new versions, create branches, etc. and readily switch between them.
A repository could be local, on your hard disk, or remote to you on a server somewhere. In the distributed VCS world, even when working with a project hosted remotely, your local copy is a full copy of the remote one, i.e., it's a full repository, not just the piece you happen to be working on.
Distributed
You don't need to worry about this at all if you are working alone and particularly if you'll only ever work locally.
Since I haven't worked with a remote repository, I stand to be corrected here.
The key thing about Distributed VCS systems is that there does not have to be a master repository, each contributor has a full copy of the whole repository. So you are working peer to peer rather than client server. A central repository can act as a master but equally can just be a useful holding point that all the developers send their updates to and get other peoples updates from. How the development team behaved in terms of defining what should be the master version of their code is up to them.
Therefore there doesn't need to be a gatekeeper who reviews each persons' changes before accepting them into the central codebase. There often is someone performing that role but since every developer has a complete copy of the repository, there doesn't need to be for the VCS to work, it's only needed for sanity.
All kinds of benefits flow from each developer having a full copy of the repository, but this article isn't about that, so if you ever need to know (or just want to know), then it's easy to find plenty of commentary via Google.
Working Directory
Without version control, your working directory is your project folder (and any sub-folders). With distributed version control, it's the same, only you have the ability to update your working directory to whatever version of your code you want to work on very quickly and very easily.
Branch and Tip
A branch essentially takes a single version of your code and creates two copies of it. You can then change those two copies independently of each other, changes to one do not affect the other.
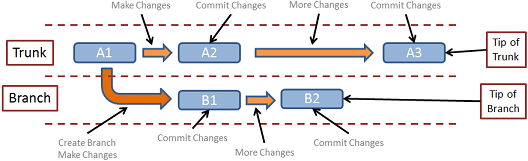
Two branches, the trunk and e.g. a feature branch
In the above image, the blue rectangles represent specific versions of your project, snapshots at a given moment in time. Whereas the arrows represent you making changes to the code, adding and removing files, etc. The darker orange arrow from A1 to B1 represents the creation of a branch as well as making code changes.
So branches sound really easy conceptually, and they are, but then it gets complicated, there are many many different ways that specific individuals and different projects decide to handle the different changes they wish to make within a project (new features, bug-fixes, etc.). There are also different ways to branch within a single VCS and many more when you look across more than one VCS.
To keep this simple, I'm going to define a simple working model in which there is a central or main branch, let's call it the trunk (you will also hear terms like baseline or default). Rarely will we make changes to the trunk directly. Mostly, we will create a branch, make changes to that and then merge it back into the trunk when we are done.
A tip is just the end of a branch line, before it has been merged into the trunk or into another branch.
Change Set
All of the changes that represent the difference between a commit and the prior commit (two versions of your project). Say you make some changes to one of the files in a project and then commit that change, the change set is the difference between the commit you just made and the prior one, i.e., the changes you made to that one file.
If you look back at the image above, the changes made between A1 and A2 are the change set for the commit you made and which created A2.
So when you make a commit, you essentially define a starting point (prior commit), a set of changes and the end point (the new commit).
Trunk
Another one where I stand to be corrected.
As a term, I think it's sort of a carry-over from the pre-distributed days where (I think) there was always a trunk which acted as the master branch within the central repository (one branch to rule them all). In the distributed world, it hasn't gone away but it's not necessary to have one, you can get all funky and complicated with your branching model. However, as far as I can tell, most folk seem to have incorporated a replacement (for the concept of a trunk) into the branching model they choose to work with. Mine is the working model I described earlier and I essentially have a trunk by name that I never make changes to directly, only by merging branches into it, but I don't have to work that way.
If you think about it, then without some kind of process to join together, all the different changes being made to a project, potentially by different people (or even just by you), then you'd have anarchy. I think the historical VCSs like Subversion achieved this control by hierarchy with the trunk being the top of the hierarchy. In the distributed world, the people and the project decide how to do it rather than being told how to do it by the VCS, i.e., they define a working model which must have something in it that, conceptually, is like a trunk.
Merge
Making branches circular, or joining them back to the trunk, or joining them with another branch. Whatever, it's the process by which different branches get joined up. Essentially, it's the reverse of branching. So if branching creates two independent copies of a single version of your code, then merging takes two independent versions and creates a new single version that incorporates both. Let's say you start with version 1 (branch A) with a single file in it (index.php). Then you create a new branch, B, and add a second file to branch B (menu.php) and add a different file to branch A (footer.php). The two branches are now quite different. If you now merge those two branches, you create a new version that contains all three files.
If you prefer pictures, then try and follow the image below. If you prefer words, then I've added a verbal description of the picture also. As before, the blue rectangles represent the snapshots and the arrows represent you making changes. One of those types of changes is not actual coding, but the merging of two snapshots to create a new one, i.e., B2 and C2 being merged to make B3. Also A3 and B4 being merged to create A4.

Two feature branches being merged towards the trunk
- Start with version A1 in branch A (the trunk).
- Create branch C from A1, make some changes to create C1.
- Make some more changes to create C2.
- Switch back to A1, make some changes to create A2.
- Create branch B from A2, make some changes to create B1.
- Make some more changes to create B2.
- Do NOT make changes to B2 but merge C2 into B2 to create B3.
- Make some more changes to create B4.
- Switch back to A2, make some changes to create A3.
- Do NOT make changes to A3 but merge B4 into A3 to create A4.
There are no changes made to B2 in order to create B3, unlike B1 to B2 or B3 to B4 for example. The change set for B3 is created by the merging of C2 into B2. Same goes when merging A3 and B4
Commit / Revision
Making a commit creates a new revision (version), i.e., a snapshot of your code at that moment in time. That snapshot isn't like a full backup, it's more like a set of instructions to re-create that version, the starting point and the change set.
So, you're developing a new product called FootBook and you want to add a feature called ToeCracker. So you divide the process up into three steps, Load, Aim and Fire. Having completed development of the first step (Load), you decide to keep a permanent record of progress so far. You make a commit. This fixes a record in the version control database of the state of the project at that point in time. You can then start work on the Aim part of the ToeCracker feature. If the first effort at Aim goes totally pear-shaped, you can revert back to the good state in a flash by rejecting all of the changes you've made so far (or only some of them), you don't have to go hunting for the backup you made 3 weeks ago and manually unpick it all.
Once you successfully finish the Fire feature (and ToeCracker is finished), you can then merge the commit you made at that point in time back into your trunk. ToeCracker is now a part of your trunk, the one you FTP to the live server, so next time you update the FootBook website, the ToeCracker feature is available for everyone to try out.
Creating the ToeCracker feature
It also allows you to temporarily stop working on ToeCracker and start work on a different feature in a different branch then later switch back to ToeCracker without losing any of the changes you'd made, i.e., commits aren't necessarily the end of something, they can just be a convenient stopping point, you can do one before you go to bed every night if you want, nobody cares. They only care about the final commit at the end of that branch.
Staging
After finishing Load, you start work on Aim and make changes to three files, A, B and C. You're ready to make a commit but the changes to C aren't really relevant to Aim, they should be part of Fire, so you don't want them to be included, you want to save them for the next commit, when you've finished Fire.
Easy, before each commit, you have to stage the files (the changed ones) that you want to be included in the commit. If you don't stage one of them, it retains its changes but the commit ignores them, i.e., the commit uses the unchanged version of C (from the prior version), but you haven't lost your changes, you've just delayed committing them; so they don't go into that version within the database, they'll go into a later one.
Just don't forget to accept changes before a commit, even if they aren't staged, otherwise you lose them, though you'll often get a warning and will get an opportunity to cancel the commit.
Push and Pull
You probably don't need to worry about this at all if you are working alone and particularly if you'll only ever work locally. Unless you use cloning as a way of branching.
Since I haven't worked with a remote repository, I stand to be corrected here.
So let's say Sam wants to help with FootBook. Therefore you now need to use a remote repository so that you and Sam can share updates with each other and you start a project on GitHub. When you finish a new feature in your local repository, you then Push that change to the remote repository. Sam can then Pull it from the remote repository into his local repository. Now, you both have fully up to date copies of the project (and all the history of how it changed) without needing to send USB sticks to each other in the post.
Pushing and Pulling between repositories
You only ever push and pull between different repositories.
Fork
A fork is essentially a permanent branch, often moved into a different repository. You could do away with the term branching and just call it temporary forking.
So you and your mate Sam are working on FootBook. You've both been developing features of FootBook, pushing your completed features (made in your local repository) to a remote repository as we discussed immediately above.
Then Sam gets really drunk and throws beer all over you, sleeps with your partner and tells you that you'll never be friends again. FootBook is dead.
So you pull all the changes from the remote repository into your local repository (so that you have a fully up to date copy including all of Sam's work). You use this to create a new project called AnkleBook. The history books, when writing about the immense commercial success of AnkleBook (and its multi-billionaire founder), will note that it started as a Fork of FootBook whilst the original project floundered in the hands of a philandering drunk and became nothing of any note.
Clone
Before you make any changes to your new copy of the code that was FootBook, the AnkleBook repository is a clone of FootBook and the mechanism you used to create the new AnkleBook repository would be to clone the FootBook repository. Cloning is how you create a fork in a separate repository.
Forking a project by cloning
You can also use cloning as a branching model (a heavyweight branching model). Create a clone, make changes, commit them and then Pull the clone into your original repository. It's called heavyweight since you create two big copies of the same thing, two sets of folders and two databases.
It's also how you would get your first copy of an existing project (e.g., the Linux Kernel) that you want to get involved with. So, using our example, having lost Sam, you ask George' to get involved, George clones the remote AnkleBook repository and starts work in his new local repository.
Merge Conflict
So you and George have been working on AnkleBook for a while and you've developed a new feature called FootLinker. During development of FootLinker you made changes to the ligament.cs file. Unfortunately, so did Sam whilst developing the ShinLinker feature. When Sam Pulls your FootLinker feature into his local repository and tries to merge it with his ShinLinker feature, the VCS throws a wobbly since there are different changes to the same file. Who wins?
When it's really easy, because you made changes to different parts of the ligament.cs file, the VCS can often work it out for you, automagically. However, what if you both made different changes to the same line of code? At that point, you usually have to step in and help the VCS choose what to do and sometimes pick up the pieces afterwards.
Same thing can happen even when working on your own. What if you have two branches in your repository? Because you are working on two new features simultaneously (and therefore, you could make conflicting edits to the same code), you can create a merge conflict for yourself. It's no different, same process, only you have to argue with yourself instead of having Sam throw beer at you again.
Diff
Diff, unsurprisingly means difference and usually refers to a tool or the output of that tool, often built into the VCS itself or available as an external plug-in. The VCS uses it to spot exactly what has changed between an older and the current version of a file, or even the same file in two different branches. And they are very clever, even when you make a change near the beginning such as an extra line of code or two it doesn't think everything below that is also a change, it works it out. So it really does only identify actual changes, edited lines, removed lines and added lines are all spotted and treated as such.
I think the output of the diff tool is also how the VCS records changes - i.e., makes a change set, so the change set is far smaller than a total backup of the project would be. It's used to do the automagic handling of conflicts and probably all kinds of other exciting stuff I haven't discovered yet. Amazing little things.
Labels, Tags, Bookmarks, Etc.
We're starting to get into the minutiae now and these terms definitely get different interpretations between different VCS options. They provide ways to do lightweight branching, record major milestones (minor and major releases) etc. Probably not that important right now.
My Use Case
It's worth pointing out that my experiences are based on developing a PHP based website, not using a VCS with something like a Visual Studio project so I can't guarantee that the principles hold true but it feels as if they should.
In particular, the issue I faced and that set me off looking into version control was that my manual model for version control was as follows:
- Hold two copies of the entire source code, one in a folder called prod (production) and one called dev (development)
Prod should always represent what's on the live server and dev is where I did my work until it was ready to go live- Each time an update was ready to go live, I would zip the prod folder as a version and store it in
archive and then copy dev into prod then FTP prod to the live server
That worked just fine until I needed to make both content changes and feature additions, if I was part way through the development of a feature addition, how could I use my manual version control model to add some new content? I was about to hit a major roadblock to keeping the site up to date since I was part way through a pretty big feature enhancement.
Finally, it's worth noting that I have not tested (to any extent) their repository hosting options, I have tried them but not in real anger - there's only me, I don't really need the distributed part, just the version control part. So Subversion might have been fine, but it doesn't seem like the future and all the DVCS's profess to being suited to single user scenarios just as much as distributed, multi-developer environments.
Comparing VCS Options
I did a bunch of reading around the internet and you very quickly realise that your primary choices are probably Bazaar, Git and Mercurial. There are others, of course. However, there aren't many guides out there for newcomers to version control, mostly the articles start from the premise that you are already using and familiar with a VCS, almost always Subversion, which makes finding guidance that's useful to me pretty hard work. The particular page that made me choose Bazaar as my first option is this one, by Smashing Magazine. I had no reason for why I should trust that particular website over any others, except that the style of writing seemed somewhat more aimed at my level of knowledge and needs than how most of the others came across.
So, I started with Bazaar since the description sounded more aligned to me. In particular, the article said:
- 'Mercurial was designed for larger projects, most likely outside the scope of designers and independent Web developers', so ignore Mercurial for now
- 'However, Git isn't as easy to pick up as CVS or SVN, so it's much harder to use for a beginner', again we'll ignore Git for now.
- Whilst for Bazaar, the key line (for me) was 'As shown with the workflows, you can use it to fit almost any scenario of users and setups', sounds a bit more like it.
I now have my own and quite different view of how I would describe them, read on...
Bazaar it was then.
And since I was used to working with two different copies (prod and dev), I wanted to have two clones and did not use branching (regretfully).
Bazaar and Launchpad
Bazaar is an open-source project sponsored by Canonical. Plenty of well-known open-source projects use Bazaar and its associated remote server, Launchpad, namely Ubuntu, Debian, MySQL, Bugzilla etc., so it clearly has some good support and is therefore likely to be pretty capable, but what about for a newcomer?
Bazaar Explorer: Looks friendly enough
In Windows, there's perfectly reasonable GUI client, Bazaar Explorer. The standalone Windows installer also provides options for adding TortoiseBzr (Shell extensions - think Explorer right click), Git integration and Subversion integration plus some other options that are probably important to more serious (professional) users.
My main testing was done with Bazaar Explorer and whilst I said perfectly reasonable above, that was from a 'does it feel like a friendly place to be?' perspective. Once I started to try and use it, I came unstuck very quickly. Just working out how to translate what I wanted to do (in my head) into Bazaar language so that I could press the right button was hard. I was back and forth to the docs like a Yo-Yo in the hands of the Yo-Yo world champion. Oh, and the docs are a bit sparse. All in all quite frustrating.
For example, what about creating a new project. Project is what Bazaar seems to call a repository but I couldn't be quite sure.
Bazaar Create Project: Anyone know what type of workspace model I want?
Seriously, if those hints said "If you flibble your flobble, then you can create a flooble" then I'd have a better idea of what was going on. And do I want to move existing files? Or create a work checkout? Absolutely no idea.
Is this a fair assessment so far? Well possibly not, Bazaar was my first attempt at version control so I should expect to struggle a bit, but for a tool described as 'you can use it to fit almost any scenario of users and setups', I shouldn't be fighting this hard. The docs for working solo, the Solo Workflow say this:
- Create Project.
- Record Changes (making commits along the way).
- Browse History (look at comments for the commit or changes between two commits, i.e., change sets).
- Package Release (tagging and labelling).
Really? You shock me! And how do I do that? Stony silence. Even non-Canonical guides and documents didn't help that much. I fought for a while thinking it was me (and it still might be) but eventually gave up. I need more help than that, either by the tool being intuitive or really good documentation, Bazaar doesn't manage either.
One other note on Bazaar is the Launchpad integration, not my key need, but I did try it out. Once a project is created on Launchpad, it's there forever, even if it has nothing in it, because they don't want folk deleting projects that others may be relying on. I get that, in the open-source world that's a key thing to worry about, but my project had nothing in it! Very frustrating. So it's hard to use Launchpad in sandbox mode whilst you get used to it and try out its features, learn the ropes, etc.
Back to being fair, I said before that some pretty big companies and projects use Bazaar and Launchpad so it must have more going for it than I found, but this is about choosing a VCS for a beginner and for me, Bazaar isn't it. Maybe it would be easier once I get much more familiar with DVCS in general and can then apply general knowledge to using Bazaar, I might risk it one day.
Git and GitHub
OK, so onwards to Git. Git gets so much attention it has to be worth a try and anyhow Mercurial wasn't suited to independent Web Developers so I only had one other choice.
The history of Git is plastered all over the place, originally developed by Linus Torvalds (apparently after a bit of a spat with BitKeeper, no idea, haven't read up about it). Now maintained by a large army and used by some pretty big names, Microsoft, Google, Android, facebook, Rails, the list goes on. So once again, it must have something going for it but what about for a newcomer?
Installing Git on Windows provides shell integration (as TortoiseBzr did for Bazaar) and a GUI, imaginatively entitled GitGUI. Boy is that thing sparse! It's certainly clutter-free, minimum information possible at any given time and not a right click menu in sight. That style of training might have worked for the Karate Kid but I don't have Mr Miyagi to help. Clearly designed for folk who already know exactly what they are doing. That's not me.
GitGui: Erm, what now? Do I need to paint the fence again?
And the visualization of the revision history (the graphlog) isn't a lot better. It's not bad per se, it's just that user-friendly was not high on the list of priorities (seemingly), think function over form. So GitGui got binned pretty damn quickly.
Maybe it's not actually that bad
A hunt around the internet led me to SmartGit, a commercial Git Client that's free for non-commercial use. Apparently, you can also use it with Mercurial and Subversion.
SmartGit: OK, this feels a bit more welcoming.
SmartGit has a much more pleasant working environment than does GitGUI so you don't start-off totally daunted. The Marketing blurb even says 'SmartGit helps Git and Mercurial beginners to get started quickly'. I was quite willing to believe them. Then I hit a big old stumbling block, how to do my desired working model, i.e., clones. No amount of reading Git manuals or the much lauded online Pro Git book helped me out of that hole.
However, I wasn't giving in that easy so I thought I'd play a while and see how making commits works and try the integration with GitHub. Yup, soon fighting again. You have to worry about staging and un-staging before committing - and that didn't feel so well integrated into SmartGit - so I'd keep forgetting. In Git and SmartGit's defence, it's all very obvious conceptually, but it just didn't feel like a natural part of the workflow, i.e., the tool isn't helping an idiot do the right thing despite himself!
The revision history (graphlog) window is a bit more inviting than GitGui's also.
SmartGit Revision Visualization Window (Graphlog)
Is this fair? Well maybe if I had switched to using branches earlier then I'd have found more success with Git and SmartGit but a bit like with Bazaar the learning curve, even just in language terms, was steep, really steep. And as I noted above, I have enough of a learning curve going on with PHP, VB and .NET to feel like taking on another one, so it got abandoned.
Mercurial and BitBucket
Mercurial is another open source project that was created for the same reason that Git was (which I still haven't read up on the details of), apparently it started within a few days of Git (one way or the other) and whilst the Linux Kernel development moved to Git rather than Mercurial, Mercurial can still claim some big names, though as sponsors this time (it's harder to tell who's using Mercurial for big name projects), the sponsors include Google, Microsoft and Mozilla to name but a few.
TortoiseHg: There's a lot going on, but it's not hard to work out what to do.
So with some trepidation, given this was supposed to be harder than the other two, I installed Mercurial. As a standard Windows install it comes with TortoiseHg. Now this version of Tortoise is different to that written for Bazaar because it's also a GUI not just a shell extension (TortoiseGit is also a shell extension not a GUI).
OK, so TortoiseHg is a very pleasant place to work, a bit like SmartGit. Let me not overemphasize this, but for me something like GitGUI vs. SmartGit or TortoiseHg is like the difference between and old DOS based word processor versus MS Word (or LibreOffice) today. It's really that big and for a beginner, it can make the world of difference to just being able to do stuff and focus on what you actually enjoy - coding, this is most likely a hobby for beginners, not a job, I want to get on with the fun bit.
But what about actually doing something? Well, step one was being able to clone and to do so easily. Bingo, I did some content updates in the original, made commits along the way and when ready, FTP'd to the live server and bingo, sorted. Meanwhile, I'm busy working on that feature in the clone. Once the feature was done, I pulled the changes from clone repository into the original repository (where I'd been making content updates) and voila, the feature changeset (its full history included) was then just part of my original repository, as a big old branch. Now just merge the feature branch into the code with the content updates and bingo, sorted (again).
In the image I've shown above, you can see the revision history (graphlog) is always there, which I find handy. To switch between creating the new commit (as shown) and reviewing what would be in the commit if you did it right now, you just click a toolbar button at the top. Then the bottom half of the screen changes accordingly. And then the layout stays the same in both views, beautiful, someone thought about this. The layout (in the bottom half) works like this, files on the left, commit comments on the right (top) and detailed changes within the selected file on the right (bottom). You can see:
- Modified files in blue, marked with an M
- Removed files in red, marked with a ! if I haven't accepted the deletion and an R if I have
- Added files where I've accepted the addition in green, marked with an A
- Added files where I've haven't accepted the addition in pink, with a ?
- Staged files have ticks in the checkbox
- A space to make comments about this version when I commit, shown right top
- The detailed changes to the selected file (scoresmenu.php) shown right bottom
So much nicer than anything I've worked with so far.
Seeing that pulling from a clone into the original repository just created a branch made me think more about branching and I now do that exclusively. So I might have a default branch*, a content update branch (when I need one, they tend to be short lived) and a feature branch (or two, or more). I can work on them independently, easily switch between them, easily merge a completed content update or new feature into the default branch, FTP it to the live server and I'm done. I can also have several feature branches running at the same time.
* You always have a default branch in Mercurial and unless you're branching with bookmarks or anonymous branches (which I am not) then for me the tip of the default branch is always the same as the live server, which is handy, i.e., I am using Mercurial's default branch as the trunk.
Is this fair? It's hard to say definitively that it's better than Git since I didn't try Git with branching but I still have a sense that there's something about Mercurial that's easier in terms of the learning curve, maybe if I went back to Git today, I'd find it that much easier. Would it be easier or better than Mercurial? Not sure. You could say that Git is probably more common and any desire you harbour for becoming involved with open source multi-contributor development is more likely to be done with Git than Mercurial, but for me, I'd guess that it's a pretty even choice with pros and cons on both sides. Maybe use Mercurial to get started and I think you'd find moving to Git straightforward, the reverse move is probably pretty easy too, but maybe Mercurial is better for 'learning the ropes'.
It's also worth noting for the is it fair discussion that much of what I am debating might be down to the GUI rather than the underlying VCS but I do think that's a really important part of the experience and the learning curve for a beginner so I do believe it's relevant (in the context of this discussion) to use it as an integral part of the judgement. And TortoiseHg is a real winner for me in this respect.
Finally on Mercurial: I mentioned staging and un-staging for Git and that I found it didn't feel like a natural part of the workflow (be that GUI based or VCS based), well Mercurial essentially has the same thing, changes vs. the prior commit are highlighted (in TortoiseHg) and you accept or reject them, then there's a tick box per changed file that pretty much replicates the staging and un-staging of Git, but it's just more obvious and natural to use. Want to accept all changes but only commit some of them, check those you want to commit, make a commit and then keep working, the accepted but not committed ones just become part of your next commit (if you want, or delay it further). In my case, I mostly commit all changes so I just tick all of them (which can be done with a single click).
Oops, that wasn't finally, you also get the TortoiseHg Overlay Icon Server, which provides a visual icon overlay on the standard Explorer icons that represent the state of the file in your repository, unchanged, added, changed etc., very nice (I think TortoiseGit has something similar). I've also uploaded the repository to BitBucket (which hosts both Git and Mercurial repositories), easy enough, no better or worse than GitHub as far as I can tell.
I've written much more about Mercurial than the other two, I've used it more. There's a reason for that.
Wrapping Up the Comparison
It's clear that I prefer Mercurial, I felt more confident and found it easy to work with, it didn't distract me from developing the website, when I made mistakes (be they version control mistakes or coding mistakes), it was pretty easy to undo, you can even rollback a commit if you realise fast enough (you might be able to do that in the others as well, I didn't get that far).
There may be excess influence of the GUI in my judgement here but for me, that was important and I think it's important for many beginners who don't come from a command line background or have no prior version control experience. This may be the single biggest reason I prefer Mercurial, because TortoiseHg is just better for me and my wonky head.
There may also be a strong influence from my way of thinking, maybe Mercurial / TortoiseHg just fit my head better than the others do, who knows?
I'd highly recommend beginners give Mercurial a try and in particular use it with TortoiseHg. Experiment with the others too, you might find them better for you.
For Bazaar, I can't put my finger on what it is about Bazaar Explorer that I found hard, looking back at it now it seems almost as if it's trying to be too simple, almost like a Wizard tool rather than something unobtrusive that just works with you. And boy did Launchpad annoy me.
For Git, I do think that it's easier than I found it initially, particularly since I now have a better idea of version control (especially the benefits of distributed, branch centric DVCS, even for solo use), the terms and concepts used, etc. but I also think the learning curve is steeper than that of Mercurial, particularly if you use GitGUI (shudders). GitGUI is the opposite of how I've just described Bazaar Explorer but not in a good way.
I have since been back to Git (to create some of the screenshots above) and I did find branching much easier then previously and I'm sure I'd remember to stage and unstage eventually. However, I couldn't get past the idea that the learning curve is steeper, it's just not as intuitive as I found Mercurial (with TortoiseHg).
Give them a try, even if your project doesn't scream at you that it would benefit from version control (maybe you think it's too small and simple), you may just find that it turns out to be useful in ways you might not expect. Even if you only ever work locally, never have any intention of using BitBucket or GitHub or getting involved with an open source project, that's not a requirement, being able to trace back through your changes, branch different features and separate things like content and features (for websites anyway) is really handy, more so than I realized when I started.
Other Notes
Arguably, I'm now going off-topic since this was supposed to be about choosing for your first VCS but I think these notes are close enough to the purpose - helping someone who's never used version control to get started - that I don't mind, hope you'll forgive me.
Branching
This was one area that was initially confusing and part of the reason I started with wanting to clone - I just didn't want to try and learn branching as well as everything else. The concept sounds really easy but there are many branching models and different ways to branch in each VCS - not just different between two VCS, actually different ways within a VCS - which the heck one did I want to use? This guide to Mercurial branching is very helpful but when you have never done VCS of any kind, it sort of pushes you away from branching since you suddenly have too many options for something you don't entirely understand anyway, at least not to any depth.
The only guidance I could give is start simple, in Mercurial, you just create a named branch (easy to do), ignore the other ways of branching - in Mercurial, this is what Steve Losh describes as 'Branching with named Branches'. It also has the advantage, for me, that the tip of the trunk (default branch) always represents the live server and I never work on it directly, I always work in a named branch and merge that into the trunk when I'm ready to roll out that feature or content update - although this is getting into what has become the detail of my own personal branching model, I mention it only because I found it really easy to follow what I was doing when working this way!
Having said that, I really want to learn about the other ways of branching, including the patch queue feature of Mercurial that Steve doesn't mention, but named branches are really easy to get your head around and use. Give it a try.
Bug Fixes and Branches
A bit more on branching and something I'm still trying to figure out how to do.
OK, so say you have your trunk and a named feature branch that you have several change sets in (but which isn't finished). Then you discover a bug on the live server. Easy enough create a new named branch from the tip of the trunk that is to be used for the bug-fix, sort out the bug, merge that branch into the trunk and FTP it out to the live server. Job done. Only how do I get that bug fix into my feature branch? I might want to avoid having merge conflicts later by bringing the bug fix into the named feature branch now rather than working out the merge conflicts when the feature is complete (when I will, I want to merge that one with the trunk).
How do I get that bug fix into the feature branch?
I don't know how to do that yet, I think that if I was working in a 'proper' DVCS way with multiple developers, then I could just pull the relevant change set from the bug fix branch into my local repository and merge it with my code, sorting the merge conflicts as I go. Then when I push my feature branch to the remote repository, the bug fix is already in there and I won't get merge conflicts. Only I don't know how to replicate that when working locally. I have a feeling that Mercurial's patch queue might help me but I don't know and I can't get an answer to that question. Hey ho!
Maybe that's another difference between Mercurial and Git, I suspect there's slightly more support and knowledge available for Git since the community is probably an order of magnitude larger, hence more advice in forums, etc. (I did say more / better rather than just more but I have no basis on which to assume that more = better!)
Branching and Merging - Conflicts
One thing I worried about when branching, and it has bitten me once, was merge conflicts - i.e., when you make conflicting edits to the same code in two different branches that later need to be merged. I made a right royal &*^& up, fortunately Mercurial has a very easy to use rollback feature and hey presto, I was back to the state before I tried to merge and I could then work out how to manage it, which I did manually in the first case before then trying the merge again, i.e., I manually edited the relevant file in each version so that they were the same, so there was no merge conflict.
Later merge conflicts I handled with the built-in diff tool which isn't user-friendly in the way that TortoiseHg (or SmartGit) is, but it's not that bad once you start getting used to it. Part of my initial reticence also came from being a bit drunk when I first tried to use the merge tool (quite a lot drunk actually) at 2 a.m. - not smart! You can also plug-in a bunch of alternative diff tools so you can try several until you find one that 'fits your head'. Pretty sure this is the case for most VCS, not just Mercurial / TortoiseHg.
Working Locally
As I've noted previously, most of my work is done locally rather than via a remote repository hosted on GitHub, BitBucket, etc. and whilst a big thing for DVCS is the distributed bit, not just the version control bit I have found that it's entirely useful for local version control, you don't lose or compromise anything (that I've found so far) by not working from a remote repository. The only potential exception to that is the point I made above about moving specific changes between branches, but I suspect there's ways to do that when working locally also, I just haven't figured it out yet.
Another option, if you have a NAS device at home, would be to install Git server or Mercurial server on that. Then rather than having your project on your local drive, you could host it on your own server, clone the server repository to your local drive and push local changes to your server. If you then exposed that server through your firewall, you could access your 'remote' project repository from anywhere in the world.
IDE Integration
Since many of us use IDEs, it's a nice option, not everyone wants it - I don't use it at the moment - but it's nice to know that you have options. Git appears to have integration with Visual Studio, NetBeans and Eclipse. Mercurial looks similar, VS, Eclipse and NetBeans.
I don't use Eclipse nor NetBeans but a quick search of the extensions library from within VS reveals options for both Git and Mercurial. Whilst the first page of Google results for both those VCSs says the same as I have listed above. I haven't tested any of them though; I can manage quite easily enough with TortoiseHg.
Bazaar has a page on its Wiki dedicated to listing the IDE integration options, it appears to have many (including VS) but a VS extensions search pulls up a grand total of none - again, I haven't tested any of them.
Initially, I thought I would really benefit from IDE integration, but on reflection (at least for projects on a hobbyist scale), it's not necessary and since the VCS GUI tool (like TortoiseHg) is dedicated to the task it does a much better job than trying to hook it into the IDE with the inevitable consequences for the way information is presented to you (even if only on a screen real-estate basis).
Let me know, (or write your own article), if you test some of them.
Cross DVCS Interoperability
I haven't tested the interoperability bits but do remember some commentary during my reading phase that discussed the ability of all of these DVCS tools to interoperate with each other and also Subversion - there were substantial differences for each tool in how well they manage this, from poorly to brilliantly (the phrase works like black magic sticks out in my memory). However, it's nice to know that you are not completely lost if you pick one tool and then get involved with a project running on a different VCS, you might be able to use your preferred GUI with a project being managed with a different VCS. Using SmartGit with Git? Want to get involved with a project using Mercurial? SmartGit should be able to cope, so you minimize your headaches, you don't need to 'learn' Mercurial before getting involved.
There's an interesting blog post by John Szakmeister. He talks about how each tool manages to cope with accessing and playing nicely with a repository from one of the others and subversion also, I can't add anything beyond that and no doubt you'll find other blogs and articles out there on the same subject. However, for a beginner, it's only really important if you decide to get involved with a multi-developer project that's hosted on a different VCS than the one you choose for your own work, hence I can't imagine it's that important relative to some of the other elements I've touched on, at least not until you're well beyond needing my advice.
If you do read that article, then I would note this: His comments on Mercurial branching are in stark contrast to mine and I am not sure I understand his reasoning which runs along the lines of branches living in different folders. I don't get that at all (though he probably has far more credibility and knowledge than I), I have many named branches and have only one set of folders plus the repository database. When I want to switch branches I just Update to that branch and magically my single set of folders gets all the right files in it (removed, added and changed as appropriate). Maybe it's something to do with professional development or a multi-developer project and I just can't see it but even then I thought the point of a distributed VCS was that each developer had a local copy, made changes and commits, then synced with the server, so each developer can work on whatever branch they need to. Maybe I'll find out some day.
Useful Links
These are just a few of the places I found decent advice, commentary and guidance.
- A StackExchange discussion about choosing a VCS, read the top answer provided by dukeofgaming, some interesting pictures that might help you
- Joel Spolsky on Mercurial, starts with a comparison to Subversion (as so many do) but you can skip it
- Steve Bennet doesn't like Git. Might help explain why I found Git hard to get to grips with. An interesting comment (#5 in the August 3rd 2012 update) that says: Use Mercurial instead! Sure, if you’re the lucky person who gets to choose the VCS used by your project. Mercurial seems to get a lot of love, but not much use, weird.
Points of Interest
Just reading about this kind of stuff doesn't get you to your answer, you've got to get your hands dirty with each option and find out what works for you. Have fun doing so.
History
- Version 1: Original article

