Introduction
The article is a proposal for a mathematical parser implementation which uses polymorphic methods for fast evaluation of given expressions. Although this paper talks about parsing input text, it focuses on methods for fast calculation of a given mathematical formula. Very good performance can be achieved by generating opcode using basic assembler level instructions. The described library interprets a math formula and emits, in run-time, machine code (using standard 8087 directives) which calculates a given expression. This approach is a combination of lexical analysis algorithms with opcode manipulation techniques, widely used in compilers and virtual machines (platforms like .NET or Java).
Further tests have shown that the presented approach is very efficient and is almost as fast as math code generated during program compilation! It is also up to 30 times faster than other popular math parsers.
It's assumed that the reader is familiar with C/C++ programming and the basics of the Assembler x86 language.
Background
How Compilers Generate Code
Let's see how programs are performed inside a system, how compilers generate code, and how they operate on the computer's memory. The execution of each process in a system demands generally four kinds of memory areas:
- code area - This part of memory contains machine code - a series of instructions executed by the CPU.
- data segment - This segment contains static data and constants defined in the program.
- stack - The stack is responsible for storing program execution data and local variables.
- heap - Segments of memory that can be allocated dynamically (this part of memory is used by the
malloc or new operator).
The program executes a series of instructions from the code area using data from the data segment. When a program calls a function (in a so-called cdecl manner), it pushes on the stack all parameters defined in the function, a pointer to a place in the code area where it is already in, and performs a jump to the code responsible for executing the given function. The stack is also a place where local variables are stored - when they are needed, the proper amount of memory is reserved on the top of the stack.
Let's analyze how compilers generate code which is responsible for mathematical calculations on a simple function that calculates a math expression, (x+1)*(x+2):
float testFun( float x )
{
return ( x + 1.0f ) * ( x + 2.0f );
}
The compiler for the given function generates these assembler instructions:
PUSH ebp
MOV ebp,esp
FLD dword ptr [ebp+8]
FADD qword ptr [__real@3ff0000000000000 (1D0D20h)]
FLD dword ptr [ebp+8]
FADD qword ptr [__real@4000000000000000 (1D0D18h)]
FMULP st(1),st
POP ebp
RET
When the function is called, the caller pushes on the top of the stack a list of parameters and a pointer to the return code. In our example, the function has only one parameter (of type float), so at the moment of the function's execution, on the top of the stack, there are (in order):
- 4-byte float variable
- 4-byte return address
At the beginning of the function, the ebp register is saved on the stack (instruction PUSH ebp), and subsequently, the stack pointer (the esp register) is copied to ebp (MOV ebp,esp). After this operation, ebp points to a place on the stack where an old value of ebp is stored, ebp+4 points to a return address, and ebp+8 points to the parameter of the function (variable x of type float).
The next part of the code performs strictly mathematical calculations (8087 instructions) using a mathematical cooprocessor's internal stack. This stack contains eight registers symbolized by ST(0), ST(1), ..., ST(6). The top of the stack is ST(0). The compiler interprets the math formula (x+1.0f)*(x+2.0f) and generates the code which performs the calculations in sequence (with the usage of the mentioned stack):
- load variable
x on the top of the stack - ST(0) (instruction FLD) - add constant to ST(0) and store the result in ST(0)
- load variable
x on the top of the stack - ST(0) becomes ST(1), x is loaded to ST(0) - add constant to ST(0) and store the result in ST(0)
- multiply ST(0) by ST(1), pop the stack, and store the result in ST(0)
After these series of operations, ST(0) (the top of the floating point stack) contains the result of the given math formula. Subsequently, the program recovers the original value of the ebp register (POP ebp) and returns to the caller (RET). The output result is passed to the caller through the top of the math stack - register ST(0).
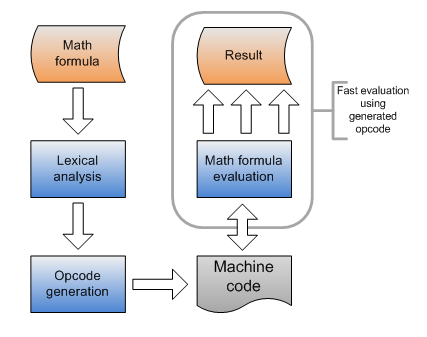
The basic idea of creating a fast mathematic parser is to create the code which will generate another code for calculation of the given math formula. The generated opcode should have the structure of the function presented above. When the program needs to use a math parser, firstly, it should perform the analysis of the mathematical formula and generate the opcode. After this, every time calculations are needed, the program should execute the generated code, giving the desired result. The main advantage of this approach is that the process of calculation is very fast and highly efficient - it is an imitation of the math executing the code which was generated during the program compilation.
Lexical Analysis
The basic issue in writing a mathematical parser is lexical analysis - it gives the structure of a given expression, and tells how a formula should be interpreted. Simple math expressions (with operators +, -, *, /, and parenthesis) can be described by a set of so-called productions:
EXPR -> TERM + TERM
EXPR -> TERM - TERM
EXPR -> TERM
TERM -> FACT * FACT
TERM -> FACT / FACT
TERM -> FACT
FACT -> number
FACT -> x
FACT -> GROUP
GROUP -> ( EXPR )
These operations describe how given expressions are built - how the set of input chars (non-terminals) can be brought out into smaller parts (terminals - like numbers, math operators, or symbols).
The production EXPR -> TERM + TERM means that the non-terminal EXPR can be divided into a sequence of non-terminal TERMs, char '+', and another non-terminal TERM. The non-terminal FACT, for example, can be brought out into number, a symbol x, or another non-terminal - GROUP.
These productions for a given mathematical expression define a parse tree (presented below) that represents the syntactic structure of the input string. Let's have a look at the example formula, (x+1)*(x+2). This expression can be derived from the non-terminal EXPR in this series of transformations:
EXPR -> TERM ->
-> FACT ->
-> FACT * FACT ->
-> GROUP * GROUP ->
-> ( EXPR ) * ( EXPR ) ->
-> ( TERM + TERM ) * ( TERM + TERM ) ->
-> ( FACT + FACT ) * ( FACT + FACT ) ->
-> ( x + 1 ) * ( x + 2 )

Productions (defined earlier) were used in each of these transformations. The knowledge of how a given production is used in the derivation process is useful in generating machine instructions for the calculation of a math formula.
Implementation
Using Spirit as a Syntactic Analyzer
The algorithm for lexical analysis is not an issue in this article - the paper describes only the basic knowledge which is needed to parse math formulas. Syntactic analysis can be performed by many (freely available) libraries. In this article, the Spirit library from the Boost package was used.
Spirit is a very useful and easy to use C++ tool, which takes advantage of modern meta-programming methods. The code below defines a grammar which is used to interpret simple math expressions:
class MathGrammar : public grammar<MathGrammar>
{
public:
template <typename ScannerT>
struct definition
{
definition( MathGrammar const& self )
{
expr = term >> *( ( '+' >> term )[ self._doAdd ] |
( '-' >> term )[ self._doSub ] )
;
term = fact >> *( ( '*' >> fact )[ self._doMul ] |
( '/' >> fact )[ self._doDiv ] )
;
fact = real_p[ self._doConst ] |
ch_p('x')[ self._doArg ] |
group
;
group = '(' >> expr >> ')'
;
}
rule<ScannerT> expr, term, fact, group;
rule<ScannerT> const& start() const { return expr; }
};
protected:
private:
AddFunctor _doAdd;
SubFunctor _doSub;
MulFunctor _doMul;
DivFunctor _doDiv;
ArgFunctor _doArg;
ConstFunctor _doConst;
};
The class MathGrammar derives from the grammar<MathGrammar> generic spirit class. It uses four non-terminals (expr, term, fact, and group). In the constructor of the internal class definition, productions for the grammar are defined. Productions are developed by using overloaded operators:
>> is an operator which merges nonterminals and terminals. For example, a>>b matches the expression ab.* is the Kleene star operator - the multiple concatenation of symbols inside parentheses. For example, *(a>>b) matches the expressions: ab, abab, ababab, etc.| is an OR operator. For example ,(a|b) matches expressions a or b.[] these brackets contain functors which will be called in case of usage of the given production.real_p is the terminal representing the constants - real numbers.ch_p('x') is a terminal representing the char x.
The usage of the presented class is very simple - during the process of expression parsing, when a given production is detected, a defined functor is called. The analysis is always performed bottom-up - this means that at first, productions are called from the bottom of the parse tree.
Let's analyze the formula (x+1)*(x+2) with the code given below:
MathGrammar calc;
if ( false == parse( "(x+1)*(x+2)", calc ).full )
{
}
During the parse procedure execution, the defined functors are called in order:
x argument (functor ArgFunctor _doArg)1 constant (functor ConstFunctor _doConst)+ operator (functor AddFunctor _doAdd)x argument (functor ArgFunctor _doArg)2 constant (functor ConstFunctor _doConst)+ operator (functor AddFunctor _doAdd)* operator (functor MulFunctor _doMul)
This order of operations can be directly used during the generation of the proper machine code for the calculation of the given formula. The obtained notation:
x 1 + x 2 + *
is a so-called Reverse Polish Notation (RPN) or postfix notation - operators follow their operands and no parentheses are used. The interpreters of RPN are often stack-based; that is, operands are pushed onto the stack, and when the operation is performed, its operands are popped from the stack, and its result is pushed back on.
The Machine Code Emission
The idea of the math parser described in this article is based on dynamic machine code generation during program run-time. The program interprets the input text (given by a user) using the syntactic analyzer - the input formula is transformed to a more suitable postfix notation, which can be calculated with the usage of the processor's math stack. After this analysis, the program generates the machine code which executes the process of evaluation of the math expression.
How do we generate the machine code in Windows dynamically? Firstly, the program must allocate a new memory segment with read/write access using the function VirtualAlloc (in the code below, it allocates 1024 bytes of memory).
#include <windows.h>
BYTE *codeMem = (BYTE*)::VirtualAlloc( NULL, 1024,
MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE );
if ( NULL == codeMem )
{
}
This memory will contain the body of the new function that will be generated. The code emitted into the allocated memory should have this structure:
PUSH ebp - save the base register ebp on the stack.MOV ebp,esp - put the current stack pointer esp into the base register ebp.- The series of mathematical calculations on the function parameter (the parameter is placed on the stack at the address
ebp+8). POP ebp - restore the saved base register ebp value.RET - return from the function instruction.
The table below describes the opcodes of instructions which should be emitted when the syntactic analyzer detects a mathematical operation:
| Assembler code | Machine opcode | Operation |
PUSH ebp | 0x55 | Save the base pointer on the stack. |
MOV ebp, esp | 0x8B, 0xEC | Move the stack pointer to the base pointer. |
FLD dword ptr [ebp+8] | 0xD9, 0x45, 0x08 | Load a float parameter (from ebp+8) to ST(0). |
FLD [mem32] | 0xD9, 0x05, xx, xx, xx, xx | Load the constant from a given address to ST(0) (the last four bytes are the address of the constant in memory). |
FADDP st(1), st(0) | 0xDE, 0xC1 | Add ST(1) to ST(0), store the result in ST(1), and pop ST(0). |
FSUBP st(1), st(0) | 0xDE, 0xE9 | Subtract ST(1) from ST(0), store the result in ST(1), and pop ST(0). |
FMULP st(1), st(0) | 0xDE, 0xE9 | Multiply ST(1) by ST(0), store the result in ST(1), and pop ST(0). |
FDIVP st(1), st(0) | 0xDE, 0xE9 | Divide ST(1) by ST(0), store the result in ST(1), and pop ST(0). |
POP ebp | 0x5D | Restore the base pointer from stack. |
RET | 0xC3 | Return from the function. |
The described instructions (which begin with Fxxx) operate on the processor's internal math stack, and always use at most two registers - ST(0) and ST(1). With their usage, the program can easily calculate every simple math expression. Of course, this list of mathematical operations can be extended to more sophisticated functions (like logarithms, trigonometric functions, root, power, etc.), but this article focuses only on the idea of machine code generation - for simplicity, it describes only simple math operators.
The instruction FLDS is responsible for loading mathematical values onto the stack, from memory. This operation will be used to load the parameter x or constants from the given math formula. The latter situation demands a special table (inside memory) with saved numeric values.
During the expression's parsing, the program creates a table with constants, which will be used during an evaluation process. When the syntactic analyzer detects a constant in a formula (for example, 1 in (x+1)) - it writes its value into the table, and emits the opcode FLD [mem32] with a pointer to a place in memory where the constant was saved. When the generated code is executed, this instruction loads the value of the given constant (read from memory) on the top of the stack.
After the process of opcode emission, the program should change the access rights of the allocated memory (given by the pointer codeMem) from read/write to execution only:
DWORD oldProtect;
BOOL res = ::VirtualProtect( codeMem, 1024, PAGE_EXECUTE, &oldProtect );
if ( FALSE == res )
{
}
After this operation, each process that tries to write into this memory will crash. In Windows systems, this approach insures protection from malware code injections. Execution of emitted code can be performed by using a simple code as shown below:
float ( *fun )( float );
fun = ( float ( __cdecl * )( float ) )codeMem;
fun( x );
Of course, when the generated formula evaluator is no longer needed, the allocated memory should be released:
if ( NULL != codeMem )
{
BOOL res = ::VirtualFree( codeMem , 0, MEM_RELEASE );
if ( FALSE == res )
{
}
}
Using the Code
The project attached to this article contains an example implementation of the described fast polymorphic math parser. The library is based on these classes:
MathFormula - Class containing code emission functionality. It encapsulates the handling of memory segments with the opcode to execute.MathGrammar - Class defining the mathematical expression grammar.AddFunctor, SubFunctor, MulFunctor, DivFunctor, ArgFunctor, ConstFunctor - The set of functors for handling math grammar productions.
The usage of the library is very simple:
#include "MathFormula.h"
MathFormula fun( "(x+1)*(x+2)" );
float result = fun( 2.0f );
The constructor of the MathFormula object performs a syntactic analysis of the input string by using the MathGrammar class. During the expression interpretation, proper functors are called when the given production rules are satisfied. Each functor invokes the emission methods in the MathFormula object - generating the machine code. After the initial analysis, math formulas can be evaluated with the usage of the overloaded parentheses operator.
The attached project can be compiled under Visual Studio 2008 with the usage of the Boost library. Information about the build process can be found in the ReadMe.txt file.
Summary
As we can see, the implementation of the math expression evaluator with the usage of dynamically generated machine code is quite simple. It is a combination of a syntactic analyzer (in this article, we used the Spirit library), a few WinAPI functions for memory allocation, and some basic knowledge about programming in Assembler.
The described implementation of the math parser has a very important advantage - it is almost as fast as the code generated statically during the program compilation! The table below shows the average math formula evaluation times for the expression (x+1)*(x+2)*(x+3)*(x+4)*(x+5)*(x+6)*(x+7)*(x+8)*(x+9)*(x+10)*(x+11)*(x+12), for different types of parsers:
| Math parser | Execution time [ns] |
| C++ | 20.7 [ns] |
| MathParser | 22.2 [ns] |
| muParser | 700.69 [ns] |
| uCalc | 762.36 [ns] |
| fParser | 907.07 [ns] |
The presented execution times are the average from 100 000 000 executions, and they all were performed on the processor: AMD Turion X2 2.0 GHz.
C++ stands for code generated by compiler during compilation. Our math parser (MathParser) execution time is only 7% worst than C++ code! In comparison, the table also contains execution times for mathematical parsers which are freely available on the internet - they are at least 30-35 times slower than MathParser!
Future Work
This article describes only an idea of a polymorphic math parser - of course, the presented code can be extended to more advanced solutions:
- more sophisticated mathematical functions could be used,
- the program could use more than one input function parameter,
- for better performance, optimizations on the generated opcode could be performed (for example: mathematical expression reduction),
- SIMD (Single Instruction Multiple Data) assembler instructions could be considered for much faster calculations on the whole vectors of values - the usage of the SSE processor's extensions.
Dynamically generated code techniques, borrowed from JIT (Just In Time) compilers, open new possibilities for very fast evaluation of given math expressions. Polymorphic math parsers could be applied in systems which need to perform fast, massive function evaluations for every math formula given by the user.
History
- 30 November 2009: Article creation
- 03 December 2009: Minor modifications

