Introduction
In the real world, some relationships are not linear. Thus, it is not suitable to apply linear regression to analysis of those problems. To solve the problem, we could employ tree regression. The main idea of tree regression is to divide the problem into smaller subproblems. If the subproblem is linear, we can combine all the models of subproblems to get the regression model for the entire problem.
Regression Model
Tree regression is similar to a decision tree, which consists of feature selection, generation of regression tree and regression.
Feature Selection
In decision tree, we select features according to information gain. However, for regression tree, the prediction value is continuous, which means the regression label is nearly unique for each sample. Thus, empirical entropy lack the ability of characterization. So, we utilize square error as the criterion for feature selection, namely,
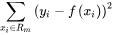
where Rm are the spaces divided by regression tree, f(x) is given by:

Thus, no matter what the features of sample are, the outputs in the same space are the same. The output of Rm is the average of all the samples' regression label in the space, namely:
The feature selection for regression tree is similar to decision tree, which aim to minimum the loss function, namely,
Generation of Regression Tree
We first define a data structure to save the tree node:
class RegressionNode():
def __init__(self, index=-1, value=None, result=None, right_tree=None, left_tree=None):
self.index = index
self.value = value
self.result = result
self.right_tree = right_tree
self.left_tree = left_tree
Like decision tree, suppose that we have selected the best feature and its corresponding value (j, s), then we spilt the data by:
And the output of each binary is:
The generation of regression tree is nearly the same as that of decision tree, which will not be described here. You can read Step-by-Step Guide To Implement Machine Learning II - Decision Tree to get more details. If you still have a question, please contact me. I will be pleased to help you solve any problem about regression tree.
def createRegressionTree(self, data):
if len(data) == 0:
self.tree_node = treeNode(result=self.getMean(data[:, -1]))
return self.tree_node
sample_num, feature_dim = np.shape(data)
best_criteria = None
best_error = np.inf
best_set = None
initial_error = self.getVariance(data)
for index in range(feature_dim - 1):
uniques = np.unique(data[:, index])
for value in uniques:
left_set, right_set = self.divideData(data, index, value)
if len(left_set) < self.N or len(right_set) < self.N:
continue
new_error = self.getVariance(left_set) + self.getVariance(right_set)
if new_error < best_error:
best_criteria = (index, value)
best_error = new_error
best_set = (left_set, right_set)
if best_set is None:
self.tree_node = treeNode(result=self.getMean(data[:, -1]))
return self.tree_node
elif abs(initial_error - best_error) < self.error_threshold:
self.tree_node = treeNode(result=self.getMean(data[:, -1]))
return self.tree_node
elif len(best_set[0]) < self.N or len(best_set[1]) < self.N:
self.tree_node = treeNode(result=self.getMean(data[:, -1]))
return self.tree_node
else:
ltree = self.createRegressionTree(best_set[0])
rtree = self.createRegressionTree(best_set[1])
self.tree_node = treeNode(index=best_criteria[0], \
value=best_criteria[1], left_tree=ltree, right_tree=rtree)
return self.tree_node
Regression
The principle of regression is like the binary sort tree, namely, comparing the feature value stored in node with the corresponding feature value of the test object. Then, turn to left subtree or right subtree recursively as shown below:
def classify(self, sample, tree):
if tree.result is not None:
return tree.result
else:
value = sample[tree.index]
if value >= tree.value:
branch = tree.right_tree
else:
branch = tree.left_tree
return self.classify(sample, branch)
Conclusion and Analysis
Classification tree and regression tree can be combined as Classification and regression tree(CART). Indeed, there exists prune process when generating tree of after generating tree. We skip them because it is a little complex and not always effective. Finally, let's compare our regression tree with the tree in Sklearn and the detection performance is displayed below:
Sklearn tree regression performance:
Our tree regression performance:
Our tree regression takes a bit longer time than sklearn's.
The related code and dataset in this article can be found in MachineLearning.
History
- 29th May, 2019: Initial version

