In this article, we discuss how to pre-configure SAP-HANA EML library, establish the connection to SAP-HANA SQL-engine programmatically, create, configure and execute a user-defined stored procedure that interacts with an instance of TensorFlow Model Server to perform the specific predictions.
Introduction
This is the final article in the series, in which we will discuss how to perform the prediction of S&P 500 Index stocks market indicator values using the SAP-HANA AI data analysis foundation. In this article, we will introduce and discuss about the code, implementing the SAP-HANA client application that triggers the S&P 500 Index prediction on the SQL-engine backend using EML-library. Specifically, we will discuss how to pre-configure SAP-HANA EML library, establish the connection to SAP-HANA SQL-engine programmatically, create, configure and execute a user-defined stored procedure that interacts with an instance of TensorFlow Model Server to perform the specific predictions. Also, we will discuss how to fetch and visualize the prediction results obtained using the user-defined stored procedure.
Setup SAP-HANA EML Library Configuration
To have an ability to predict S&P 500 Index on the SAP-HANA SQL-engine backend using the model previously built and exported, we must first update the SAP-HANA EML library configuration. To do that, we must connect SP500 tenant database using Eclipse SAP-HANA Studio Add-in and execute the following SQL-script:
SET SCHEMA SP500;
INSERT INTO _SYS_AFL.EML_MODEL_CONFIGURATION VALUES _
('sp500_model' , 'RemoteSource', 'TensorFlow');
DROP REMOTE SOURCE "TensorFlow";
CREATE REMOTE SOURCE "TensorFlow" ADAPTER "grpc" CONFIGURATION 'server=localhost;port=8500';
DROP TABLE CHECK_PARAMS;
DROP TABLE UPDATE_CONFIGURATION_PARAMS;
DROP TABLE UPDATE_CONFIGURATION_RESULT;
DROP PROCEDURE UPDATE_CONFIGURATION;
CREATE TABLE UPDATE_CONFIGURATION_PARAMS ("Parameter" VARCHAR(100), "Value" VARCHAR(100));
CREATE TABLE UPDATE_CONFIGURATION_RESULT _
("Key" VARCHAR(100), "Value" INTEGER, "Text" VARCHAR(100));
CREATE PROCEDURE UPDATE_CONFIGURATION() AS
BEGIN
DECLARE CURSOR CUR FOR
SELECT VOLUME_ID FROM SYS.M_VOLUMES WHERE SERVICE_NAME = 'indexserver';
FOR CUR_ROW AS CUR DO
EXEC 'CALL _SYS_AFL.EML_CTL_PROC_
(''UpdateModelConfiguration'', UPDATE_CONFIGURATION_PARAMS, UPDATE_CONFIGURATION_RESULT)'
|| ' WITH OVERVIEW WITH HINT(ROUTE_TO(' || :CUR_ROW.VOLUME_ID || '))';
END FOR;
END;
TRUNCATE TABLE UPDATE_CONFIGURATION_RESULT;
CALL UPDATE_CONFIGURATION();
CREATE TABLE CHECK_PARAMS ("Parameter" VARCHAR(100), "Value" VARCHAR(100));
INSERT INTO CHECK_PARAMS VALUES ('Model', '*');
CALL _SYS_AFL.EML_CHECKDESTINATION_PROC(CHECK_PARAMS, ?);
The following code listed above, first inserts the row to _SYS_AFL.EML_MODEL_CONFIGURATION internal system table, providing the model and remote source name. After that, it creates a remote source that will use the grpc protocol to communicate with TensorFlow Model Server (TMS). In the remote source creation clause, we must specify a proper configuration such as TMS-server domain name or IP-address, as well as the port used to establish the TMS-server connection. In this case, we use the default configuration parameters since the TMS-server is running on the same host as the SAP-HANA SQL-engine.
Next, the following script creates two tables UPDATE_CONFIGURATION_PARAMS and UPDATE_CONFIGURATION_RESULT, to store the remote source configuration parameters. The first table will consist of parameter and value columns, and the second one – key and value columns respectively. After that, we create a stored procedure UPDATE_CONFIGURATION() that will trigger another UpdateModelConfiguration built-in EML library procedure to update the model configuration on the EML-library backend. The UpdateModelConfiguration procedure inserts the EML-library configuration parameters to those tables that have been previously created, using the SP500 tenant database index server volume-id.
Finally, what we have to do is to create CHECK_PARAMS table and insert the row containing two values of either “Model” and “*” into the following table. Also, we must call a built-in _SYS_AFL.EML_CHECKDESTINATION_PROC procedure that actually accepts a single parameter of CHECK_PARAMS table previously created.
Connect to SAP-HANA SQL-Engine Programmatically
To predict S&P 500 Index on the SAP-HANA SQL-engine backend, we must implement SAP-HANA Python client application that connects to the SQL-engine programmatically and imports the evaluation dataset from sp500.csv file to the SP500 database previously created.
To prepare the evaluation dataset, we will use functions that we’ve already implemented and discussed in the previous article. Specifically, we will load the entire dataset from csv-file to Pandas data frame and then prepare it for importing to SP500 database. First, what we must do is to retrieve a set of column names of the dataset loaded into Pandas data frame. This data will further be used for creating a specific table in SP500 database that will contain stocks pricing values for each company, at each moment of time (i.e., timestamp), as it has already been discussed in the previous article. After that, we will need to retrieve the actual stock pricing values from the same Pandas data frame, converting it to the Python’s generic list. Finally, we will use the already implemented get_datasets(…) function to prepare the evaluation dataset:
train_ratio = 0.8
filename = "sp500.csv"
dataset = pd.read_csv(filename);
columns = dataset.columns;
dataset = dataset.values.tolist()
(train_X, train_Y, test_X, test_Y,
train_min_vals_X, train_max_vals_X, train_min_vals_Y, train_max_vals_Y,
test_min_vals_X, test_max_vals_X, test_min_vals_Y, test_max_vals_Y) = \
get_datasets(dataset, train_ratio)
After we’ve prepared the specific evaluation dataset, now it’s time to establish a connection to SP500 tenant database to create a specific table that will be used to store the S&P 500 Index evaluation data used for prediction by our model previously built and exported. Before opening the specific connection, we must first define several connection parameters as follows:
tf.app.flags.DEFINE_string ('f', '', 'kernel')
tf.app.flags.DEFINE_string ('hxeinst_host' , '192.168.0.177' , 'HXE host')
tf.app.flags.DEFINE_integer('hxeinst_port' , 39041 , 'HXE port')
tf.app.flags.DEFINE_string ('hxeinst_db' , 'SP500' , 'HXE database name')
tf.app.flags.DEFINE_string ('hxeinst_user' , 'SP500' , 'HXE user name')
tf.app.flags.DEFINE_string ('hxeinst_passwd' , 'Ezantj7912' , 'HXE password')
args = tf.app.flags.FLAGS
Finally, we must invoke the functions listed below to establish the connection:
connection = dbapi.connect(address=args.hxeinst_host,
port=args.hxeinst_port, user=args.hxeinst_user,
password=args.hxeinst_passwd, database=args.hxeinst_db)
cursor = connection.cursor()
Also, we must execute the SET SCHEMA SP500; SQL-clause to select a proper tenant database.
cursor.execute('SET SCHEMA SP500;')
Since we’ve already established the connection to the SP500 tenant database, now we can import the evaluation dataset to the following database by dynamically creating a specific SP500_DATA table and inserting the specific data from the dataset that has been already prepared.
Import Evaluation Dataset To SAP-HANA Database
To import the evaluation dataset to SP500 tenant database, we must create the SP500_DATA table dynamically. For that purpose, we must programmatically construct an SQL-query that creates the specific table. To do that, we must use the columns list retrieved from the Pandas data frame. A fragment of code listed below, first creates a list of columns along with FLOAT SQL-datatype for each column and then joins this list into a single string containing each column name and its data-type. After that, we construct a formatted string containing the specific SQL-clause used for creating the SP500_DATA table:
try:
cursor.execute('DROP TABLE SP500.SP500_DATA;')
except (RuntimeError, TypeError, NameError, dbapi.Error):
pass
columns = [col + ' FLOAT' for col in columns.tolist()]
columns = ','.join(np.array(columns)[2:]).replace('.','_')
query = 'CREATE TABLE SP500.SP500_DATA ({0});'.format(columns)
cursor.execute(query)
After we've created the specific SP500_DATA table, now we can insert the evaluation data to it by running the following code:
for row in test_X:
vals = ','.join([str(val) for val in row]);
query = 'INSERT INTO SP500.SP500_DATA VALUES ({0})'.format(vals)
cursor.execute(query)
In this code, we loop over each row in our evaluation dataset and dynamically create SQL-query string. For each row, we retrieve the stock pricing values from each column and append them to the specific list, joined into a comma-separated string. After that, we construct an SQL-query string, that, when executed, inserts all column values for each row into the SP500_DATA table. Actually SP500_DATA table has the same structure as our original dataset.
Predict S&P 500 Index Using SAP-HANA EML Library
Since we've already created the SP500_DATA table and imported the dataset to the following table, now it's time to discuss how to predict S&P 500 Index on the SAP-HANA SQL-engine backend. This is typically done by creating and configuring the specific EML user-defined procedure that communicates with a running instance of TensorFlow Model Server (TMS), in which the S&P 500 prediction model is currently served.
Before creating such procedure, we must first perform several configuration steps such as creating three configuration tables:
SP500_PARAMS - The following table contains the parameters such as model and its signature, remote source name and deadline duration.SP500_PROC_PARAM_TABLE - This table is used to store the EML user-defined procedure parameters, including the name of parameters table (e.g., SP500_PARAMS), the evaluation data table name (e.g., SP500_DATA), as well as the prediction resultant table SP500_RESULTS;SP500_RESULTS - The table, in which the prediction results are stored, when returned by the EML user-defined procedure.
Here's a fragment of code that implements the EML user-defined procedure pre-configuration:
try:
cursor.execute('DROP TABLE SP500.SP500_PARAMS;')
except (RuntimeError, TypeError, NameError, dbapi.Error):
pass
cursor.execute("CREATE TABLE SP500_PARAMS _
(\"Parameter\" VARCHAR(100), \"Value\" VARCHAR(100));")
cursor.execute("INSERT INTO SP500_PARAMS VALUES ('Model', 'sp500_model%sp500_prediction');")
cursor.execute("INSERT INTO SP500_PARAMS VALUES ('RemoteSource', 'TensorFlow');")
cursor.execute("INSERT INTO SP500_PARAMS VALUES ('Deadline', '10000');")
try:
cursor.execute('DROP TABLE SP500.SP500_RESULTS;')
except (RuntimeError, TypeError, NameError, dbapi.Error):
pass
cursor.execute("CREATE TABLE SP500_RESULTS (SP500INDEX FLOAT);")
try:
cursor.execute('DROP TABLE SP500.SP500_PROC_PARAM_TABLE;')
except (RuntimeError, TypeError, NameError, dbapi.Error):
pass
cursor.execute("CREATE COLUMN TABLE SP500_PROC_PARAM_TABLE _
(POSITION INTEGER, SCHEMA_NAME NVARCHAR(256), TYPE_NAME NVARCHAR(256), \
PARAMETER_TYPE VARCHAR(7));")
cursor.execute("INSERT INTO SP500_PROC_PARAM_TABLE VALUES \
(1, CURRENT_SCHEMA, 'SP500_PARAMS' , 'in');")
cursor.execute("INSERT INTO SP500_PROC_PARAM_TABLE VALUES \
(2, CURRENT_SCHEMA, 'SP500_DATA' , 'in');")
cursor.execute("INSERT INTO SP500_PROC_PARAM_TABLE VALUES \
(6, CURRENT_SCHEMA, 'SP500_RESULTS' , 'out');")
After we've created the specific parameters tables and added the user-defined procedure parameters required, we can now create an EML user-defined stored procedure that performs the actual prediction. This is typically done by executing the following code:
cursor.execute("CALL SYS.AFLLANG_WRAPPER_PROCEDURE_DROP(CURRENT_SCHEMA, 'SP500');")
cursor.execute("CALL \"SYS\".\"AFLLANG_WRAPPER_PROCEDURE_CREATE\" _
('EML', 'PREDICT', CURRENT_SCHEMA, 'SP500', \"SP500_PROC_PARAM_TABLE\");")
Finally, our S&P 500 Index user-defined SP500 stored procedure is ready for execution. To execute the following procedure, we must implement the following code:
cursor.execute("CALL \"SP500\" (\"SP500_PARAMS\", \"SP500_DATA\", \
\"SP500_RESULTS\") WITH OVERVIEW;")
The following procedure accepts three main parameters, including the SP500_PARAMS table that contains the procedure's basic execution paramaters, SP500_DATA - a table containing our evaluation dataset and SP500_RESULTS table that contains the prediction results returned from the TensorFlow Model Server. After the following procedure is successfully executed, we must query the SP500_RESULTS table to retrieve all prediction results. To do this, we must implement the following code:
cursor.execute("SELECT * FROM \"SP500\".\"SP500_RESULTS\";")
predicted = cursor.fetchall()
results = []
for row in predicted:
results.append(row["SP500INDEX"]);
In this code, we execute the SELECT * FROM SP500.SP500_RESULTS query to fetch all prediction results and append each resultant row to a Python's generic list. After that, we can evaluate and visualize the results. To visualize the results, we must execute the following code:
test_Y = denormalize(test_Y, test_min_vals_Y, test_max_vals_Y)
results = denormalize(results, test_min_vals_Y, test_max_vals_Y)
plt.plot(np.array(test_Y), color='blue')
plt.plot(np.array(results), color='red')
cursor.close()
connection.close()
Prior to visualizing the results, we must first denormalize the resultant set using denormalize(...) function previously implemented. To plot a graph visualizing the resultant set of predicted S&P 500 Index values, we must use Python's matplotlib.pyplot library. The visualized prediction results are shown in the figure below:
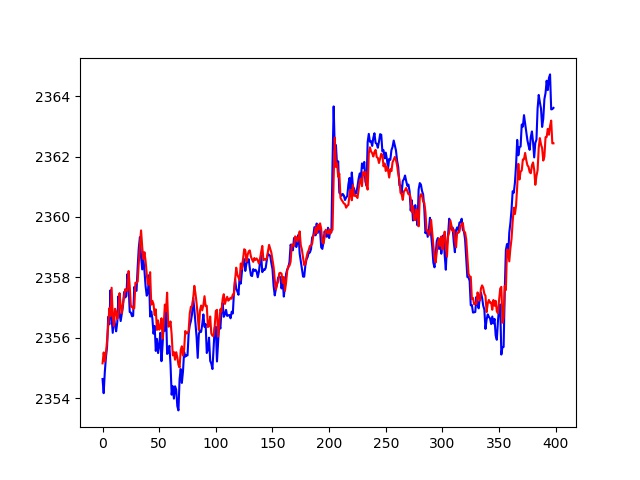
Conclusion
In the following series of articles, we've thoroughly discussed how to use SAP-HANA Express 2.0 to predict S&P 500 Index stocks market indicator values using SAP-HANA AI data analysis foundation. Specifically, we've discussed the number of aspects of deploying SAP-HANA virtual server from a "scratch", as well as how to build and export S&P 500 Index prediction model using TensorFlow and how to serve it using TensorFlow Model Server (TMS). In this final article, we've introduced the concepts of using SAP-HANA AI data analysis features, such as EML-library to perform the prediction on the SQL-engine backend.
History
- 29th September, 2019 - Initial version published

