This is an article about many of the synchronization mechanisms available to C++ developers creating high performance, scalable, software for the Windows platform. To set things in perspective, we start out by creating a simple I/O completion port based server, receiving 5GB/s sent by one hundred concurrent clients.
Introduction
This article is about the synchronization mechanisms available on the Windows platform using the Visual C++ compiler and the Windows API. To simplify the use of some of the synchronization mechanisms, I have created a set of classes that mainly wraps concurrency mechanisms provided by the Windows API:
WaitableHandle: Base class for waitable Windows kernel objects
EventWaitHandle: A class for working with Windows kernel event objectsMutex: A class for working with Windows kernel mutex objectsSemaphore: A class for working with Windows kernel semaphore objectsWaitableTimer: A class for working with Windows kernel waitable timer objectsThread: A thread class, similar in spirit to std::thread, but derived from WaitableHandle since threads are also waitable Windows kernel objectsProcess: A class for executing other processes. Like threads, processes are waitable Windows kernel objects
ThreadGroup: A class that allows you to work with threads on a group levelTimerQueue: A class that provides an interface to Windows timer queuesTimerQueueTimer: A class representing a Windows timer queue timerCriticalSection: A class for working with Windows critical section objects, satisfying C++ 11 BasicLockable and Lockable requirementsSynchronizationBarrier: A class for working with Windows synchronization barriersSlimReaderWriterLock: A class for working with Windows slim read/writer objects, satisfying C++ 11 BasicLockable, Lockable and SharedMutex requirementsConditionVariable: A class for working with Windows condition variablesInterlockedLinkedList: A class for working with Windows interlocked linked listsConcurrentQueue: An efficient bounded multi-producer/multi-consumer queueSpinlock: A spinlock based on std::atomicIO::Context: A Windows IO completion port served by a thread pool
The classes are part of a larger effort that enables you to easily create native server software on Windows using C++, and clients in both C# and C++. Unit tests are implemented using boost test, and so far I have implemented more than 630 test cases. There are also, currently, 23 example programs.
The solution has two main libraries, Harlinn.Common.Core and Harlinn.Windows, where Harlinn.Common.Core contains classes that are useful for both server and client development, and the Harlinn.Windows library contains classes that are useful for UI development. To ease integration with software developed for the .NET platform the Harlinn.Common.Core library provides classes that are compatible with their .NET counterparts, such as:
GuidDateTimeTimeSpantemplate<IO::StreamReader StreamT> BinaryReadertemplate<IO::StreamWriter StreamT> BinaryWriter
Data serialized using the C++ implementation of BinaryReader and BinaryWriter can be serialized and deserialized using the .NET implementation of BinaryReader and BinaryWriter found in the IO namespace of the Harlinn.Common.Net library. If you need to process XML, then the classes in HCCXml.h lets you do that with a minimum of fuss. The Currency class implements a fixed point type compatible with the COM CY type, and Variant is a class that makes it easy to work with the COM VARIANT type. I have implemented support for two noSQL database engines: Microsofts Extensible Storage Engine and the Lightning Memory-Mapped Database.
The Harlinn.Windows library will implement functionality for UI development. Both GDI and DirectX2D is supported for rendering, and event handling is based on boost.signals2.
Build Instructions
Instructions for building the code are provided in Build.md located in the $(SolutionDir)Readme folder.
Related Articles
This article belongs to a series of articles focusing on server development for the Windows platform.
- Using C++ to Simplify the Extensible Storage Engine (ESE) API - Part 1, an introduction to the Extensible storage Engine
- Using C++ to Simplify the Extensible Storage Engine (ESE) API - Part 2, an implementation of a data layer using the Extensible storage Engine
- Hello C#! C++ at Your Service, the implementation of a client library in C# for .NET Core and a server written in C++
This is an ongoing project, and the code provides classes that demonstrate that writing performant servers in C++ does not have to be hard.
Background
Before going into the details, I would like to provide a scenario where choosing the right synchronization mechanisms will have a huge impact.
I have developed server software for Windows for more than 20 years and have come to a real appreciation of facilities provided by the platform. My experience is that the I/O completion port mechanism is a very useful feature of the Windows API that can be used to implement efficient and scalable solutions.
I/O completion ports can be thought of as an efficient multi-producer, multi-consumer queue, that is tightly integrated with the Windows I/O subsystem. They can be used as a thread pool, executing asynchronous function calls:
IO::Context context( 8 );
context.Start( );
context.Async( []( )
{
printf( "Hello from thread pool\n" );
} );
context.Stop( );
and, as the name implies, they can be used for I/O.
Sending and Receiving 5GB/s
I/O completion ports is a key technology that enables us to create performant, scalable, servers. To appreciate just how well this works, we should keep in mind that I am testing this on a laptop, capable of writing about 27 GB/s to memory.
The IO::Context is a class that makes it relatively easy to create a multithreaded server. It is responsible for the I/O completion port and manages the thread-pool used to handle server-side activity.
To demonstrate, we first need a simple client:
void Client( ThreadData& threadData, size_t count )
{
Socket clientSocket( AddressFamily::InterNetworkV6,
SocketType::Stream,
ProtocolType::Tcp );
Address address( 42000 );
clientSocket.Connect( address );
clientSocket.Write( &count, sizeof( count ) );
Int32 index = static_cast<Int32>( threadData.index );
clientSocket.Write( &index, sizeof( index ) );
std::vector<Record> records;
records.resize( 2000, Record{Guid(),
DateTime( static_cast<Int64>( index + 1 ) ),index + 1, 1.0 } );
size_t sent = 0;
while ( sent < count )
{
clientSocket.Write( records.data( ), records.size( ) * sizeof( Record ) );
sent += records.size( );
}
}
The client first sends the number of records it intends to send, then the index of the threadData structure, before sending the requested number of records.
Then something on the server side to receive the data:
class Protocol
{
std::vector<ThreadData>& threadData_;
public:
Protocol( std::vector<ThreadData>& threadData )
: threadData_(threadData )
{ }
template<IO::StreamReader StreamReaderT, IO::StreamWriter StreamWriterT>
bool Process( IO::BinaryReader<StreamReaderT>& requestReader,
IO::BinaryWriter<StreamWriterT>& replyWriter )
{
std::vector<Record> records;
records.resize( 200000 );
size_t count = requestReader.ReadUInt64( );
Int32 index = requestReader.ReadInt32( );
size_t received = 0;
while ( received < count )
{
requestReader.Read( records.data( ), records.size( ) * sizeof( Record ) );
received += records.size( );
}
auto& entry = threadData_[index];
entry.stopwatch.Stop( );
entry.serverDoneEvent.Signal( );
return false;
}
};
Here, we first receive the number of records from the client, then the index into the threadData_ vector, and finally the records. When done, we signal the main function, which is waiting for the server to receive data from all the clients.
To create the TCP/IP based server, we just need to create an instance of the Server::TcpSimpleListener<> template instantiated for our implementation of the Protocol class that will attach itself to the context:
constexpr size_t ClientCount = 100;
constexpr size_t ThreadPoolSize = 12;
size_t PerClientRecordCount = 100'000'000;
std::vector<ThreadData> threadData;
for ( size_t i = 0; i < ClientCount; i++ )
{
threadData.emplace_back( ).index = static_cast<Int32>( i );
}
IO::Context context( ThreadPoolSize );
Address address( 42000 );
Server::TcpSimpleListener<Protocol>
listener( context, address, ClientCount, threadData );
The last argument, and any additional arguments, to the Server::TcpSimpleListener<Protocol> constructor will be passed to the Protocol constructor. An instance of Protocol class will be created for each of the connection handlers managed by Server::TcpSimpleListener<>, one for each socket connection that can be served concurrently as specified by ClientCount.
At this point, we have implemented the server, and we run it by starting the context:
context.Start( );
With the server up and running, it is time to start the clients:
stopwatch.Start( );
for ( size_t i = 0; i < ClientCount; i++ )
{
Thread thread( [&threadData, i, PerClientRecordCount]( )
{
Client( threadData[i], PerClientRecordCount );
} );
}
Now, we just wait for the server to receive data from all the clients:
for ( size_t i = 0; i < ClientCount; i++ )
{
auto& threadDataEntry = threadData[i];
threadDataEntry.serverDoneEvent.Wait( );
}
stopwatch.Stop( );
The program ends by telling us how much data was transferred between all the clients and the server:
Sent 10000000000 records in 71.646624 seconds using 100 concurrent client(s),
5.199534 GB per second.
Both the server and client are implemented by the same executable, and can be tested by building and executing:
HExContextPerf.exe
Synchronization using I/O Completion Ports
It is a good idea to structure your program in a way that minimizes the need for synchronization based on mechanisms that can cause the current thread to block. A TCP/IP based server that use an I/O completion port can be designed to ensure that there are no contentions between the threadpool threads for the objects that handle completion notifications for each of the connections.
ExampleSocketServer01 demonstrates this, and the client, ExampleSocketClient01, sends the expected data to the server.
The server is mainly implemented by two classes:
Listener: Manages the socket listening for incoming connection requests.ConnectionHandler: Manages the socket used for each concurrent connection, the current state of the connection, and receiving data from a client.
This is a very simple server, the client only sends two pieces of information:
- a header containing the number of sensor values that will be sent
- a sequence of sensor values
All of the I/O operations are performed asynchronously; and the server is implemented using a couple of low level C++ templates for implementing a TCP/IP based servers using IO::Context and I/O completion ports, that provides very little functionality beyond routing completion results to the implementation of the handler objects.
The design provides thread safety for the ConnectionHandler objects by ensuring that the server only executes a single asynchronous request for each instance of the ConnectionHandler at a time.
The main function is straightforward:
int main()
{
try
{
WSA wsa;
constexpr size_t ThreadPoolSize = 12;
IO::Context context( ThreadPoolSize );
Address address( 42000 );
Listener listener( context, address, 2 );
context.Start( );
puts( "Press enter to exit" );
while ( getc( stdin ) != '\n' );
context.Stop( );
}
catch ( std::exception& exc )
{
auto* message = exc.what( );
printf( "Exception: %s\n", message );
}
}
The implementation of the Listener class:
class Listener : public Server::TcpListenerBase<Listener>
{
template<typename DerivedT>
friend class SocketHandler;
public:
using Base = Server::TcpListenerBase<Listener>;
private:
CriticalSection criticalSection_;
Address address_;
boost::container::flat_map<SOCKET,
std::unique_ptr<ConnectionHandler>> connectionHandlers_;
public:
Listener( IO::Context& context, const Address& address,
size_t numberOfConnections )
: Base( context ), address_( address )
{
for ( size_t i = 0; i < numberOfConnections; ++i )
{
auto handler = std::make_unique<ConnectionHandler>( context, this );
connectionHandlers_.emplace( handler->Client( ).Handle( ),
std::move( handler ) );
}
}
The Listener creates an instance of the ConnectionHandler handler class for each connection it will be able to handle concurrently.
void Start( ) override
{
printf( "Starting listener\n" );
Server( ).Bind( address_ );
Server( ).Listen( );
for ( auto& entry : connectionHandlers_ )
{
Accept( entry.second.get( ) );
}
}
When the Start() function of the IO::Context class is called, it calls the Start() function of each the attached handlers. The Server() function returns a reference to the Socket object that is used to listen for incoming connection requests, and the Accept(...) function starts an asynchronous Accept operation:
void Accept( ConnectionHandler* connectionHandler )
{
auto* request = connectionHandler->GetAcceptRequest( Server( ) );
BeginAsyncAccept( request );
}
When an asynchronous Accept operation completes the framework, pass the pointer to the AcceptRequest object that was passed to the BeginAsyncAccept(...) function to the HandleAcceptCompleted(...) function:
bool HandleAcceptCompleted( AcceptRequest* request )
{
if ( request->IoResult( ) != ERROR_OPERATION_ABORTED &&
request->IoResult( ) != STATUS_CANCELLED &&
request->IoResult( ) != STATUS_LOCAL_DISCONNECT &&
request->IoResult( ) != STATUS_REMOTE_DISCONNECT )
{
auto acceptSocket = request->AcceptSocket( );
auto it = connectionHandlers_.find( acceptSocket );
if ( it != connectionHandlers_.end( ) )
{
it->second->HandleAcceptCompleted( request );
}
}
return true;
}
IoResult() returns the status of the request, and if the request was not cancelled, we just forward the call to the implementation of HandleAcceptCompleted implemented by the ConnectionHandler class. All I/O performed by the ConnectionHandler class is asynchronous, and values from the ConnectionHandlerState enumeration helps to keep track of the current state of the handler:
enum class ConnectionHandlerState
{
Unknown,
Accepting,
ReceivingHeader,
ReceivingValues,
Disconnecting
};
The Listener keeps track of each of the ConnectionHandler objects, and the ConnectionHandler keeps track of all the resources it requires:
class ConnectionHandler
: public Server::TcpConnectionHandlerBase<ConnectionHandler>
{
template<typename DerivedT>
friend class SocketHandler;
public:
using Base = Server::TcpConnectionHandlerBase<ConnectionHandler>;
private:
Listener* listener_;
ConnectionHandlerState state_;
size_t received_;
Stopwatch stopwatch_;
AcceptRequestBuffer header_;
WSABUF wsabuf_;
std::vector<SensorValue> records_;
std::unique_ptr<AcceptRequest> acceptRequest_;
std::unique_ptr<ReceiveRequest> receiveRequest_;
std::unique_ptr<DisconnectRequest> disconnectRequest_;
public:
ConnectionHandler( IO::Context& context, Listener* listener )
: Base( context ),
listener_( listener ),
state_( ConnectionHandlerState::Accepting ),
received_(0),
wsabuf_{}
{
}
The good thing is that the overhead added by the framework is truly insignificant, but you are also responsible for just about everything that goes on. The fun part of working with sockets is that you never know how much data you are going to receive until after the call:
bool HandleAcceptCompleted( AcceptRequest* request )
{
if ( request->IoResult( ) == NO_ERROR )
{
stopwatch_.Start( );
received_ = 0;
auto nextRequest = GetReceiveRequest( );
if ( request->NumberOfBytesTransferred( ) < request->NumberOfBytesToRead( ) )
{
state_ = ConnectionHandlerState::ReceivingHeader;
wsabuf_.buf = ((char*)request->Buffer( )) + request->NumberOfBytesTransferred( );
wsabuf_.len = request->NumberOfBytesToRead( )
- static_cast<UInt32>( request->NumberOfBytesTransferred( ) );
}
else
{
state_ = ConnectionHandlerState::ReceivingValues;
wsabuf_.buf = (char*)records_.data( );
wsabuf_.len = static_cast<int>( records_.size( ) * sizeof( SensorValue ) );
}
BeginAsyncReceive( nextRequest );
}
else
{
Disconnect( );
}
return true;
}
In this case, we provided enough space for the header, by passing the address of the header_ object to the constructor for the AcceptRequest:
AcceptRequest* GetAcceptRequest( const Socket& server )
{
if ( !acceptRequest_ )
{
acceptRequest_ = std::make_unique<AcceptRequest>( server,
Client(), &header_, static_cast<UInt32>(sizeof(Header)) );
}
else
{
acceptRequest_->Clear( );
}
return acceptRequest_.get( );
}
header_ is actually an AcceptRequestBuffer object, which is derived Header and adds the space required for the local and remote address information:
struct AcceptRequestBuffer : public Header
{
using Base = Header;
constexpr static size_t AddressInfoSize = AcceptRequest::CalculateBufferSizeFor( 0 );
Byte AddressInfo[AddressInfoSize];
AcceptRequestBuffer()
: Base(), AddressInfo{}
{}
};
If the request passed to HandleAcceptCompleted(...) received less than the number of bytes required for Header, it sets state_ to ConnectionHandlerState::ReceivingHeader and initiates an asynchronous read operation to read the remaining bytes of the header, or it sets state_ to ConnectionHandlerState::ReceivingValues to begin to receive values from the client.
The framework calls HandleReceiveCompleted(...) when the read operation completes:
bool HandleReceiveCompleted( ReceiveRequest* request )
{
if ( request->IoResult( ) == NO_ERROR )
{
if ( request->NumberOfBytesTransferred( ) < static_cast<size_t>(wsabuf_.len) )
{
wsabuf_.buf = wsabuf_.buf + request->NumberOfBytesTransferred( );
wsabuf_.len = wsabuf_.len -
static_cast<UInt32>( request->NumberOfBytesTransferred( ) );
request->Clear( );
BeginAsyncReceive( request );
}
else
{
switch ( state_ )
{
case ConnectionHandlerState::ReceivingHeader:
{
state_ = ConnectionHandlerState::ReceivingValues;
wsabuf_.buf = (CHAR*)records_.data( );
wsabuf_.len = static_cast<int>( records_.size( ) * sizeof( SensorValue ) );
request->Clear( );
BeginAsyncReceive( request );
}
break;
case ConnectionHandlerState::ReceivingValues:
{
if ( received_ + BatchSize < header_.RecordCount )
{
received_ += BatchSize;
wsabuf_.buf = (CHAR*)records_.data( );
wsabuf_.len = static_cast<int>( records_.size( ) *
sizeof( SensorValue ) );
request->Clear( );
BeginAsyncReceive( request );
}
else
{
received_ += BatchSize;
stopwatch_.Stop( );
auto duration = stopwatch_.Elapsed( ).TotalSeconds( );
auto pointsPerSecond = ( received_ ) / duration;
auto gbPerSecond = ( pointsPerSecond * sizeof( SensorValue ) ) /
( 1024ll * 1024 * 1024 );
wprintf( L"Received %llu records in %f seconds, "
"%f records and %f GB per second.\n",
received_, duration, pointsPerSecond, gbPerSecond );
Disconnect( );
}
}
break;
}
}
}
else
{
Disconnect( );
}
return true;
}
As long as no error occurs, it makes sure that the expected number of bytes has been received from the client. When the header is fully received, it starts to receive values, in batches of 20 000 at the time, and when all the values are received from the client, it begins an asynchronous disconnect:
void Disconnect( )
{
state_ = ConnectionHandlerState::Disconnecting;
auto nextRequest = GetDisconnectRequest( );
BeginAsyncDisconnect( nextRequest );
}
When the asynchronous disconnect completes, the framework calls:
bool HandleDisconnectCompleted( DisconnectRequest* request )
{
if ( request->IoResult( ) == NO_ERROR )
{
Destroy( );
}
return true;
}
Ideally, the framework would now reuse the connection, which is what a call to Accept() does; but, surprisingly, this actually degrades the performance of the server significantly. Destroy() calls the Listener implementation, causing it to close the socket and create a new ConnectionHandler.
void DestroyAndAddNewHandler( ConnectionHandler* connectionHandler )
{
std::unique_lock lock( criticalSection_ );
auto acceptSocket = connectionHandler->Client( ).Handle( );
auto it = connectionHandlers_.find( acceptSocket );
if ( it != connectionHandlers_.end( ) )
{
auto handlerPtr = std::move( it->second );
connectionHandlers_.erase( acceptSocket );
auto& context = Context( );
auto handler = std::make_unique<ConnectionHandler>( context, this );
auto newHandlerPtr = handler.get( );
connectionHandlers_.emplace( handler->Client( ).Handle( ), std::move( handler ) );
Accept( newHandlerPtr );
}
}
Using I/O completion ports efficiently, requires some understanding of concurrency, awareness of a few pitfalls, and some basic understanding of how certain things like memory allocation works.
Whether we are developing software in C#, Java or C++, our programs will use dynamically allocated memory. When allocating and releasing memory, the software is accessing something that must be treated as a shared resource. Memory can be allocated in one thread and released in another; both operations will at some point manipulate global structures, and if our software performs a huge amount of allocations and releases on each thread, the execution will be serialized around the memory management functions.
I would guess that at least 95% of the requests for dynamic memory made by a thread, is for small buffers with a very short lifetime. A good design would set aside some per thread, or session, memory to avoid unnecessary trashing of the memory subsystem. It can also be a good idea to pre-allocate a number of fixed size buffers that will be used for I/O. Interlocked Singly Linked Lists is a great mechanism for managing these buffers, providing an efficient mechanism that can be used to allocate and release buffers as needed by the threads of the thread pool serving the I/O completion port.
Based on this infrastructure, it is relatively easy to create servers that scale well, capable of servicing thousands of concurrent users.
Why We Need Synchronization
It is a common observation is that, over time, users tend to be interested in a common subset of the available data, and when this is the case, adding some sort of cache is very beneficial to the performance of the server. Having a per thread cache can make sense, but at some point, updates made by one thread, must be made visible to the other threads.
It is also common to create some sort of session that will represent a transactional context inside the server. When working with I/O completion ports, a session will usually be served by more than one thread, and sometimes it also makes sense to have more than one thread operating concurrently on behalf of a session. Read and write access to the sessions is obviously something that must be carefully managed, the same goes for the cache – and this is what synchronization is all about: Safe, and efficient, management of access to resources shared between multiple threads.
There is a wide range of synchronization mechanisms available, and to choose the right one for a particular task requires understanding of its basic behavior and its performance characteristics.
When it comes to performance, I am mostly interested in exploring atomic operations and the CRITICAL_SECTION object. I know CRITICAL_SECTION performs very well. Internally, it is partially implemented using atomic operations performed in the application address space, and it is easy to use. I also know that there are many pitfalls associated with using atomic operations, it is easy to end up with a design that mostly wastes CPU cycles – so identifying some of these pitfalls is useful.
Before going any further, we need to pick a trivial task that does not get in the way of the topic, and incrementing a value will be a theme for the rest of this article:
constexpr size_t MaxIterations = 4'000'000'000;
size_t result = 0;
auto stopwatch = Stopwatch::StartNew( );
for ( size_t i = 0; i < MaxIterations; i++ )
{
++result;
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
printf( "Result = %zu, duration = %f seconds\n", result, duration );
Output:
Result = 4000000000, duration = 0.000000 seconds
A quick look in the disassembly view, reveals what just happened:
mov edx, 0EE6B2800h
lea rcx, [string "Result = %zu, duration = %f sec@"... ( 07FF7474FE158h )]
call printf( 07FF747457000h )
0x0EE6B2800 is the same as 4 000 000 000. So, of course, the compiler optimized away the whole loop, creating a solution that executed in no time. This is, as determined by the compiler, the most efficient way to “count” to 4 000 000 000.
We will start by showing how interleaving “normal” code and atomic operations, which are considered a lightweight synchronization mechanism, can have a significant cost.
To prevent the compiler from optimizing the loop, we change it slightly:
constexpr size_t MaxIterations = 4'000'000'000;
size_t result = 0;
auto stopwatch = Stopwatch::StartNew( );
for ( size_t i = 0; i < MaxIterations; i++ )
{
_mm_mfence( );
++result;
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
printf( "Result = %zu, duration = %f seconds\n", result, duration );
Output:
Result = 4000000000, duration = 33.696560 seconds
_mm_mfence( ) is an intrinsic function that:
Perform a serializing operation on all load-from-memory and store-to-memory instructions that were issued prior to this instruction. Guarantees that every memory access that precedes, in program order, the memory fence instruction is globally visible before any memory instruction which follows the fence in program order.
Now we prevented both the compiler, and the CPU from doing anything clever, and every core will go to the L3 cache, or main memory for a multi CPU system, to ensure that it has an updated view of memory. This is done for each iteration – which is brutal and was accomplished using a single line of code.
Switching to std::atomic<size_t> for the counter, sees an improvement:
constexpr size_t MaxIterations = 4'000'000'000;
std::atomic<size_t> counter = 0;
auto stopwatch = Stopwatch::StartNew( );
for ( size_t i = 0; i < MaxIterations; i++ )
{
++counter;
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
size_t result = counter;
printf( "Result = %zu, duration = %f seconds\n", result, duration );
Output:
Result = 4000000000, duration = 17.257034 seconds
The above, performs about as well as using InterlockedIncrement, which is used internally by the implementation of std::atomic<size_t>; and it is still quite expensive.
I think this is important since the number of classes that use InterlockedIncrement and InterlockedDecrement for reference counting is huge, and executing code that bumps the reference count up and down inside a loop can severely degrade the performance of the program. This can often be easily avoided by just passing the object by reference, and not by value, even if the size of the object is just 64-bits. My point is that using atomics can, if used without care, significantly degrade the performance of our program.
Partitioning Take 1
To try to improve the performance of the counter, we partition the job across four threads:
constexpr size_t ThreadCount = 4;
constexpr size_t MaxIterations = 4'000'000'000;
constexpr size_t PerThreadIterations = MaxIterations / ThreadCount;
std::atomic<size_t> counter;
ThreadGroup threadGroup;
auto stopwatch = Stopwatch::StartNew( );
for ( int i = 0; i < ThreadCount; ++i )
{
threadGroup.Add( [&counter]( )
{
for ( size_t j = 0; j < PerThreadIterations; j++ )
{
++counter;
}
} );
}
threadGroup.Wait( );
stopwatch.Stop( );
size_t result = counter;
auto duration = stopwatch.TotalSeconds( );
printf( "Result = %zu, duration = %f seconds\n", result, duration );
Output:
Result = 4000000000, duration = 71.819745 seconds
This is significantly slower than the 17.25 seconds we got for the single-threaded case. If anything, this showed that frequent concurrent updates to atomic variables can seriously degrade the performance of our software.
Partitioning Take 2
To really improve the performance of the counter, we still partition the job across four threads:
constexpr size_t ThreadCount = 4;
constexpr size_t MaxIterations = 4'000'000'000;
constexpr size_t PerThreadIterations = MaxIterations / ThreadCount;
struct ThreadData
{
Int64 counter = 0;
};
ThreadData threadData[ThreadCount];
ThreadGroup threadGroup;
auto stopwatch = Stopwatch::StartNew( );
for ( int i = 0; i < ThreadCount; ++i )
{
auto& perThreadData = threadData[i];
threadGroup.Add( [&perThreadData]( )
{
size_t counter = 0;
for ( size_t j = 0; j < PerThreadIterations; j++ )
{
counter = Performance::Increment( counter );
}
perThreadData.counter = counter;
} );
}
threadGroup.Wait( );
stopwatch.Stop( );
size_t result = 0;
for ( int i = 0; i < ThreadCount; ++i )
{
result += threadData[i].counter;
}
auto duration = stopwatch.TotalSeconds( );
printf( "Result = %zu, duration = %f seconds\n", result, duration );
Where the Performance::Increment(…) is implemented in a separate DLL to ensure that it will be called for each iteration, and not optimized away:
Int64 Increment( Int64 value )
{
return ++value;
}
Output:
Result = 4000000000, duration = 1.472855 seconds
Each thread does a part of the job, placing the result in perThreadData.counter. threadGroup.Wait( ) waits for all of the threads to complete; and since this is done using a kernel mode wait, we can be sure that the main thread has an updated view of the data. The main thread then aggregates the result of each thread.
To efficiently parallelize a job, it is a good idea to:
- Partition the job into separate independent tasks
- Allocate required resources before executing the task
- Let each task run without performing operations that require synchronization
- Aggregate the results when all the tasks have run to completion
This may not always be possible, but it will give the best performance.
Replacing:
counter = Performance::Increment( counter );
with:
++counter;
This gets us where we really want to be, parallel execution of fully optimized code:
Result = 4000000000, duration = 0.001265 seconds
Obviously, the compiler was now able to evaluate the loop at compile time, so the four threads just returned the resulting value.
Counting this way is certainly contrived, but it keeps things simple and lets us focus on the topic.
Normal Program Operation
Normal program execution is oblivious to other threads executing in parallel, and a core on a modern Intel x86/x64 processor will sometimes be able to process as many as four instructions in parallel per cycle.
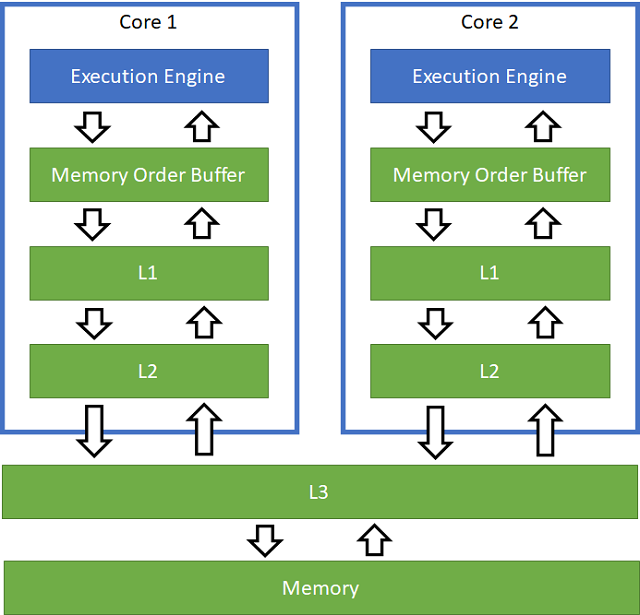
This is a kind of parallelism that is achieved because the processor can analyze cached instructions and cached data at runtime, and most of the time we are happy with this functionality.
The hierarchical cache design enables the processor to read and write to memory addresses very quickly, and it does not really matter if main memory is updated or not as long as the cache presents a consistent view of what is stored in memory to the core. Depending on how the thread access information in memory, the benefit to throughput can be significant:
- L1 cache access latency: 4 cycles
- L2 cache access latency: 11 cycles
- L3 cache access latency: 39 cycles
- Main memory access latency: 107 cycles
An optimally designed parallel program would keep every execution unit of every core busy with useful work. A thread can keep a core at full throttle, as long as it can move relevant data into the internal register file ahead of executing the operation that relies on it, and as long as the pipeline can write results back to the cache, without waiting for the operations to complete.
Sometimes though, a thread reaches a point where it must access information that may have been modified by another thread or update an address that may be of interest to another thread.
For this to be done reliably, we must use some sort of coordination mechanism, and this always comes at a cost in terms of performance.
As a rule-of-thumb, we should always strive to keep the required synchronization at a minimum.
If we are sure that data is not modified while accessed by multiple treads, then no synchronization is required – this can be used to great advantage while designing parallel code.
Atomic Operations
The purpose of atomic operations is to facilitate coordinated access to memory that may have been modified by multiple cores without flushing the entire cache and force the core to read everything back from memory. Atomic operations are performed by the processor, they are not an operating system service.
Both the standard template library and the Visual C++ compiler provide the functionality required to perform atomic operations on variables; and when nothing elaborate is required, using this functionality is often the simplest and best way to concurrently read from, and write to, data shared between threads. Implementing a mechanism for reference counting using InterlockedIncrement and InterlockedDecrement falls within this category.
The library provides a simple Spinlock class, implemented in HCCSync.h:
class Spinlock
{
private:
enum LockState
{
Locked, Unlocked
};
std::atomic<LockState> state_;
public:
constexpr Spinlock( ) noexcept
: state_( Unlocked )
{}
void lock( ) noexcept
{
while ( state_.exchange( Locked, std::memory_order_acquire ) == Locked )
{
}
}
bool try_lock( ) noexcept
{
return state_.exchange( Locked, std::memory_order_acquire ) == Unlocked;
}
void unlock( ) noexcept
{
state_.store( Unlocked, std::memory_order_release );
}
};
Using the Spinlock class is easy, here is a simple counter protected by a Spinlock, and a set of per thread counters that demonstrates that this is working as expected:
constexpr size_t ThreadCount = 4;
constexpr size_t ThreadIterationCount = 4'000'000;
struct Data
{
Spinlock spinlock;
size_t counter = 0;
};
Data data;
std::array<size_t, ThreadCount> threadCounters = {};
ThreadGroup threadGroup;
for ( size_t i = 0; i < ThreadCount; ++i )
{
threadGroup.Add( [i, &data,&threadCounters]( )
{
for ( size_t j = 0; j < ThreadIterationCount; ++j )
{
std::unique_lock lock( data.spinlock );
data.counter++;
threadCounters[i]++;
}
} );
}
puts( "Main thread waiting on background threads" );
threadGroup.join( );
printf( "Data counter: %zu\n", data.counter );
for ( size_t i = 0; i < ThreadCount; ++i )
{
printf( "Thread %zu counter: %zu\n",i, threadCounters[i] );
}
Output:
Main thread waiting on background threads
Data counter : 16000000
Thread 0 counter : 4000000
Thread 1 counter : 4000000
Thread 2 counter : 4000000
Thread 3 counter : 4000000
It is called a spin lock because the lock() function will busy-wait on the lock, burning CPU cycles until the lock is acquired. A spin lock like this should never be used as a drop-in replacement for a CriticalSection or Mutex, it is for situations where we know that the probability of contention is really low, and that the lock is short-lived, no more than a few hundred cycles. The whole point of atomic operations is to improve performance, and busy-waiting is not an efficient use of system resources.
I have seen a few spin lock implementations that place a call to Sleep(0) inside the while loop in the lock() function, and in my opinion, this defeats the purpose of the spin lock, as this will cause the thread to give up the rest of its current time-slice. Even if the documentation for Sleep states:
A value of zero causes the thread to relinquish the remainder of its time slice to any other thread of equal priority that is ready to run. If there are no other threads of equal priority ready to run, the function returns immediately, and the thread continues execution.
It is important to realize that Sleep(0) requires a round-trip to kernel mode, and here is a fragment that gives us some idea about the cost of calling of Sleep(0):
constexpr size_t Count = 10'000'000;
Stopwatch stopwatch;
stopwatch.Start( );
auto cyclesStart = CurrentThread::QueryCycleTime( );
for ( size_t i = 0; i < Count; ++i )
{
Sleep( 0 );
}
auto cyclesEnd = CurrentThread::QueryCycleTime( );
stopwatch.Stop( );
auto cycles = cyclesEnd - cyclesStart;
auto cyclesPerIteration = cycles / Count;
auto duration = stopwatch.TotalSeconds( );
printf( "Cycles per iteration %zu - loop done in %f", cyclesPerIteration, duration );
Output:
Cycles per iteration 1398 - loop done in 5.170509
When executed on an idle system, the above snippet demonstrates that calling Sleep(0) has a cost which is too high to be used as part of a spin lock – it would be much better to use a CriticalSection which performs significantly better.
Atomic operations can improve the performance of a program, and to give us an idea about how much, here are two implementations that use two threads to increment a counter. The first using std::atomic<size_t> for the counter, and the next using a 64-bit integer for the counter protected by a critical section.
constexpr size_t Count = 1'000'000'000;
std::atomic<size_t> counter = 0;
size_t cyclesThread = 0;
Stopwatch stopwatch;
stopwatch.Start( );
SynchronizationBarrier barrier(2);
Thread thread( [&barrier, &counter, &cyclesThread]( )
{
barrier.Enter( );
auto cyclesStart = CurrentThread::QueryCycleTime( );
for ( size_t i = 0; i < Count; i++ )
{
++counter;
}
auto cyclesEnd = CurrentThread::QueryCycleTime( );
cyclesThread = cyclesEnd - cyclesStart;
} );
barrier.Enter( );
auto cyclesStart = CurrentThread::QueryCycleTime( );
for ( size_t i = 0; i < Count; i++ )
{
++counter;
}
auto cyclesEnd = CurrentThread::QueryCycleTime( );
size_t cyclesMainThread = cyclesEnd - cyclesStart;
thread.join( );
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto cyclesPerIteration = (cyclesMainThread + cyclesThread ) / counter;
printf( "Cycles per atomic increment using two threads %zu in %f seconds\n",
cyclesPerIteration, duration);
Output:
Cycles per atomic increment using two threads 83 in 31.029148 seconds
Changing the above code to use a CriticalSection to protect the counter variable:
constexpr size_t Count = 1'000'000'000;
size_t counter = 0;
size_t cyclesThread = 0;
CriticalSection criticalSection;
Stopwatch stopwatch;
stopwatch.Start( );
SynchronizationBarrier barrier( 2 );
Thread thread( [&barrier,&criticalSection,&counter, &cyclesThread]( )
{
barrier.Enter( );
auto cyclesStart = CurrentThread::QueryCycleTime( );
for ( size_t i = 0; i < Count; i++ )
{
std::unique_lock lock( criticalSection );
++counter;
}
auto cyclesEnd = CurrentThread::QueryCycleTime( );
cyclesThread = cyclesEnd - cyclesStart;
} );
barrier.Enter( );
auto cyclesStart = CurrentThread::QueryCycleTime( );
for ( size_t i = 0; i < Count; i++ )
{
std::unique_lock lock( criticalSection );
++counter;
}
auto cyclesEnd = CurrentThread::QueryCycleTime( );
size_t cyclesMainThread = cyclesEnd - cyclesStart;
thread.join( );
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto cyclesPerIteration = ( cyclesMainThread + cyclesThread ) / counter;
printf( "Cycles per iteration using two threads with CriticalSection: %zu in %f seconds\n",
cyclesPerIteration, duration );
Outputs:
Cycles per iteration using two threads with CriticalSection : 164 in 67.675265 seconds
The implementation using std::atomic is nearly twice as efficient as the one using the CriticalSection, but if I change the implementations to use four atomic variables, all sharing the same cache line, vs four 64-bit integers protected by a single critical section, the latter outperforms the former by 32%.
While trivial, these examples illustrate how little leeway we have when we try to improve the performance of concurrent operations using atomic operations. They are a great way to implement efficient concurrent software, but it is a bit like brain surgery – we should not do it unless we have no other choice, and we know what we are doing.
Cache Line
If we still feel like giving atomic operations a try, we need to keep in mind that a cache line is the unit of data transfer between cache and memory, a cache line is typically 64 bytes. The processor will read or write an entire cache line when any address within the cache line is read or written. The processor will also try to prefetch cache lines by analyzing the memory access pattern for each core.
We should always make sure that independent data that requires synchronization between threads using atomic operations do not share the same cache-line.
Kernel Object Synchronization
Synchronization can be performed using several synchronization mechanisms that are backed by Windows kernel object implementations. These are the most heavyweight synchronization mechanisms provided by the Win32/64 API, and the most versatile:
- They can be named, putting them in the kernel object namespace.
- They can be used for inter-process synchronization.
- They can be secured.
- Child processes can inherit handles from the processes that either opened them or created them.
- We can specify a timeout, in milliseconds, when waiting for a kernel object to enter its signaled state.
- They can have a lifetime beyond the process that created them.
The Win32/64 API allows us to use the following kernel object types with synchronization:
- Thread
- Process
- File and console standard input, output, and error streams
- Job
- Event
- Mutex
- Semaphore
- Waitable timer
WaitableHandle
WaitableHandle is the base class for the classes that provide access to the kernel objects that a program can wait on. It has a single data member:
class WaitableHandle
{
private:
HANDLE handle_;
public:
...
};
WaitableHandle is move assignable, move constructible, but not copy assignable and not copy constructible. The implementation ensures that the lifetime of the handle is properly managed. The class, as the name suggests, implements functions that allows us to wait on a kernel object.
The Wait(…) function is a thin wrapper around the WaitForSingleObject(…) function:
bool Wait( UInt32 timeoutInMillis = INFINITE ) const
{
auto rc = WaitForSingleObject( handle_, timeoutInMillis );
if ( rc == WAIT_FAILED )
{
ThrowLastOSError( );
}
return rc == WAIT_TIMEOUT ? false : true;
}
The Wait(…) function returns true if the wait was successful, and the kernel object is in a signaled state, or false if the wait expired due to a timeout. If the WaitForSingleObject(…) function returns WAIT_FAILED indicating an error, Wait(…) will throw an exception containing the error code returned by GetLastError() and the accompanying error message provided by the OS.
When the WaitForSingleObject(…) returns, the cache will be in synch with main memory, and no further action is required by the thread to ensure safe access to the objects protected by the handle.
To provide compatibility with the std::lock_guard and other templates from the standard template library, WaitableHandle also implements:
void lock( ) const
{
Wait( );
}
bool try_lock( ) const
{
return Wait( );
}
It is up to the derived classes to implement the missing unlock( ) member function.
EventWaitHandle
The EventWaitHandle class provides a mechanism to notify a waiting thread of the occurrence of an event. This class wraps the Event kernel object and manage the lifetime of the handle.
There are two kinds of event objects: manual-reset and auto-reset. When an event enters a signaled state, a manual-reset event will release all the waiting threads for execution, while an auto-reset event will only release one of the waiting threads.
Events are often used when one thread performs some work and then signals another thread to perform work that depends on the work it has just performed. The event is created in a non-signaled state, and then after the thread completes its work, it sets the event to a signaled state. At this point, the waiting thread is released and can continue its operation.
The EventWaitHandle can be used like this:
EventWaitHandle event1( true );
EventWaitHandle event2( true );
Thread thread( [&event1, &event2]( )
{
puts( "Background thread signalling event1" );
event1.Signal( );
puts( "Background thread waiting for event2" );
event2.Wait( );
} );
puts( "Main thread waiting for event1" );
event1.Wait( );
puts( "Main thread signalling event2" );
event2.Signal( );
puts( "Main thread waiting for background thread to terminate" );
thread.Wait( );
Output:
Main thread waiting for event1
Background thread signalling event1
Background thread waiting for event2
Main thread signalling event2
Main thread waiting for background thread to terminate
Constructors
EventWaitHandle objects can be constructed in several ways, and the default constructor creates an empty object that can be move assigned another EventWaitHandle.
constexpr EventWaitHandle( ) noexcept;
explicit EventWaitHandle( bool manualReset, bool initialState = false,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit EventWaitHandle( LPCWSTR name, bool manualReset = true, bool initialState = false,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit EventWaitHandle( LPCSTR name, bool manualReset = true, bool initialState = false,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit EventWaitHandle( const std::wstring& name, bool manualReset = true,
bool initialState = false,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit EventWaitHandle( const std::string& name, bool manualReset = true,
bool initialState = false,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
If manualReset is set to true, the constructor creates a manual-reset event, otherwise, it creates an auto-reset event.
initialState specifies that the event will be created in a signaled state.
When a manual-reset event is signaled, it remains signaled until it is reset to non-signaled by the ResetEvent() function. All waiting threads, or threads that later begin to wait for the event, will be released when the object's state is signaled.
When an auto-reset event is signaled, it remains signaled until a single waiting thread is released, then the system automatically resets the state to non-signaled. If no threads are waiting, the auto-reset event remains signaled.
The name argument specifies a name for the event and the length must not be greater than MAX_PATH. If the name matches an existing event object, a handle to that event is created and the manualReset and initialState arguments are ignored.
securityAttributes specifies the SECURITY_ATTRIBUTES for the event. When the securityAttributes is nullptr, the event gets a default security descriptor with ACLs from the primary or impersonation token of the creating thread.
desiredAccess specifies the access mask for the event using values from the EventWaitHandleRights enumeration that can be combined using the ‘|’ operator.
None: No rightsDelete: The right to delete a named eventReadPermissions: The right to open and copy the access rules and audit rules for a named eventSynchronize: The right to wait on a named eventChangePermissions: The right to change the security and audit rules associated with a named eventTakeOwnership: The right to change the owner of a named eventModify: The right to set or reset the signaled state of a named eventFullControl: The right to exert full control over a named event, and to modify its access rules and audit rules
OpenExisting and TryOpenExisting
To access an existing event object, we use the OpenExisting(…) function, which has the following overloads:
static EventWaitHandle OpenExisting( LPCWSTR name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle OpenExisting( LPCSTR name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle OpenExisting( const std::wstring& name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle OpenExisting( const std::string& name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
The OpenExisting(…) functions will throw an exception if the event cannot be opened, while the TryOpenExisting(…) functions will return an empty EventWaitHandle.
static EventWaitHandle TryOpenExisting( LPCWSTR name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle TryOpenExisting( LPCSTR name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle TryOpenExisting( const std::wstring& name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
static EventWaitHandle TryOpenExisting( const std::string& name,
EventWaitHandleRights desiredAccess =
EventWaitHandleRights::Synchronize |
EventWaitHandleRights::Modify,
bool inheritHandle = false );
PulseEvent
The PulseEvent() function sets the event to the signaled state and then resets it to the non-signaled state after releasing the waiting threads as specified by the event type.
void PulseEvent( ) const;
A manual-reset event will release all the threads that can be released immediately. The function then resets the state of the event to non-signaled and returns.
An auto-reset event will release a single waiting thread and then reset the state of the event to non-signaled.
According to the documentation for the PulseEvent(…) Windows API function, this function should be avoided:
A thread waiting on a synchronization object can be momentarily removed from the wait state by a kernel-mode APC, and then returned to the wait state after the APC is complete. If the call to PulseEvent occurs during the time when the thread has been removed from the wait state, the thread will not be released because PulseEvent releases only those threads that are waiting at the moment it is called. Therefore, PulseEvent is unreliable and should not be used by new applications.
SetEvent and Signal
SetEvent and Signal sets the signaled state of the event object.
void SetEvent( ) const;
void Signal( ) const;
Signal just calls SetEvent, and using it can often make the intent behind the calling code clearer.
Setting an event that is already in the signaled state has no effect.
A manual-reset event remains signaled until it is set explicitly to the non-signaled state by a call to the ResetEvent() function. Waiting threads, and threads that begin a wait operation for the event, will be released while the state of the event is signaled.
An auto-reset event is signaled until a single waiting thread is released, it is then reset to non-signaled automatically.
ResetEvent, Reset and unlock
ResetEvent, Reset and unlock sets the event to a non-signaled state.
void ResetEvent( ) const;
void Reset( ) const;
void unlock( ) const;
Reset and unlock just calls ResetEvent. By implementing unlock, the class meets the BasicLockable requirements, allowing us to use templates such as std::lock_guard to wait on the event and automatically reset the event when the lock goes out of scope. Depending on our design, this may make sense.
Mutex
The Mutex is used to ensure that a thread has mutual exclusive access to an object.
The thread that owns a mutex can perform multiple wait operations on the Mutex without blocking its execution. This prevents the thread from deadlocking while waiting for a mutex that it owns. To release ownership of the mutex, the thread must call ReleaseMutex once for each successful wait operation.
The Mutex is a synchronization object that is set to signaled when it is not owned by a thread, and non-signaled when it is owned.
The Mutex class wraps the mutex kernel object and manage the lifetime of the handle. The class meets the BasicLockable requirements, allowing us to use templates such as std::unique_lock to acquire and release ownership of a mutex kernel object.
The Mutex class can be used like this:
size_t counter = 0;
Mutex mutex( true );
ThreadGroup threadGroup;
for ( int i = 0; i < 100; ++i )
{
threadGroup.Add( [i, &mutex, &counter]( )
{
auto id = i + 1;
for ( int i = 0; i < 10; ++i )
{
printf( "T%d: waiting\n", id );
std::unique_lock lock( mutex );
printf( "T%d: acquired mutex\n", id );
++counter;
printf( "T%d: value %zu\n", id, counter );
}
} );
}
mutex.unlock( );
puts( "Main thread waiting on background threads" );
threadGroup.join();
printf( "Final value %zu\n", counter );
The example created one hundred threads, where each thread takes a lock on the mutex and increments the value of counter ten times. The mutex is initially held by the main thread of the program and none of the “counter” threads can proceed until all the threads are created.
Output:
Main thread waiting on background threads
T1: waiting
T13: waiting
T2: waiting
T3: waiting
T4: waiting
T5: waiting
T6: waiting
T7: waiting
T20: waiting
...
...
T100: waiting
Main thread waiting on background threads
T83: acquired mutex
T83: value 2
T83: waiting
T76: acquired mutex
T76: value 3
T76: waiting
...
...
T3: value 998
T1: acquired mutex
T1: value 999
T2: acquired mutex
T2: value 1000
Final value 1000
Constructors
Mutex objects can be constructed in several ways, and the default constructor creates an empty object that can be move assigned another Mutex.
constexpr Mutex( ) noexcept;
explicit Mutex( bool initiallyOwned,
MutexRights desiredAccess = MutexRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Mutex( LPCWSTR name, bool initiallyOwned = true,
MutexRights desiredAccess = MutexRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Mutex( LPCSTR name, bool initiallyOwned = true,
MutexRights desiredAccess = MutexRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Mutex( const std::wstring& name, bool initiallyOwned = true,
MutexRights desiredAccess = MutexRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Mutex( const std::string& name, bool initiallyOwned = true,
MutexRights desiredAccess = MutexRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
If the caller created the mutex object and the initiallyOwned argument is true, the calling thread gets ownership of the newly created mutex object. More than one process can call CreateMutex, or CreateMutexEx which is called by the Mutex constructors, to create the same named mutex. The first process will create the mutex, and the other processes will just open a handle to the existing mutex. This allows multiple processes to get handles to the same mutex, without forcing the user to make sure that the creating process is started first. If we do this, then we should set initiallyOwned to false to avoid uncertainty about which process has the initial ownership.
The name argument specifies a name for the mutex object and the length must not be greater than MAX_PATH. If the name matches an existing mutex object, a handle to that mutex is created and the initiallyOwned argument is ignored.
securityAttributes specifies the SECURITY_ATTRIBUTES for the mutex. When the securityAttributes is nullptr, the mutex gets a default security descriptor with ACLs from the primary or impersonation token of the creating thread.
desiredAccess specifies the access mask for the mutex using values from the MutexRights enumeration that can be combined using the ‘|’ operator.
None: No rightsDelete: The right to delete a named mutexReadPermissions: The right to open and copy the access rules and audit rules for a named mutexSynchronize: The right to wait on a named mutexChangePermissions: The right to change the security and audit rules associated with a named mutexTakeOwnership: The right to change the owner of a named mutexModify: The right to set or reset the signaled state of a named mutexFullControl: The right to exert full control over a named mutex, and to modify its access rules and audit rules
OpenExisting and TryOpenExisting
To access an existing mutex object, we use the OpenExisting(…) function, which has the following overloads:
static Mutex OpenExisting( LPCWSTR name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex OpenExisting( LPCSTR name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex OpenExisting( const std::wstring& name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex OpenExisting( const std::string& name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
The OpenExisting(…) functions will throw an exception if the mutex cannot be opened, while the TryOpenExisting(…) functions will return an empty Mutex.
static Mutex TryOpenExisting( LPCWSTR name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex TryOpenExisting( LPCSTR name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex TryOpenExisting( const std::wstring& name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
static Mutex TryOpenExisting( const std::string& name,
MutexRights desiredAccess = MutexRights::Synchronize |
MutexRights::Modify,
bool inheritHandle = false );
ReleaseMutex, Release and unlock
ReleaseMutex() releases ownership of the mutex, and the Release() and unlock() functions just calls the ReleaseMutex() function.
Semaphore
Semaphore objects can be used for resource counting. A semaphore has a maximum count and a current count. Use the maximum count to hold the maximum number of resources protected by the semaphore, and the current count for the number of currently available resources.
The state of a semaphore is set to signaled when its count is greater than zero, and non-signaled when its count is zero.
Each successful wait on a Semaphore will cause the count to be decremented by 1, and we must call Release(…) function to increase the semaphore's count by a specified amount. The count can never be less than zero or greater than the maximum value.
The class meets the BasicLockable requirements, allowing us to use templates such as std::unique_lock to wait on a Semaphore and call ReleaseSemaphore(1) when the lock goes out of scope.
Here is a “toy” resource manager demonstrating a typical use case for a Semaphore object:
namespace ResourceManager
{
struct Resource
{
long long counter_ = 0;
};
class Resources
{
constexpr static size_t ResourceCount = 5;
Semaphore semaphore_;
Mutex mutex_;
std::array<Resource, ResourceCount> resources_;
std::list< Resource* > freeList_;
public:
Resources( )
: semaphore_( ResourceCount, ResourceCount ), mutex_( false )
{
for ( auto& r : resources_ )
{
freeList_.push_back( &r );
}
}
Resource* GetResource( )
{
if ( semaphore_.Wait( ) )
{
std::unique_lock lock( mutex_ );
auto* result = freeList_.back( );
freeList_.pop_back( );
return result;
}
return nullptr;
}
void Release( Resource* r )
{
std::unique_lock lock( mutex_ );
freeList_.push_back( r );
semaphore_.Release( );
}
size_t Sum( ) const
{
size_t result = 0;
for ( auto& r : resources_ )
{
result += r.counter_;
}
return result;
}
};
}
The Resources class manages access to five Resource objects.
The Semaphore is used to provide notification to the waiting threads that a resource is available for allocation, while the Mutex is used to protect the list of free resources.
To try it out, we let one hundred threads share a Resources object and get access to Resource objects as they become available:
using namespace ResourceManager;
Resources resources;
ThreadGroup threadGroup;
for ( int i = 0; i < 100; ++i )
{
threadGroup.Add( [i, &resources]( )
{
auto id = i + 1;
for ( int i = 0; i < 10; ++i )
{
printf( "T%d: waiting\n", id );
auto* r = resources.GetResource( );
printf( "T%d: acquired resource\n", id );
r->counter_++;
printf( "T%d: value %zu\n", id, r->counter_ );
resources.Release( r );
}
} );
}
puts( "Main thread waiting on background threads" );
threadGroup.join( );
auto sum = resources.Sum( );
printf( "Final value %zu\n", sum );
Output:
T1: waiting
T2: waiting
T1: acquired resource
T1: value 1
T3: waiting
T3: acquired resource
T3: value 2
T5: waiting
T5: acquired resource
T5: value 3
T9: waiting
T18: waiting
...
...
T100: acquired resource
T100: value 190
T92: acquired resource
T92: value 200
T98: acquired resource
T98: value 207
T74: acquired resource
T74: value 178
T81: acquired resource
T81: value 225
Final value 1000
Constructors
Semaphore objects can be constructed in several ways, and the default constructor creates an empty object that can be move assigned another Semaphore.
constexpr Semaphore( ) noexcept;
explicit Semaphore( long initialCount, long maximumCount,
SemaphoreRights desiredAccess = SemaphoreRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Semaphore( LPCWSTR name, long initialCount, long maximumCount,
SemaphoreRights desiredAccess = SemaphoreRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Semaphore( LPCSTR name, long initialCount, long maximumCount,
SemaphoreRights desiredAccess = SemaphoreRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Semaphore( const std::wstring& name, long initialCount, long maximumCount,
SemaphoreRights desiredAccess = SemaphoreRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit Semaphore( const std::string& name, long initialCount, long maximumCount,
SemaphoreRights desiredAccess = SemaphoreRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
The initialCount argument specifies the initial count for the Semaphore object, and must not be less than zero or greater than the maximumCount argument. A semaphore is non-signaled when its count is zero and signaled when it is greater. The count is decremented by one for each thread that successfully waits on a semaphore. The count is increased by calling the ReleaseSemaphore(…) function with the amount to increase the count by as its argument.
The maximumCount argument specifies the maximum count for the Semaphore object, which must be one or greater.
The name argument specifies a name for the semaphore object and the length must not be greater than MAX_PATH. If the name matches an existing semaphore object, a handle to that semaphore is created and the initialCount and maximumCount arguments are ignored.
securityAttributes specifies the SECURITY_ATTRIBUTES for the semaphore. When the securityAttributes is nullptr, the semaphore gets a default security descriptor with ACLs from the primary or impersonation token of the creating thread.
desiredAccess specifies the access mask for the semaphore using values from the SemaphoreRights enumeration that can be combined using the ‘|’ operator.
None: No rightsDelete: The right to delete a named semaphoreReadPermissions: The right to open and copy the access rules and audit rules for a named semaphoreSynchronize: The right to wait on a named semaphoreChangePermissions: The right to change the security and audit rules associated with a named semaphoreTakeOwnership: The right to change the owner of a named semaphoreModify: The right to set or reset the signaled state of a named semaphoreFullControl: The right to exert full control over a named semaphore, and to modify its access rules and audit rules
OpenExisting and TryOpenExisting
To access an existing semaphore object, we use the OpenExisting(…) function, which has the following overloads:
static Semaphore OpenExisting( LPCWSTR name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore OpenExisting( LPCSTR name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore OpenExisting( const std::wstring& name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore OpenExisting( const std::string& name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
The OpenExisting(…) functions will throw an exception if the semaphore cannot be opened, while the TryOpenExisting(…) functions will return an empty Semaphore.
static Semaphore TryOpenExisting( LPCWSTR name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore TryOpenExisting( LPCSTR name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore TryOpenExisting( const std::wstring& name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
static Semaphore TryOpenExisting( const std::string& name,
SemaphoreRights desiredAccess = SemaphoreRights::Synchronize |
SemaphoreRights::Modify,
bool inheritHandle = false );
ReleaseSemaphore, Release and unlock
ReleaseSemaphore increases the count of the semaphore by the specified amount:
long ReleaseSemaphore( long releaseCount = 1 ) const;
long Release( long releaseCount = 1 ) const;
void unlock( ) const;
Release just calls ReleaseSemaphore, as does unlock() with releaseCount set to one.
WaitableTimer
A waitable timer is a synchronization object whose state is set to signaled when the specified due time arrives. The Windows API provides two waitable timer types: manual-reset and synchronization; and both can be periodic.
A manual-reset waitable timer is signaled until the SetWaitableTimer function is called to set a new due time; while a synchronization timer is in its signaled state until a single thread is released after successfully waiting on the waitable timer.
The following fragment creates a thread that will wait for five seconds on the timer.
std::cout << "Start: " << DateTime::Now( ) << std::endl;
EventWaitHandle event( true );
WaitableTimer timer(true, TimeSpan::FromSeconds( 5 ) );
Thread thread( [&timer, &event]( )
{
std::cout << "Background thread waiting on timer" << std::endl;
timer.Wait( );
std::cout << "Background thread continued: " << DateTime::Now( ) << std::endl;
std::cout << "Background thread signalling event" << std::endl;
event.Signal( );
} );
std::cout << "Main thread waiting for event" << std::endl;
event.Wait( );
std::cout << "Main thread waiting for background thread to terminate" << std::endl;
thread.Wait( );
Output:
Start: 03.09.2020 22 : 02 : 59
Main thread waiting for event
Background thread waiting on timer
Background thread continued : 03.09.2020 22 : 03 : 04
Background thread signalling event
Main thread waiting for background thread to terminate
Constructors
WaitableTimer objects can be constructed in several ways, and the default constructor creates an empty object that can be move assigned another WaitableTimer.
constexpr WaitableTimer( ) noexcept;
explicit WaitableTimer( bool manualReset,
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( bool manualReset, const DateTime& dueTime,
const TimeSpan& interval = TimeSpan( ),
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( bool manualReset, const TimeSpan& dueTime,
const TimeSpan& interval = TimeSpan( ),
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( LPCWSTR name, bool manualReset = true,
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( LPCSTR name, bool manualReset = true,
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( const std::wstring& name, bool manualReset = true,
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
explicit WaitableTimer( const std::string& name, bool manualReset = true,
WaitableTimerRights desiredAccess = WaitableTimerRights::FullControl,
LPSECURITY_ATTRIBUTES securityAttributes = nullptr );
If the manualReset argument is true, the constructor creates a manual-reset waitable timer; if false, a synchronization waitable timer is created that is automatically reset after releasing a single waiting thread.
The dueTime argument specifies when the waitable timer will enter the signaled state. If dueTime is a DateTime, then the dueTime is absolute, and when dueTime is a TimeSpan, the dueTime is relative.
The name argument specifies a name for the waitable timer object and the length must not be greater than MAX_PATH. If the name matches an existing waitable timer object, a handle to that waitable timer is created and the manualReset argument is ignored.
securityAttributes specifies the SECURITY_ATTRIBUTES for the waitable timer. When the securityAttributes is nullptr, the waitable timer gets a default security descriptor with ACLs from the primary or impersonation token of the creating thread.
desiredAccess specifies the access mask for the waitable timer using values from the WaitableTimerRights enumeration that can be combined using the ‘|’ operator.
None: No rightsDelete: The right to delete a named waitable timerReadPermissions: The right to open and copy the access rules and audit rules for a named waitable timerSynchronize: The right to wait on a named waitable timerChangePermissions: The right to change the security and audit rules associated with a named waitable timerTakeOwnership: The right to change the owner of a named waitable timerModify: The right to set or reset the signaled state of a named waitable timerFullControl: The right to exert full control over a named waitable timer, and to modify its access rules and audit rules
OpenExisting and TryOpenExisting
To access an existing waitable timer object, we use the OpenExisting(…) function, which has the following overloads:
static WaitableTimer OpenExisting( LPCWSTR name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer OpenExisting( LPCSTR name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer OpenExisting( const std::wstring& name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer OpenExisting( const std::string& name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
The OpenExisting(…) functions will throw an exception if the waitable timer cannot be opened, while the TryOpenExisting(…) functions will return an empty WaitableTimer.
static WaitableTimer TryOpenExisting( LPCWSTR name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer TryOpenExisting( LPCSTR name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer TryOpenExisting( const std::wstring& name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
static WaitableTimer TryOpenExisting( const std::string& name,
WaitableTimerRights desiredAccess =
WaitableTimerRights::Synchronize |
WaitableTimerRights::Modify,
bool inheritHandle = false );
SetTimer
The SetTimer function activates the waitable timer, and when the due time arrives, the waitable timer is signaled.
void SetTimer( LARGE_INTEGER dueTime, DWORD interval,
PTIMERAPCROUTINE completionRoutine,
void* argToCompletionRoutine,
bool resumeSystemIfSuspended ) const;
void SetTimer( LARGE_INTEGER dueTime, DWORD interval,
bool resumeSystemIfSuspended = false ) const;
void SetTimer( const DateTime& dueTime, const TimeSpan& interval,
PTIMERAPCROUTINE completionRoutine,
void* argToCompletionRoutine,
bool resumeSystemIfSuspended ) const;
void SetTimer( const TimeSpan& dueTime, const TimeSpan& interval,
PTIMERAPCROUTINE completionRoutine,
void* argToCompletionRoutine,
bool resumeSystemIfSuspended ) const;
void SetTimer( const DateTime& dueTime, const TimeSpan& interval = TimeSpan( ),
bool resumeSystemIfSuspended = false ) const;
void SetTimer( const TimeSpan& dueTime, const TimeSpan& interval = TimeSpan( ),
bool resumeSystemIfSuspended = false ) const;
The dueTime specifies the time for when the timer will be set to signaled. Use a positive value to set the absolute time in UTC as FILETIME, or a negative value to set the relative time with a 100-nanosecond resolution. When dueTime is given as a DateTime, the argument specifies an absolute dueTime, and when given as a TimeSpan, the dueTime will be relative.
The interval argument gives the period of the timer, in milliseconds. When interval is zero, the waitable timer will be signaled once, and when interval is greater than zero, the waitable timer will be periodic and automatically reactivated each time the period elapses, until the timer is cancelled using the Cancel() function or reset using the SetTimer(…) function. When interval is given as a TimeSpan, the argument will be converted to milliseconds.
The completionRoutine argument specifies a pointer to an optional completion routine.
The argToCompletionRoutine argument specifies an argument to be passed to the optional completion routine.
If the resumeSystemIfSuspended argument is true, the system will be restored from suspended power conservation mode when the waitable timer becomes signaled.
Thread
A thread is also a synchronization object that we can wait on. Thread objects enter their signaled state when they are done executing.
The Thread class can be used like the std::thread class, and provides additional Windows specific functions.
NOTE: We should not use the Win x86/x64 ExitThread(…) or the c runtime _endthread(…) and _endthreadex(…) functions to terminate a thread, both this implementation and the implementation of std::thread that is currently provided with Visual C++ use a std::unique_ptr<> to hold a pointer to a tuple<…> containing the thread arguments, so the stack needs to be properly unwound to allow the std::unique_ptr<> destructor to delete this tuple.
The Thread class does provide an alternative that is implemented by throwing an exception that is not derived from std::exception. This is not a bullet proof mechanism as any catch all, “catch(…)”, will catch this exception.
The best way to exit a thread is to return from the thread function.
Thread thread( []( ) { return 5; } );
thread.join( );
auto exitCode = thread.ExitCode( );
printf( "Thread exited with exit code %d\n", exitCode );
Output:
Thread exited with exit code 5
The implementation of std::thread provided with Visual C++ closes the handle to the thread in its implementation of join( ), making it impossible to perform further operations on the object. The Thread class will keep the handle until we call Close(), or the object goes out of scope.
Constructors
Thread objects can be constructed in several ways, and the default constructor creates an empty object that can be move assigned another Thread.
constexpr Thread( ) noexcept;
constexpr Thread( HANDLE handle, UInt32 threadId ) noexcept;
template <class Function, class... Args>
requires ( std::is_same_v<std::remove_cvref_t<Function>, Thread> == false )
explicit Thread( Function&& function, Args&&... args );
template <class Function, class... Args>
requires ( std::is_same_v<std::remove_cvref_t<Function>, Thread> == false )
explicit Thread( LPSECURITY_ATTRIBUTES securityAttributes,
Function&& function, Args&&... args );
The second constructor initializes a Thread object using the handle and threadId arguments, which are assumed to be valid.
The two last constructors create a new thread, executing std::invoke using a decayed copy of function and its decayed arguments that have been passed to the new thread.
securityAttributes specifies the SECURITY_ATTRIBUTES for the thread. When the securityAttributes is nullptr, the thread gets a default security descriptor with ACLs from the primary or impersonation token of the creating thread.
User Mode Synchronization
The Windows API provides a set of synchronization mechanisms that are far more efficient than the kernel-based mechanism we have covered this far.
The user-mode synchronization mechanisms can avoid an expensive round-trip to kernel mode when objects are not locked, or the lock is released within a few thousand CPU cycles, which is most of the time. A thread starting a real wait operation and giving up the rest of its time-slice, must still enter kernel mode since it is only here that the system can schedule a thread for execution.
CriticalSection
The CriticalSection class wraps a CRITICAL_SECTION struct, adding no addition data members. The class is not copy constructible, or copy assignable, or move constructible or move assignable.
When a thread tries to acquire a lock on a critical section that is locked, the thread spins, trying to acquire the lock on the critical section without giving up the current time-slice for the thread. If the lock cannot be acquired before the loop is done, the thread goes to sleep to wait for the critical section to be released.
CriticalSection implements a synchronization mechanism that is similar to a mutex object, but it can only be used to synchronize the threads of a single process.
size_t counter = 0;
CriticalSection criticalSection;
criticalSection.Enter( );
ThreadGroup threadGroup;
for ( int i = 0; i < 100; ++i )
{
threadGroup.Add( [i, &criticalSection, &counter]( )
{
auto id = i + 1;
for ( int i = 0; i < 10; ++i )
{
printf( "T%d: waiting\n", id );
std::unique_lock lock( criticalSection );
printf( "T%d: acquired mutex\n", id );
++counter;
printf( "T%d: value %zu\n", id, counter );
}
} );
}
criticalSection.Leave( );
puts( "Main thread waiting on background threads" );
threadGroup.join( );
printf( "Final value %zu\n", counter );
Constructors
CriticalSection has a single constructor:
explicit CriticalSection( UInt32 spinCount = DefaultSpinCount, bool noDebugInfo = true );
The spinCount argument specifies the spin count for the critical section.
The noDebugInfo argument specifies that the OS should not create debug information for the critical section.
The constructor uses InitializeCriticalSectionEx to initialize the CRITICAL_SECTION structure, and if the noDebugInfo argument is true, then the constructor will pass CRITICAL_SECTION_NO_DEBUG_INFO to the InitializeCriticalSectionEx function.
As of Vista, Windows Server 2008, Microsoft changed the way InitializeCriticalSection works.
As far as I understand it, InitializeCriticalSection, InitializeCriticalSectionAndSpinCount and InitializeCriticalSectionEx without the CRITICAL_SECTION_NO_DEBUG_INFO; now allocates some memory used for debug information, in the process address space, that is not released by DeleteCriticalSection. This will cause the process to leak a tiny amount of memory for each critical section that is deleted.
TryEnter and try_lock
The TryEnter function tries to acquire a lock on the critical section without blocking. If successful, the calling thread takes ownership of the critical section and must call Leave() or unlock() to release the lock. The try_lock() function just calls TryEnter().
Enter and lock
The Enter() function returns when the thread has acquired ownership of the lock on the critical section. The lock() function just calls Enter().
Leave and unlock
The Leave() function releases ownership of the lock on the critical section. Leave() must be called for each successful call to TryEnter() or Enter().
SlimReaderWriterLock
SlimReaderWriterLock class wraps a SRWLOCK struct, adding no additional data members. The class is not copy constructible, or copy assignable, or move constructible or move assignable. The default constructor initializes the SRWLOCK.
SlimReaderWriterLock is used to allow concurrent read access by multiple threads, while ensuring that when a thread writes to the protected resource it will have exclusive access, blocking other writers and readers.
Constructors
SlimReaderWriterLock has a single constructor:
SlimReaderWriterLock( ) noexcept
The constructor calls InitializeSRWLock(…) to initialize the SRWLOCK structure for the object.
AcquireExclusive and lock
Acquires the slim reader/writer lock in exclusive mode.
AcquireShared and lock_shared
Acquires the slim reader/writer lock in shared mode.
TryAcquireExclusive and try_lock
Tries to acquire the slim reader/writer lock in exclusive mode.
TryAcquireShared and try_lock_shared
Tries to acquire the slim reader/writer lock in shared mode.
ReleaseExclusive and unlock
Releases a lock that was acquired in exclusive mode.
ReleaseShared and unlock_shared
Releases a lock that was acquired in shared mode.
ConditionVariable
ConditionVariable class wraps a CONDITION_VARIABLE struct, adding no additional data members. The class is not copy constructible, or copy assignable, or move constructible or move assignable. The default constructor initializes the CONDITION_VARIABLE.
Condition variables are designed to let us wait on a change notification on a resource protected by a CriticalSection or SlimReaderWriterLock.
To demonstrate, here is a simple multi-producer, multi consumer, queue:
class SimpleQueue
{
ConditionVariable queueEmpty_;
ConditionVariable queueFull_;
CriticalSection criticalSection_;
size_t lastItemProduced_ = 0;
size_t queueSize_ = 0;
size_t startOffset_ = 0;
bool closed_ = false;
public:
static constexpr size_t MaxQueueSize = 50;
using Container = std::array<size_t, MaxQueueSize>;
private:
Container conatainer_;
public:
SimpleQueue( )
{
}
void Close( )
{
{
std::unique_lock lock( criticalSection_ );
closed_ = true;
}
queueEmpty_.WakeAll( );
queueFull_.WakeAll( );
}
bool Push( size_t item )
{
{
std::unique_lock lock( criticalSection_ );
while ( queueSize_ == MaxQueueSize && closed_ == false )
{
queueFull_.Sleep( criticalSection_ );
}
if ( closed_ )
{
return false;
}
auto containerOffset = ( startOffset_ + queueSize_ ) % MaxQueueSize;
conatainer_[containerOffset] = item;
queueSize_++;
}
queueEmpty_.Wake( );
return true;
}
private:
size_t PopValue( )
{
auto result = conatainer_[startOffset_];
queueSize_--;
startOffset_++;
if ( startOffset_ == MaxQueueSize )
{
startOffset_ = 0;
}
return result;
}
public:
bool Pop( size_t& item )
{
bool result = false;
{
std::unique_lock lock( criticalSection_ );
if ( closed_ == false )
{
while ( queueSize_ == 0 && closed_ == false )
{
queueEmpty_.Sleep( criticalSection_ );
}
}
if( queueSize_ )
{
item = PopValue( );
result = true;
}
}
if ( result && closed_ == false )
{
queueFull_.Wake( );
}
return result;
}
};
Items can be pushed on the queue if it is not closed, and items can be popped as long as the queue is not closed or there are items in the queue.
The Push(…) function takes an exclusive lock on the queue, and if the queue is full, it waits on the ConditionVariable queueFull_ by calling Sleep(criticalSection_). Sleep(…) releases the specified critical section and initializes the wait as an atomic operation. The critical section is re-acquired before the call to Sleep(…) completes. This allows other threads to acquire the critical section and remove elements from the queue. Before returning the Push(…) function calls queueEmpty_.Wake( ) to release a single thread waiting for items to appear in the queue. The logic behind the Pop(…) is the same, except that this function will wait if the queue is empty, and notify waiting producers that there is room for more items after an item is removed from the queue.
This queue is quite simple to use:
SimpleQueue queue;
std::atomic<size_t> generated;
std::atomic<size_t> consumed;
ThreadGroup producerThreadGroup;
ThreadGroup consumerThreadGroup;
for ( int i = 0; i < 4; ++i )
{
producerThreadGroup.Add( [i , &queue,&generated]( )
{
while ( queue.Push( 1 ) )
{
++generated;
}
printf( "Producer %d done.\n", i + 1 );
} );
}
for ( int i = 0; i < 4; ++i )
{
consumerThreadGroup.Add( [i, &queue, &consumed]( )
{
size_t value = 0;
while ( queue.Pop( value ) )
{
++consumed;
}
printf( "Consumer %d done.\n", i + 1 );
} );
}
puts( "Main thread going to sleep" );
CurrentThread::Sleep( TimeSpan::FromSeconds( 2 ) );
puts( "Main thread closing the queue" );
queue.Close( );
puts( "Main thread waiting on producer threads" );
producerThreadGroup.join( );
puts( "Main thread waiting on consumer threads" );
consumerThreadGroup.join( );
size_t sent = generated;
size_t received = consumed;
printf( "Result: produced %zu values and consumed %zu values\n", sent, received );
Constructors
ConditionVariable has a single constructor:
ConditionVariable( ) noexcept;
The constructor calls InitializeConditionVariable(…) to initialize the CONDITION_VARIABLE structure for the object.
Wake
The Wake() function wakes a single thread waiting on the condition variable.
WakeAll
The WakeAll() function wakes all threads waiting on the condition variable.
Sleep
The Sleep function has the following overloads:
bool Sleep( const CriticalSection& criticalSection,
DWORD timeoutInMillis = INFINITE ) const;
bool Sleep( const CriticalSection& criticalSection,
const TimeSpan& timeout ) const;
bool Sleep( const SlimReaderWriterLock& slimReaderWriterLock,
DWORD timeoutInMillis = INFINITE, bool sharedMode = false ) const;
bool Sleep( const SlimReaderWriterLock& slimReaderWriterLock,
const TimeSpan& timeout, bool sharedMode = false ) const;
The first and second overload sleeps on the specified condition variable and releases the specified critical section as an atomic operation.
The third and fourth overload sleeps on the specified condition variable and releases the specified SlimReaderWriterLock as an atomic operation. If sharedMode is true, the lock is held in share mode, otherwise the lock must be held in exclusive mode when calling the functions.
The timeout argument specifies the interval after which the functions returns, regardless of the outcome of the Sleep. The function returns false if a timeout occurred, true otherwise.
SynchronizationBarrier
A synchronization barrier allows multiple threads to wait until all threads have reached a stage of execution where they wait until the last thread arrives, and then they all continue their execution.
SynchronizationBarrier class wraps a SYNCHRONIZATION_BARRIER struct, adding no additional data members. The class is not copy constructible, or copy assignable, or move constructible or move assignable. The default constructor initializes the SYNCHRONIZATION_BARRIER.
Constructors
SynchronizationBarrier has a single constructor:
explicit SynchronizationBarrier( UInt32 totalThreads, Int32 spinCount = -1 );
The totalThreads argument specifies the number of threads that must enter the barrier, before all the threads are allowed to continue.
The spinCount argument specifies the number of times threads will spin while waiting for other threads to arrive at the barrier. If this parameter is -1, the thread spins 2000 times. When the thread exceeds spinCount, the thread blocks unless it called Enter(…) with SynchronizationBarrierFlags::SpinOnly.
Enter
The Enter(…) function causes the calling thread to wait until the required number of threads have entered the barrier.
TimerQueue
TimerQueue is a wrapper around the Windows timer queue. The implementation makes it easy to specify the callback using anything that is invokable, and an arbitrary number of arguments can be passed to the invokable implementation in the same way parameters can be passed to std::thread.
size_t counter = 0;
EventWaitHandle event( true );
TimerQueue timerQueue;
auto timer = timerQueue.CreateTimer( 100, 100, TimerQueueTimerFlags::Default,
[&counter,&event]( )
{
counter++;
if ( counter == 5 )
{
event.Signal( );
}
} );
event.Wait( );
timer.Close( );
timerQueue.Close( );
The End
I hope this was interesting, and that I was able to demonstrate how to easily use many of the synchronization mechanisms that are available when developing software using C++ on the Windows platform. So, until next time: happy coding. 😊
History
- 8th September, 2020
- 12th September, 2020
- Added
ExampleSocketServer01 and ExampleSocketClient01
- 6th October, 2020
- Bug fixes, cleaned up most of the unit tests
- 7th October, 2020
- More unit tests for the
Harlinn.Common.Core library
- 11th October, 2020
- More unit tests for the
Harlinn.Common.Core library
- 13th October, 2020
- More unit tests for the
Harlinn.Common.Core library, and two new examples for the Harlinn.Windows library.
- 17th October, 2020
- Fix for
TimerQueue and TimerQueueTimer, more unit tests for the Harlinn.Common.Core library
- 18th December, 2020
- Bug fixes for
IO::FileStream - Initial http server development support
- Synchronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx01
- Asynchronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx02
- Simplified asynchronous I/O, Timers, Work and events for Windows waitable kernel objects using Windows thread pool API: $(SolutionDir)Examples\Core\ThreadPools\HExTpEx01
- 1st January, 2021
- Improved support for asynchronous server development
- New design for working with sockets
- Concept based stream implementations
- 11th February, 2021
- Bug fixes
- Initial C++ ODBC support
- 25th February, 2021
- Updated LMDB
- Updated xxHash
- Added the initial implementation of very fast hash based indexes for large complex keys using LMDB
- Fast asynchronous logging - nearly done :-)
- 3rd of March, 2021:
- New authorization related classes
- SecurityId: Wrapper for SID and related operations
- ExplicitAccess: Wrapper for EXCPLICIT_ACCESS
- Trustee: Wrapper for TRUSTEE
- SecurityIdAndDomain: Holds the result from LookupAccountName
- LocalUniqueId: Wrapper for LUID
- AccessMask: Makes it easy to inspect the rights assigned to an ACCESS_MASK
- AccessMaskT<>
- EventWaitHandleAccessMask: Inspect and manipulate the rights of an EventWaitHandle.
- MutexAccessMask: Inspect and manipulate the rights of a Mutex.
- SemaphoreAccessMask: Inspect and manipulate the rights of a Semaphore.
- WaitableTimerAccessMask: Inspect and manipulate the rights of a WaitableTimer.
- FileAccessMask: Inspect and manipulate file related rights.
- DirectoryAccessMask: Inspect and manipulate directory related rights.
- PipeAccessMask: Inspect and manipulate pipe related rights.
- ThreadAccessMask: Inspect and manipulate thread related rights.
- ProcessAccessMask: Inspect and manipulate process related rights.
- GenericMapping: Wrapper for GENERIC_MAPPING
- AccessControlEntry: This is a set of tiny classes that wraps the ACE structures
- AccessControlEntryBase<,>
- AccessAllowedAccessControlEntry
- AccessDeniedAccessControlEntry
- SystemAuditAccessControlEntry
- SystemAlarmAccessControlEntry
- SystemResourceAttributeAccessControlEntry
- SystemScopedPolicyIdAccessControlEntry
- SystemMandatoryLabelAccessControlEntry
- SystemProcessTrustLabelAccessControlEntry
- SystemAccessFilterAccessControlEntry
- AccessDeniedCallbackAccessControlEntry
- SystemAuditCallbackAccessControlEntry
- SystemAlarmCallbackAccessControlEntry
- ObjectAccessControlEntryBase<,>
- AccessAllowedObjectAccessControlEntry
- AccessDeniedObjectAccessControlEntry
- SystemAuditObjectAccessControlEntry
- SystemAlarmObjectAccessControlEntry
- AccessAllowedCallbackObjectAccessControlEntry
- AccessDeniedCallbackObjectAccessControlEntry
- SystemAuditCallbackObjectAccessControlEntry
- SystemAlarmCallbackObjectAccessControlEntry
- AccessControlList: Wrapper for ACL
- PrivilegeSet: Wrapper for PRIVILEGE_SET
- SecurityDescriptor: Early stage implementation of wrapper for SECURITY_DESCRIPTOR
- SecurityAttributes: Very early stage implementation of wrapper for SECURITY_ATTRIBUTES
- Token: Early stage implementation of wrapper for an access token
- DomainObject
- User: Information about a local, workgroup or domain user
- Computer: Information about a local, workgroup or domain computer
- Group: local, workgroup or domain group
- Users: vector of User objects
- Groups: vector of Group objects
- 14th of March, 2021 - more work on security related stuff:
- Token: A wrapper for a Windows access token with a number of supporting classes like:
- TokenAccessMask: An access mask implmentation for the access rights of a Windows access token.
- TokenGroups: A wrapper/binary compatible replacement for the Windows TOKEN_GROUPS type with a C++ container style interface.
- TokenPrivileges: A wrapper/binary compatible replacement for the TOKEN_PRIVILEGES type with a C++ container style interface.
- TokenStatistics: A binary compatible replacement for the Windows TOKEN_STATISTICS type using types implemented by the library such as LocalUniqueId, TokenType and ImpersonationLevel.
- TokenGroupsAndPrivileges: A Wrapper/binary compatible replacement for the Windows TOKEN_GROUPS_AND_PRIVILEGES type.
- TokenAccessInformation: A wrapper/binary compatible replacement for the Windows TOKEN_ACCESS_INFORMATION type.
- TokenMandatoryLabel: A wrapper for the Windows TOKEN_MANDATORY_LABEL type.
- SecurityPackage: Provides access to information about a Windows security package.
- SecurityPackages: An std::unordered_map of information about the security packages installed on the system.
- CredentialsHandle: A wrapper for the Windows CredHandle type.
- SecurityContext: A wrapper for the Windows CtxtHandle type
- Crypto::Blob and Crypto::BlobT: C++ style _CRYPTOAPI_BLOB replacement
- CertificateContext: A wrapper for the Windows PCCERT_CONTEXT type, provides access to a X.509 certificate.
- CertificateChain: A wrapper for the Windows PCCERT_CHAIN_CONTEXT type which contains an array of simple certificate chains and a trust status structure that indicates summary validity data on all of the connected simple chains.
- ServerOcspResponseContext: Contains an encoded OCSP response.
- ServerOcspResponse: Represents a handle to an OCSP response associated with a server certificate chain.
- CertificateChainEngine: Represents a chain engine for an application.
- CertificateTrustList: A wrapper for the Windows PCCTL_CONTEXT type which contains both the encoded and decoded representations of a CTL. It also contains an opened HCRYPTMSG handle to the decoded, cryptographically signed message containing the CTL_INFO as its inner content.
- CertificateRevocationList: Contains both the encoded and decoded representations of a certificate revocation list (CRL)
- CertificateStore: A storage for certificates, certificate revocation lists (CRLs), and certificate trust lists (CTLs).
- 23rd of March, 2021:
- Updated to Visual Studio 16.9.2
- Build fixes
SecurityDescriptor: Implemented serialization for security descriptors, enabling persistence of authorization data.

