Here we provide a hands-on example of Azure Synapse SQL Pool.
In the first article of this series, we explored how Azure Synapse Analytics helps you analyze, understand, and report your data. We also took a quick look at its two components: SQL pool and Apache Spark. In this article, we will get started with Azure Synapse Analytics by setting up an SQL pool. To demonstrate, we will analyze New York City safety data to discover how many calls to 311 were emergency versus non-emergency.
Azure Synapse’s built-in, configured serverless SQL database pool enables you to query data from your data lake using Microsoft SQL Server Transact-SQL (T-SQL) syntax and related tools and functions. You can also create one or more dedicated SQL Pools according to your project, configuration, and authentication requirements. Note that SQL pools were formerly called SQL Data Warehouse (SQL DW).
Register an Azure Account
You need to sign up for an Azure account if you do not already have one. The free Azure account gives you access to all free services for 30 days — plus a $200 credit to explore Azure fully.
Create a Synapse Workspace
First, you need to create a Synapse workspace. In the Azure portal, search for "synapse" and select "Azure Synapse Analytics."

On the Azure Synapse Analytics screen, click Create Synapse Workspace or + New. You should now see the first page for creating a Synapse workspace. This Synapse workspace will be the focal point of your data and analysis.
Azure now displays the first of a few screens. Start entering information to create a new resource group, "ASA_Tutorial," and workspace name, "asa-workspace." Pick a region that makes sense for your Azure use. This will likely be a nearby location.
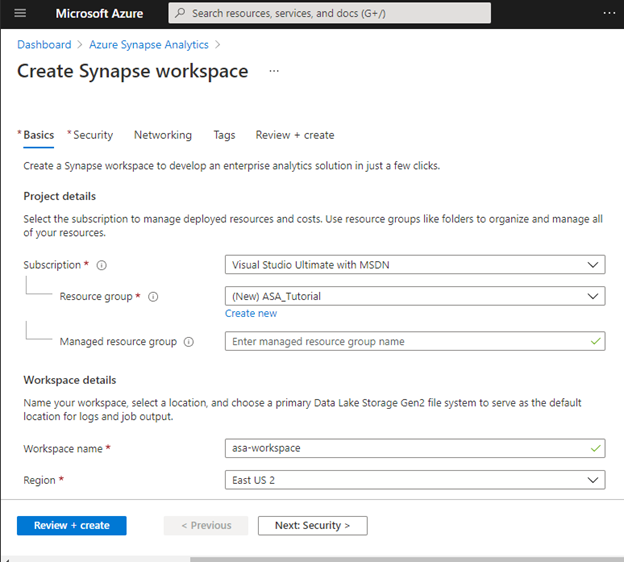
Note that creating a workspace does not incur any costs. You are not yet using storage, data, or other services. Later, when you upload data, there is a small storage fee. Services like SQL data pools and Apache Spark incur costs, and some of these cloud charges could be significant. Using the built-in Serverless SQL pool is much less expensive when doing data exploration and adhoc analysis.
From here, we could click on Review + create, but we will instead step through the next couple of screens to see all the configurations. So, click Next: Security.
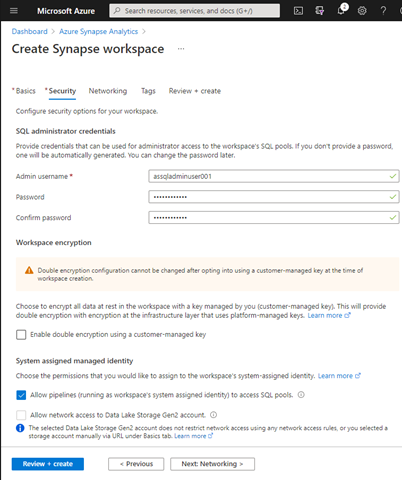
In this next step, you can provide an administrator user name and password for the workspace SQL pools. You may want to set these yourself, at least when you are doing this manually.
Every workspace includes a built-in SQL pool. You can also use an existing or dedicated SQL or Apache Spark pool.
Next, click Next: Networking.
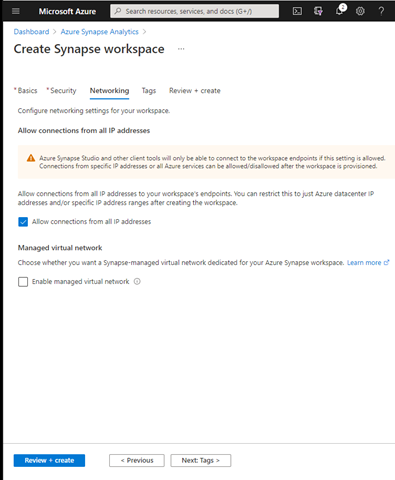
Accept the default networking details and click Next: Tags.
Tags are not critical, but you can use them to find sets of resources if you have many otherwise unrelated resources. After (optionally) setting up tags, click Review + create to continue.
Azure now displays a summary of your configured workspace for your review.
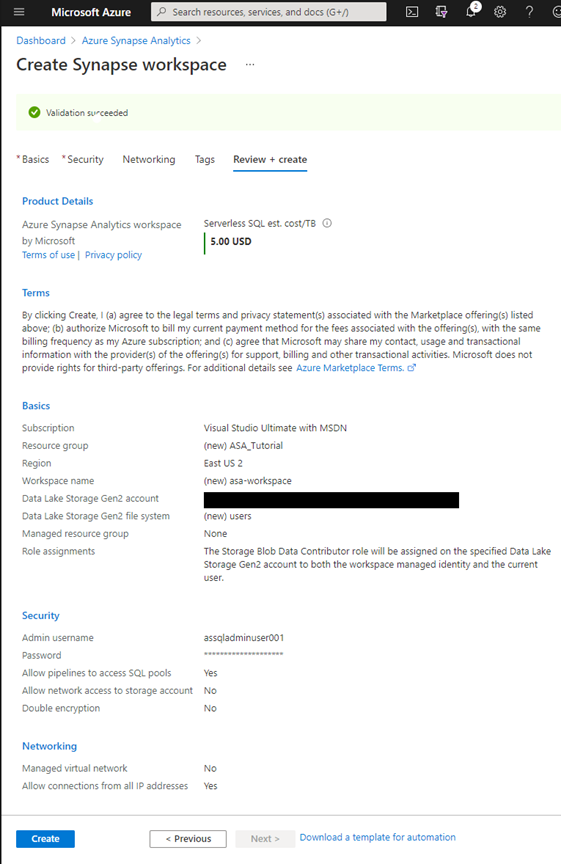
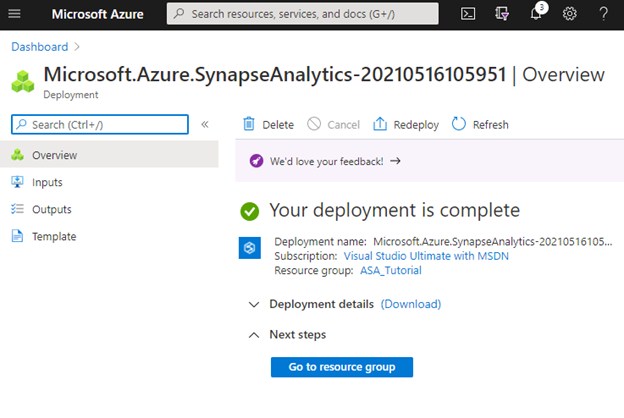
Now, click Create and get a cup of coffee. Deploying the workspace will take a few minutes. When this step completes, the status changes to "Your deployment is complete."
Synapse Studio and Knowledge Center
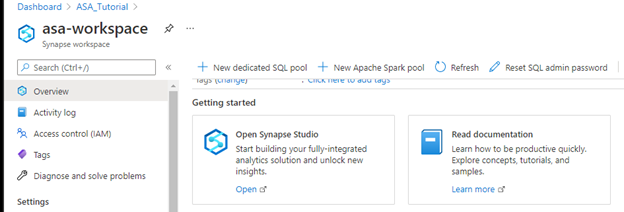
When your workspace is ready, go to its Overview page. Under "Getting started," click the Open Synapse Studio link. Alternatively, you can visit Azure Synapse.
Synapse Studio opens. Note the left navigation bar. The icons from top to bottom are: Home, Data, Develop, Integrate monitor, and Pipeline. The first time through, you may want to tour Synapse Studio. This will annotate your screen and steps you through Synapse Studio’s buttons and areas. You can always find the tour link by clicking "?" on the upper right navigation menu and selecting Guided Tour.
Before proceeding to the examples, you may want to explore the Synapse Knowledge center. Synapse Analytics documentation and resources are collected here.
Click the Home Hub icon (the house icon on the left navigation menu), then click Learn to go to the Knowledge Center. You can click on samples to create fully operational projects, including scripts, notebooks, and data.
You can also load data samples there. Click Browse gallery to find some data to use in the first example.
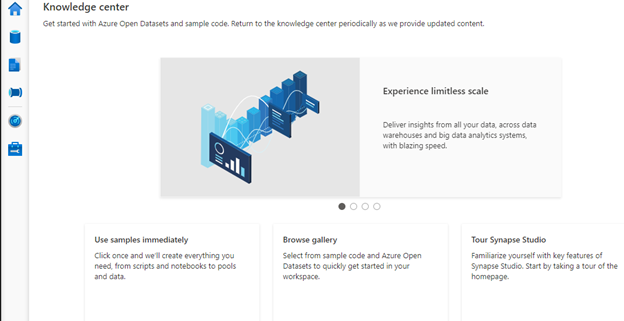
There is a wealth of information and samples here. You can explore Datasets, Notebooks, SQL scripts, or Pipelines. But for now, we are interested in Datasets.
Let’s explore New York City Safety Data. To find it, you can browse the datasets or type "New York Safety Data" into the search bar. Click the dataset and then click Continue. Azure displays a data description and preview. You can also click See full details for more detailed information.
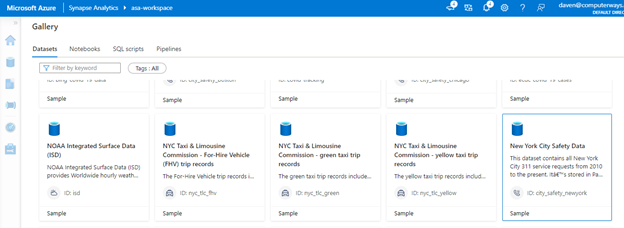
Click Add dataset. This downloads the sample data into your workspace and maneuvers the Studio to the Data tab.
You should see "city_safety_newyork" under Azure Blob Storage > Sample Dataset.
When you click on the ellipse, a flyout menu enables you to create an SQL script, a notebook (we will cover this later), and properties. Properties summarize the data. The file contains data for all New York City 311 citizen service requests from 2010 to the present.
This data is in a standard format called Parquet. The Azure Data Factory provides many Parquet connectors for various Azure, Amazon, Google, and Oracle storage systems.
Note that you can also upload a file. In our case, we have a link that is online and updated regularly.
To start our analysis, we use the flyout menu to create a query of the dataset’s top 100 rows.
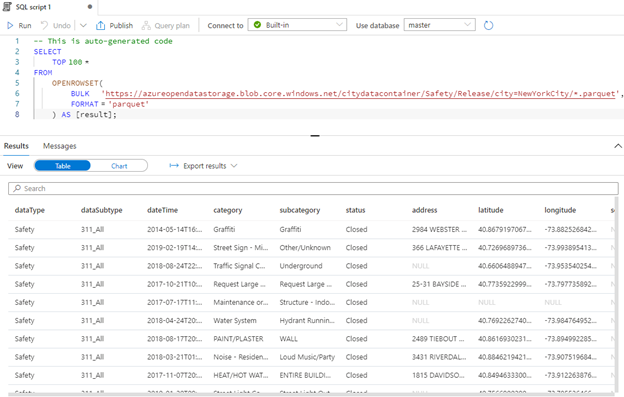
Azure generates a default SQL script, "SQL script 1," to show rows in the Parquet data. Click Run to see the results. We can also click on the "Develop" icon on the left navigation menu to see "SQL Script 1" is now listed.
Now we can explore a bit to discover more about the data. For example, how many rows does it have? To find out, change "TOP 100 *" to "Count(*)" and click Run again.
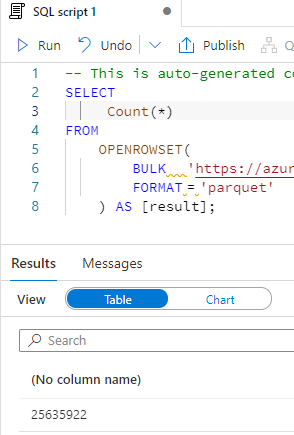
To discover the date range, replace Count(*) with min(dateTime) as MinDate, max(dateTime) as MaxDate and click run to see the results.
Exploring data directly from files is helpful, but you need to create a separate database for more complex situations. You cannot create objects in the master SQL pool database.
Let us create a database in the default SQL pool to store artifacts such as database credentials and users to control database access, views, procedures, and functions.
The database collection is significant because we are accessing Parquet and potentially other text-based files. To avoid conversion errors, set the collation to Latin1_General_100_BIN2_UTF8.
In the Develop tab, press the + button to create a new blank SQL script workspace. Run the following command: create database asaPoolDB collate Latin1_General_100_BIN2_UTF8

Click on the data icon, and from the ellipse on Databases, click Refresh.
You can also expand databases. See asaPoolDB and the tabs beneath it to find out what you can store there.
We can create an external data source, which is a shorthand way of referring to a container. It hides the underlying data container, and you can configure the data source with credentials.
In our safety data example, to create a data source. Make sure you are using the asaPoolDB and run this script:
CREATE EXTERNAL DATA SOURCE [CityData] WITH
(
LOCATION = 'https://azureopendatastorage.blob.core.windows.net/citydatacontainer'
)

Refresh the external data sources, and you should see the "CityData" source.
At this point, you might want to publish your SQL scripts, which saves them. To do this, create a new empty SQL script, such as "SQL script 4." Of course, you can rename these scripts if you wish.
Now our safety data query looks like this:
SELECT
Top 100 *
FROM
OPENROWSET(
BULK '/Safety/Release/city=NewYorkCity/*.parquet',
DATA_SOURCE = 'CityData',
FORMAT = 'parquet'
) AS [result];
Note that specifying the DATA_SOURCE parameter provides a shortcut to the full URL. You must specify the relative path.
Run the query. It should produce the same data as the original query.
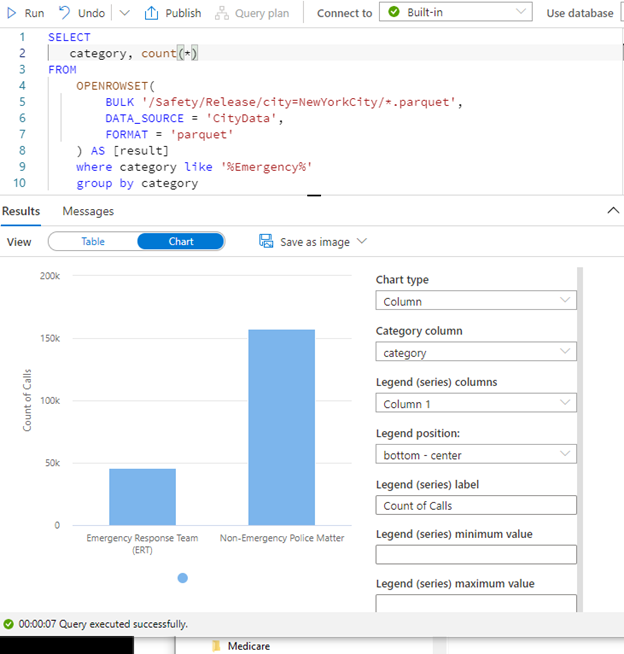
The default view is a table, but you can click on the Chart button to turn it into a graphic. By turning the results into a chart, we can see the number of emergencies versus non-emergency calls.
Use this script for a count and run to display the chart:
SELECT
category, count(*)
FROM
OPENROWSET(
BULK '/Safety/Release/city=NewYorkCity/*.parquet',
DATA_SOURCE = 'CityData',
FORMAT = 'parquet'
) AS [result]
where category like '%Emergency'
group by category;
Next Steps
This article provided a hands-on example of Azure Synapse SQL Pool. Completing this example should get you started on adapting Azure Synapse Analytics resources to your projects.
For more training, continue to the third article in this series to learn how to set up Apache Spark.
Check out the Hands-on Training Series for Azure Synapse Analytics for in-depth training sessions led by Azure Synapse engineers.

