This article teaches us how to create an Azure Synapse Analytics workspace, Azure Machine Learning workspace, and Azure Machine Learning linked service. We also import the data into a Spark table from our underlying storage.
In the first article of this series, we learned about how Azure Synapse Analytics and Azure Machine Learning help analyze data without extensive coding and ML experience. We also created a roadmap to follow along the rest of the series:
- Creating an Azure Synapse Analytics workspace
- Creating an Azure Machine Learning workspace
- Creating and configuring an Azure Machine Learning linked service
- Importing the data
- Training a prediction model using AutoML
- Enriching data using a pre-trained Azure ML model
- Enriching data using Azure Cognitive Services
Let’s start creating our workspaces and linked services to prepare for our data analysis later in this article series.
Creating and Configuring a Synapse Workspace
We’ll use the Azure portal to create an Azure Synapse workspace. We’ll need to have an active Azure account, so sign up if you don’t already have one. You can enjoy 12 months of free popular services and a $200 credit to explore Azure fully for 30 days once you’re registered.
From the Azure portal, we click Create a resource and search for "Azure Synapse Analytics."
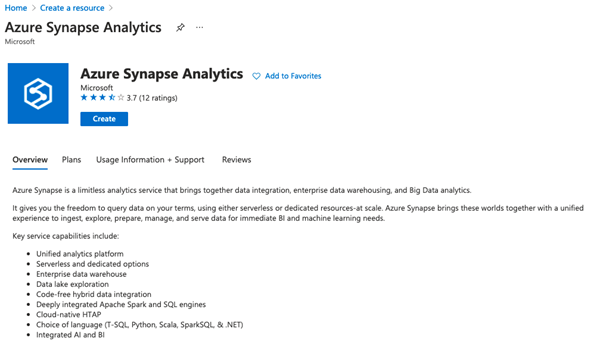
On the Azure Synapse Analytics page, we click Create, then start entering our Basics project details. Next, we select the subscription we want to use to create a workspace. We can create a new resource group (like in the image above) or manage a previously-created resource group. Here, we make a new one.
We enter a name for our workspace, select Data Lake Gen2 from Subscription, choose or create a new storage account and file system, then click Next: Security.
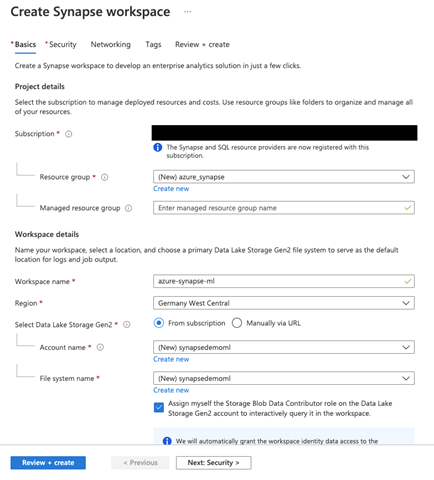
On the next page, Security, we enter SQL administrator credentials.
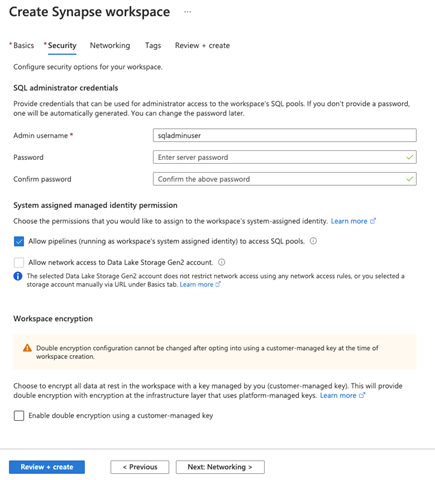
Next, we review our Networking settings.
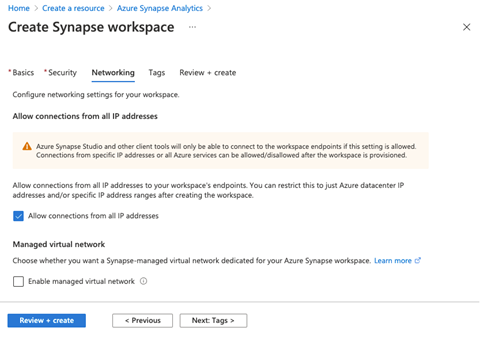
We make sure to check Allow connections from all IP addresses. This is required to connect Azure Synapse Studio or any other client tools to the workspace endpoint. We can restrict and allow or disallow specific IP addresses later once we provision the workspace successfully.
Next, we can optionally create Tags, although we’ll skip that step here. We then click Review + create to make the workspace.
The workspace deployment may take a few minutes. We can monitor the deployment status in the progress bar at the top — or just get ourselves a nice cup of coffee.
When the deployment is complete, we open the resource group and click on the workspace we just created. Here, we can see the workspace web URL, primary ADLS Gen2 storage account URL and file system, dedicated and serverless SQL endpoints, and a development endpoint.
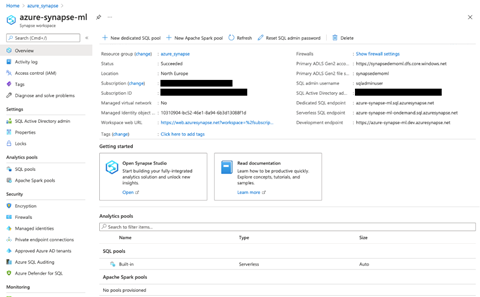
With our Azure Synapse Analytics workspace in place, let’s move on to creating an Azure Machine Learning workspace.
Creating and Configuring an Azure Machine Learning Workspace
We can use the Azure portal to create an Azure Machine Learning workspace the same way we made a Synapse workspace.
From the Azure portal, we click Create a resource and search for "Machine Learning." When we are on the Azure Machine Learning page, we click Create to start creating a workspace.
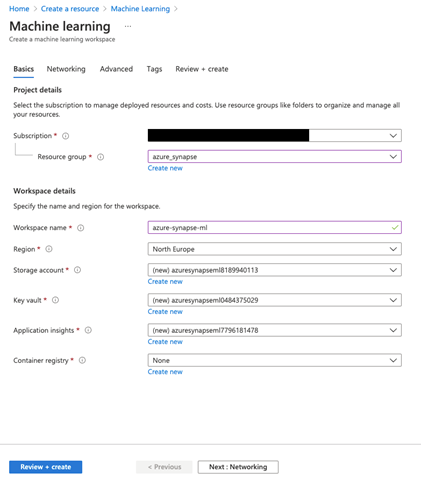
We’ll enter basic project details like Subscription, Resource group, Workspace name, and more on this page. Instead of creating a new Resource group, we choose the one we made earlier. Next, we name our workspace, and the rest of the fields populate automatically.
Then, we click Next: Networking. Here, we’ll follow the default settings and choose Public endpoint as the Connectivity method.
We then click Next: Advance and again keep the default settings.
We’ll keep the rest of the default settings as well and go on creating the workspace. When the deployment is complete, we’ll be able to see the Azure Machine Learning workspace under our deployed resources.
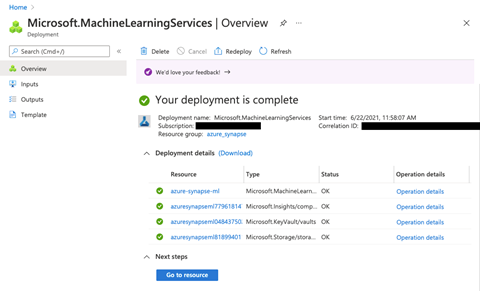
With both of our workspaces in place, let’s go ahead and create a linked service.
Creating and Configuring an Azure Machine Learning Linked Service
To leverage Azure Machine Learning in Azure Synapse Analytics, we need to link our two workspaces. There are two types of authentication: Synapse workspace managed identity and service principal. Here, we’ll use a service principal to create the linked service.
Creating a Service Principal
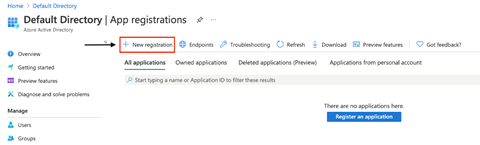
Before creating the linked service, we need to create a new service principal from within the Azure portal. So, we first open our Azure portal and navigate to Azure Active Directory. Here, we go to the App registrations tab under Manage.
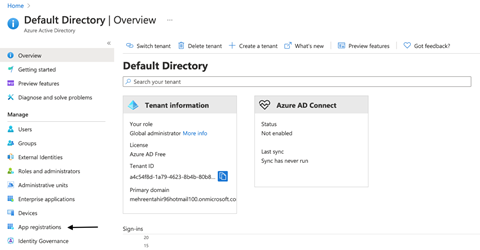
We don’t have any registered applications at the moment, so we’ll register one by clicking New registration.
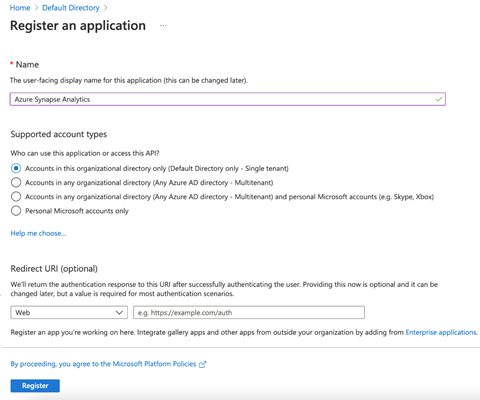
We enter a name for our application and choose Supported account types. Here, we leave the default account type. We leave the Redirect URI blank and click Register to register our application.
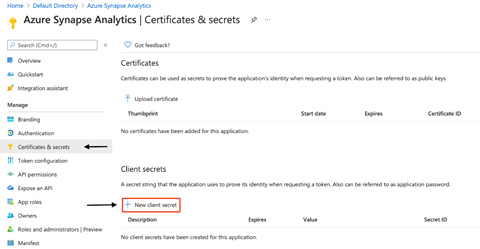
When the application successfully registers, we need to generate a secret for the application. So, we navigate to Certificate & Secret from our application and click New client secret under Client secrets.
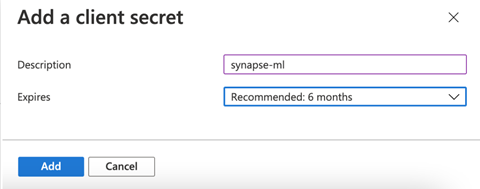
We now enter the description for the new secret and select a validity period that best suits us (here, our secret expires after six months), and click Add.
When Azure Active Directory generates the secret, we keep that value safe since we’ll need it when creating a linked service.
Our next step is to create a service principal for the application. For that purpose, we navigate to our application’s Overview tab. In our case, Azure Synapse Analytics has automatically created our service principal, visible in the following image.
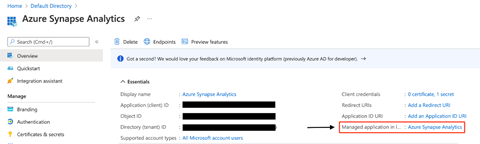
The last thing we need to do before we create a linked service is to ensure the service principal has the necessary permissions to work with our Azure Machine Learning workspace. So first, we navigate to our previously-created Azure Machine Learning workspace and select the Access Control (IAM) section to configure that. Next, we click + Add and choose Add role assignment to add a new role.
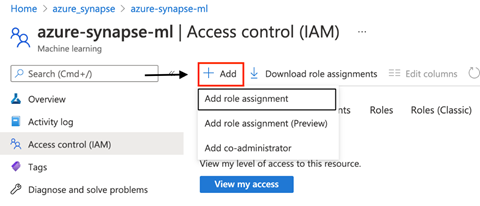
Next, we choose the Role of Contributor from the dropdown menu on the Add role assignment page. We also Select the service principal that we just created, which in our case is Azure Synapse Analytics.
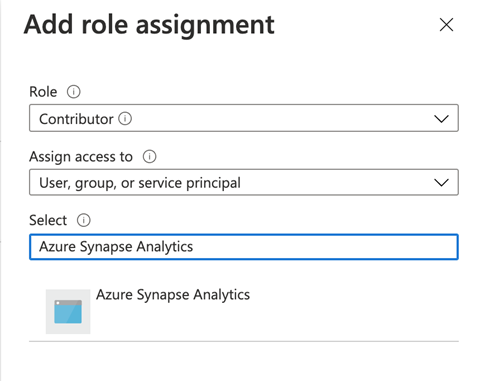
We now click Save to add the role assignment. When the role is successfully added, we’re ready to create our Azure Machine Learning linked service.
Creating an Azure ML Linked Service
From here on, we’ll go to Azure Synapse studio to create a linked service. We find the option to launch the Azure Synapse studio under Getting started in our Azure Synapse workspace. We click Open.
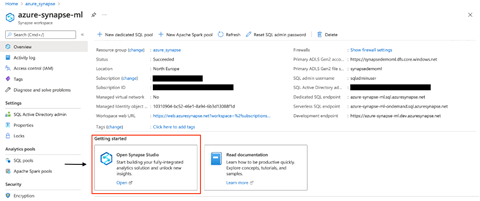
When prompted, we click Authenticate to continue. Make sure your browser allows pop-ups.
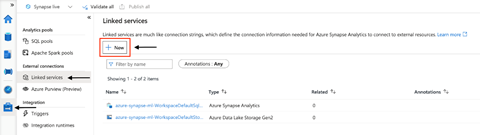
Once we’re in the studio, we go to the Manage section and select Linked services. We find Azure Synapse Analytics and Azure Data Lake Storage Gen2 linked services already listed there. We’ll create a new linked service for Azure ML by clicking + New.
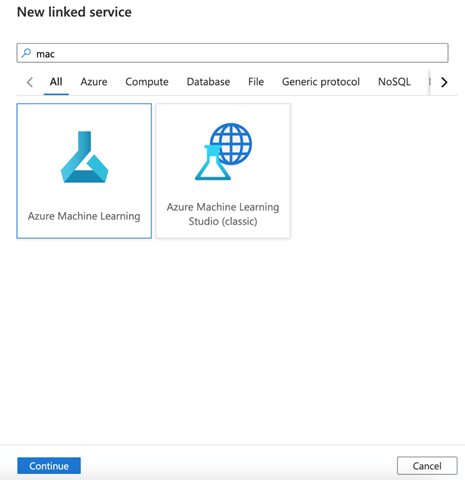
On the next page, we search for "Machine Learning services." We select Azure Machine Learning and Continue.
Next, we need to provide the details of our Azure ML workspace in the new linked service (Azure Machine Learning) dialogue. We enter these details:
- Name: We enter a name for our linked service.
- Integration runtime: We choose an option for integration runtime. Here, we use default settings.
- Authentication method: As we mentioned earlier, Azure Synapse Analytics provides two authentication methods: Synapse workspace managed identity and service principal. We select service principal here.
- Azure subscription: This field populates automatically, but we ensure the subscription containing our Azure Synapse Analytics resource group is selected.
- Azure Machine Learning workspace name: We choose the Azure ML workspace that we created previously.
- Tenant: This field is pre-filled. You can also find this tenant ID on your application’s overview page. See the image below.
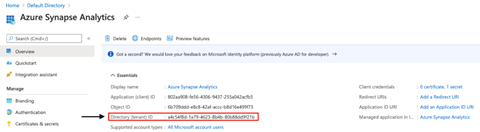
- Service principal ID: This is the application (client) ID. You can find this ID above the tenant ID on your application’s overview page. See the image below.
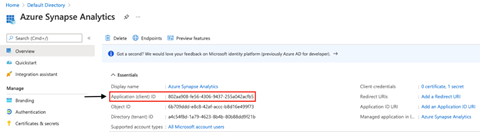
- Service principal key: This is the secret value we generated in the previous section.
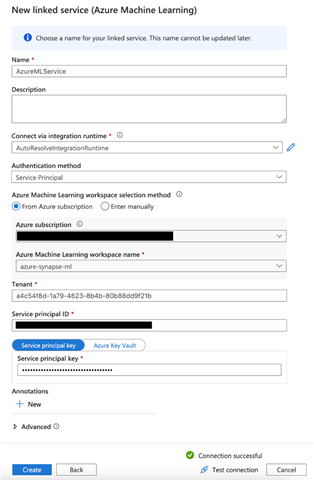
When we’ve filled all the required fields, we click Test Connection to verify the configurations. If the test passes, we click Create. Here’s how the new linked service dialogue looks like right before we create the service:
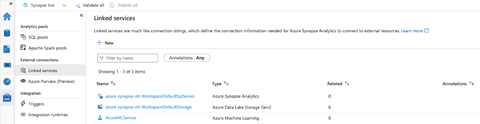
After we’ve successfully created the service, we can see it under Linked services.
Importing the Data
Before we import data to our Synapse workspace, we need to create Spark and SQL pools to store that data. Creating these pools is pretty straightforward, and we can do this from within Azure Synapse Studio.
Creating a Dedicated SQL Pool in Azure Synapse Studio
From within Azure Synapse studio, we click Manage and select SQL Pools. Here, we see a serverless SQL pool already exists. We are interested in a dedicated SQL pool, though, so we click New.
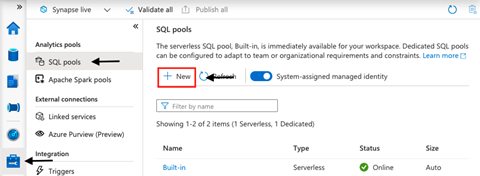
Next, we name our dedicated SQL pool (SynapseML) and choose its initial settings. By default, the Performance level is DW1000c, which means 1,000 data warehouse compute units at around $15.10 per hour. Here, we must make a tradeoff between the capacity based on cost budget versus performance requirements. For the sake of this article, let’s select DW100c.
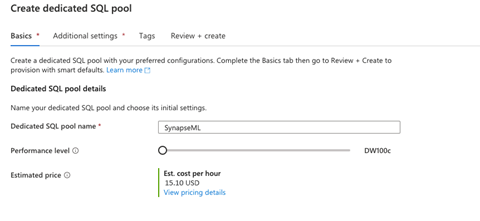
In the next step, Additional settings, we can use existing data or create an empty pool. We’ll create an empty pool by choosing None as the data source, then move on to Review + create to make the pool.
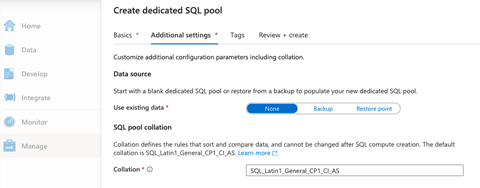
When our dedicated SQL pool is created, we’ll move ahead to make a Spark pool.
Creating a Spark Pool
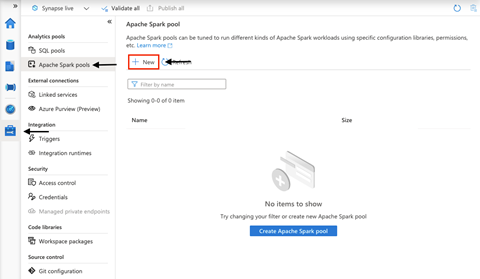
Creating a Spark pool is almost the same as creating an SQL Pool. From Azure Synapse Studio, we navigate to the Manage tab and select Apache Spark pools. There is no pool available at the moment, so we create one by clicking New.
Next, we name our Spark pool (SynapseML) and choose basic settings. We select the node size (small, medium, large, extra-large, or extra-extra-large), enable or disable autoscaling, and select the number of nodes. We must make a tradeoff between budget and performance.
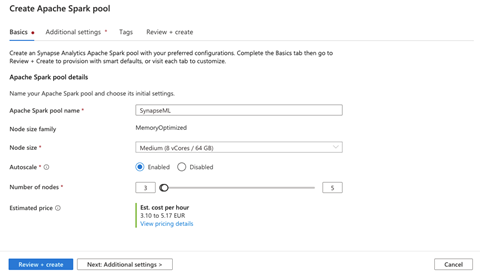
Now, we click Next: Additional settings.
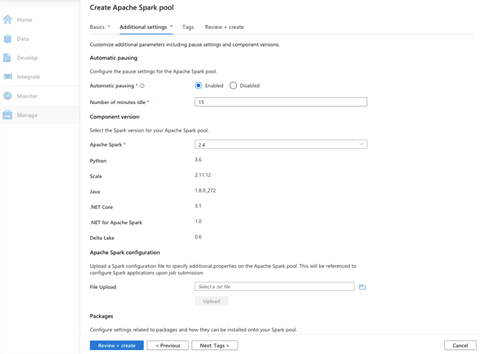
On this page, we can further customize our Spark pool. For example, we can enable or disable automatic pausing and specify how long Spark should wait before shutting down the cluster when there is no active job.
We can also choose the Apache Spark version we want to use. At the time of writing, Apache Spark 3.0 is still in preview.
We can configure Apache Spark using a configuration file and specify any other additional pool properties, too.
For the sake of simplicity, we'll use default settings for the rest of the fields. After reviewing the settings, we click Create.
After our Spark pool deploys successfully, we should see it under Apache Spark pools.
Our spark pool is in place now, but our underlying storage is still empty. So next, let’s upload some data to Azure Data Lake Storage, then import it into a Spark pool.
Uploading Data to Azure Data Lake Storage
Azure Synapse provides an easy interface to upload data files to Azure Data Lake Storage.
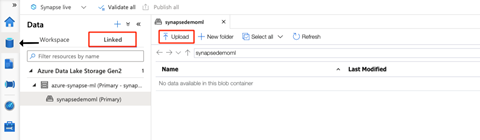
In Synapse studio, we select the Data hub then the Linked section. Here, we find the primary Azure Data Lake Storage Gen2 account. We observe that our storage is empty. To upload the data, we click Upload.
In the Upload Files dialogue, we select the data files we want to upload. For the sake of this demonstration, we’ll be using the open-source House Sales in King County, USA dataset we download from Kaggle.
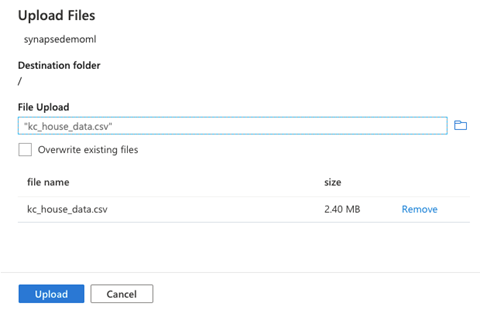
After choosing the file to upload, we click Upload to upload our data to Azure Data Lake Storage.
Importing Data from an Azure Data Lake to a Spark Table
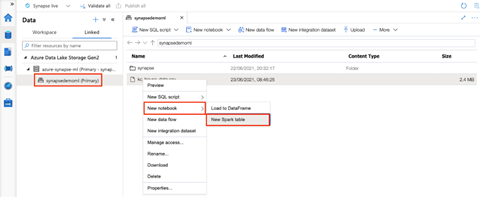
Azure Synapse Analytics makes it easy for users to import data from Azure Data Lake Storage to a Spark table with just a few clicks. First, we right-click on our data file and choose New Spark table from under New notebook.
We then replace the notebook cell’s code with the following code and run it:
%%pyspark
df = spark.read.load('abfss://synapsedemoml@synapsedemoml.dfs.core.windows.net/kc_house_data.csv', format='csv'
, header=True
)
df.write.mode("overwrite").saveAsTable("default.kchouse")
We’ll load the whole dataset into our Spark table named "kchouse." We can view the contents of the table using the following code:
display(df.limit(10))
What’s Next?
This article taught us how to create an Azure Synapse Analytics workspace, Azure Machine Learning workspace, and Azure Machine Learning linked service. We then imported the data into a Spark table from our underlying storage.
With all the configurations and data in place, we’ll explore how to enrich our real estate data using trained models and work around predictive analytics. Continue to the final article of this series to work with machine learning tools.
For even more in-depth Azure Synapse training, register to view the Hands-on Training Series for Azure Synapse Analytics.

