ANTLR is one of the simplest and most powerful tools available for generating parsing code. This article explains how to generate parsing code with ANTLR and use the code in a C++ application. It introduces ANTLR's grammar files and the fundamental classes of the ANTLR runtime. This article also shows how to build and run a simple application that parses an arithmetic operation.
1. Introduction
Many applications need to analyze the structure of text. Visual Studio analyzes code while you type and provides feedback and recommendations. Modern text editors analyze documents to check for errors in spelling and grammar. In both cases, the process of analyzing the structure of text is called parsing.
Rather than write a parser from scratch, it's easier to use a tool that generates parsing code. There are many options available, including GNU Bison and Lex/Yacc. This article and the next focus on ANTLR (ANother Tool for Language Recognition), which can be freely downloaded here.
These articles don't delve into the theory of parsing, so I won't discuss the merits of LL parsing versus LALR analysis. Instead, my goal is to provide a practical overview of ANTLR for C++ developers. This article presents the basics of ANTLR's usage and walks through the development of an application capable of parsing mathematical expressions. The next article explores ANTLR's advanced features.
2. Parsing Text with ANTLR
Terence Parr, a professor at the University of San Francisco, leads ANTLR development on the antlr.org web site. ANTLR is provided as a Java archive (JAR) and the name of the latest archive is antlr-4.9.2-complete.jar. This section explains how to generate parsing code in C++ and compile an application that uses the generated code.
2.1 Generating Parsing Code
To use ANTLR's JAR file, you need to be able to invoke the java executable from a command line. This is provided as part of the Java runtime environment, which can be downloaded from Oracle. After you've installed Java, you can execute commands that generate parsing code. The command for generating C++ code using ANTLR 4.9.2 is given as follows:
java -jar antlr-4.9.2-complete.jar -Dlanguage=Cpp <grammar-file>
The first flag, -jar, tells the runtime to execute code in the ANTLR JAR file. The second flag, -Dlanguage, identifies the target language. ANLTR supports several different languages, including Java, C#, Python, and JavaScript. This article is focused on generating C++ code, so -Dlanguage should be set to Cpp.
The last part of the command identifies a grammar file that describes the structure of the language to be analyzed. For example, if you want to generate a parser that analyzes Python code, the grammar file must define the general structure of Python code.
2.2 Building the Example Application
This article provides two zip files that contain C++ projects based on ANTLR's generated code. The first, expression_vs.zip, is intended for Windows systems running Visual Studio. The second, expression_gnu.zip, relies on GNU build tools, and is intended for Linux/macOS systems.
Both projects build an application that parses a string containing a mathematical expression like (2+3)*5. The grammar file is Expression.g4, and you can generate code from this grammar with the following command:
java -jar antlr-4.9.2-complete.jar -Dlanguage=Cpp Expression.g4
When this command is run, ANTLR generates several files. To build the example application, only six are required:
- ExpressionLexer.h - declares the lexer class,
ExpressionLexer - ExpressionLexer.cpp - provides code for the
ExpressionLexer class - ExpressionParser.h - declares the parser class,
ExpressionParser - ExpressionParser.cpp - provides code for the
ExpressionParser class - ExpressionListener.h - declares the listener class,
ExpressionListener - ExpressionListener.cpp - provides code for the
ExpressionListener class
For the example application, you'll only need to be concerned with two of these classes: the lexer class (ExpressionLexer) and the parser class (ExpressionParser). Put simply, a lexer extracts meaningful strings (tokens) from text and the parser uses tokens to determine the text's underlying structure. Listing 1 presents the code of main.cpp, which creates instances of these classes.
Listing 1: main.cpp
#include <iostream>
#include "antlr4-runtime.h"
#include "ExpressionLexer.h"
#include "ExpressionParser.h"
int main(int argc, const char* argv[]) {
antlr4::ANTLRInputStream input("6*(2+3)");
ExpressionLexer lexer(&input);
antlr4::CommonTokenStream tokens(&lexer);
ExpressionParser parser(&tokens);
std::cout << parser.expr()->toStringTree() << std::endl;
return 0;
}
To compile this, the compiler needs the antlr4-runtime.h header and other headers that declare ANTLR classses. Both projects contain these headers in their include directories.
After compilation, applications must be linked to a library containing ANTLR's code. I've placed the ANTLR libraries in the lib folder of each project. In the Visual Studio project, the lib folder contains antlr4-runtime.lib and antlr4-runtime.dll. In the GNU project, the lib folder contains libantlr4-runtime.so.
After the application is compiled and linked, it can be run as a regular executable. The example application prints a parse tree that defines the expression's structure. For the given example, the parse tree's result is given as:
(6*(2+3) (6 6) * ((2+3) ( (2+3 (2 2) + (3 3)) )))
I'll discuss parse trees later in this article and in the second article. Before that, I want to introduce ANTLR's grammars and present the fundamental classes of the ANTLR runtime.
3. Introducing ANTLR Grammar
Writing ANTLR grammar files isn't easy, so before you start a new *.g4 file, I recommend that you search the Internet for existing grammars. In particular, Tom Everett provides a wide range of grammar files on his Github repository. If one of these will be sufficient for your project, feel free to skip this section.
If you can't find an existing file for your project, you'll need to write your own. There are five fundamental points to know:
- The filename's suffix must be .g4.
- A line can be commented out by preceding it with two slashes (
//). - A grammar must be identified with
grammar name;, where name is the desired identifier. - After the identification statement, a grammar file contains a series of rule definitions.
- The grammar identification and rule definitions must end with semicolons.
To understand these points, it helps to look at an example. Listing 2 presents the content of Expression.g4, which is provided in the attached Expression_grammar.zip file.
Listing 2: Expression.g4
grammar Expression;
// Parser rule
expr : '-' expr | expr ( '*' | '/' ) expr |
expr ( '+' | '-' ) expr | '(' expr ')' | INT | ID;
// Lexer rules
INT : [0-9]+;
ID : [a-z]+;
WS : [ \t\r\n]+ -> skip;
This file identifies itself as Expression and then defines four rules. At minimum, a rule definition has a name and a description separated by colon. This is given by the following general format:
name : description;
The syntax of ANTLR's rules is based on the Extended Backus-Naur Form, or EBNF. The following discussion introduces the EBNF and then presents the different features in parser rules and lexer rules.
3.1 The Extended Backus-Naur Form (EBNF)
In the 1950s, researchers looked for ways to describe the syntax of programming languages. At IBM, John Backus devised a metalanguage to describe the new ALGOL language. Peter Naur expanded on this, and the resulting notation became known as the Backus-Naur form (BNF). Over time, new features were added and the result became known as the extended Backus-Naur form, or EBNF. In essence, EBNF is a language that describes languages.
According to EBNF, a rule's description is a combination of one or more strings. If the strings are separated by commas or spaces, they form a sequence. In this case, the rule is met if every string is present in the given order. The following rule defines a sequence containing four letters:
NAME : "n", "a", "m", "e";
If the description's strings are separated by vertical lines, the rule will be valid if any of the strings are present. For example, the following rule is met if any of the strings identify a single digit:
DIGIT : "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9";
If two strings are separated by a dash, it implies a range of values. The following rule looks for any alphabetic character, uppercase or lowercase.
ALPHA_CHAR : "a"-"z" | "A"-"Z"
Strings can be associated with punctuation that identifies how it's intended to be used.
- If a symbol is surrounded in curly braces, as in
{digit}, it can be repeated 0 or more times. - If a symbol is surrounded in square backets, as in
[digit], it can be repeated 0 or 1 time.
Braces, brackets, and parentheses are used to group symbols together, and a group of symbols can be used to form subrules.
- Inside a group, characters can be identified without quotes.
- If a group is followed by a question mark, as in
(x|y|z)?, the rule will match nothing or any alternative in the group. - If a group is followed by an asterisk, as in
(x|y|z)*, the rule will match nothing or any repeated alternative in the group. - If a group is followed by a plus sign, as in
(x|y|z)+, the rule will match any alternative repeated once or more.
The question mark, asterisk, and plus sign can also follow individual symbols. If a rule contains "TEST"?, it will match if zero or one instances of "TEST" are present.
3.2 Lexer Rules
Rules in an ANTLR grammar can be split into two groups. A lexer rule reads a stream of characters and extracts meaningful strings (tokens). A parser rule obtains the underlying structure of the text using lexer rules and other parser rules.
Lexer rules start with uppercase letters while parser rules start with lowercase letters. The following lexer rule from Expression.g4 extracts INT tokens.
INT : [0-9]+;
In ANTLR, lexer rules can access features that aren't available for parser rules. These include char sets, fragments, lexer commands, and special notation.
3.2.1 Char Sets
Many lexer rules associate a token with a group of characters, called a char set. A char set is a collection of characters inside square brackets. Char sets follow a different set of syntax rules:
- Characters in a char set don't need to be surrounded with quotes.
- Char sets don't use vertical lines to indicate alternatives. If a set contains a sequence of characters, the rule will be met if any of the characters are present.
- A space in a char set represents the space character.
- Special characters, such as quotes or brackets, must be escaped with a backslash (\) in a char set.
- Like other EBNF groups, char sets can be followed by
?, +, and * to indicate cardinality. - ANTLR provides special formatting rules for Unicode characters.
For example, the following rule states that an ID token consists of one or more lowercase alphabetic characters:
ID : [a-z]+;
This discussion won't explain how lexer rules access Unicode characters. For more information, visit ANTLR's documentation on lexer rules.
3.2.2 Fragments
If a lexer rule is preceded by fragment, it behaves like a regular lexer rule but doesn't define a new type of token. Using fragments increases the grammar's readability.
To understand fragments, suppose you want to define a token that represents numbers in scientific notation, such as 6.023e-23. If you don't want to create a separate token for the exponent, you can use fragments:
SCI_NUMBER : ('+'|'-')? DIGIT+ '.' DIGIT* EXPONENT?;
fragment EXPONENT : ('e'|'E') ('+'|'-') ? DIGIT+;
fragment DIGIT : '0'-'9';
Fragments can be accessed by lexer rules, but not by parser rules. A fragment's goal is to improve the readability of rules that extract tokens.
3.2.3 Lexer Commands
A lexer command tells the lexer to perform special processing on certain tokens. A lexer command consists of an arrow (->) followed by a command name.
The simplest and most common lexer command is skip, which tells the lexer to discard any tokens it finds of the given type. For example, the following rule defines a token named WS (whitespace) and tells the expression lexer to ignore any whitespace it encounters:
WS : [ \t\r\n]+ -> skip;
Another popular command is type(type_name), which changes the type of the token produced by the rule. For example, the following type command changes the rule to produce a STRING token instead of an INT.
INT : [0-9]+ -> type(STRING);
3.2.4 Special Notation
Lexer rules can employ special notation that isn't available for parser rules:
- A range between two values can be identified using two dots (
..) in addition to a hyphen (-). - Set inclusion can be negated with the tilde (~) operator.
For example, if a lexer rule wants to match characters other than a, b, or c, it could use the notation ~[a..c]*.
3.3 Parser Rules
Parser rules use lexer rules and other parser rules to obtain the underlying structure of the text. Parser rules can't access interesting features like char sets and fragments. But there are two aspects of parser rules that don't apply to lexer rules: start rules and custom exception handling.
3.3.1 Start Rules and EOF
Just as every C++ application starts with a main function, every ANTLR parser has a parser rule called the start rule. This is the first rule engaged by the parser, and it defines the highest-level structure of the text.
An example will help make this clear. Suppose you want to write a parser that analyzes poems. A poem contains one or more lines, so the start rule might look like this:
poem : line+ EOF;
The EOF token is provided by ANTLR, and though it stands for end of file, it applies to any source of text. This token represents the end of the incoming text. If the EOF is omitted, ANTLR will read as many lines as it can, and then give up (without error) if it can't parse a line.
It's common to make the start rule the first rule in the grammar. The following rules should proceed from high to low, with lexer rules following the parser rules.
3.3.2 Custom Exception Handling
If ANTLR encounters a syntax error while processing a rule, it catches the exception, reports the error, and returns from the rule. This exception handling can be customized by following the rule with a catch block. This has the following general format:
catch[ExceptionClass e] { process e }
Possible exception classes include RecognitionException, NoViableAltException, InputMismatchException, and FailedPredicateException. Each of these is a subclass of Java's RuntimeException class, so the methods printStackTrace, getMessage, and toString are available.
4. Fundamental ANTLR Classes
At this point, you should have a basic understanding of how grammar files identify the conventions of a language. In this section, we'll start looking at coding applications that rely on ANTLR's generated classes. At minimum, a parsing application needs to perform four steps:
- Create an
ANTLRInputStream to provide characters. - Create a lexer instance (
ExpressionLexer in our example) from the input stream. - Use the lexer instance to create a
CommonTokenStream that will provide tokens. - Create a parser instance (
ExpressionParser in our example) from the token stream.
If you've never worked with ANTLR before, these classes may seem bewildering. To introduce them, this section takes a gradual approach that proceeds from the simple to the complex. Every parsing application starts by extracting tokens from text, so I'll begin by discussing ANTLR's token classes.
4.1 Token Classes
As mentioned earlier, a lexer looks for meaningful strings in the text and produces tokens. ANTLR's tokens are represented by instances of the CommonToken class, which is a descendant of the Token and WritableToken classes. Figure 1 illustrates the class hierarchy.
Figure 1: Token Class Hierarchy
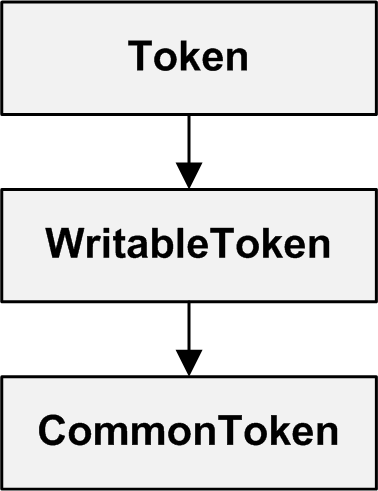
A Token can provide a great deal of information through its functions. Table 1 lists ten functions of the Token class, and all of them are pure virtual.
Table 1: Functions of the Token Class (Pure Virtual) | Function | Return Value |
getType() | The token's type |
getLine() | The number of the line containing the token |
getText() | The text associated with the token |
getCharPositionInLine() | The line position of the token's first character |
getTokenIndex() | The index of the token in the input stream |
getChannel() | The channel that provides the token to the parser |
getStartIndex() | The token's starting character index |
getStopIndex() | The token's last character index |
getTokenSource() | A pointer to the TokenSource that created the token |
getInputStream() | A pointer to the CharStream that provided the token's characters |
The first subclass of Token is WritableToken, provides methods that modify the token's data. For example, setText() changes the token's text and setType() changes the token's type.
The Token and WritableToken classes are pure virtual. The only concrete class in the token hierarchy is CommonToken. This provides code for the functions declared in the Token and WritableToken classes.
4.2 Stream Classes
ANTLR passes data using streams. Streams aren't collections, so you can't update a stream's elements the way you can update elements in a collection. Also, you can't access a stream's element by its index. Instead, a stream provides access to one element at a time (if an element is available). Figure 2 presents the hierarchy of ANTLR's stream classes.
Figure 2: Stream Class Hierarchy

The top of the hierarchy is the IntStream class, which provides functions for accessing the stream's elements. Table 2 lists seven of these functions, and all of them are pure virtual.
Table 2: Functions of the IntStream Class (Pure Virtual) | Function | Description |
consume() | Accesses and consumes the current element |
LA(ssize_t i) | Reads the element i positions away |
mark() | Returns a handle that identifies a position in the stream |
release(ssize_t marker) | Releases the position handle |
index() | Returns the index of the upcoming element |
seek(ssize_t index) | Set the input cursor to the given position |
size() | Returns the number of elements in the stream |
Below IntStream, the next classes are CharStream and TokenStream. CharStream provides character data through getText(). TokenStream provides Tokens through get() and character data through getText().
IntStream and CharStream are virtual classes, so applications provide data by creating instances of ANTLRInputStream and ANTLRFileStream. The ANTLRInputStream class has five public constructors:
ANTLRInputStream() - Creates an empty ANTLRInputStreamANTLRInputStream(const std::string& input) - Creates an ANTLRInputStream containing the given stringANTLRInputStream(std::istream &stream) - Creates an ANTLRInputStream containing characters from the given input streamANTLRInputStream(const char* data, size_t length) - Creates an ANTLRInputStream containing the specified charactersANTLRInputStream(const std::string_view& input) - Creates an ANTLRInputStream containing the given string view (available for C++17 and higher)
TokenStream has two subclasses: UnbufferedTokenStream and BufferedTokenStream. The main difference between them is that BufferedTokenStream provides several methods that provide vectors of Tokens. For example, getTokens() returns all of the stream's tokens and get(int start, int stop) returns the tokens between the given values.
The last class in the stream hierarchy, CommonTokenStream, is important because it provides the CommonTokens required by an ANTLR-generated parser. The CommonTokenStream constructor requires a pointer to a TokenSource instance (such as a lexer). Then it's accepted by the Parser constructor to provide CommonTokens.
4.3 The Lexer Class
When you generate code from the Expression.g4 grammar, you'll find two important source files: ExpressionLexer.h and ExpressionLexer.cpp. The first declares the ExpressionLexer class and the second provides code for its functions. ExpressionLexer is a subclass of ANTLR's Lexer class, and Figure 3 illustrates the class hierarchy of lexers and parsers.
Figure 3: Lexer/Parser Class Hierarchy
As input, the ExpressionLexer constructor accepts a pointer to a CharStream containing text to be parsed. As discussed earlier, CharStream is pure virtual, so applications usually provide text by creating an instance of ANTLRInputStream.
If you look in the main.cpp file, you'll see that it creates the ExpressionLexer with the following code:
antlr4::ANTLRInputStream input("6*(2+3)");
ExpressionLexer lexer(&input);
Once the ExpressionLexer is created, you can call its methods to obtain information about lexer rules and tokens. For example, calling getRuleNames() returns a vector containing "T__0", "T__1", "T__2", "T__3", "T__4", "T__5", "INT", "ID", and "WS". getTokenNames() returns a vector containing <INVALID>, '-', '*', '/', '+', '(', ')', INT, ID, and WS.
Most applications don't call lexer functions, and simply use the lexer to create a parser. Because the ExpressionLexer inherits from TokenSource, it can be used to create a CommonTokenStream, which can be used to create an ExpressionParser. This is shown in the following code:
antlr4::CommonTokenStream commonStream(&lexer);
ExpressionParser parser(&commonStream);
4.4 The Parser Class
ANTLR's Parser has the overall responsibility for text analysis. This class provides several functions, and rather than list them all at once, I'll split them into four categories:
- Functions related to tokens
- Functions related to parse trees and parse tree listeners
- Functions related to errors
- Functions related to rules and rule contexts
This discussion explores the functions in these categories. For more information on the Parser class, visit ANTLR's official documentation.
4.4.1 Token Functions
Every Parser can access a source of tokens and read individual tokens. The functions in Table 3 make this possible:
Table 3: Token Functions of the Parser Class | Function | Description |
consume() | Consumes and returns the current token |
getCurrentToken() | Returns the current token |
isExpectedToken(size_t symbol) | Checks whether the current token has the given type |
getExpectedTokens() | Provides tokens in the current context |
isMatchedEOF() | Identifies the current token is EOF |
createTerminalNode(Token* t) | Adds a new terminal node to the tree |
createErrorNode(Token* t) | Adds a new error node to the tree |
match(size_t ttype) | Returns the token if it matches the given type |
matchWildcard() | Match the current token as a wildcard |
getInputStream() | Returns the parser's IntStream |
setInputStream(IntStream* is) | Sets the parser's IntStream |
getTokenStream() | Returns the parser's TokenStream |
setTokenStream(TokenStream* ts) | Sets the parser's TokenStream |
getTokenFactory() | Returns the parser's TokenFactory |
reset() | Resets the parser's state |
Most of these functions are easy to understand. An application can control the parsing process by calling consume() to access each token from the stream. Applications can also add nodes to the parser's tree by calling createTerminalNode() and createErrorNode().
4.4.2 Parse Tree and Listener Functions
On of the Parser's primary jobs is to create a parse tree from the input text. As the following article will explain, listeners make it possible to access the tree's nodes programmatically. Table 4 lists many of the Parser functions related to parse trees and listeners.
Table 4: Parser Functions Related to Parse Trees and Listeners | Function | Description |
getBuildParseTree() | Checks if a parse tree will be constructed during parsing |
setBuildParseTree(bool b) | Identifies if a parse tree should be constructed |
getTrimParseTree() | Checks if the parse tree is trimmed during parsing |
setTrimParseTree(bool t) | Identifies the parse tree should be trimmed during parsing |
getParseListeners() | Returns the vector containing the parser's listeners |
addParseListener(
ParseTreeListener* ptl) | Adds a listener to the parser |
removeParseListener(
ParseTreeListener* ptl) | Removes a listener from the parser |
removeParseListeners() | Removes all listeners from the parser |
By default, parsers create a tree with every node from the source text. This behavior can be configured by calling setTrimParseTree() with an argument set to true. This tells the parser to use a TrimToSizeListener to determine which nodes should be removed from processing.
4.4.3 Error Functions
Parsers keep track of each error detected during parsing. Applications can customize error handling using the functions in Table 5.
Table 5: Error Functions of the Parser Class | Function | Description |
getNumberOfSyntaxErrors() | Returns the number of syntax errors |
getErrorHandler() | Returns the parser's error handler |
setErrorHandler(handler) | Sets the parser's error handler |
notifyErrorListeners(string msg) | Sends a message to the parser's error listeners |
notifyErrorListeners(Token* t,
string msg, exception_ptr e) | Sends data to the parser's error listeners |
The setErrorHandler function is particularly important, because it allows an application to customize how exceptions are handled. This accepts a reference to an ANTLRErrorStrategy, and I'll discuss this further in the following article.
4.4.4 Rule and Context Functions
During the text analysis, the parser enters and exits different rules of the grammar. The information associated with each rule is called the rule context. Table 6 lists the functions that access the parser's rules and rule contexts.
Table 6: Parser Functions Related to Rules and Contexts | Function | Description |
enterRule(ParserRuleContext* ctx,
size_t state, size_t index) | Called upon rule entry |
exitRule() | Called upon rule exit |
triggerEnterRuleEvent() | Notify listeners of rule entry |
triggerExitRuleEvent() | Notify listeners of rule exit |
getRuleIndex(string rulename) | Identify the index of the given rule |
getPrecedence() | Get the precedence level of the topmost rule |
getContext() | Returns the context of the current rule |
setContext(ParserRuleContext* ctx) | Sets the parser's current rule |
getInvokingContext(size_t index) | Returns the context that invoked the current context |
getRuleInvocationStack() | Returns a list of rules processed up to the current rule |
getRuleInvocationStack(
RuleContext* ctx) | Returns a list of rules processed up to the given rule |
The setContext function tells the parser to process a specific context. This can be very helpful when debugging complex text structures.
5. Parse Trees and Rule Contexts
When ANTLR generates a Parser class, it creates functions whose names are based on the grammar's rules. Functions named after lexer rules return TerminalNode pointer and functions named after parser rules return ParserRuleContext pointers. As we'll see, ParserRuleContexts are very important in ANTLR applications.
To see what these functions look like, I recommend that you open the ExpressionParser.h header file in the example code. This defines two functions named after lexer rules (INT and ID), which return TerminalNode pointers. It also defines an expr function that returns a pointer to an ExprContext. Figure 4 presents the inheritance hierarchy of the ExprContext class.
Figure 4: ExprContext Inheritance Hierarchy
This section looks at the ParseTree, RuleContext, and ParserRuleContext classes. Once you understand them, you'll be better able to access ANTLR-generated code in your applications.
5.1 The ParseTree Class
After a parser has successfully analyzed a block of text, the text's structure can be expressed as a tree whose nodes correspond to the grammar's rules. This is called a parse tree, and Figure 5 displays the parse tree generated for the expression 6*(2+3).
Figure 5: Parse Tree of the Example Application
As shown, the top node of the tree (the root) corresponds to the grammar's first rule. The bottom nodes (terminal nodes) identify tokens that match the lexer rules.
If you look through the code in the ANTLR C++ runtime, you'll find a folder named tree that contains code related to parse trees. Tree-related classes include ParseTree, TerminalNode, ParseTreeVisitor, and ParseTreeWalker, and they all belong to the antlr4::tree namespace.
Despite its name, a ParseTree represents a single node of a parse tree, not the entire tree. It has a parent property that points to its parent node (null for the root node) and a property named children, which is a vector of ParseTree pointers that identify its child nodes (empty for terminal nodes). ParseTree also has three helpful functions:
accept(ParseTreeVisitor*) - allows a visitor to access the node's datatoString() - returns a string containing the node's datatoStringTree(Parser* parser, bool pretty = false) - returns a string containing data for the entire tree
The second article in this series explains how to use ParseTreeVisitors and ParseTreeWalkers. The example code in this article calls toStringTree to display the structure of the parsed expression.
5.2 The RuleContext Class
Just as a ParseTree represents a single node in the tree, a RuleContext represents the invocation of a single rule. Every RuleContext has a property named invokingState that identifies how it was called. The invokingState of the root node is always -1.
The RuleContext class provides a function that every developer should be aware of: getText(). This returns the text associated with the given rule. If you call getText() on the context for the parser's start rule, it will return all of the text.
5.3 The ParserRuleContext Class
As its name implies, a ParserRuleContext is a rule context related to parsing. If the rule didn't complete successfully, the exception property will point to the RecognitionException that describes the issue. If the rule completes successfully, exception will be null.
Every ParserRuleContext keeps track of the starting and ending tokens in the context. These can be accessed by calling getStart and getStop. An application can also find out which portion of the text corresponds to the context by calling getSourceInterval().
5.4 The ExprContext Class
ANTLR generates the ExprContext class as a context for the expr rule in Expression.g4. As demonstrated in the main.cpp code, an application can obtain an ExprContext by calling the parser's expr function. The generated parser has a function for every rule in the grammar, and invoking the function will return the corresponding rule context.
Inside ExpressionParser.h, the ExprContext class is defined with the following code:
class ExprContext : public antlr4::ParserRuleContext {
public:
ExprContext(antlr4::ParserRuleContext *parent, size_t invokingState);
virtual size_t getRuleIndex() const override;
std::vector<ExprContext *> expr();
ExprContext* expr(size_t i);
antlr4::tree::TerminalNode *INT();
antlr4::tree::TerminalNode *ID();
virtual void enterRule(antlr4::tree::ParseTreeListener *listener) override;
virtual void exitRule(antlr4::tree::ParseTreeListener *listener) override;
};
As given in the grammar, an expr node may be composed of other expr nodes. These other nodes can be accessed through the expr() function, which returns a vector of ExprContext pointers. An application can also access the expression's tokens through the TerminalNode pointers returned by INT() and ID().
The last two functions allow listeners to respond when the parser starts processing the rule (enterRule) and completes processing the rule (exitRule). The second article in this series demonstrates how to create listeners and shows how enterRule and exitRule are used in practice.
6. History
- 1st August, 2021: Submitted Version 1.0 of the article
- 4th August, 2021: Correctly identified the grammar's zip file

