Here we download a copy of the trained model for offline use. Then, we show how to write a simple Python app that can pull images from a camera multiple times per second, run through the model, and determine if a pedestrian has stepped into the field of view.
This three-part article series explores how to train, test, and deploy an AI model to detect pedestrians in front of a vehicle using Azure Custom Vision.
The previous article tested, re-trained, and re-tested an object detection model. However, it is of limited use without final deployment.
This article will cover downloading a copy of the trained model for offline use. It will also demonstrate how to deploy the model to a Raspberry Pi and modify it to act as a real-time object detector.
Visit GitHub for this demonstration’s complete code.
Exporting the Model
The previous article in this series tested the model several times and iterated to improve the model’s performance. Now, it is time to export the model and run it offline.
Select your project in the Custom Vision service web portal. Move to your project’s Performance tab, select the iteration you want to export, and click Export on the top menu bar.
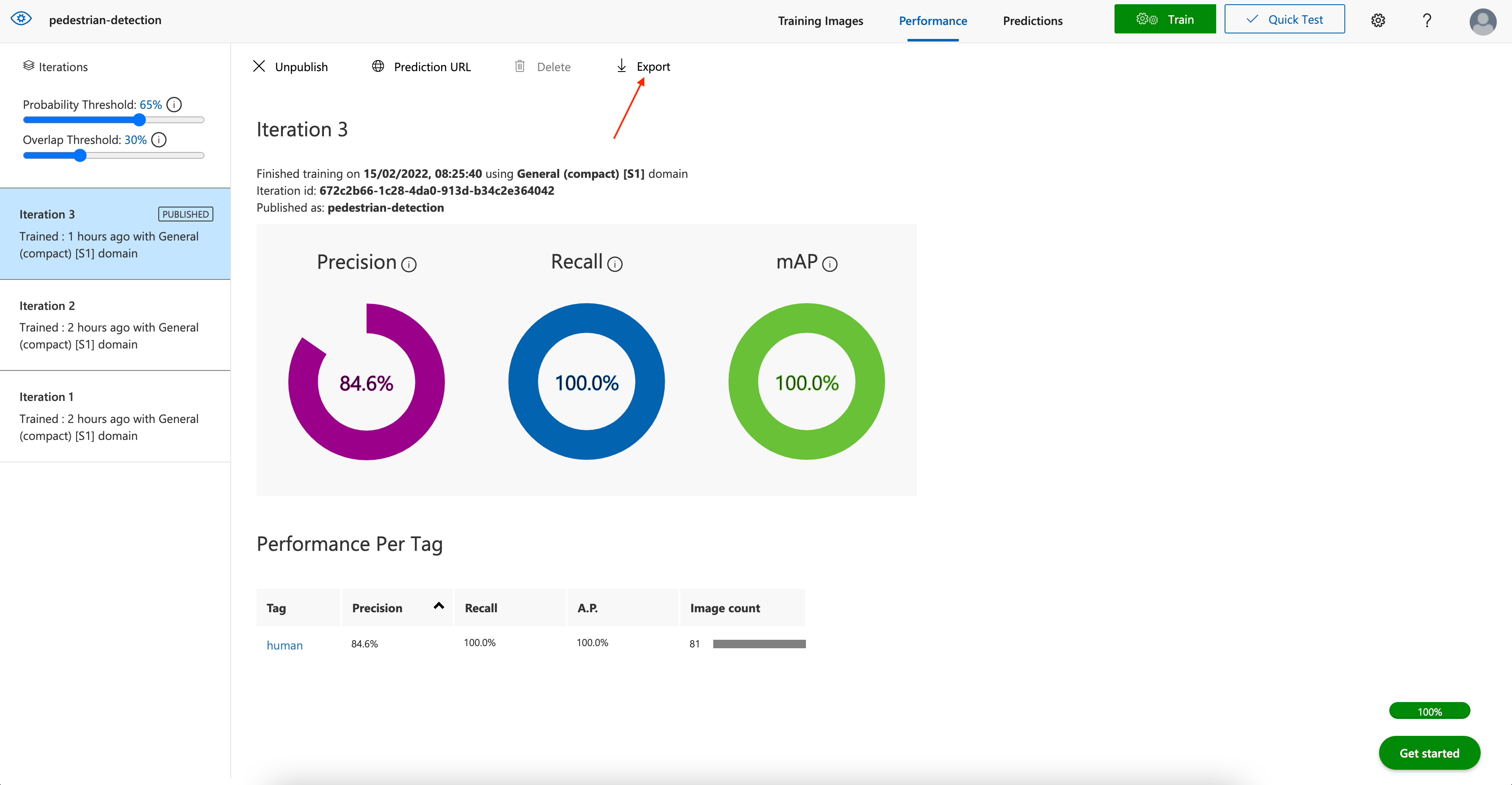
The next page prompts you to choose your platform. Select Dockerfile since you’ll be running the model on an edge device.
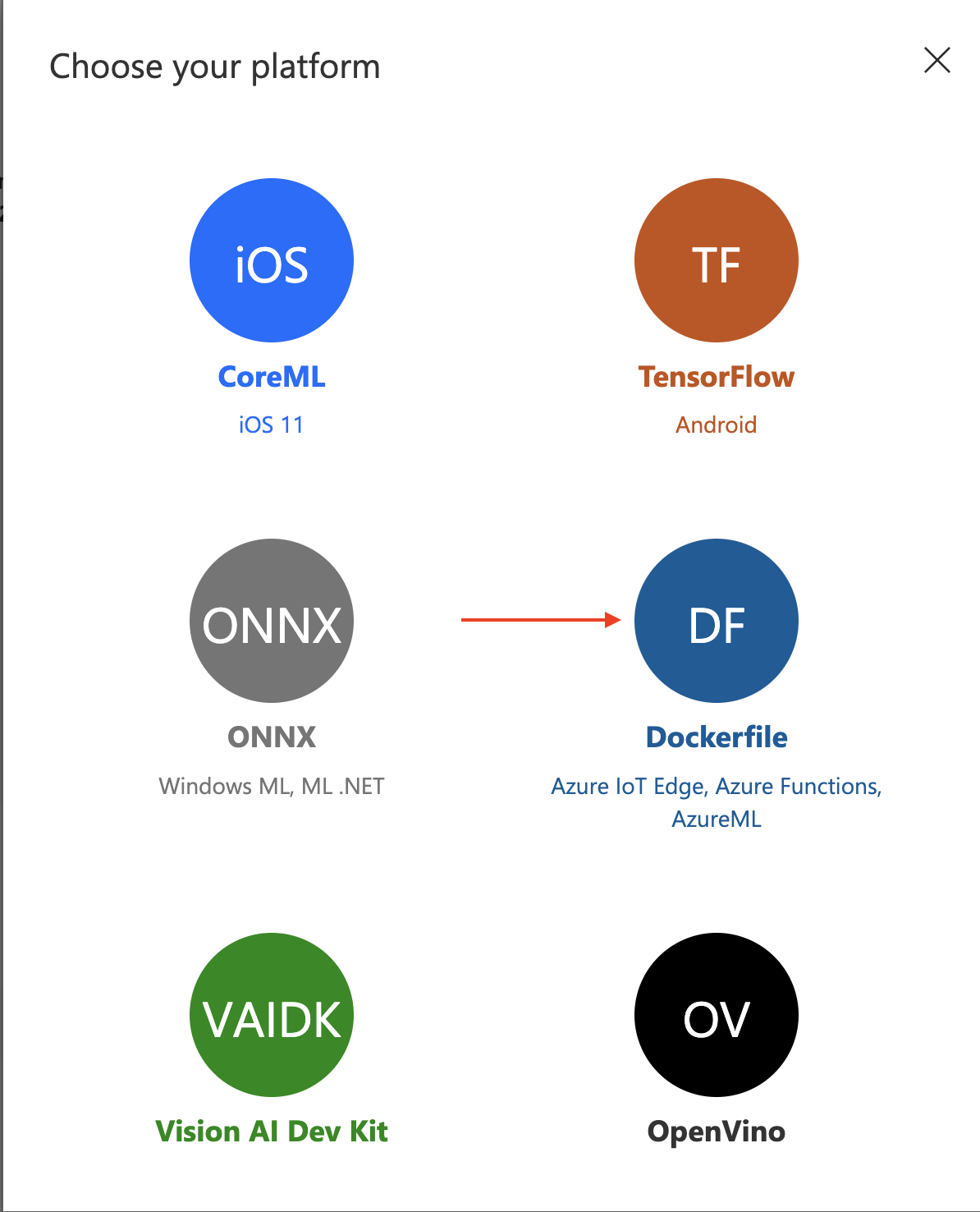
The next step is to specify the type of platform where you’ll be running the model. Select ARM (Raspberry Pi 3) from the menu and click Export. Then, click Download.
The above option downloads a .zip file containing the ready-made solution to run the model on a Raspberry Pi device.
Now that the model is ready to run offline, we’ll set up the Raspberry Pi to host the service.
Setting up Your Raspberry Pi
This article assumes that your device uses the Raspberry Pi operating system (OS). If not, follow Raspberry Pi’s Getting Started Guide to install the OS on your device. Once you’ve installed the OS, install the other required packages to run the object detection model.
Note: We tested this article’s setup and code on the Raspberry Pi 4 Model B with Debian Buster (now called the Raspberry Pi Legacy OS) and Raspberry Pi Camera V2 with Python 3.7. However, the code should work with any version of the OS, camera, and required modules.
Before installing the required modules, update all packages with the following command:
$ sudo apt-get update && sudo apt-get upgrade
You should create a virtual environment to install the required modules. Create and activate a virtual environment with the name env as follows:
$ python3 -m venv env
$ source env/bin/activate
Once your virtual environment is activated, install the required packages. The Custom Vision model requires TensorFlow on the edge device.
Execute the following command to install TensorFlow 2.4.0 with Python 3.7.
$ pip install https:
Then install a Pillow library to support opening, manipulating, and saving the images.
$ pip install pillow
Finally, install Flask to run the server.
$ pip install flask
Once you’ve installed the modules mentioned above, your environment is ready to host the Custom Vision model.
Next, run your Custom Vision model on the Raspberry Pi. The previously-exported trained model is in .zip format, which should be easy to bring to Raspberry Pi.
Unzip the exported model on your Raspberry Pi and go to the app directory. This directory contains the trained model, labels, and Flask app files to handle the image prediction.
First, examine the predict.py file:
import tensorflow as tf
import numpy as np
import PIL.Image
from datetime import datetime
from urllib.request import urlopen
MODEL_FILENAME = 'model.pb'
LABELS_FILENAME = 'labels.txt'
od_model = None
labels = None
class ObjectDetection:
INPUT_TENSOR_NAME = 'image_tensor:0'
OUTPUT_TENSOR_NAMES = ['detected_boxes:0', 'detected_scores:0', 'detected_classes:0']
def __init__(self, model_filename):
graph_def = tf.compat.v1.GraphDef()
with open(model_filename, 'rb') as f:
graph_def.ParseFromString(f.read())
self.graph = tf.Graph()
with self.graph.as_default():
tf.import_graph_def(graph_def, name='')
with tf.compat.v1.Session(graph=self.graph) as sess:
self.input_shape = sess.graph.get_tensor_by_name(self.INPUT_TENSOR_NAME).shape.as_list()[1:3]
def predict_image(self, image):
image = image.convert('RGB') if image.mode != 'RGB' else image
image = image.resize(self.input_shape)
inputs = np.array(image, dtype=np.float32)[np.newaxis, :, :, :]
with tf.compat.v1.Session(graph=self.graph) as sess:
output_tensors = [sess.graph.get_tensor_by_name(n) for n in self.OUTPUT_TENSOR_NAMES]
outputs = sess.run(output_tensors, {self.INPUT_TENSOR_NAME: inputs})
return outputs
def initialize():
global od_model
od_model = ObjectDetection(MODEL_FILENAME)
global labels
with open(LABELS_FILENAME) as f:
labels = [l.strip() for l in f.readlines()]
def predict_url(image_url):
with urlopen(image_url) as binary:
image = PIL.Image.open(binary)
return predict_image(image)
def predict_image(image):
predictions = od_model.predict_image(image)
predictions = [{'probability': round(float(p[1]), 8),
'tagId': int(p[2]),
'tagName': labels[p[2]],
'boundingBox': {
'left': round(float(p[0][0]), 8),
'top': round(float(p[0][1]), 8),
'width': round(float(p[0][2] - p[0][0]), 8),
'height': round(float(p[0][3] - p[0][1]), 8)
}
} for p in zip(*predictions)]
response = {'id': '', 'project': '', 'iteration': '', 'created': datetime.utcnow().isoformat(),
'predictions': predictions}
print("Results: " + str(response))
return response
The above code defines the following methods:
ObjectDetection class loads the trained model. The ObjectDetection class also defines a method named predict_image to take the image as input, score it using the model, and return the predictions.initialize method creates an object of the ObjectDetection class and loads the labels from the specified label file.predict_url method takes the image URL as an argument, loads the image from the specified URL, and returns the call to the predict_image method.predict_image method takes the image file as an argument and calls the predict_image method of the ObjectDetection class. It saves the returned response in the predictions variable and separately shows the probability, tagId, tagName, and boundingBox on the screen.
Now, examine the app.py file:
import json
import os
import io
from flask import Flask, request, jsonify
from PIL import Image
from predict import initialize, predict_image, predict_url
app = Flask(__name__)
app.config['MAX_CONTENT_LENGTH'] = 4 * 1024 * 1024
@app.route('/')
def index():
return 'CustomVision.ai model host harness'
@app.route('/image', methods=['POST'])
@app.route('/<project>/image', methods=['POST'])
@app.route('/<project>/image/nostore', methods=['POST'])
@app.route('/<project>/classify/iterations/<publishedName>/image', methods=['POST'])
@app.route('/<project>/classify/iterations/<publishedName>/image/nostore', methods=['POST'])
@app.route('/<project>/detect/iterations/<publishedName>/image', methods=['POST'])
@app.route('/<project>/detect/iterations/<publishedName>/image/nostore', methods=['POST'])
def predict_image_handler(project=None, publishedName=None):
try:
imageData = None
if ('imageData' in request.files):
imageData = request.files['imageData']
elif ('imageData' in request.form):
imageData = request.form['imageData']
else:
imageData = io.BytesIO(request.get_data())
img = Image.open(imageData)
results = predict_image(img)
return jsonify(results)
except Exception as e:
print('EXCEPTION:', str(e))
return 'Error processing image', 500
@app.route('/url', methods=['POST'])
@app.route('/<project>/url', methods=['POST'])
@app.route('/<project>/url/nostore', methods=['POST'])
@app.route('/<project>/classify/iterations/<publishedName>/url', methods=['POST'])
@app.route('/<project>/classify/iterations/<publishedName>/url/nostore', methods=['POST'])
@app.route('/<project>/detect/iterations/<publishedName>/url', methods=['POST'])
@app.route('/<project>/detect/iterations/<publishedName>/url/nostore', methods=['POST'])
def predict_url_handler(project=None, publishedName=None):
try:
image_url = json.loads(request.get_data().decode('utf-8'))['url']
results = predict_url(image_url)
return jsonify(results)
except Exception as e:
print('EXCEPTION:', str(e))
return 'Error processing image'
if __name__ == '__main__':
initialize()
app.run(host='0.0.0.0', port=80)
The above code creates a Flask rest API for the object detection model. It defines two methods: predict_image_handler and predict_url_handler, which the application calls depending on whether the prediction is for the image file or the image file URL.
After exploring how the model runs offline, run the application.
First, change the host and port in the app.py file as follows:
app.run(host='127.0.0.1', port=5000)
Save the file with this modification and run the app:
$ python app.py
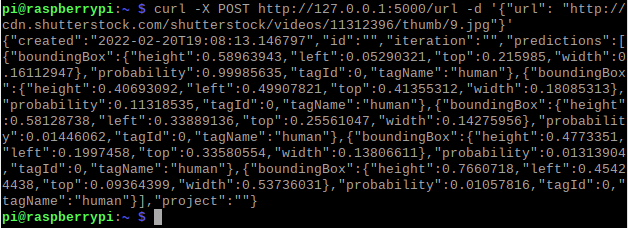
Leave the server running. Open another terminal and post a request to the server using the following curl command:
$ curl -X POST http:
The above command invokes the Prediction API, and the predictions will appear on your screen.
Enabling Real-time Object Detection on Raspberry Pi
The model is now running offline and can detect when and where a human is present in an image. However, the model currently works only with still images. It must be able to immediately determine if a pedestrian has stepped into the field of view.
To capture the video stream, extract its images, run them through the model, and detect a person's presence, you’ll need to install OpenCV on Raspberry Pi. This library should enable real-time object detection.
Use the following command to install OpenCV:
$ pip install opencv-python
Once OpenCV has successfully installed, a real-time object detector is mere steps away.
Note: Before proceeding, test your camera module. You can try the Raspberry Pi Camera V2 using the following command:
$ raspistill –o output.jpg
If you’re using another camera, ensure that it is compatible with Raspberry Pi and can capture images and video. Otherwise, the program triggers an error.
Now, create another file named pedestrian-detection.py in your app directory and add the following code:
import cv2
from PIL import Image
from predict import initialize, predict_image
def main():
initialize()
capture = cv2.VideoCapture(0)
while(True):
ret, frame = capture.read()
predictions = predict_image(Image.fromarray(frame))
cv2.imshow('Pedestrian detector', frame)
keyCode = cv2.waitKey(30) & 0xFF
if keyCode == 27:
break
capture.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
The above program starts by loading and initializing the model. Next, it creates an object-capture function for capturing the video. Then, it reads each frame and passes the frame to the predict_image method, both for prediction and to display the frame. It also defines the key just in case it must break the loop. Finally, once the loop is over, it releases the video capture and destroys all the windows.
Now, run the program as follows:
$ python pedestrian-detection.py
Once your program runs successfully, a separate window with the current camera field opens, and you’ll see the predictions in your terminal.
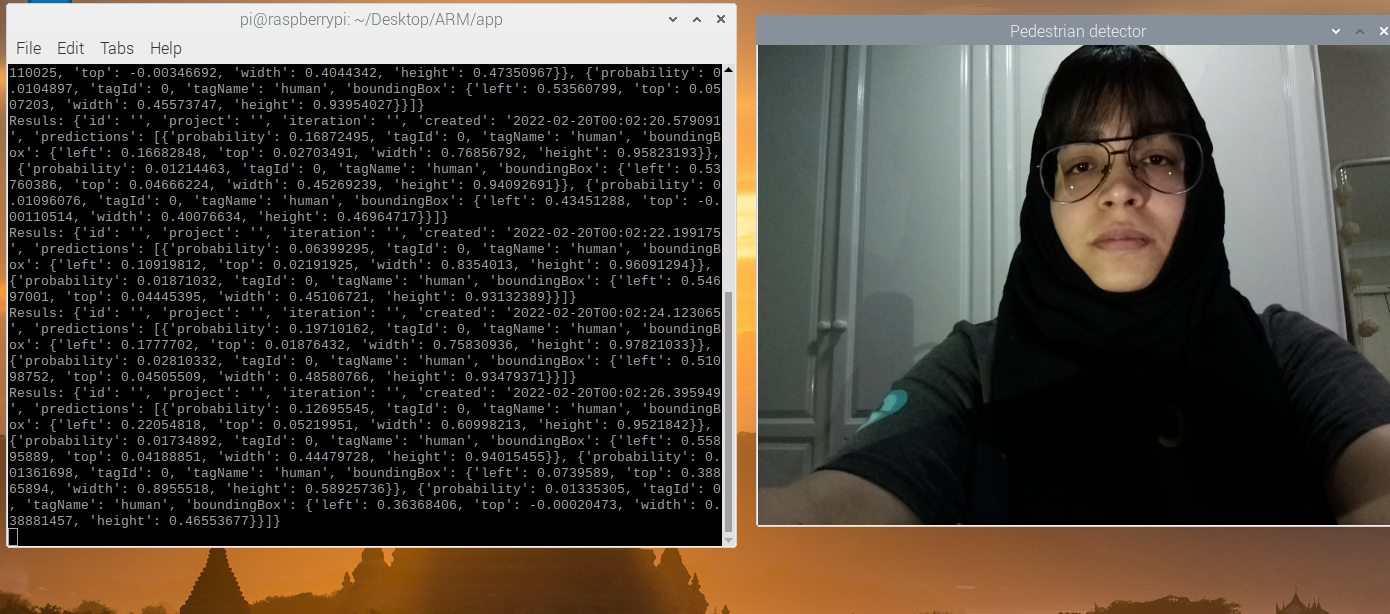
If the current field of view is empty, your model returns an empty predictions list.
Summary
This article demonstrated how to deploy the model on the edge for real-time predictions. The Custom Vision service enables training and deploying complicated machine learning models without comprehensive knowledge of the underlying AI and algorithms.
This article series is an introductory guide for Azure’s Custom Vision service. The Custom Vision service enables a broad range of developers to train and deploy machine learning models tailored specifically to their use cases.
Now that you know how easy it is, check out Azure’s Custom Vision service to learn more about training and deploying machine learning models.
To learn how to drive app innovation and reap lasting business benefits with a faster approach to AI, check out Forrester study: Fuel Application Innovation with Specialized Cloud AI Services.

