There are scenarios where the same operation needs to be performed many times. One such case is when you need to translate every SID in a user's token to a human readable name. When those operations take a significant amount of time, there is a significant potential optimization by performing them in parallel.
Introduction
Microsoft Visual Studio comes with the Parallel Programming Library which contains a number of functions that make it trivial to execute code in parallel. One of them is the parallel_for which we will explore here.
Background
In my previous article, I provided a way to extract all privileges and groups from a user's access token. Wanting to test my code in a more complex environment, I ran it on my work laptop with my corporate user account. As is common in large corporate environments, my account is member of many groups. 256 to be precise. Actually, I suspect my account would be member of more groups, but there is a hard limit of 256 group SIDs in a token.
When my computer is on the company network, this scan took 0.8 seconds which is hardly noticeable. But when I connect from home using VPN, this took 4.5 seconds. This is unacceptably long if it would be involved in a GUI update.
Most of that time is spent in win32 API calls. And since every lookup is essentially independent of the other ones, this is a prime example of a scenario where we can gain time.
Implementing a parallel_for Loop
This is the code we start with, which is a single thread for loop.
ULONG w32_GetTokenGroups(HANDLE hToken, vector<w32_CUserGroup>& groups) {
DWORD bufLength = 0;
DWORD retVal = NO_ERROR;
PTOKEN_GROUPS pGroups = NULL;
retVal = w32_GetTokenInformation(hToken, TokenGroups, (PVOID&)pGroups, bufLength);
if (retVal == NO_ERROR) {
groups.resize(pGroups->GroupCount);
TCHAR name[w32_MAX_GROUPNAME_LENGTH];
DWORD nameSize = sizeof(name);
TCHAR domain[w32_MAX_DOMAINNAME_LENGTH];
DWORD domainSize = sizeof(domain);
SID_NAME_USE sidType;
for (DWORD i = 0; i < pGroups->GroupCount; i++) {
DWORD nameSize = sizeof(name);
DWORD domainSize = sizeof(domain);
PSID pSid = pGroups->Groups[i].Sid;
LPTSTR sidString = NULL;
if (!LookupAccountSid(
NULL, pSid, name, &nameSize, domain, &domainSize, &sidType)) {
retVal = GetLastError();
break;
}
if (!ConvertSidToStringSid(pSid, &sidString)) {
retVal = GetLastError();
break;
}
groups[i].Attributes = pGroups->Groups[i].Attributes;
groups[i].Domain = domain;
groups[i].Sid = sidString;
groups[i].Name = name;
groups[i].SidType = sidType;
LocalFree(sidString);
}
}
if (pGroups)
HeapFree(GetProcessHeap(), 0, pGroups);
if (retVal != NO_ERROR)
groups.clear();
return retVal;
}
There are a couple of observations to be made:
- The results of our operation are stored in a vector. While a vector is not threadsafe for concurrent modifications, it is safe to modify referenced items contained in a vector as long as 1 thread only accesses 1 item. Because the vector is resized before the
for loop, this is not an issue. - The call to
ConvertSidToStringSid is safe as well, because its parameters are local to the loop. - The call to
LookupAccountSid is unsafe because it references variables outside the loop. This was a sensible decision for a single thread loop because it decreases stack allocations. But in the scheme of things, the inefficiency doesn't really matter compared to the actual operations.
The parallel_for helper has this signature:
template <typename _Index_type, typename _Function>
void parallel_for(
_Index_type first,
_Index_type last,
const _Function& _Func,
const auto_partitioner& _Part = auto_partitioner());
Just like the normal for loop, you supply the initial index and the size. It's a tad confusing because it says 'last' but the documentation specifies it is the index past the last element so if you start at 0, last is actually the number of elements. And finally, it takes the function to execute in parallel. The partitioner divides the workload. Unless you have a specific reason to do things differently, just go with the default.
If we implement it, we get this:
ULONG w32_GetTokenGroups(HANDLE hToken, vector<CGroupIdentity>& groups) {
DWORD bufLength = 0;
DWORD retVal = NO_ERROR;
PTOKEN_GROUPS pGroups = NULL;
retVal = w32_GetTokenInformation
(hToken, TokenGroups, (PVOID&)pGroups, bufLength);
if (retVal == NO_ERROR) {
groups.resize(pGroups->GroupCount);
concurrency::parallel_for(size_t(0),
(size_t)pGroups->GroupCount, [&](size_t i) {
if (retVal == NO_ERROR) {
TCHAR name[MAX_GROUPNAME_LENGTH];
DWORD nameSize = sizeof(name);
TCHAR domain[MAX_DOMAINNAME_LENGTH];
DWORD domainSize = sizeof(domain);
SID_NAME_USE sidType;
PSID pSid = pGroups->Groups[i].Sid;
LPTSTR sidString = NULL;
if (!LookupAccountSid(
NULL, pSid, name, &nameSize, domain, &domainSize, &sidType)) {
retVal = GetLastError();
return;
}
if (!ConvertSidToStringSid(pSid, &sidString)) {
retVal = GetLastError();
return;
}
groups[i].Attributes = pGroups->Groups[i].Attributes;
groups[i].Domain = domain;
groups[i].Sid = sidString;
groups[i].Name = name;
groups[i].SidType = sidType;
LocalFree(sidString);
}
});
}
if (pGroups)
HeapFree(GetProcessHeap(), 0, pGroups);
if (retVal != NO_ERROR)
groups.clear();
return retVal;
}
We need to move the buffers inside the loop to make them safe, but that's about it. The time to translate 256 SIDs via the VPN has now gone down from 4500 ms to 1000 ms. That's still quite a long time, but for a one-time operation during a screen update (remember that the token is immutable) I can live with single 1000 ms update.
Perhaps a word on error handling: It looks as if there is a race condition: what happens if during the parallel execution, there are 2 threads encountering an error? The correct answer is: there is indeed a race in writing retVal. That doesn't really matter though. The only thing that matters is that if 'an' error occurs, we know it after the loop is finished. Which specific iteration failed doesn't matter. And since each iteration runs in parallel in their own thread, they don't affect each other. As soon as retVal is set to anything other than NO_ERROR, nothing will be executed anymore.
Ppl has support for cancellation, but it involves the loops checking a cancellation token and in such simple tasks as our lambda function, there is not much to be gained from that.
Making the Parallel Execution Optional
This is normally where I would have ended my article, but as described here, about 1 time in 7, Symantec decides that performing parallelized lookups in different threads is a sign of nefarious activities and rips the executable from existence without a peep.
Now in a corporate environment, things like virus scanners are managed by corporate teams who don't want to hear complaints and who are not interested unless there is a major production outage.
Still, I didn't want to handicap my application and put everything in a single thread just because there is one environment where the parallelisation causes issues. As it turns out: making the parallel behavior optional and subject to a simple boolean value is easy.
After all, the parallel_for is already working with a lambda expression. All we have to do is pull it one level higher. We can trivially refactor the translation routine like this:
if (retVal == NO_ERROR) {
groups.resize(pGroups->GroupCount);
auto translator = [&](size_t i) {
if (retVal == NO_ERROR) {
TCHAR name[MAX_GROUPNAME_LENGTH];
DWORD nameSize = sizeof(name);
TCHAR domain[MAX_DOMAINNAME_LENGTH];
DWORD domainSize = sizeof(domain);
SID_NAME_USE sidType;
PSID pSid = pGroups->Groups[i].Sid;
groups[i].Attributes = pGroups->Groups[i].Attributes;
if (!LookupAccountSid(
NULL, pSid, name, &nameSize, domain, &domainSize, &sidType)) {
retVal = GetLastError();
return;
}
groups[i].SidType = sidType;
groups[i].Name = name;
groups[i].Domain = domain;
LPTSTR sidString = NULL;
if (!ConvertSidToStringSid(pSid, &sidString)) {
retVal = GetLastError();
return;
}
groups[i].Sid = sidString;
LocalFree(sidString);
}
};
if (parallelGroupLookup) {
concurrency::parallel_for(size_t(0),
(size_t)pGroups->GroupCount, translator);
}
else {
for (int i = 0; i < pGroups->GroupCount; i++) {
translator(i);
}
}
With lambda expressions and the ppl framework, doing powerful and flexible parallelisation is trivial.
Measuring Execution Time
In order to measure the time of different operations correctly, I needed a convenient way to measure execution time with a high degree of precision. The standard GetTickCount is much too crude. For this purpose, Microsoft has implemented high performance counters which count CPU ticks.
My stopwatch class is simple:
class CStopWatch
{
LARGE_INTEGER m_StartTime;
LARGE_INTEGER m_Frequency;
public:
void Start();
LONGLONG ElapsedMilliSec();
LONGLONG ElapsedMicroSec();
};
The functionality is really basic. After the stopwatch is started, we can request the number of milliseconds or microseconds since the start. The internal variables are the start time and the tick frequency which we only have to read once.
void CStopWatch::Start()
{
QueryPerformanceFrequency(&m_Frequency);
QueryPerformanceCounter(&m_StartTime);
}
LONGLONG CStopWatch::ElapsedMilliSec()
{
LARGE_INTEGER endingTime;
LARGE_INTEGER elapsedMilliseconds;
QueryPerformanceCounter(&endingTime);
elapsedMilliseconds.QuadPart = endingTime.QuadPart - m_StartTime.QuadPart;
elapsedMilliseconds.QuadPart *= 1000;
elapsedMilliseconds.QuadPart /= m_Frequency.QuadPart;
return elapsedMilliseconds.QuadPart;
}
LONGLONG CStopWatch::ElapsedMicroSec()
{
LARGE_INTEGER endingTime;
LARGE_INTEGER elapsedMicroseconds;
QueryPerformanceCounter(&endingTime);
elapsedMicroseconds.QuadPart = endingTime.QuadPart - m_StartTime.QuadPart;
elapsedMicroseconds.QuadPart *= 1000000;
elapsedMicroseconds.QuadPart /= m_Frequency.QuadPart;
return elapsedMicroseconds.QuadPart;
}
Most of the heavy lifting here is done by QueryPerformanceFrequency which gets the tick frequency and QueryPerformanceCounter which gets the number of ticks. Because we are doing integer arithmetic, the number of ticks is multiplied first before being divided by the frequency to improve precision.
Using this stopwatch, we can measure time like this:
vector<CGroupIdentity> groups;
CStopWatch stopwatch;
stopwatch.Start();
w32_GetTokenGroups(GetCurrentThreadEffectiveToken(), groups, false);
wcout << dec <<groups.size() << L" Groups for the current thread in " <<
dec << stopwatch.ElapsedMilliSec() << L" milliseconds" << endl;
for (auto group : groups) {
wcout << group.Name << L" " << group.Sid << endl;
}
Points of Interest
I measured execution times when connected directly to the network, and while connected via VPN. Obviously, the times measured via VPN are susceptible to external variation.
Directly on the network, this is the result of parallelization.
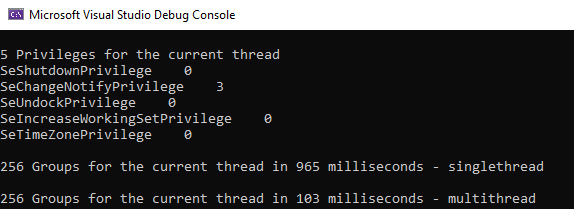
There are no artificial delays involved, and there are 12 CPU cores in my laptop so a 10x speed improvement is about as much as can be hoped for. Having learned multithreaded programming in a time when having 2 cores in a system was 'l33t' and required 2 physical CPU's and an expensive motherboard, I find it awesome that with minimal refactoring, we can get this sort of improvement.
Connected via VPN otoh, the results are a tad less impressive.

The speedup is 'only' 5 times. I repeated this test several times, and between 4 and 5 times quicker is about what every test achieves. I do not know the details of how our VPN architecture is implemented, but I suspect there is some throttling going on to make sure that a client cannot swamp the VPN connection points. Whatever the case may be, a 5 times improvement is still nothing to sneeze at. And more importantly, 600 ms is within an acceptable range for a 1-off in a user interface update.
History
- 7th September, 2022: First version

