Service Virtualization is a great way to provide mock endpoints of data that can be used in various API developments. This is the first part of a series in which we are going to write, from scratch, a cloud based application, in C#, that combines minimal APIs, Infrastructure as Code with Terraform, and AWS features including DynamoDB. Over the period of writing the series, we are going to cover all aspects of pulling a complex application together.
Introduction
This is the start of an unusual series for me. It's a bit of a labour of love, and is the culmination of almost three years thought, watching teams struggle to manage so-called unhappy path testing, and the desire to create a service that you can easily integrate into your application space.
Having spent years developing with APIs, I have been frustrated by teams that only really test the 2xx series of results from calls. Imagine if your application relied on the Google Maps API, for instance. Would your application behave gracefully if the Maps API was offline? What about if the user you were authenticating with no longer has access? Can you cope?
To answer questions like this, I have used Service Virtualization applications that allow me to mock up results and return them based on the data I input.
The series here goes through the various stages of creating this capability. There are certain assumptions and practices that I will be following and I'll be detailing the core concepts shortly. As the series progresses, and we refine the application further, I will add to these practices.
Source Code
- The source for this article can be found on GitHub
Very High Level Architecture
When we create and deploy our service, I am assuming the following features:
- Our service will make use of AWS (Amazon Web Services) features. We could use Azure but I have chosen to go with AWS.
- We will be deploying one service to manage the service virtualization (we'll refer to this as SV from now on).
- We will only be virtualizing HTTP/HTTPS.
- Our SV capability will be controlled via APIs.
- We will be able to host multiple users/organizations in our SV.
- We will control the storage of the request/response items using
DynamoDB. - To lower the cost of development, all development will be done with LocalStack (the free tier is fully functional).
- Our cloud infrastructure will be defined using a technique known as Infrastructure as Code (IaC). In other words, we will script as many areas of our AWS deployment as possible.
- We will use Blazor for our front end application. We could use any clientside technology but, for the purposes of this development, we are going to use a Web Assembly (WASM) framework.
- We will install LocalStack using Docker.
- We will incrementally build up our SV capability so we will be throwing code away. That's okay and is a perfectly normal thing to do.
- We aren't going to be blanketing the code in unit tests. I want to go through the process of building and deploying SV into a cloud environment and not get people lost in the details of the various tests.
- We aren't going to worry about performance initially. If we need to speed things up, we'll profile it and do it later on.
- We won't spend too much time worrying how AWS does things. Over this series, we will build up our knowledge.
- All API calls to our services will follow a convention of being created under /api.
- I will be creating the lowest possible number of interfaces that I can. I will register concrete types. To make types testable, we can mark methods as
virtual.
What Problem does SV Address?
Service virtualization is a technique we use to simulate the behaviour of components or services that a software application relies on but might not be available or accessible during development or testing. It's a way to create controlled and realistic test environments even when certain dependencies are unavailable or difficult to replicate. As a technique, this allows large teams to decompose deliveries in a simple, controlled manner; the benefit of this is that a team can define a RESTful contract and develop against it, but the team that will actually develop the implementation does not have to provide it at that point.
In software systems (especially large scale ones), different components or services interact with each other to perform various functions. During development and testing, these components might not all be ready or easily accessible. This is where SV comes into play, by allowing developers and testers to simulate the behaviour of these components. These virtual representations mimic the actual behaviour of the real components, along with so-called unhappy paths, even though the real components might not be fully implemented or operational yet.
SV typically works like this:
-
Simulation: SV tools create virtual instances of the services or components that our application interacts with. These instances imitate the behavior and responses of the real services.
-
Simulation: We can configure these virtual instances to respond to various inputs and scenarios, simulating both normal and exceptional conditions. This helps in testing different scenarios without relying on the actual services.
-
Testing: As developers and testers, we use these virtual instances to conduct comprehensive testing of software. We are able to test different integration points, functional interactions, and error handling.
-
Isolation: Virtualizing services helps us to isolate the testing process from the dependencies that might be unavailable or unstable meaning that the development and testing process can proceed smoothly even if the actual services are undergoing changes or maintenance.
-
Efficiency: SV reduces the need to have all components fully developed and available before testing can begin. This speeds up the testing process and allows for more comprehensive testing even when some components are still in development. This is a great way to create regression sweets that can be exercised in a repeatable, controlled manner.
SV is particularly useful in scenarios where components or services are distributed, or where they come from a third-party, and my favourite, where they are still under development.
Installing LocalStack
As I mentioned at the start, we want to use LocalStack as a proxy for AWS (and what a mighty fine proxy it is). To install LocalStack, we are going to use the following docker compose file (save the file as docker-compose.yml).
version: "3.8"
services:
localstack:
container_name: "goldlight-localstack"
image: localstack/localstack
ports:
- "127.0.0.1:4566:4566"
- "127.0.0.1:4510-4559:4510-4559"
environment:
- DEBUG=${DEBUG-}
- DOCKER_HOST=unix:///var/run/docker.sock
- PERSISTENCE=1
volumes:
- "${LOCALSTACK_VOLUME_DIR:-./volume}:/var/lib/localstack"
- "/var/run/docker.sock:/var/run/docker.sock"
When you have created this file (and assuming that you have installed docker previously - if not, download Docker Desktop and install it); once the file has been created, run the following command:
docker compose up
This downloads the localstack image and starts it locally.
Download and install the AWS Command Line Interface (AWS CLI). As I am developing this on a Windows laptop, I used chocolatey to install it using the command:
choco install awscli
Once that was installed, I use a wrapper for the AWS CLI called awslocal. The reason that I use this is to make my life a little simpler because this removes the need for me to type the endpoint for my locally deployed AWS instance in when I want to use the CLI. Follow the GITHUB instructions to install the package locally and test that everything is working with the following command:
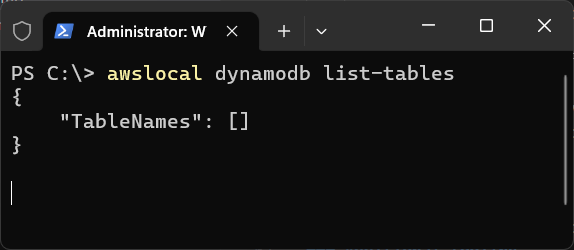
awslocal dynamodb list-tables
What this command does is return us a list of any tables you have created. As we haven't actually done anything in AWS that would result in us having tables, we should get the following response.
Infrastructure as Code
Now, just as I was getting ready to write this article, something happened that changed what I was going to write. I originally wrote my IaC scripts using a tool called Terraform which enabled me to script up what an environment looked like. Just as I sat down to start writing this series, HashiCorp (the company behind Terraform) changed the OSS license model.
I went backwards and forwards about whether or not I was going to look at a different capability because there was a lot of noise around the licensing model change of the OSS part of TerraForm but I have decided to stick with my original implementation; TerraForm is still free to use for personal work, so download and extract the binary from here.
Relevant licensing details can be found here [https://developer.hashicorp.com/terraform/cloud-docs/overview]. The relevant section is this:
Small teams can use most of Terraform Cloud's features for free, including remote Terraform execution, VCS integration, the private module registry, and more.
Free organizations are limited to five active members.
Note: For non Windows developers, please consult the relevant guides under the different products to get details of how to install on your system.
Configuring AWS CLI
Now that AWS CLI has been installed, we really need to configure it. I'm going to add three environment variables to help me remember what I'm going to set up.
AWS_ACCESS_KEY_ID='goldlight'
AWS_SECRET_ACCESS_KEY='goldlight'
AWS_DEFAULT_REGION='eu-west-2'
With these variables set up, it's time for me to configure AWS. Run the following command and enter the above values against the appropriate prompts.
aws configure
Adding the First Table
So far, we have done the following:
- Installed LocalStack as a Docker service
- Installed appropriate tooling (awslocal, terraform)
- Learned how to list tables
- Configured the AWS CLI
With all that in place, we are now ready to create a DynamoDB table. If you have never heard of DynamoDB before, it's the NoSQL offering from Amazon, and it's what we are going to use to manage our data.
The approach that we are going to use to create the table follows the idea that we will use IaC to control what we build. The core concept is that we describe what we want creating, and use Terraform to actually create it. This is an attractive proposition because it means that we have a much simpler route to transitioning the code from localstack to AWS if, and when, we want to.
For our purposes, Terraform effectively consists of two parts:
- The Terraform application (we installed it earlier)
- Our Terraform files (they have a .tf extension)
For the moment, we aren't going to worry too much about Terraform best practices at first. We will get back to this as we start layering our architecture.
Let's start by creating a Terraform file called main.tf. This is going to contain everything we need to build the structure of our table. It's important to note that Terraform creates a number of files while it's building your infrastructure, so it's a good idea to keep your .tf files in a separate folder to the rest of your application. This will make your life a lot easier in the long run.
Our Terraform file is broken down into two parts. The first part tells us what provider we are going to be using (AWS). The second part tells us how to build the DynamoDB table.
First, we will add the provider part.
provider "aws" {
region = "eu-west-2"
access_key = "goldlight"
secret_key = "goldlight"
skip_credentials_validation = true
skip_metadata_api_check = true
skip_requesting_account_id = true
endpoints {
dynamodb = "http://localhost:4566"
}
}
AWS services can be hosted in a number of regions (basically, think of this as being close to the countries the datacentres are located in). As I live in the UK, I'm using EU-WEST-2 as my region. The region is extremely important for a number of reasons; you may have data sovereignty issues for instance, where you can only host certain information in certain countries. Other reasons to need to choose your region carefully include the fact that not all features are available in every region. Please consult the AWS documentation about a feature to get a good understanding of where you can host it (for DynamoDB, you can find the list here).
The secret_key and access_key should contain familiar values. For the moment, we are just replicating the values here. Later on, we will remove the hardcoded values and replace them with environment values we set above.
The skip_... entries instruct Terraform to bypass Identity and Access Management (IAM) checks, AWS metadata API checks, and user credentials. Again, these options will start to make sense as we build out our AWS capability. I wouldn't worry too much about them just yet; just wait for us to build out our feature sets when we will start to add in things like user management.
Finally, we set the endpoint for DynamoDB so that Terraform knows what address to use to create the table. Obviously, the value here relates to our LocalStack entry.
Now that we have set up our AWS provider, we need to describe our DynamoDB table. As this is a NoSQL database, we don't have to detail every field that will appear; we are only going to describe what we need in terms of the primary key (the hash key), and what our read and write capacity is.
resource "aws_dynamodb_table" "organizations" {
name = "organizations"
read_capacity = 20
write_capacity = 20
hash_key = "id"
attribute {
name = "id"
type = "S"
}
}
The first line tells us that we are going to create a DynamoDB table, and gives us a key called organizations. This is not the name of the table, Terraform allows us to use the key in other resources so we add it here.
The name of our table is organizations, and that is what will be created when we run our Terraform builds.
When we create our DynamoDB table, the read_capacity parameter specifies the initial number of read capacity units (RCU) to be allocated to the table. DynamoDB uses something called provisioned capacity mode, where we specify the amount of read and write capacity units that we expect our application to require.
In DynamoDB, a single RCU represents one strongly consistent read per second, or two eventually consistent reads per second, for an item up to 4 KB in size. If we need to read larger items, we consume more read capacity units.
Strongly consistent reads and eventually consistent reads refers to the way that we manage storing data in DynamoDB. If we have a strongly consistent read, we are saying that we will always be returning the latest data but this has trade-offs around waiting for data to be written to the data store. Eventually consistent reads offer us better performance but the trade off here is that we aren't guaranteeing that we will be reading the latest records because they may not have replicated across regions. Fundamentally, these relate to data that's being replicated; if we read and write from a single node database, then we should be able to get a consistent view. If we replicate across many data instances, there is a period after each write where data is being propagated across the various data sources. This means that there is a possibility that we may not be reading from a source that has been updated yet.
Following this, we can see that the write version of our capacity is managed through our write_capacity, which specifies the write capacity units (WCU) for our table.
Again, don't worry too much about these values at this stage. We haven't decided on any throughput or volumetrics at this stage. We can come back and tweak this value later on.
The hash_key can be thought of as the equivalent of the primary key. We are going to call this field id and describe it in our attribute section. The datatype of our hash is a string; we will use a UUID as our value but DynamoDB doesn't support this as a native type, so we will store the string representation of it.
At this point, our Terraform file looks like the following:
provider "aws" {
region = "eu-west-2"
access_key = "goldlight"
secret_key = "goldlight"
skip_credentials_validation = true
skip_metadata_api_check = true
skip_requesting_account_id = true
endpoints {
dynamodb = "http://localhost:4566"
}
}
resource "aws_dynamodb_table" "organizations" {
name = "organizations"
read_capacity = 20
write_capacity = 20
hash_key = "id"
attribute {
name = "id"
type = "S"
}
}
Now that we have our file created, we need to run it. To do this, we will use the terraform command, which we installed earlier. As TerraForm just extracts the necessary files, I added the location of terraform.exe to my PATH. If I forgot to do this, I would have to use the fully qualified path to the executable.
There are, effectively, three stages to applying our script (run the commands in a console or shell window and change your current working directory to the folder that contains the main.tf file).
- Run
terraform init. This prepares the current working directory to accept the Terraform commands. - Run
terraform plan --out terraform.tfplan. This shows what changes will be required by the terraform execution, and saves this to a file called terraform.tfplan. - Run
terraform apply terraform.tfplan. This creates or updates our infrastructure. It is possible to miss out step 2, and just run steps 1 and 3, but that would need you to remove the terraform.tfplan portion of the command.
That's it, run these commands and our DynamoDB table will be created. Once the commands have completed, we can verify that our table has been created using the awslocal command.
awslocal dynamodb list-tables
The output should now look like this:
{
"TableNames": [
"organizations"
]
}
Let's Write Some Code
Well, we have a table now. Granted it's got nothing in it but it's ready for us to start writing some code. We're going to take a little bit of a diversion from AWS right now and we're going to build a service that returns a single response no matter what we send it. This is going to be the start of us building our SV server and it's the point that our front end would interact with to update DynamoDB.
For the moment, we are going to assume that any request is going to get an HTTP 200 OK result. Let's start by creating an ASP.NET Core Web API (I'm using .NET Core 7) and calling it Goldlight.VirtualServer.
The following image shows the settings we are using.

Visual Studio will create the basic structure that we need. As we are using minimal APIs, our program file looks like this:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseHttpsRedirection();
var summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm",
"Balmy", "Hot", "Sweltering", "Scorching"
};
app.MapGet("/weatherforecast", () =>
{
var forecast = Enumerable.Range(1, 5).Select(index =>
new WeatherForecast
(
DateOnly.FromDateTime(DateTime.Now.AddDays(index)),
Random.Shared.Next(-20, 55),
summaries[Random.Shared.Next(summaries.Length)]
))
.ToArray();
return forecast;
})
.WithName("GetWeatherForecast")
.WithOpenApi();
app.Run();
internal record WeatherForecast(DateOnly Date, int TemperatureC, string? Summary)
{
public int TemperatureF => 32 + (int)(TemperatureC / 0.5556);
}
There's a lot of boilerplate in there, but what is important is that we have sufficient code in there to add what we need to support the code that we are going to add to return the 200 response.
In order to return a response, no matter what the request is, we need to use something called middleware. With our middleware, we want to intercept the incoming request and create a version of the response that we want. Adding our own middleware is a useful way to insert our own behaviour into the request pipeline and we are going to use this ability to return a custom response.
The first thing we are going to do is create a simple helper method that we will build on, at various stages, throughout our development.
static async Task WriteResponse<T>(HttpContext context, T result,
int statusCode = 200, string contentType = "application/json")
{
HttpResponse response = context.Response;
response.StatusCode = statusCode;
response.ContentType = contentType;
await response.WriteAsync(JsonSerializer.Serialize(result));
}
This code sets our status code, and the content type we want; as we default to status 200 and application/json, we only have to supply the context and something to return as our result. All we need to do now is hook this up inside our program file.
Just before the app.Run(); call, add the following code:
app.Run(async context => { await WriteResponse(context,"Hello ServiceVirtualization"); });
Note - we need both versions of app.Run so don't delete the other one.
This asynchronous method waits for a request to come in with a web context and uses that to write the response to. If we run the service now, we can test that we successfully get the message back.
Our network traffic looks like the following:
Congratulations, we have just created SV. Granted, it's not very useful right now. Let's start to flesh this out with the ability to have different servers for different companies.
SV Design Goal
While we haven't added user or organisation management capabilities to our application, we are going to assume that we will allow companies or individuals to use SV. In both cases, we are going to manage all SV at a group level, so a company is a group and a single individual is a group of one. Why are we doing this? We're going to do this so that our users only have access to their own SV, and this is going to form part of the request path.
What we are envisaging here is that, rather than SV returning a response when we call http://localhost:5106/myvirtualizedservice, the path would look more like this http://localhost:5106/deployed/acmecorp/myvirtualizedservice.
Instead of hardcoding this, we're going to start by adding the ability to store data in DynamoDB and use this to start populating company details. It's time to write some AWS code.
Before we start, we need to decide just what we want to store for our organization. We know that we want a hash key that's a UUID, and we want it to be a string representation but what else do we want? Well, we want a name as well, so we will make that a required data item with a minimum length of one so that we will always have a value in here. As the data is going to be stored as a JSON entity, any additional attributes should be easily catered for.
Prior to populating our database, we want to create an API and data model that will be used from web clients. With that in mind, we are going to use this contract (I have put this into a folder called /models/v1).
[DataContract]
public class Organization
{
[DataMember(Name="id")]
public Guid? Id { get; set; }
[DataMember(Name="name")]
public string? Name { get; set; }
}
We are going to add a minimal POST API that maps to the endpoint /api/organization. For the moment, we aren't going to worry about API versioning, we will add that later.
We don't want to leave the code cluttered with the example Weather API, so we're going to remove all traces of it from the codebase. Once that's done, we add the following method:
app.MapPost("/api/organization", ([FromBody]Organization organization) =>
{
System.Diagnostics.Debug.WriteLine($"Received organization:
{JsonSerializer.Serialize(organization)}");
return TypedResults.Created($"/api/organizations/{organization.Id}", organization);
})
All we are going to do, for the moment, is print out details of the organization, and return a 201 (Created) response. At this stage, I really want to stress that we should really think about the statuses that we return so that they don't give people a surprise. I have seen so many APIs where a 200 OK response is returned to cover so many cases. When we successfully create something inside our service, we should always return a 201 status.
A small side note: It's possible, if you've seen minimal APIs before, that you might have seen people returning Result instead of TypedResult. If you have, you might be wondering what the difference is. When we return TypedResult, along with the returned object, we also return metadata about it which can be used in the Swagger file to identify the different statuses and objects we return from the method. If we return a Result, and we want to document the return types, we have to use a Produces extension on our call to say what we are returning.
If we were to run our application right now, and attempt to post an organization, we will see something that, at first glance, is surprising. When we run our application, the middleware we created in the app.Run call is intercepting all traffic and our API isn't getting called so we want to change the behaviour.
To work around the middleware problem, we are going to change our behaviour so that we check to see whether or not our path starts with /api/. If it does, we want to continue processing. To do this, we are going to change our middleware to use app.Use instead of app.Run. With this, we get access to both the current context (which allows us to check the path), and a reference to the next part of the request pipeline. When we invoke the next stage, we make sure that we return so that we don't fall through to our WriteResponse code.
app.Use(async (context, next) =>
{
if (context.Request.Path.Value!.StartsWith("/api/"))
{
await next.Invoke();
return;
}
await WriteResponse(context, "Hello ServiceVirtualization");
});
At this point, our code now looks like the following:
using System.Text.Json;
using Goldlight.VirtualServer.Models.v1;
using Microsoft.AspNetCore.Http.HttpResults;
using Microsoft.AspNetCore.Mvc;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseHttpsRedirection();
app.MapPost("/api/organization", ([FromBody] Organization organization) =>
{
System.Diagnostics.Debug.WriteLine($"Received organization:
{JsonSerializer.Serialize(organization)}");
return TypedResults.Created($"/api/organizations/{organization.Id}", organization);
});
app.Use(async (context, next) =>
{
if (context.Request.Path.Value!.StartsWith("/api/"))
{
await next.Invoke();
return;
}
await WriteResponse(context, "Hello ServiceVirtualization");
});
app.Run();
static async Task WriteResponse<T>(HttpContext context,
T result, int statusCode = 200, string contentType = "application/json")
{
HttpResponse response = context.Response;
response.StatusCode = statusCode;
response.ContentType = contentType;
await response.WriteAsync(JsonSerializer.Serialize(result));
}
It's incredible how quickly minimal APIs let us reach the point of having a working API.
Setting Our Project Up to Work With Localstack
We have a small number of packages that we need to install up front. We're going to add LocalStack.Client and LocalStack.Client.Extensions Nuget packages. Once these are in place, we want to add the following entries to our program file.
builder.Services.AddLocalStack(builder.Configuration);
builder.Services.AddDefaultAWSOptions(builder.Configuration.GetAWSOptions());
In our app settings file, we need to add the following entry:
"LocalStack": {
"UseLocalStack": true,
"Session": {
"AwsAccessKeyId": "goldlight",
"AwsAccessKey": "goldlight",
"AwsSessionToken": "my-AwsSessionToken",
"RegionName": "eu-west-2"
},
"Config": {
"LocalStackHost": "localhost",
"UseSsl": false,
"UseLegacyPorts": false,
"EdgePort": 4566
}
}
It's fair to say that we wouldn't want to do this in a production system; we certainly wouldn't want to hardcode values in this way, but as a development environment and while we're working locally, this is okay. The reality is that we would want to read some of this configuration using a more secured approach but, for the moment, this is good enough for us.
The configuration will be picked up and used by the options above. The LocalStackHost and EdgePort will provide the details our service needs around where the LocalStack is running, and where our DynamoDB instance will be.
Saving the Data
Now that we have an organization coming in, and the AWS registrations performed in our application, we are ready to write some code to save the data to DynamoDB. We are going to isolate our database code into its own library, so let's create a .NET Core Class Library called Goldlight.Database (again targeting .NET 7).
Inside this library, we want to install the AWSSDK.DynamoDBv2 and LocalStack.Client.Extensions NuGet packages. These are going to provide us with access to both the DynamoDB and the LocalStack features we will be using inside our application. When the installation finishes, we are going to create a representation of the model we are going to push into the database. Our model class looks like the following:
[DynamoDBTable("organizations")]
public class OrganizationTable
{
[DynamoDBHashKey("id")]
public string? Id { get; set; }
[DynamoDBProperty]
public string? Name { get; set; }
[DynamoDBProperty]
public int ModelVersion { get; set; } = 1;
[DynamoDBVersion]
public long? Version { get; set; };
}
What we are creating here is a representation of the data that we want to put into our table structure. At the top level, we want the id that matches the hash key we created in our Terraform. We are writing to the named DynamoDBTable called organizations, and this shouldn't come as a surprise. This will tie back to the id from our API, but we can see that the type here is a string. As we mentioned before, DynamoDB is limited in the types that it supports so we can't use a GUID directly.
We create two properties, the Name and the ModelVersion. The name is the name of the organization that we will pass in from the API, while the model version is the version of the model that we used to populate this entry. What we are doing with this is introducing, at an early stage, a little bit of future proofing. If, over time, we introduce a breaking change to the model in the API, we can use the version to work out which particular model it should populate at the API.
For the moment, we aren't going to worry about the Version property. We will see what the purpose of it is when we come to updating the record.
Once the table object has been created, we are ready to write the code that saves the actual data to DynamoDB. We are going to create a class called OrganizationDataAccess. This is going to hold the logic that we will use to save the data to the database. The code is pretty straightforward, and relies on us having access to the DynamoDB data model capability.
Create the following class:
public class OrganizationDataAccess
{
private readonly IDynamoDBContext _dynamoDbContext;
public OrganizationDataAccess(IDynamoDBContext dbContext)
{
_dynamoDbContext = dbContext;
}
public virtual async Task SaveOrganizationAsync(OrganizationTable organization)
{
await _dynamoDbContext.SaveAsync(organization);
}
}
The IDynamoDBContext interface provides us with access to the features that we need to save the data (and load later on). With this, our SaveOrganizationAsync method simply calls the DynamoDB SaveAsync implementation. As we have created a mapped model, the code knows which table to save the record to, and what to save into it. I find this to be an incredibly straightforward way to manipulate the data and we will be exploiting that capability later on.
We need to register this class. I have chosen to manage the registration of all data related activities inside this class library. So we are going to create an extension method that accepts the IServiceCollection interface and adds the relevant details.
public static class DataRegistration
{
public static IServiceCollection AddData(this IServiceCollection services)
{
return services.AddTransient<OrganizationDataAccess>().AddAwsService<IAmazonDynamoDB>()
.AddTransient<IDynamoDBContext, DynamoDBContext>();
}
}
We are adding three things here.
- A transient registration of our data access class. We can see that we haven't wrapped an interface around this; if we create an interface, there's an implication that we should be creating other implementations of that type and, for the moment, we aren't doing that.
- When we call
AddAwsService, we are actually hooking into LocalStack here. This is a LocalStack extension that basically says "when you attempt to do something with the IAmazonDynamoDB service, and the configuration says to use LocalStack, LocalStack will handle it". If we don't put this call in, our code thinks it's attempting to connect to AWS and we will fail with Region endpoint failures. This caught me out a couple of times in the past so I'm calling it out as important here. - Finally, we are adding the
IDynamoDBContext registration as transient so that we get a new instance every time we connect to DynamoDB.
The reason we have added the DynamoDB registrations inside this class is so I have a single location for everything data related. When I add other features, I'll follow a similar approach there.
Back to the Main Service
With the registration code in place, we need to add it in our program.cs code. After the AddDefaultAWSOptions line, add the following to call the data registration.
builder.Services.AddData();
We're almost done now. Our final step is to update our POST call to call the new save routine. As we are going to be using the OrganizationDataAccess class we just created, we need to inject that into our MapPost call. This is asynchronous so we mustn't forget to mark this as an async method.
Inside the post code, we are going to create an instance of the OrganizationTable class and map the values in from the request. Once that's populated, we call our SaveOrganizationAsync code and we are good to go.
app.MapPost("/api/organization",
async (OrganizationDataAccess oda, [FromBody] Organization organization) =>
{
OrganizationTable organizationTable = new()
{
Id = organization.Id.ToString(),
Name = organization.Name,
ModelVersion = 1
};
await oda.SaveOrganizationAsync(organizationTable);
return TypedResults.Created($"/api/organizations/{organization.Id}", organization);
});
This is what our code looks like now:
using System.Text.Json;
using Goldlight.Database;
using Goldlight.Database.DatabaseOperations;
using Goldlight.Database.Models.v1;
using Goldlight.VirtualServer.Models.v1;
using LocalStack.Client.Extensions;
using Microsoft.AspNetCore.Mvc;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
builder.Services.AddLocalStack(builder.Configuration);
builder.Services.AddDefaultAWSOptions(builder.Configuration.GetAWSOptions());
builder.Services.AddData();
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseHttpsRedirection();
app.MapPost("/api/organization",
async (OrganizationDataAccess oda, [FromBody] Organization organization) =>
{
OrganizationTable organizationTable = new()
{
Id = organization.Id.ToString(),
Name = organization.Name,
ModelVersion = 1
};
await oda.SaveOrganizationAsync(organizationTable);
return TypedResults.Created($"/api/organizations/{organization.Id}", organization);
});
app.Use(async (context, next) =>
{
if (context.Request.Path.Value!.StartsWith("/api/"))
{
await next.Invoke();
return;
}
await WriteResponse(context, "Hello ServiceVirtualization");
});
app.Run();
static async Task WriteResponse<T>(HttpContext context, T result,
int statusCode = 200, string contentType = "application/json")
{
HttpResponse response = context.Response;
response.StatusCode = statusCode;
response.ContentType = contentType;
await response.WriteAsync(JsonSerializer.Serialize(result));
}
Where Are We Now?
Let's pause and take a checkpoint of what we have achieved so far.
- We have installed a local copy of something that, for all intents and purposes, looks and behaves like the cloud instance of AWS. This means it won't be too hard to migrate our services to AWS when we want to.
- We have used Terraform to create a table instance in
DynamoDB. - We created an application that returns a virtualized response.
- We have an application that saves details about an organization into
DynamoDB.
I hope you'll agree that this is pretty impressive and hasn't actually taken us that much to achieve. Now that we have created an organization, we are going to start to flesh out the behaviour by adding the ability to fetch, update, and delete the organization. Once we have that, we are ready to create a front end that services it.
Designing for a Changing Architecture
Before we move on, I want us to address something that's annoying me here, namely the fact that we have a very fragile approach to the design of our APIs that we are building in from the start, namely the ability to handle breaking changes in our APIs. To address this, we are going to add versioning to our APIs. To avoid introducing too much in the last few sections, we just created a simple non-versioned API, but that's a bad practice to get into when we are working with applications that have the potential to grow.
As we are building this application with "an agile" mindset, we are continually building something called a Minimum Viable Product. In other words, we have an expectation that our application will have more and more functionality added to it continuously, and we will polish it more and more. This is why we don't have any validation in our API just yet; and how we were able to rapidly go from using middleware to return a hardcoded response no matter what we sent to our API to being able to cope with saving data to the database but still having the middleware respond if we hit endpoints that don't start with /api/. With this mindset, it's important for us to understand the implications of what we are doing. We are designing for change right from the start. We accept that things will change over time, and we accept that changing things will break things we have done before.
The reason we want to introduce versioning at this point is we accept that the rate of change means that our APIs will change, and this could end up breaking things. It's why we put the version number in the entity we saved in the database. The "language" we're transmitting and saving data in is JSON (for the moment; who knows, we might change the transmission to a different format later). But if our API uses JSON, we have to understand that the JSON could have breaking changes with it. Consider the following JSON:
{
"id": "ea080555-57bd-4d8f-9c18-53c7395a743f",
"addressline1": "31 Front Street",
"addressline2": "Pant-y-gyrdl",
"addressline3": "Somewhereinwalesshire",
"postcode": "PS1P4T"
}
Over time, our requirements change and we realise our customers may no longer have one address, they could be hotel chains with hundreds of addresses. To cater for this, we decide that our addresses should be in an array. All of a sudden, the same customer is now represented by this version of the JSON instead.
{
"id": "ea080555-57bd-4d8f-9c18-53c7395a743f",
[
{
"type": "home",
"addressline1": "31 Front Street",
"addressline2": "Pant-y-gyrdl",
"addressline3": "Somewhereinwalesshire",
"postcode": "PS1P4T"
}
]
}
As we can clearly see here, this is a breaking change and there's no way a simple API could handle both cases without some major compromises. To avoid this situation, we use API versioning. In other words, the first format will be handled by v1 and the breaking change will be handled by the v2 API.
There are many ways we can handle versioning. We could add it as a query-string parameter, we could add it to the path, or we could add it in some way to the header, or we could use a custom media type for our versioning. Whichever format we choose, we will be applying this approach to every API.
Anyway, back to adding versioning support. We're going to start by installing the Asp.Versioning.Http package into our API library.
The versioning approach we are going to use is to use the media type. In other words, our Content-Type header will need to be set to application/json;v=1.0. To add support for this in, we are going to add API versioning to our services like this:
ApiVersion version1 = new(1, 0);
builder.Services.AddApiVersioning(options =>
{
options.ReportApiVersions = true;
options.DefaultApiVersion = version1;
options.ApiVersionReader = new MediaTypeApiVersionReader();
});
What we have done here is created our default API version as version 1.0, and set up the API version capability to use the Media type. When we set ReportApiVersions to true, we add information to the HTTP headers telling them the api-supported-versions and api-deprecated-versions.
We still have some things to do to finish adding the versioning support. We are going to create an ApiVersionSet to represent a grouping of our APIs. We have to add this call to our app like this.
ApiVersionSet organizations = app.NewApiVersionSet("Organizations").Build();
Finally, we need to actually add the version information to our API. We add the version set to the API and then say what the version is for the API using the WithApiVersionSet and HasApiVersion methods.
app.MapPost("/api/organization", async (OrganizationDataAccess oda,
[FromBody] Organization organization) =>
{
OrganizationTable organizationTable = new()
{
Id = organization.Id.ToString(),
Name = organization.Name,
ModelVersion = 1
};
await oda.SaveOrganizationAsync(organizationTable);
return TypedResults.Created($"/api/organizations/{organization.Id}", organization);
}).WithApiVersionSet(organizations).HasApiVersion(version1);
Reading from DynamoDB
It's all very well for us that we can write to DynamoDB. Without the ability to read from it, it seems rather pointless. To that end, we are going to add an API that will (for the moment), retrieve the details of all organizations from DynamoDB. To achieve this, we need to create an endpoint for our API, and add the ability to read all rows from DynamoDB. The boilerplate for our API side looks like this:
app.MapGet("/api/organizations", async (OrganizationDataAccess oda) =>
{
}).WithApiVersionSet(organizations).HasApiVersion(version1);
Once we have this in place, we are ready to update our OrganizationDataAccess code. DynamoDB allows us to perform two distinct types of operations, a scan or a query. If we have search criteria that we need to apply (e.g., searching on the hash key), the query operations would provide us with more efficiency. As we don't have any criteria to query against for a get all type of call, we will scan the table using ScanAsync.
public virtual async Task<IEnumerable<OrganizationTable>> GetOrganizationsAsync()
{
return await _dynamoDbContext.ScanAsync<OrganizationTable>
(new List<ScanCondition>()).GetRemainingAsync();
}
The code looks a bit odd because we have a ScanAsync method and GetRemainingAsync to perform the read. The call to ScanAsync configures the scan operation that we are going to perform, and this is handed off to GetRemainingAsync which actually performs the scan.
Something that we want to remember. We are dealing with a cloud database here, and it is set up, by default, to be eventually consistent. This can cause real confusion for people used to a data being instantly written to the database. Eventually consistent databases accept that there may be a little bit of a delay in populating the database, with the benefit that this pattern suits scaling services and capabilities.
As the code stands, if we were simply to return the organization directly from the GetOrganizationsAsync call, we are returning an enumerable list of OrganizationTable. This is not what we want to return to the calling code so we need to convert this back to an Organization. To that end, we are going to write the API handler to both call the data access method, and then to shape the result back into what we would expect.
app.MapGet("/api/organizations", async (OrganizationDataAccess oda) =>
{
IEnumerable<OrganizationTable> allOrganizations = await oda.GetOrganizationsAsync();
return allOrganizations
.Select(organization => new Organization { Id = Guid.Parse(organization.Id!),
Name = organization.Name });
}).WithApiVersionSet(organizations).HasApiVersion(version1);
As that has taken care of fetching the full list of records, we also need to consider that we want to be able to get a single organization based on the id. We will start off with the data access code. For this operation, as we are getting a single row based on the hash key (the id), we can make use of the LoadAsync method, which accepts the hash key as the parameter. The code for this is simpler than for the full scan operation as we are only returning a single row.
public virtual async Task<OrganizationTable?> GetOrganizationAsync(Guid id)
{
return await _dynamoDbContext.LoadAsync<OrganizationTable>(id.ToString());
}
We return a nullable OrganizationTable because we may not find a matchind entry. If we don't get a match, we want our API call to return NotFound. As we remember, our API methods haven't explicitly returned a type yet. That's because the internals of the minimal API are able to work out that:
app.MapPost("/api/organization",
async (OrganizationDataAccess oda, [FromBody] Organization organization)
is equivalent to:
app.MapPost("/api/organization", async Task<Created<Organization>>
(OrganizationDataAccess oda, [FromBody] Organization organization)
Why am I mentioning this? Well, our new GET call is going to return either a 200 status with the organization information, or it's going to return a 404 not found status. With the more complex return types, we have to tell the code what we are going to be returning as part of the API signature like this.
app.MapGet("/api/organization/{id}",
async Task<Results<Ok<Organization>, NotFound>> (OrganizationDataAccess oda, Guid id)
The {id} in the call matches the Guid id in the parameter list.
Note: I am taking this opportunity to correct a mistake I made earlier. When we wrote the post method, we returned /api/organizations/id. There is an implication with that entry, that we will be searching for a collection of resources using the id. We don't want to do that, so we are going to correct it so that we use the singular rather than the plural, so we have /api/organization/id instead.
Inside the API method, we will call the GetOrganizationAsync method. If the id doesn't match any of our organizations, we will get a null back in which case we will return a NotFound. If we get a value back, we will convert it back to the organization and return an Ok.
app.MapGet("/api/organization/{id}", async Task<Results<Ok<Organization>, NotFound>>
(OrganizationDataAccess oda, Guid id) =>
{
OrganizationTable? organization = await oda.GetOrganizationAsync(id);
if (organization == null)
{
return TypedResults.NotFound();
}
return TypedResults.Ok(new Organization { Id = Guid.Parse(organization.Id!),
Name = organization.Name });
}).WithApiVersionSet(organizations).HasApiVersion(version1);
Don't forget, when we want to test our APIs, we need to set our Content-Type to application/json;v=1.0 in our request header, like this (I use Postman for my testing).
Updating an Organization
When we work with APIs, we generally have two methods that we use to update records. We can either use PUT or we can use PATCH. With a PUT updated, the idea is to replace one version of the record with another while a PATCH is aimed at updating individual parts of the record. We are going to replace the whole record so we are going to use a PUT API.
The minimal structure we need to put in place to add a PUT operation.
app.MapPut("/api/organization",
async (OrganizationDataAccess oda, Organization organization) =>
{
}).WithApiVersionSet(organizations).HasApiVersion(version1);
For this method, I have left out the [FromBody] on the Organization. The code is smart enough to work out that this is what we are passing in. We could have left it off the MapPost earlier on as well, but we initially left it there to demonstrate what was being posted in.
At this point, I want to address something that I deliberately left out of our discussion. When we created our OrganizationTable, we added the following mapping.
[DynamoDBVersion]
public long? Version { get; set; }
This value is automatically populated by the system when the record is being added. The value in it is really important because this is used for optimistic locking. In other words, when the record is created, it is created with a Version of 0. If I want to update the record, I pass in the Version which is used to compare the record against the entry inside DynamoDB. So, if two people retrieve the record and attempt to updated it, by the time the second update hits the system, the version will have incremented and DynamoDB will inform us that it was unable to update the record because we have a conflict.
What is missing from our code is the ability to cope with the optimistic locking. There's no problem with that because we are gradually building up our functionality, step by step, and this is in line with the principles we set out earlier. In order to cope with the version, we have to add it to our Organization model. While we are doing this, we are going to add a couple of helper methods; one to convert from an OrganizationTable to the Organization, and another method to do the opposite and convert from the Organization to the OrganizationTable. If I were following SOLID principles 100% here, I would create these helper methods externally to the contract but this solution keeps all of the behaviour in one easy to find location.
[DataContract]
public class Organization
{
[DataMember(Name="id")]
public Guid? Id { get; set; }
[DataMember(Name="name")]
public string? Name { get; set; }
[DataMember(Name="version")]
public long? Version { get; set; }
public static Organization FromTable(OrganizationTable table)
{
return new()
{
Id = Guid.Parse(table.Id!),
Name = table.Name,
Version = table.Version ?? 0
};
}
public OrganizationTable ToTable(int modelVersion = 1) {
return new()
{
Id = Id.ToString(),
Name = Name,
Version = Version,
ModelVersion = modelVersion
};
}
}
With this capability, we can now pass in the version that matches up with the one we retrieved from DynamoDB, and the PUT operation will call the existing save method to update the underlying record.
We'll do a quick refactor of our main code to use the helper methods, giving us the following.
app.MapPost("/api/organization",
async (OrganizationDataAccess oda, Organization organization) =>
{
await oda.SaveOrganizationAsync(organization.ToTable());
return TypedResults.Created($"/api/organization/{organization.Id}", organization);
}).WithApiVersionSet(organizations).HasApiVersion(version1);
app.MapGet("/api/organization/{id}",
async Task<Results<Ok<Organization>, NotFound>> (OrganizationDataAccess oda, Guid id) =>
{
OrganizationTable? organization = await oda.GetOrganizationAsync(id);
if (organization is null)
{
return TypedResults.NotFound();
}
return TypedResults.Ok(Organization.FromTable(organization));
}).WithApiVersionSet(organizations).HasApiVersion(version1);
app.MapGet("/api/organizations", async (OrganizationDataAccess oda) =>
{
IEnumerable<OrganizationTable> allOrganizations = await oda.GetOrganizationsAsync();
return allOrganizations
.Select(Organization.FromTable);
}).WithApiVersionSet(organizations).HasApiVersion(version1);
app.MapPut("/api/organization",
async (OrganizationDataAccess oda, Organization organization) =>
{
await oda.SaveOrganizationAsync(organization.ToTable());
return TypedResults.Ok();
}).WithApiVersionSet(organizations).HasApiVersion(version1);
Deleting Unwanted Records
As promised, the last operation we want to add is the ability to delete a record. As we have covered a lot of the groundwork already, it should come as no surprise that this is a simple operation inside the data access code.
public virtual async Task DeleteOrganizationAsync(Guid id)
{
await _dynamoDbContext.DeleteAsync<OrganizationTable>(id.ToString());
}
The API code should also look familiar by now.
app.MapDelete("/api/organization/{id}", async (OrganizationDataAccess oda, Guid id) =>
{
await oda.DeleteOrganizationAsync(id);
return TypedResults.Ok();
}).WithApiVersionSet(organizations).HasApiVersion(version1);
Where We Are
This has been a packed article. In this article, we have learned how to install LocalStack and the AWS CLI. We used Terraform to create our first DynamoDB table, and followed this up by creating a minimal API application that we used to add basic CRUD operations that allow us to manage organizations. We have applied versioning to our API and we have seen how we can use middleware to act as Service Virtualization.
With the basics in place, what do we need to do now? Remember that we are building out our functionality in an incremental fashion, it's worth thinking about how our users will use the application. We have created an organization and we know that we want our users to be able to reach their services at /deployed/organization so what does that imply? Suppose that we have an organization called Five Nights at Freddy's. There are so many reasons that we wouldn't want our users to have to use that in their path. We want a way to take that organization name and make it url friendly. We also want the users to be able to amend it if they need to, and it must be unique.
At the same time, I'm starting to think that I want the organization to have an access key that is only available to members of that organization. I want to do this because I want the ability to create public and private services so the access key will be used to restrict access to private services.
Why am I thinking about future requirements right now? When we build an application, we shouldn't just stumble from requirement to requirement without knowing what we are aiming for. In an Agile development team, I would be acting as the product owner here; the person who knows what they want the application to be and I know that I want the application to have public and private virtualized services. Again, if I were thinking about the priority of the stories, I might decide that now is the time to address them.
Note: This is not intended to be a debate about various Agile methodologies and whether they are worth it or not. This is just a way of conceptualizing why I am choosing to address these two requirements now.
Adding the Access Key
This one is the easy one. I want the service to create the access key on the POST and I want to return it in the GET calls; I also want to return it in the post call. The PUT call should not be allowed to change it, and it shouldn't appear in the contract for POST and PUT. Once it's created, it is immutable. The implication of this is that we actually need two separate contracts; the first is the one we currently have and we'll use this for the POST and PUT. The second contract will be returned from the POST, and will be the one we return from the GET call.
As we are going to be saving to DynamoDB, we will update the data access code first.
[DynamoDBTable("organizations")]
public class OrganizationTable
{
[DynamoDBHashKey("id")]
public string? Id { get; set; }
[DynamoDBProperty]
public string? Name { get; set; }
[DynamoDBProperty]
public int ModelVersion { get; set; } = 1;
[DynamoDBVersion]
public long? Version { get; set; }
[DynamoDBProperty]
public string? ApiKey { get; set; };
}
We are setting the key here using a simple algorithm; we want a new key and a Guid will give us that. We don't want it to look too much like a Guid, so we remove the - in the text.
To match our requirements above, we are going to create an OrganizationResponse table that will handle the response from our POST and GET calls. To work with the POST call, we allow the code to instantiate this class with the Organization information. From this, we can add our API Key.
[DataContract]
public class OrganizationResponse : Organization
{
public OrganizationResponse() { }
public OrganizationResponse(Organization organization)
{
Id = organization.Id;
Name = organization.Name;
Version = organization.Version;
}
[DataMember(Name="api-key")]
public string? ApiKey { get; set; }
public OrganizationResponse(OrganizationResponse organization)
{
Id = organization.Id;
Name = organization.Name;
Version = organization.Version;
ApiKey = organization.ApiKey;
}
public override OrganizationTable ToTable(int modelVersion = 1)
{
OrganizationTable table = base.ToTable(modelVersion);
table.ApiKey = ApiKey;
return table;
}
public static OrganizationResponse FromTable(OrganizationTable table)
{
return new()
{
Id = Guid.Parse(table.Id!),
Name = table.Name,
ApiKey = table.ApiKey,
Version = table.Version ?? 0
};
}
}
When we POST the record, we accept the Organization and use this to create the OrganizationResponse object we created above. This is the point at which we want to create our API Key. We will save this new OrganizationResponse to DynamoDB, setting the ApiKey inside the data record. I'm going to take this chance to fix a defect in my original implementation, where the response didn't reflect the version of the record in the database. We know that DynamoDB will automatically save the first version as 0, so we can hardcode our response here. The last thing here is to return the OrganizationResponse.
app.MapPost("/api/organization",
async (OrganizationDataAccess dataAccess, Organization organization) =>
{
OrganizationResponse organizationResponse = new(organization)
{
ApiKey = Guid.NewGuid().ToString().Replace("-", "")
};
await dataAccess.SaveOrganizationAsync(organizationResponse.ToTable());
organizationResponse.Version = 0;
return TypedResults.Created($"/api/organization/{organization.Id}",
organizationResponse);
}).WithApiVersionSet(organizations).HasApiVersion(version1);
We are in a position to change the get calls to return OrganizationResponse instances rather than Organization. This is relatively straightforward as it just involves changing any references of Organization into OrganizationResponse in the MapGet methods.
app.MapGet("/api/organization/{id}",
async Task<Results<Ok<OrganizationResponse>, NotFound>>
(OrganizationDataAccess oda, Guid id) =>
{
OrganizationTable? organization = await oda.GetOrganizationAsync(id);
if (organization is null)
{
return TypedResults.NotFound();
}
return TypedResults.Ok(OrganizationResponse.FromTable(organization));
}).WithApiVersionSet(organizations).HasApiVersion(version1);
app.MapGet("/api/organizations", async (OrganizationDataAccess oda) =>
{
IEnumerable<OrganizationTable> allOrganizations = await oda.GetOrganizationsAsync();
return allOrganizations
.Select(OrganizationResponse.FromTable);
}).WithApiVersionSet(organizations).HasApiVersion(version1);
We are now ready to think about one of our other requirements; namely that we should have the organization in the URL in our SV endpoints.
The Friendly Organization Name
When we create the organization, we want to create a "friendly" version of the organization name. The first thing we want to do is remove any whitespace from the organization name. We aren't going to remove or change non-whitespace characters as we want the name to be as locale-friendly as possible. We want to have an international audience, so we don't want to have to anglicize the name. We also want this friendly name to be unique. Let's address this last requirement first.
We already have something available to us that gives us the ability to have a unique name. We have the hash key, which cannot have collisions. This would seem to suggest that this is a pretty good candidate for a unique name. The only change we have to make to support this capability is to change the data type on the contract.
"But Pete, doesn't this mean we have to use a new version for the API?" Remember that we talked about breaking changes and API contracts earlier; strictly speaking, we should consider this to be a breaking change as this changes the data type from Guid to string. As we haven't released the contract to anyone just yet, I'm inclined for us to be able to apply a little bit of flexibility here and say that we don't have to introduce a new version just yet. We aren't going to have different teams connecting to our service and providing us with Guids or strings because they have old uses of our system, so we only need the one version. To make life a little bit easier on ourselves, we will leave the name of the entry id. We have four sets of changes to make.
First, we change the Organization contract and change the data type for the Id field. We're going to take the opportunity to remove the FromTable method which isn't being called anymore now that the get calls use the OrganizationResponse type.
[DataContract]
public class Organization
{
[DataMember(Name="id")]
public string? Id { get; set; }
[DataMember(Name="name")]
public string? Name { get; set; }
[DataMember(Name="version")]
public long? Version { get; set; }
public virtual OrganizationTable ToTable(int modelVersion = 1) {
return new OrganizationTable
{
Id = Id!,
Name = Name!,
Version = Version,
ModelVersion = modelVersion
};
}
}
Second, we change the OrganizationResponse contract.
[DataContract]
public class OrganizationResponse : Organization
{
public OrganizationResponse() { }
public OrganizationResponse(Organization organization)
{
Id = organization.Id;
Name = organization.Name;
Version = organization.Version;
}
[DataMember(Name="api-key")]
public string? ApiKey { get; set; }
public override OrganizationTable ToTable(int modelVersion = 1)
{
OrganizationTable table = base.ToTable(modelVersion);
table.ApiKey = ApiKey;
return table;
}
public static OrganizationResponse FromTable(OrganizationTable table)
{
return new()
{
Id = table.Id,
Name = table.Name,
ApiKey = table.ApiKey,
Version = table.Version ?? 0
};
}
}
The third change is to change any reference to Guid for this type in our API calls. The only two calls we have to worry about are the get by id, and the delete calls. Simply change Guid to string in the data types.
app.MapGet("/api/organization/{id}",
async Task<Results<Ok<OrganizationResponse>, NotFound>>
(OrganizationDataAccess oda, string id) =>
{
OrganizationTable? organization = await oda.GetOrganizationAsync(id);
if (organization is null)
{
return TypedResults.NotFound();
}
return TypedResults.Ok(OrganizationResponse.FromTable(organization));
}).WithApiVersionSet(organizations).HasApiVersion(version1);
app.MapDelete("/api/organization/{id}", async (OrganizationDataAccess oda, string id) =>
{
await oda.DeleteOrganizationAsync(id);
return TypedResults.Ok();
}).WithApiVersionSet(organizations).HasApiVersion(version1);
The fourth, and last change here, relies on us changing the data access code to change the data type for the field.
public virtual async Task<OrganizationTable?> GetOrganizationAsync(string id)
{
return await _dynamoDbContext.LoadAsync<OrganizationTable>(id);
}
public virtual async Task DeleteOrganizationAsync(string id)
{
await _dynamoDbContext.DeleteAsync<OrganizationTable>(id);
}
We now have an API that will save our organization with a unique name. Now let's address our other requirements around this. Something that is sitting in the back of my mind is that the friendly name should be automatically generated for the client. We don't want the user to have to create the friendly name so we'll add an API to generate this for us.
We have two requirements about the name; that it should have no whitespace, and that it should not worry about locale issues. Let's address both of those requirements with a new API, which we're going to call friendlyname. This is going to accept the organization name as the parameter, and we'll get the friendly name from this.
Important note: In taking this approach, we are dictating that the friendly name is created once, and once only. If the user has made a typo when they sign their organization up, there is no opportunity to change this other than to delete the organization and create a new one. This won't prevent them from changing the organization name later on; it's just the initial call that's going to create this name.
The implementation of the friendly name API simply converts the string to an invariant culture lower case, and removes whitespace entries.
app.MapGet("/api/friendlyname/{organization}",
(string organization) => TypedResults.Ok(string.Join("",
organization.ToLowerInvariant().Split(default(string[]),
StringSplitOptions.RemoveEmptyEntries))));
When we write our front end for the application, we can use this method to create our friendly API names.
Conclusion
In this article, we have covered a great deal of ground. In order to build our virtualizing service, we have decided to create a LocalStack representation of code that we can host on AWS. The code is very happy path, at the moment, and doesn't perform error handling or validation, but we have created a C# service that uses minimal APIs to add perform basic CRUD operations that target DynamoDB.
To make things more interesting, we have started to describe what our DynamoDB table is going to look like for an organization using Terraform. We have reached a natural point to start creating our user interface. In the next article, we are going to add a user interface and start tightening up our application by adding basic validation and error handling. We will also add the first rough implementation of adding request and response items relating to our organization.
History
- 24th October, 2023: Initial version

