Starting today, we embark on a series of articles delving into functional programming in C#. Throughout this exploration, we will clarify how functional programming can enhance code readability, efficiency, and unit testing, and we'll discuss how it can be applied in contemporary C# applications.
Introduction
Crafting software is a challenging endeavor, and creating high-quality software is even more formidable. This is why numerous books are dedicated to the subject, aiming to streamline the development process, and new architectural paradigms are frequently proposed to enhance data organization. Concurrently, methodologies like test-driven development have been widely adopted in the industry.
Nonetheless, a trend that has been somewhat overlooked in recent decades but is gaining traction with the advent of multicore processors is the inclination to embrace functional programming over imperative or object-oriented programming for software development. Our objective in this series is to unveil precisely what this paradigm entails and why it deserves broader adoption. Additionally, we will explore the challenges posed by its steep learning curve, which contributes to the slower pace of its adoption.
The subsequent textbook proves useful for concluding this series, addressing functional programming as a comprehensive subject matter.
This article was originally published here: Embracing functional programming in C#
What is Functional Programming?
Functional programming is frequently touted as the panacea for addressing all bugs in programs; it facilitates readability, testability, and maintainability. While this holds true in specific contexts, it's essential to delve into the rationale behind the commercial pitch.
What Leads to Bugs in Software?
It is challenging to answer this question succinctly. Bugs can be triggered by transient failures, unresponsive services, non-scalable components, or other availability and performance issues. In fact, we are referring here to intrinsic bugs provoked by a flawed design in the code. Among them, one of the more problematic issues is state mutation.
-
State mutation refers to the process of modifying the state of an object or variable. It involves changing the value or properties of the object, often leading to side effects that can impact the behavior of the program.
-
State mutation is prevalent in imperative programming paradigms, where the focus is on describing step-by-step procedures and manipulating the state of variables.
The challenge with state mutation is that it introduces complexity and makes it harder to reason about the behavior of a program. Unintended consequences can arise when different parts of the codebase modify the same state, leading to bugs that are difficult to trace and debug.
Example 1
Consider the following C# code that calculates the sum of integers in a list.
public static int Sum(List<int> list) {
var sum = 0;
foreach (var x in list)
sum += x;
return sum;
}
There is nothing incorrect in this code, and now, imagine that we need a method that calculates the sum of absolute values. To prevent duplication, we reuse the previous function.
public static int SumAbsolute(List<int> list) {
for (var i = 0; i < list.Count(); ++i)
list[i] = Math.Abs(list[i]);
return Sum(list);
}
Now we can use these methods in the main program.
static void Main(string[] args)
{
var data = new List<int>() { -1, 0 };
Console.WriteLine($"Sum of absolute values: {SumAbsolute(data)}");
Console.WriteLine($"Sum of values: {Sum(data)}");
}
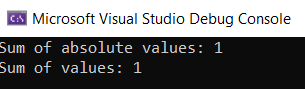
The core issue lies here because the SumAbsolute method directly mutates the input list without copying its values beforehand. In our context, detecting the problem was relatively straightforward, but consider the potential complications in a codebase comprising several thousand lines.
Example 2
This example is extracted from Functional Programming in C# (Buonanno).
public class Product
{
int inventory;
public bool IsLowOnInventory { get; private set; }
public int Inventory
{
get { return inventory; }
private set
{
inventory = value;
IsLowOnInventory = inventory <= 5;
}
}
}
In a multithreaded setting, there exists a brief window wherein the Inventory has been updated, but IsLowOnInventory has not. It occurs very infrequently, but it is possible, and during such instances, debugging becomes exceptionally challenging. These troublesome bugs are known as race conditions and are incredibly challenging to detect, if detection is even possible. While one might assume that our code is often single-threaded, unfortunately, multicore processors are making concurrency more and more prevalent.
Indeed, the move toward multicore machines is one of the main reasons for the renewed interest we're currently seeing in FP.
Functional Programming in C# (Buonanno)
In contrast, immutability, where once an object is created, its state cannot be altered, helps in creating more predictable and bug-resistant code. More on this later.
Why Do We Talk About Functional Programming?
We've just observed that state mutation can lead to significant bugs in certain programs. Now, let's consider a straightforward real-valued function ff of a single variable such that f(x)=x2+x+1. What is the outcome of f(1) ?
This question appears quite straightforward, and the result is 3. How do we calculate that? We take 1, square it, add 1, and then add 1 again. Why all this fuss?

The second method of calculation appears absolutely nonsensical: nevertheless, this is precisely what we occasionally engage in when altering the state of a variable throughout a computation (in our scenario, initially, x equals one, and then, in the midst of the operation, x becomes equal to 2). While it may sound trivial when articulated in this manner, it undeniably reflects the actuality of the situation.
When assessing a mathematical function for a specific value, that value remains constant throughout the computation. In fact, this aligns with one of the core concepts of functional programming and is a fundamental aspect of its name: the result will only depend on its arguments, irrespective of any global state. This concept is known as purity, and functional programming endeavors to steer clear of state mutation to maintain purity.
What is a Pure Function?
A pure function is a function that, given the same input, will always produce the same output and has no observable side effects.
- The output of the function is solely determined by its input.
- The function does not modify any external state or variables. It doesn't rely on or change anything outside of its scope (no side effects).
Pure functions are a fundamental concept in functional programming, promoting predictability, testability, and ease of reasoning about code.
This is the reason why, in purely functional languages like F#, variables are strictly immutable and cannot be altered once initialized. In C#, immutability is not inherently guaranteed by design, and we must employ alternative methods to uphold this essential property.
Information
The recently fashioned programming language Rust is not inherently a functional language, but variables are immutable by default. This serves as an acknowledgment that the mutation of state is identified as one of the fundamental sources of bugs.
Important
Side effects are inevitable in computer science. There will always be a need to modify a database or a file; otherwise, our work would be entirely pointless. The philosophy of functional programming is simply to isolate these effects in impure functions and code everything else with pure functions.
Why Purity Matters?
Purity is not merely a philosophical concept. Parallelism is significantly streamlined with pure functions, as we don't have to consider side effects or any global state. This is why functional programming is regarded as enhancing concurrency. Similarly, testing becomes notably straightforward with pure functions, thereby enhancing testability as well.
We will explore that aspect in the final post of this series.
Functional Programming is Connected to Mathematical Functions
Functional programming is, therefore, a paradigm that avoids mutation. However, the connection with a mathematical function extends beyond this.
When defining a function f, we comprehend its domain A (the values it can evaluate) and are aware of its potential return values B. This mapping is denoted as f:A⟼B.
In programming languages, the same principle should apply: we ought to be able to predict the outcome of any function or procedure that we use. However, is this always the case?
int Divide(int x, int y)
{
return x / y;
}
The signature states that the function accepts two integers and returns another integer. But this is not the case in all scenarios. What happens if we invoke the function like Divide(1, 0)? The function implementation doesn't abide by its signature, throwing DivideByZeroException.
Functional Programming in C# (https://functionalprogrammingcsharp.com/honest-functions)
Important
An honest function is one that accurately conveys all information about its possible inputs and outputs, consistently honoring its signature without any hidden dependencies or side effects.
How can we make this function an honest one? We can change the type of the y parameter (NonZeroInteger is a custom type which can contain any integer except zero).
An honest function is not merely a philosophical concept. Having precise knowledge of what a function returns allows for chaining this function, much like composing functions in a mathematical sense. Therefore, honesty, or referential transparency, enhances code predictability, testability, and reasoning.
LINQ is indeed an example in the .NET framework of code written in a functional style. LINQ allows us to chain, or compose, functions effectively.
var res = accounts.Where(x => x.IsActive).Select(t => t.Name).OrderByDescending();
Why Would One Opt for Functional Programming With C#? Why Not Utilize Haskell, Erlang, or F#?
This is an excellent question. Why not program in Haskell, F#, or another programming language since they are so wonderful? The issue is that we must consider the reality: there is a surplus of C# developers while F# engineers are quite scarce.
No company would take the risk of being unable to hire because it adopts a marvelous paradigm that nobody is proficient (this option is, in fact, only viable for large enterprises). That's why the compromise was made to stick with C# and attempt to incorporate functional programming within this language.
Information
C# is predominantly an object-oriented language, allowing it to serve as a bridge between the two worlds.
Information
In this series, we will utilize the LaYumba.Functional library, which is accessible as a NuGet package.
Introducing the Option Concept
As developers, we routinely use common methods from the base library without questioning them. For instance, converting a string to an integer is a common operation, as shown in the following code:
var input = Console.ReadLine();
var s = Convert.ToInt32(input);
Console.WriteLine(s);
This code will produce an integer output for inputs such as "1230" or "-2". However, what does the application yield when provided with an input like "hello" for instance?
This code exemplifies a function that is not honest; neither its name nor its signature indicates that an exception can be thrown. We only anticipate the return of an integer and when a bug is eventually discovered, developers will make slight modifications to the original code.
var input = Console.ReadLine();
if (int.TryParse(input, out var s))
{
Console.WriteLine(s);
}
else
Console.WriteLine("An error occurred.");
What is the Issue with This Code?
There is nothing inherently wrong with this code. It functions as intended and helps prevent bugs. However, it is highly probable that the output value will be the input of another function (typically, code is not written solely for pleasure), and in such cases, we need to handle two branches: one for correct input and another for incorrect input. This introduces if-else statements and potentially nested if-else statements, eventually making the code unreadable and thus difficult to maintain.
Functional programming, on the contrary, suggests working with honest functions where the output is precisely known. If a method might return an exception, it must be explicitly indicated in its signature. This approach allows us to compose functions without resorting to if-else statements and is closely aligned with its mathematical counterpart. When composing multiple functions in mathematics, it is uncommon to indicate that an error can occur.
The code becomes much clearer because we can chain functions.
Ok, but How Can We Do That? Enter Option
In functional programming, an Option is a data type that represents the presence or absence of a value. It is a way of handling the possibility of having no result or an undefined result without resorting to using null.
-
An Option type can be either Some(value), indicating the presence of a value, or None, indicating the absence of a value.
-
The use of Option types helps in creating more honest and predictable functions, as it forces explicit handling of the absence of a value. This can lead to more robust and less error-prone code.
Information
Option is sometimes referred to as Maybe in the literature.
With this concept, we can define an honest function for converting a string to an integer.
private static Option<int> ConvertToInt32(string input)
{
return int.TryParse(input, out var s) ? Some(s) : None;
}
The signature now clearly indicates that it is possible to not obtain data (due to an exception, for example), providing a cleaner and more explicit way to handle potential absence of values compared to using null or exceptions. The result can thus be used downstream to continue the workflow without the need for numerous if-else conditions.
var input = Console.ReadLine();
var res = ConvertToInt32(input);
Console.WriteLine(res);
This coding approach allows us to chain functions naturally, resulting in a more readable code. For example, consider the following scenario:
- Read a string
- Convert it to an integer
- Double its value
With an Option, the code closely resembles the previous algorithm.
var input = Console.ReadLine();
var res = ConvertToInt32(input).Map(x => x * 2);
Console.WriteLine(res);
Whether an error occurs during the conversion or everything proceeds smoothly, we will obtain a result without the need for complex branching logic.
Information
For the concrete implementation of the Option concept in C#, refer to Functional Programming in C# (Buonanno).
Introducing the Either Concept
The Option concept is suitable when we want to model the absence of data. However, there are scenarios where we need more information, specifically to understand why there is no value. This becomes particularly relevant when different exceptions can be thrown by the program.
Either is a data type that represents one of two possible values: Left or Right. It is often used to model a computation that can result in either a success (Right) or a failure (Left). The convention is to use Left for the error or failure case and Right for the success case. The advantage of using Either is that it provides more information about the failure by allowing us to include an error value along with the Left case. This can be helpful in situations where multiple types of errors can occur, and we want to distinguish between them.
Using Either, we can rewrite the previous code.
var input = Console.ReadLine();
var res = ConvertToInt32(input).Map(x => x * 2);
Console.WriteLine(res);
private static Either<string, int> ConvertToInt32(string input)
{
try
{
return Right(Convert.ToInt32(input));
}
catch (Exception ex)
{
return Left(ex.Message);
}
}
Information
We only scratch the surface of the various possibilities that functional programming offers for improved readability. We cannot be exhaustive or too rigorous with the intricate details (such as monads) in this brief overview. For a deeper understanding of these concepts, it is recommended to refer to a dedicated book on the subject.
We will now explore how to approach functional thinking with data. But, to avoid overloading this article, readers interested in this implementation can find the continuation here.
History
- 1st February, 2024: Initial version

