Introduction
In this article I will demonstrate how to read a large csv file chunk by chunk (1 chunk = no of lines) and populate System.Data.DataTable object and bulk insert to a database.
I will explain in details, what are the .NET framework components I used and face challenges like memory management, performance, large file read/write etc and how to resolve the problem. When I wrote this article, my intention was sharing my real life experience with others who are currently working with similar requirement or near future will work and will get benefited to read this article.
Background
One day client send us new requirements. The requirements are:
- Client will upload very large csv type data file by their web application.
- After uploading finished, files will be stored a specific server location.
- A software agent (Windows service, console app run with task scheduler) will parse those files sequentially and dump files data to a particular database.
- Data files schema will be predefined and this schema will be configurable by database.
- Client will configure that data file schema before uploading start.
- After dumping data from files, client will generate various report from the database.
Uploaded File Structure
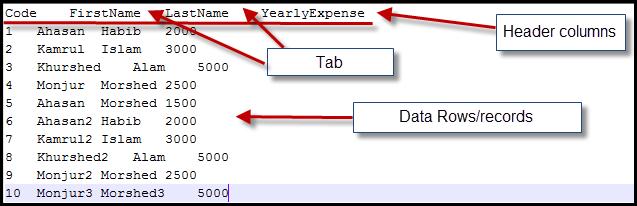
Previously I mentioned that file type will be .csv. We all know that .csv type file should have a pre-defined data separator. In ourcase that is “tab”. Means it contains “tab” separated data. First line of the file will be its column definition(data schema). Next each new line represents a row/record and this need to dump to the database periodically by any software agent/component.
Input data file contains four columns:
1. Code
2. YearlyExpense
3. LastName
4. FirstName
The file looks:
File Parsing
First off all I design an interface IFileParser which has two methods.
- GetFileData
- WriteChunkData
public interface IFileParser
{
IEnumerable<DataTable> GetFileData(string sourceDirectory);
void WriteChunkData(DataTable table, string distinationTable,
IList<KeyValuePair<string, string>> mapList);
}
1. GetFileData: The responsibility of GetFileData method is it read a file chunk by chunk and populate datatable (ADO.NET object) and send that table to its client.
2. WriteChunkData: WriteChunkData method responsibility is insert DataTable data to the database.
It needs to be clear that
Mulitple Lines = 1 chunk of data = 1 DataTable.
So the it will be better after reading data file, the method will return a single DataTable when finish to read a chunk and return it to its caller method. Then the caller method will call WriteChunkData method so that data will be dump to the database. This process will continue until reach end of the file. Two very important components of .NET framework will use:
- IEnumerable<T>
- yield
Interface methods
IEnumerable<DataTable> IFileParser.GetFileData(string sourceFileFullName)
{
bool firstLineOfChunk = true;
int chunkRowCount = 0;
DataTable chunkDataTable = null;
string columnData = null;
bool firstLineOfFile = true;
using (var sr = new StreamReader(sourceFileFullName))
{
string line = null;
while ((line = sr.ReadLine()) != null)
{
if (firstLineOfFile)
{
columnData = line;
firstLineOfFile = false;
continue;
}
if (firstLineOfChunk)
{
firstLineOfChunk = false;
chunkDataTable = CreateEmptyDataTable(columnData);
}
AddRow(chunkDataTable, line);
chunkRowCount++;
if (chunkRowCount == _chunkRowLimit)
{
firstLineOfChunk = true;
chunkRowCount = 0;
yield return chunkDataTable;
chunkDataTable = null;
}
}
}
if (null != chunkDataTable)
yield return chunkDataTable;
}
DataTable Create Without Data:
private DataTable CreateEmptyDataTable(string firstLine)
{
IList<string> columnList = Split(firstLine);
var dataTable = new DataTable("tblData");
dataTable.Columns.AddRange(columnList.Select(v => new DataColumn(v)).ToArray());
return dataTable;
}
Data Rows Added in DataTable:
private void AddRow(DataTable dataTable, string line)
{
DataRow newRow = dataTable.NewRow();
IList<string> fieldData = Split(line);
for (int columnIndex = 0; columnIndex < dataTable.Columns.Count; columnIndex++)
{
newRow[columnIndex] = fieldData[columnIndex];
}
dataTable.Rows.Add(newRow);
}
Tab Separated Data Split:
private IList<string> Split(string input)
{
var dataList = new List<string>();
foreach (string column in input.Split('\t'))
{
dataList.Add(column);
}
return dataList;
}
Why I use IEnumerable<T> <span style="color: rgb(17, 17, 17); font-family: "Segoe UI", Arial, sans-serif; font-size: 14px;">instead of </span>IList<T> or ICollection<T>. The reason behind is IList<T> or ICollection>T> are not support lazy return feature. Another thing is inside method I use yield statement and it use before return statement for returning chunk data lazily.
If you plan to use yield statement in a method, that method return type must be
IEnumerableIEnumerable<T>IEnumeratorIEnumerator<T>
To use yield return you must respect some preconditions. If you use IList<T> instead of IEnumerable<T> you will get compilation errors:
System.Collections.Generic.IList<System.Data.DataTable>' is not an iterator interface type

You will find detail precondition to use yield statement in this link.
The main benefit of yield statement is, it supports evaluated code lazily. When return data by yield statement, current code is remembered and next time when the iteration method is called remaining statement is executed.
Another simple example:
public void ClientCode()
{
foreach (int i in GetValues())
{
Console.WriteLine(i.ToString());
}
}
public IEnumerable<int> GetValues()
{
yield return 1;
yield return 2;
yield return 3;
yield return 4;
}
The method will return 1 and print it to the console, next return 2 and print it to console, next 3 and print it to the console. Last return 4 and print it to the console. That way yield statement support lazily evaluated code.
StreamReader object is used for reading data file line by line. It helps to control memory pressure. It picks single line of data from disk to memory at a time.
In our datafile, first line of the data file is column list and next every line of data is a row/record. Some flag variables are used to track state like First Line, First Chunk Line.
When start reading, first chunk parsing time, create a DataTable and start populating data. When reach Maximum Chunk Size, method returns populated DataTable to its caller.
One very important concept need to clear properly before take advantage from lazy evaluation. We said previously that using IEnumerable<T> with yield statement actually work with lazy evaluation. Sometimes it may cause performance penalty.
IEnumerable<DataTable> dataTables = fileParser.GetFileData(sourceFileFullName);
Console.WriteLine("Total data tables for first time:" + dataTables.Count());
Console.WriteLine("Total data tables for second time: " + dataTables.Count());
Console.WriteLine("Total data tables for third time: " + dataTables.Count());
Though you call dataTables.Count() method 3 times, but actually it calls FileParser.GetFileData method 3 times. That type of scenario it will cause performance penalty. These scenarios need to handle carefully otherwise it will bring unfavorable circumstance for us.
Bulk Insert
void IFileParser.WriteChunkData(DataTable table, string distinationTable,
IList<KeyValuePair<string, string>> mapList)
{
using (var bulkCopy = new SqlBulkCopy(_connectionString, SqlBulkCopyOptions.Default))
{
bulkCopy.BulkCopyTimeout = 0;
bulkCopy.DestinationTableName = distinationTable;
foreach (KeyValuePair<string, string> map in mapList)
{
bulkCopy.ColumnMappings.Add(map.Key, map.Value);
}
bulkCopy.WriteToServer(table, DataRowState.Added);
}
}
The SqlBulkCopy object is very efficient to write huge data to SQL Server database from datasource. It has a property named ColumnMappings. Mapping source and destination data column information need to add in this property. Point to be noted that without adding mapping information, object treats that destination column will be same sequence as its source column. So it is always better to add mapping information both source and destination column are same with same sequence. Some SqlBulkCopy object behaviours you should know. These are:
- If destination table has any column which is not mentioned in source data then its default value will be inserted.
- If mapping destination column not found at destination table then
InvalidOperationException will be raised with message “The given ColumnMapping does not match up with any column in the source or destination.” - If mapping source column does not found at source datatable then
InvalidOperationException will be raised with message “The given ColumnName 'FirstName2' does not match up with any column in data source.” - Interesting point, source column is case insensitive but destination column is case sensitive. Means, destination database table column name must be same case in Mapping Information. Otherwise it treat that it is different.
Client Code
IFileParser fileParser = new DefaultFileParser();
string destinationTableName = "Data";
string sourceDirectory = @"D:\Data";
string sourceFileFullName = GetFileFullName(sourceDirectory);
IEnumerable<DataTable> dataTables = fileParser.GetFileData(sourceFileFullName);
foreach(DataTable tbl in dataTables)
{
fileParser.WriteChunkData(tbl, destinationTableName, Map());
GC.Collect();
}
Console.WriteLine("Completed successfully!");
GetFileData method return list of datatable. Though it is IEnumerable<DataTable> so when accessing its any property then its body will execute. So one mistake you may do:
try
{
IEnumerable<DataTable> dataTables = fileParser.GetFileData(sourceFileFullName);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
throw;
}
But it never throw/catch any exception because GetFileData method's code will not execute. So when you debug that method just mind it code will not go inside that method only because it returns IEnumerable<T> with yeild statement. When I access datatables inside foreach loop then it will execute the code and returns DataTable one by one.
I use GC.Collect method once per iteration. Why it is needed? Well, though I use tbl variable inside foreach, each time new datatable is assigned to that variable and previous (after database write) is reassigned with new one and data will be waiting for garbage collection for release memory. Though it is very large amount of data so i need it when it finish, garbage collection will collect that as quick as possible. So I called GC.Collect for force collection of garbage data. If you want to check its benefit,
long totalMemoryBefore = System.Diagnostics.Process.GetCurrentProcess().PrivateMemorySize64;
fileParser.WriteChunkData(tbl, destinationTableName, Map());
GC.Collect();
long totalMemoryAfter = System.Diagnostics.Process.GetCurrentProcess().PrivateMemorySize64;
You can use various counter to judge memory cleanup after calling GC.Collect.
Precaution When Writing Code
When you will work with (file parsing and dumping to database type) that type of requirement you need to following some technique. That will help you to manage your code easily.
- Write more and more data validation code before start processing.
- Write defensive coding as much as possible.
- Never trust data which you receive from difference sources.
- First validate data schema. Then go for data. Xml type data has some kind of Schema validation with xsd. But text/csv file has no such tool. You can manually do it.
- Throw custom exception with detail error message where mismatch found so that you can understand where and what the problem found.
- Log custom exception with detail error data and stack trace if possible then including line number where the error found.
- Do not correct any data at run-time by your own decision without client/domain expert confirmation. Event single space is an issue. You do not know space has a special meaning there or not.
- Write client notification code like emailing/send sms so that if any error/exceptional things happen then client can know as early as possible.
Points of Interest
In my code sample and demonstration I did not present data validation/exception related things. Event I did not show any defensive programming. You need to write validation code for validating data. Though data comes from a .csv file, actually text file and text file data is always unstructured, so you need to write extra code for validating and because of tab separation you need to take special care of space/tab/carriage return/new line feed characters. You may need to write some extra code for data cleaning before dump it to database. You may need to take decision from client or domain expert regarding that.

