Introduction
In the course of developing an Order Management System, the need for a transactional method of processing trade records became apparent. This test app shows, in a simplified manner, how one can modify the contents of a table in SQL Server and use the result(s) of that modification to update another, dependent, table.
Background
It is commonplace in SQL to insert records into a table and to retrieve the identities associated with the rows that have been inserted (using RETURN @@IDENTITY) and then to use those identities for other, dependent, inserts on another table.
Obviously if the first batch of transactions throws an error, there is a possibility that you will not be able to commit your second, dependent, batch of transactions. On the flipside, it is also possible that your second batch (the dependent batch) of transactions can throw an error. In this case, you have already committed data to the first table and may want to roll back those changes to ensure your database is not left in an inconsistent state.
This was particularly important in the business case I had to solve. For those not familiar with finance, most trades originate as "executions" (think of a trader calling a broker and saying "Hey, buy 100 shares of IBM") and end up being "allocated" across multiple funds (which means 20 shares to one fund, 30 to another and 50 to yet another). In designing the database to hold this trading information, it's obvious that there is an easy way to set this up if you use a simple foreign key relation between parent "executions" table and the "allocated trades" child table. There are two business requirements in this scenario. First, if an execution fails to get into the execution table (for whatever reason), any trades allocated from that execution should not get into the database. This is easy, for if the execution insert fails, you will not have a valid executionid to insert into the second table, as a result the foreign key constraint will not allow you to insert the allocated trades. The other requirement is the reverse of the first situation, if any of the allocated trades don't get into the database (for whatever reason) then the original execution should also not be in the database. In this situation, the foreign key constraint will not matter as it is the child table that has failed to be updated properly, hence the need for a mechanism to roll back the original parent table insert should any subsequent, dependent, transactions fail. Here's where you can make use of the .NET CommittableTransaction class.
Using the Code
CommittableTransactionTester is straightforward console app that updates a database and rolls back or commits transactions based on whether or not any part of the batch failed. Note that I've omitted a few of the methods that are called in Main(), they can be found in the attached project for reference. There is also a TEST.bak file which should be loaded into SQL Server prior to running the test app.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Data.SqlClient;
using System.Transactions;
namespace CommittableTransactionTester
{
class Program
{
private static SqlConnection conn;
static void Main(string[] args)
{
CommittableTransaction MASTER_TRANSACTION = new CommittableTransaction();
conn = new SqlConnection(string.Format(@"Server={0};DataBase={1};
Trusted_Connection={2}",
"LOCALHOST", "TEST", "True"));
conn.Open();
conn.EnlistTransaction(MASTER_TRANSACTION);
try
{
Console.WriteLine("Enter an integer value to be inserted into table 2:");
int table2Input = Int32.Parse(Console.ReadLine());
Console.WriteLine("Enter an integer value to be inserted into table 1:");
int table1Input = Int32.Parse(Console.ReadLine());
UpdateTable2(table2Input, "UPDATING TABLE 2", MASTER_TRANSACTION);
int? readTable2 = ReadTable2(table2Input, MASTER_TRANSACTION);
UpdateTable1((int)table1Input, (int)readTable2,
string.Format("PASS! VALUE {0} IN TEST_TABLE_2", readTable2),
MASTER_TRANSACTION);
MASTER_TRANSACTION.Commit();
Console.WriteLine("TRANSACTIONS COMMITTED SUCCESSFULLY!");
}
catch (System.Transactions.TransactionException tranEx)
{
if(!MASTER_TRANSACTION.TransactionInformation.Status.Equals
(TransactionStatus.Aborted))
MASTER_TRANSACTION.Rollback(tranEx);
Console.WriteLine(tranEx.Message);
}
catch (Exception ex)
{
MASTER_TRANSACTION.Rollback();
Console.WriteLine(ex.Message);
}
Console.ReadKey();
}
}
}
The code should be relatively straightforward (if not, too bad, this is my first attempt to write a CodeProject article!). Running the project for the first time shouldn't result in any errors, regardless of your inputs:

It's when you get to subsequent tests that you will start to notice the beauty of the CommittableTransaction. For instance, if you inserted the values 1 and 1 into the tables, and then try to pass the same values again, you will certainly get an error:
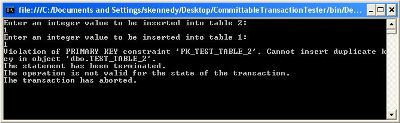
Another test (assuming you started with 1,1 as I did) is to check the case where you attempt to insert the values 2 and 1. In this case, it is perfectly fine to insert value 2 into table 2 (assuming you haven't done so already!), but you definitely cannot insert the value 1 into table 1 (assuming you have done so already). Hence, you probably want to roll back your insert of the value 2 into table 2, and this is exactly what happens:

The important point here is that the first transaction (inserting the value 2 into table 2) did not fail, it was the attempt to insert the value 1 into the first table that failed, hence the value 2 never makes it into the second table (because the entire transaction was rolled back).
Points of Interest
In practice, I share one instance of the CommittableTransaction class across a variety of different method calls during our end of day trade processing. The whole process is executed as a batch, if the trades don't get in, roll everything back, if we don't get a price for a security (necessary for other calculations not described here), roll everything back.... you get the point. Within each of these methods, there are literally hundreds of insert/update procedures that need to be executed successfully in order for our data to remain in a consistent state. If any of these procedures fail, they are all rolled back.
History

