In the first couple of articles, we looked at streams. We saw that we could take something simple such as a list of countries, filter or map their names and then print them via a foreach. We then looked at ranges/loops and generators as a way of supplying values as an alternative to a predefined list.
Although we didn’t explicitly mention this, a stream can be divided into 3 distinct parts:
- A source operation such as a supplier or a generator which pushes elements into our stream via a spliterator.
- Optional intermediate steps: these can filter values, sort values, map values, affect the stream’s processing (such as go parallel) and so on.
- Finally, a terminal operation either consumes the values, reduces the values, short-circuits the values or collects them. Short-circuiting a terminal operation means that the stream may terminate before all values are processed. This is useful if the stream is infinite.
We’ve covered the first two parts reasonably well and also used forEach to do consuming, so let’s now look at collecting. Why collect instead of consume? There are several reasons including:
- Since it returns nothing, consuming must involve a side-effect (else it wouldn’t do anything) which when running in parallel might not be in the order we expect or to put it in order cause unnecessary synchronisation
- We want to use the results again later
- We want to reduce the values into a single result
- We want to be able to inspect/return the values, such as for unit tests or to build in reusability
- Side-effects can make testing hard and often require mocking
- Side-effects break the concept of pure-functions (values in, results out only; same values in give same results out) which make it harder to prove code works
We’ll start by looking at reduction. This is a form of collecting where instead of returning all the results which come out of the stream, we condense them down into [usually] a single result. A common example would be summing all the values. Let’s look at the built in reduction operations using a list of Integers as the source:
public class ListReduction
{
public static void main(String[] args)
{
List<Integer> numbersList = Arrays.asList(1, 2, 5, 4, 3);
System.out.println(numbersList.stream().count());
System.out.println(numbersList.stream().mapToInt(x -> x).sum());
System.out.println(numbersList.stream().mapToInt(x -> x).average()
.getAsDouble());
System.out.println(numbersList.stream().mapToInt(x -> x).max()
.getAsInt());
System.out.println(numbersList.stream().mapToInt(x -> x).min()
.getAsInt());
System.out.println(numbersList.stream().mapToInt(x -> x)
.summaryStatistics());
}
}
Note:
- the
summaryStatistics() operation calculates all the values average() returns an OptionalDouble – we need to use getAsDouble() to get the valuemax() and min() return OptionalInt – we need to use getAsInt() to get the value
As already discussed in the article on Optional, if the Optional value happens to be the special empty() value [when we didn't pass any values through or filtered all of them out], we will get a NullPointerException if we try to use get or getAs<type> – we might wish to consider getOrElse for example to supply a default to avoid this.
Also note because we were streaming a list, we had to use mapToInt(x -> x) to change the stream shape from Object to int as IntStream works with int not Integer.
If we used an array of int instead, we could dispense with the map:
public class ArrayReduction
{
public static void main(String[] args)
{
int[] numbersArray = new int[] { 1, 2, 5, 4, 3 };
System.out.println(Arrays.stream(numbersArray).count());
System.out.println(Arrays.stream(numbersArray).sum());
System.out.println(Arrays.stream(numbersArray).average().getAsDouble());
System.out.println(Arrays.stream(numbersArray).min().getAsInt());
System.out.println(Arrays.stream(numbersArray).max().getAsInt());
System.out.println(Arrays.stream(numbersArray).summaryStatistics());
}
}
This looks a bit tidier. We can’t do anything about having to create the stream each time. If we tried to save a reference to Arrays.stream(numbersArray), it would only be able to be used once. This is why summaryStatistics can be very useful.
What if we want to write our own reductions? There are two ways. The first is to use the reduce operation which we’ll look at here. The other way is to use collect which we’ll look at in the next article.
To do reduction, we need one or two things:
- a binary function which takes two values and returns a single one
- we may also need an initial value (termed the identity)
Let’s imagine the stream as a queue of values [assume the stream is sequential]. If an identity value is given, we’ll put that in queue first. All the values from the stream in turn are then added to the queue. Once we have our queue, we remove the first value and assign it to the accumulator. While there are more values in the queue, we remove the next first value from the queue, and then perform the binary function on the accumulator and the value removed. We then assign the result back to the accumulator. This is repeated until the queue is empty.
It’s easy to see why it’s useful to have an identity value. In the case of sum, for example, the identity is zero, and thus zero is assigned to the accumulator before values are taken from the stream. If there are no values in the stream, the final result is just zero.
What if both the streams are empty and there was no identity value? To solve this problem, the version of the API without an identity value returns an appropriate Optional. You can now see why we took a detour to discuss Optional in the last article.
Let’s replace the built in operations above with explicit reductions using reduce:
public class ExplicitReductions
{
public static void main(String[] args)
{
int[] numbersArray = new int[] { 1, 2, 3, 4, 5 };
System.out.println(Arrays.stream(numbersArray).map(x -> 1)
.reduce(0, Integer::sum));
System.out.println(Arrays.stream(numbersArray)
.reduce(0, Integer::sum));
System.out.println(Arrays.stream(numbersArray)
.reduce(Integer::min).getAsInt());
System.out.println(Arrays.stream(numbersArray)
.reduce(Integer::max).getAsInt());
}
}
A few things to note:
- To perform
count, we have to map the values to a 1 and then do a sum. It might seem that it would be far easier to just use length on the array to get the count, however remember in a stream we might have other operations first such as to filter some of the values. An example use might be to count how many values are even. - Average is missing since it’s a bit more complicated. We have to keep both a tally and a sum so the simple call to reduce is not enough to implement it.
- The reduction operation is also called ‘fold left’ since if we drew a tree, it would be leaning left.
For example with 4 values:
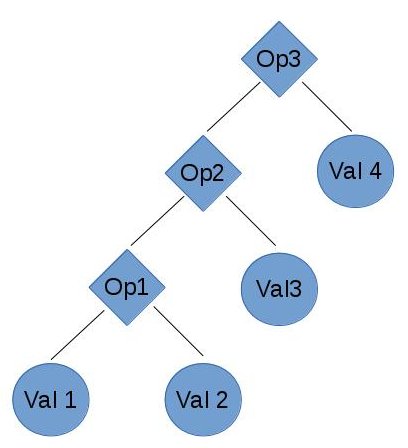
This reduces to (((Val1 Op1 Val2) Op2 Val3) Op3 Val4)
We can use our own functions in reduce. For example, to do a factorial, we just need a function which multiplies the accumulator by the next value:
public class Factorial
{
public static void main(String[] args)
{
int n = 6;
System.out.println(IntStream.rangeClosed(1, n)
.reduce((x, y) -> x * y).getAsInt());
}
}
Let’s finish off by looking at the short-circuit operators:
public class ShortCircuit
{
public static void main(String[] args)
{
List<String> countries = Arrays.asList("France", "India", "China",
"USA", "Germany");
System.out.println(countries.stream()
.filter(country -> country.contains("i"))
.findFirst().get());
System.out.println(countries.stream()
.filter(country -> country.contains("i"))
.findAny().get());
System.out.println(countries.stream()
.allMatch(country -> country.contains("i")));
System.out.println(countries.stream()
.allMatch(country -> !country.contains("z")));
System.out.println(countries.stream()
.noneMatch(country -> country.contains("z")));
System.out.println(countries.stream()
.anyMatch(country -> country.contains("i")));
System.out.println(countries.stream()
.anyMatch(country -> country.contains("z")));
}
}
As said earlier, terminal short-circuit operations may mean we don’t process all the values in the stream. There are built in operations to find the first value that matches [findFirst], any one value that matches [findAny] and to find out if all, any or none match [allMatch, anyMatch, noneMatch].
Note in the case of findFirst or findAny, we only need the first value which matches the predicate (although findAny is not guaranteed to return the first). However, if the stream has no ordering then we’d expect findFirst to behave like findAny. The operations allMatch, noneMatch and anyMatch may not short-circuit the stream at all since it may take evaluating all the values to determine whether the operator is true or false. Thus, an infinite stream using these may not terminate.
We’ve still got collectors to look at, so that will be the focus of the next article.

