Introduction
SQL Server 2012 introduced us a new feature called as Column Store Indexes (CSI), which brings a tremendous improvement in the performance of the query. This article is split into the following sections:
- Understanding what are CSIs
- Demo on CSI
- Limitations of CSI
- Executing a query, ignoring the CSI
Background
SQL Server, until 2008R2, has supported two type of storages – Heap & B-Trees. The data in any table, without an index defined on it gets stored in a heap storage mode, while the data of a table with an index (either clustered or non-clustered) gets stored in a B-Tree structure. But, both heap and B-tree storage modes store the data row-wise, while the Column Store indexes (CSI) of a table, store the data in a columnar format. This has a huge performance improvement, we will see how later in this article. To further speed up such queries, SQL 2012 also introduced a new query processing mode, called as the “Batch Processing Mode”, where operators process a batch of rows (typically 1000 rows) rather than a row at a time. Column Store Indexes along with batch processing mode improves the performance of the queries, usually by 10X and in some cases by 100X too.
How Do CSIs Improve Performance?
The fundamental unit of storage in SQL server is called a “Page”. The mdf file of any database is divided into n number of pages, ideally the number of pages grows as the data grows in the DB. The page size in SQL server is 8 KB. An extent is made up of 8 physically contiguous pages, i.e., 64 KB. An extent can be either a uniform extent (Data belongs to only 1 table) or a mixed extent (Data can belong to multiple tables). The data gets filled in a new extent as soon as the size of the extent (64 KB) is fully completed.
Now, for the sake of demonstration, let us not consider the actual sizes. Let us assume the below scenario. Consider an employee table with columns, EmpID, EmpName and Designation. Let us have a total of 6 rows in the table, each page with 3 rows (only for demo purposes).
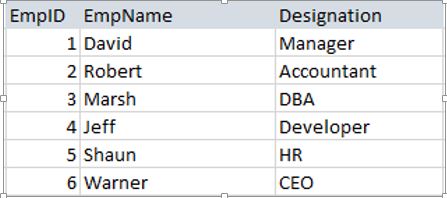
Now, let us see how the data gets retrieved with and without the CSI.
select empname from tblEmployees
The below diagram shows the way the data is stored and is queried, without the CSI.
(Data gets stored row wise in pages.)

Now let us create a column store index on the table (syntax shown later) and then the below diagram shows the retrieval process.
(Data gets stored column wise in pages.)
As you can see, in the first query, the data was retrieved from 2 pages while in the second query, the data got retrieved only from 1 page and hence there would be lesser number of disk I/O operations and hence there would be an improvement in the performance of the query.
Demo
For this demo, let us use the AdventureworksDW database, available on www.codeplex.com.
Open a new query window in the management studio, and turn on the statistics, so that the time taken for the query to run can be seen.
SET STATISTICS TIME ON
SET STATISTICS IO ON
Now run the following query;
select ProductKey,UnitPrice,CustomerPONumber,OrderDate from FactResellerSales
As the statistics are turned on, we can see the number of logical reads and the CPU time, in the Messages tab of the output window as shown below.
Now, let us create a Column store index on this table, using the query below:
CREATE NONCLUSTERED COLUMNSTORE INDEX csi_FactResellerSales
ON dbo.FactResellerSales
(ProductKey, UnitPrice, CustomerPONumber, OrderDate,SalesOrderNumber);
This would take a few seconds to run as the SQL server re-organizes the data storage mechanism. Once this query is run, again run the select query. Now observe the difference between the corresponding logical reads and the CPU time.
One can notice that there is an improvement in the logical reads by more than 10X while the CPU time got halved. This ratio is much bigger when the number of records are in huge number.
Limitations of CSI
- The biggest limitation with CSI in SQL 2012 is that, once a CSI is applied on a table, it becomes read-only. The table does not support any
Insert/Update/Delete operations on the table, as the understanding behind CSI is to create them only on tables with huge amount of data and or not updated frequently. But this wouldn’t be the scenario in most of the cases, real time. The solution to this problem is also explained below under. (SQL 2014 allows an updateable CSI.) - The column store index (SQL 2012) doesn’t support columns of all data types. Restricted types are:
- binary
- text
- image
- varchar(max)
- xml
- uniqueidentifier
Update Data on a CSI Table
To perform the Insert or update or delete operations on a table with a column store index, one has 2 options:
- Drop the index, perform the required operations and re-create the index again.
- Disable the index, perform the required operations and re-build the index again.
But these options might not suit the real time scenarios. For a table with a huge amount of data, the best way to perform these operations is explained here under.
- Create a CSI on the table with huge amount of data and which doesn’t have update operations on it, say historical data
- Create another table with a similar table design, except that the CSI is not defined on this table.
- Now this table can have current records which might be updated, inserted or deleted.
- During retrieval, pull the records from both the tables using a
union and thus the historical data can be retrieved at a quicker pace.
Ignore CSI Usage in Query
Suppose you have a table with CSI defined on it. And now, if you want to run a query without considering the CSI existence into account, the following query can be used.
select ProductKey,UnitPrice,CustomerPONumber,OrderDate from FactResellerSales
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)
Conclusion
Column store indexes when used appropriately, reduce disk I/O and use memory more efficiently. This is best suited for queries where scanning and aggregating a huge amount of data is the need of the hour. One should use it when the workload is read-only. These limitations are resolved in SQL 2014 and allows to create a clustered column store index (CCSI), which means that the table can be updated too.

