A common question is what is the difference between truncating a table and deleting a table. The short answer is that they both do the same thing, but in different ways. So consider that you have a table that contains 1,000,000 rows and you need to remove all of the rows.
Option 1 is to use DELETE tablename. Using DELETE with no filter will remove every row in the table as is to be expected while leaving the table intact, but as each row is being deleted, the row will be recorded in the transaction log, 1,000,000 rows = 1,000,000 records in the log. Some other traits of DELETE are:
DELETE uses a row lock each row in the table is locked for deletion- After
DELETE is run, the table can still contain empty data pages - If the table contains an
IDENTITY column, the counter of that column will remain
Option 2 is to use TRUNCATE TABLE tablename which will also delete all rows in the table, but the primary difference between this and DELETE is the logging. TRUNCATE TABLE deallocates the data pages and only logs the deallocation of the pages. Other traits of TRUNCATE includes:
- It always locks the table, including a schema lock, and page, but not each row
- Without exception, all pages are deallocated from the table, including empty pages
- Once truncated, an
IDENTITY column is reset to the seed column defined by the table, if no seed is defined, the value is set to 1.
Generally, TRUNCATE is more efficient then DELETE as it has reduced logging and fewer locks, but there are some limitations. TRUNCATE cannot be used with:
- A table that is referenced by a foreign key
- Participate in indexed views
- Are published using transactional or merge replication
- Truncate will not activate a trigger, due to how
TRUNCATE is logged - Requires
ALTER TABLE permission
One common misconception is that because of the way that TRUNCATE is logged, it cannot be rolled back when included in an explicit transaction and this is not the case at all. TRUNCATE is still logged just differently than DELETE. In order for SQL to maintain its ACID properties of a database, the ability to rollback, implicitly or explicitly, must be available.
To demonstrate this, review the T-SQL code below:
USE MASTER;
GO
IF EXISTS(SELECT * FROM sys.databases WHERE name = ‘LogGrowth’)
BEGIN
DROP DATABASE LogGrowth
END
CREATE DATABASE LogGrowth;
GO
ALTER DATABASE LogGrowth SET RECOVERY SIMPLE;
GO
SELECT name,
log_reuse_wait_desc,
CASE recovery_model
WHEN 1 THEN ‘FULL’
WHEN 2 THEN ‘BULK_LOGGED’
WHEN 3 THEN ‘SIMPLE’
END AS recovery_model
FROM sys.databases
WHERE name = ‘LogGrowth’;
GO
–Transactions
USE LogGrowth;
GO
IF NOT EXISTS(SELECT * FROM sys.tables WHERE name = ‘Transact’)
BEGIN
CREATE TABLE Transact(
col1 CHAR(50)
);
END
GO
–INSERT 50 rows in the Transact table
INSERT Transact
VALUES(‘This is gonna be gone’);
GO 50
SELECT COUNT(*)
FROM Transact;
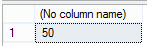
Now explicitly begin a transaction to TRUNCATE the table and show the row count and immediately roll the transaction back:
BEGIN TRAN
TRUNCATE TABLE Transact;
SELECT COUNT(*)
FROM Transact;
ROLLBACK TRAN
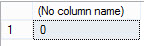
After rolling back the transaction, you can verify that the 50 records still exist by executing another SELECT statement with COUNT(*):
SELECT COUNT(*)
FROM Transact;
The T-SQL code above can be downloaded here.

