Introduction
I made a comment about Fluentx library being slow due to its excessive usage of delegates, now I'm being challenged to provide the facts.
Fx.Switch Original code
Original Fx.Switch sample:
static int FxSwitch(object obj)
{
int result = -1;
Type typ = obj.GetType();
var fx = Fx.Switch(typ);
fx.Case<int>().Execute(() =>
{
result = 1;
})
.Case<string>().Execute(() =>
{
result = 2;
})
.Default(() =>
{
result = 0;
});
return result;
}
Simple alternative
static int SimpleSwitch(object obj)
{
int result = -1;
Type typ = obj.GetType();
switch (Type.GetTypeCode(typ))
{
case TypeCode.Int32:
result = 1;
break;
case TypeCode.String:
result = 2;
break;
default:
result = 0;
break;
}
return result;
}
Speed Comparison
Method: average of 1 million iterations after proper warm up to remove cost of JItting
Fx.Switch 0.7497169 us
SimpleSwitch 0.0748549 us
So the speed difference between the two is 10x.
Memory Allocation Comparison
Fx.Switch allocates around 240 bytes per call. Here is the break down of 1 million calls:
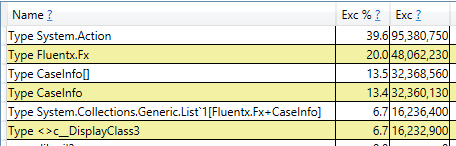
Delegates are the most costly in memory allocation, followed by Fluentx.Fx objects. CaseInfo[] and CaseInfo objects are allocated as part of List<CaseInfo> which is held by the Fluentx.Fx objects.
SimpleSwitch does not need to allocate any memory after the first run.
IL size and JITTing Comparison
Here is IL size and method Jitting comparison:
97 230 Fluentx.Program.FxSwitch(class System.Object) JIT FluentxTest.exe
26 58 Fluentx.Fx.Switch(class System.Type) JIT Fluentx.dll
30 60 Fluentx.Fx.Fluentx.ISwitchTypeBuilder.Case() JIT Fluentx.dll
19 32 Fluentx.Fx.Fluentx.ISwitchTypeCaseBuilder.Execute(class System.Action) JIT Fluentx.dll
30 93 Fluentx.Fx.Fluentx.ISwitchTypeBuilder.Case() JIT Fluentx.dll
94 223 Fluentx.Fx.Fluentx.ISwitchTypeBuilder.Default(class System.Action) JIT Fluentx.dll
8 6 Fluentx.Program+<>c__DisplayClass3.b__0() JIT FluentxTest.exe
40 47 Fluentx.Program.SimpleSwitch(class System.Object) JIT FluentxTest.exe
FxSwitch solution has 7 methods involved, 2 in main program and 5 in Fluentx.dll. The main method alone FxSwitch has 97 byte IL instruction, compiled into 230 byte machine code.
The SimpleSwitch implementation is much simpler: single method with 40 byte IL and 47 byte machine code.
Instruction Trace Comparison
If you wonder why FxSwitch is so costly or want to know how exactly it's implemented, you can get an instruction level trace using windbg with the "wt" command. Then you can display such "wt" command output using PerfView.
Here is instruction trace summary for FxSwitch soluton:

This shows the FxSwitch solution needs 1,216 instructions, without considering extra cost on garbbage collection. The most costly part is calling Linq.Enumerable.Last method on an internal list, and then enumerating on it.
Here is the same thing for FxSimple solution:
Only 113 instructions, mostly in GetType and GetTypeCode methods.
Algorithm Complexity Analysis
The expectation for switch statement is that its time complexity should be constant. In .Net, implementation for switching on string even try to achive this expectation when there are enough case labels. This is achived by constructing a Dictionary<string, int> lookup table on first use.
The FxSwitch solution has time complexity of: O(N * Ln(N)) + O(N) = O(N * Ln(N)) where N is the number of case labels. So it performance would be worse when used on larger number of case labels.
The reason is that Fx.Switch is implemented by constructing an internal List first and then perform a linear search on the list. The cost of constructing a List by keep appending to it is O(N * Ln(N)) because the list needs to be resized from time to time, allocating more memory and copying more memory. As the list is constructed once, used and then discarded, I would think may be the list does not need to be constructed in the first place. In this case, the time complexity would be linear O(N), far from constant time expectation.
MultiDictionary
Fluentx provides a multiDictionary named Multititionary (sic.). Here is a sample usage:
Multitionary<int, string> muldic = new Multitionary<int, string>();
muldic.Add(new Kuple<int, string>(1, "1"));
muldic.Add(new Kuple<int, string>(1, "one"));
muldic.Add(new Kuple<int, string>(2, "2"));
muldic.Add(new Kuple<int, string>(2, "two"));
Kuple<int, string> v = muldic[1];
The constructor looks little bit strange because it does not allow user to specify comparer, and initial size as Dictionary<K,V> does.
The Add call looks strange in that a Kuple object need to be allocated.
The index operator is even stranger in that it returns a single value, not a collection as you would expect. To get all the values associated with a key, you have to walk the whole dictionary.
If you look deeper, Multititionary is implemented using a single list of Kuple, so there is no way to get constant lookup time as in Dictionary.
The CLR team has already provided a MultiValueDictionary with the right AP surface and implementation.
Conclusions
I'm hoping to make a few points across with this discussion:
- C# and CLR have minimum optimization for delegates and LINQ Enumerable usages. When used on small bodies, relative cost could be very hard.
- It's possible to write quite good performance C# code, but you need to know what to avoid. So a good strategy is measure the performance of your code often and early.
- Write high-quality code is hard, write high-quality library code is even harder. So please be extremely careful when sharing your code as basic library code, and do not take other people's library code without a deeper understanding of how it works, especially when it does not come with source code.
Thanks

