Introduction
This article describes a simple method for addressing one of the most common difficulties encountered by small-to-medium sized companies with their technical documentation: structuring information across the documentation system.
The method can, in many cases:
- Make life easier for people who have to provide information or write material for technical documentation
- Vastly reduce the overhead of information management
- Make the information contained in technical documents far more accessible, which in turn can reduce the time required to personally explain things to frustrated users
These are not marketing-style claims. It has made those differences everywhere I have introduced it.
(Mind you, that's a bit of a cop-out, there, because I've only ever introduced it where I knew it would make big improvements).
Interestingly, the method has never been named, because:
- Until now, it has never needed a name. I've demonstrated it personally to everyone who needed it, and rarely written anything about it.
- Everyone who uses it knows how simple it is, and just how obvious it is to work that way, so I never bothered giving a name to something so simple and obvious.
However, now that it's "going public" in a place where a few hundred thousand "SND CODZ PLZ!" superior beings are waiting to claim credit for everything they see on the Interwebs, I shall satirise the whole "meaningful names" thing by lazily naming it The Wallace Method.
The well-known software house Gliebules and Daughter has kindly allowed use of their name, products, and processes in this article.
1 The Context of Technical Documents
Here's a great rule for life (and for technical documentation in particular):
Before you set off to go anywhere, make sure you know where you are.
1.1 Document Streams
Your company probably has multiple streams of product documentation, not just technical – e.g., there is typically a stream for marketing documents (for use when selling the products), and another for internal documents (for use when designing/discussing the products).
Each stream has its own storage structures, document libraries, etc. with the technical documentation requirements normally being the most sophisticated, simply because it contains the largest volume of detailed information.
Two points are important to note about the streams:
- Text from one stream is rarely usable in documents in other streams, because the people who read the documents in each stream are either different people, or are the same people who are reading for a different purpose.
To illuminate this: if you are thinking of buying a video recorder, you are not interested in which buttons you need to press to program it to record your favourite soaps; you only want to know its features. You want marketing information.
When the dog has buried the remote, and you are on your hands and knees trying to program the damned thing, the last thing you need to read is text telling you its features. You want technical information.
- Diagrams, screenshots, and graphics are very portable between the different streams, so make sure that everyone can find all the fantastic image files you've made – time spent on drawing the same diagram twice is Christmas-bonus money wasted.
1.2 The Technical Documentation Perspective
Now, I know that you're a developer, and are therefore the smartest man in the room/planet/galaxy far, far away/flea circus, but the chances are that you still need a little bit of perspective adjustment, where technical documentation is concerned.
The only perspective that works for technical documentation (it's true: There can be Only One) can be demonstrated by following this process:
- Print out a hard copy of every technical document produced by your company.
- Pile them all up in a single pile, one on top of the other in whatever order you feel is appropriate.
- In a word processor, open your standard template for document front pages.
- Where the title goes, enter the words: "Our Products".
- Print out a hard copy of the page.
- Put it on top of the pile of technical documents.
- If someone asks you how many technical documents your company has, point at the pile, and say "One".
Got that?
You have one and only one technical document, which covers every detail of every product your company makes.
For everyone's convenience, that one document is chopped up into smaller sections, which are produced and distributed independently, each focusing on one or more particular elements of "your products".
Just to confuse everyone, we also refer to these sections as "documents".
That is the only perspective that works. Every other perspective (I've seen them all, many times, and heard every excuse) leads to unnecessary problems, work, and expense.
1.3 How Having the Wrong Perspective Bites You
Let's look at an example of what can result from the absence of the correct perspective.
1.3.1 The Situation at Gliebules and Daughter
Gliebules and Daughter (G&D) is a Big Data company, which has five main software products:
- The G&D Data Pipelinifier sucks in oodles of data from wherever it is told to.
- The G&D Data Transmogrificator transmogrificates the sucked-in data.
- The G&D Data Jajahardericator is an optional product, which massages data that has been transmogrificated.
- G&D GoodLooki is an in-house built user interface which allows users to work with their data.
- G&D MeGodOk is an administrative UI, for controlling it all.
From that grand overview, it is quite clear that the five products together serve a single purpose: to get data from somewhere and feed it to clients.
The problem that G&D has is that each development department acts alone when producing documentation, documenting their products as if they were independent things, which, as we have seen, they are clearly not.
Our correct perspective was not the perspective used at Gliebules and Daughter.
1.3.2 The Effect of Using the Wrong Perspective at Gliebules and Daughter
A brief look at G&D's technical documents showed that the Pipelinifier user guide had a section describing the Transmogrificator, Transmogrificator documents had sections describing the Pipelinifier, and more than half of the Jajahardericator documentation was spent on explaining how everything else works.
This is perfectly understandable. If you sit someone down and say "document your tool!", he is likely to spend more of his time researching and documenting other things, because he knows how his tool works, and he sees the other things as the hard part that needs to be explained, so he explains them where he is, rather than in the right place.
This is a combination of the "We Need Everything Everywhere" and the "Type where the curser is" syndromes, both of which are extremely common.
So, at G&D, people all over the company were documenting the same things in different words in different documents, and documentation updates for product changes had become a joke, because no-one knew which – or even how many – documents had to be updated when a product changed.
Worse: people were sometimes aware that something was documented in other documents, so were not including it in their own document – which was the only place the information should have been.
This gave G&D customers serious problems:
- They could not find information they needed, because it was all over the place.
- When they did find something that looked useful, half the time it didn't work, because it had been written in the wrong place by the wrong people and never updated.
- Some customers concluded that they could not trust any of the documentation.
This resulted in G&D customer-support requirements vampirically sucking all the life out of the development teams.
In other words: it was quite a normal situation, for documentation.
Oh, and in case you haven't guessed, it is closely based on extremely similar situations that I have had to fix for several companies.
1.3.3 Why the Gliebules and Daughter Problem Happens
The mess at G&D can be found, to varying degrees, in many, many software companies, from the smallest to the largest.
After many years of tearing my hair out to solve problems not only with documentation, but with the amount spent on customer support, I reached a few inevitable conclusions:
- Poor information management in technical documentation costs money.
- Inappropriate information management in technical documentation costs money.
- Good, appropriate information management in technical documentation can save an absolute fortune.
It's pretty obvious when you think about it, no?
Well, if it is so obvious, then why does no-one do anything about it? Why do I have to leave my home and fly all over the globe to point out and fix this "so obvious" thing?
Well, one thing that I always find is that documentation is rarely taken as being the source of problems like those at G&D. Intelligent people have actually asked me why, if the problem is the excessive cost of customer support, am I talking about documentation?
Here's how "the obvious" gets lost:
- After having spent time messing something up by doing it the wrong way, a customer calls support.
- He screams "IT DOESN'T WORK!" (Or he might say it quietly; horses for courses.)
- He demands an immediate explanation of why his fumbling efforts did not work.
- He then demands that the program be made to work the way he tried to make it work.
- Somewhere during all the (often venomous) discussions and frantic fix activity, someone casually mentions that the documentation is no help, but everyone ignores him.
In the subsequent rush to get things working the way that the customer has ad-hoc decided that it now has to work, no-one recognises that if the documentation had been up to scratch:
- The customer would have used the product the way it was designed to be used.
- It would have worked.
- No prio-1 change requests would have been added to the work queue. Nor prio-2 or prio-3 to prio-99, for that matter. No-one would have had to do or change anything.
The "Oh, we've got a document. That's good enough!" attitude is widespread. The quality and usefulness of a document are set at a zero priority; all that matters is that it exists.
Try taking the same attitude with code, and see how far it gets you:
"We've got some code. It's just thrown together by a bunch of people who didn't talk to each other about it, it doesn't do anything it's supposed to do, and it goes off in directions that it's not supposed to, but customers will end up just dumping it to one side and ignoring it, so that's OK. Ship it!"
2 The Wallace Method
I'll be chuckling over that name for a long time – it's the kind of meaningless, uninformative name that the method itself does not allow.
2.1 Objectives
The objective of the Wallace Method is to take all your disorganised information, whether well- or badly-written, and guide you into organising it. Your information will still be well- or badly-written, but at least it will be organised, meaning that:
- Readers will be able to find the information they need. This should take a lot of strain off your support team.
- Contributors will know where to put new information, and where to update existing information. You would probably be surprised at how much stress this can remove from the poor guys who have to add or update information in a document.
2.2 Requirements
The only requirement for the Wallace Method is the human brain.
The information that goes into documents is required by people, not computers; and it has to be understood by people, not computers.
Because computers do not understand what you write, they are the wrong tool for truly effective information management, which requires understanding of the information.
So, if you're a small to medium sized company, which doesn't have any extraordinary documentation requirements, all you need to manage your information is the human brain.
... And the ability to read, of course, but, given how I'm communicating this to you, I think we can take your literacy as a given.
2.3 The One and Only Wallace-method Rule
Yes, you read that section heading correctly: The Wallace Method has only one rule.
Here it is:
Rule 1: Everything added to a document must be entirely related to the nearest heading preceding it.
See what I was saying about it being obvious?
Here's a picture:
Fig. 2.3.1: A sample Wallace-method document-construction model
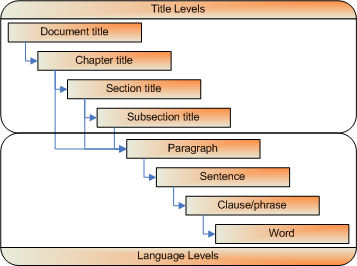
So, we have "Title Levels" and "Language Levels".
- At the title levels, everything beneath the title must be about the title – not necessarily the whole title, but nothing but the title.
- At the language levels, every word, clause/phrase, sentence, and paragraph must be dedicated to giving information about the subject of the nearest title above it.
That is phenomenally simple and obvious!
Why am I wasting your time with this simple and obvious drivel?
Here's why:
Exercise 1
Pick up one of your technical documents, and see if the phenomenally simple and obvious rule has been applied.
- How are your headings/titles? Is it easy to see what each chapter/section is about? Can you tell exactly what information must be within each section, just by reading its title?
- Inspect the Table of Contents (if there is one; if not, do it the hard way). Can you see that every subsection heading/title is an appropriate child to its parent heading/title?
- Pick a biggish section or chapter, go to the bottom of it, and work backward, hopping from sub-heading to sub-heading, checking that everything written beneath a heading is entirely related to the heading.
While going through the exercise, how many potential improvements did you spot?
That is why I'm wasting your time with this simple and obvious drivel.
With only one rule in your head, and a couple of hours, you can fix a huge number of problems in your documentation – and flag an even larger number to fix later.
2.4 How the Wallace Method Works
The definition of "information" is "useful data", but only people can decide what data is useful, and only people can decide where it is useful. Information that is in the wrong place is demoted to "data" status, and people are not good at reading and processing data (which may be one of the reasons why computers are so popular).
The Wallace Method depends on the meanings of titles being read and understood. If the meaning of a title is not understood, then it is impossible to populate its section with information.
Computers cannot understand what a title means, and have no idea how to communicate your thoughts and ideas to other people, so you can't let them do your information management for you.
Computer-application-based information-management systems always become too cumbersome, restrictive, and difficult to maintain, because all you can do to compensate for what is seen as human error in using the system is add more and more increasingly complicated and confusing rules, until it eventually just grinds to a halt.
Even the stupidest person, however, can make value judgements like "Hey, this has got nothing to do with that!", so making everyone follow the one (phenomenally simple and obvious) rule actually makes it impossible for information to find itself in the wrong place, with hardly any effort on the part of anyone.
The Wallace Method works because it uses the most sophisticated computing device that you have available to you – your brain. It uses your brain to do something that it finds really easy to do – classify and correlate stuff.
To do all that classification and correlation, your brain uses an immense number of complicated and sophisticated rules, which are governed by your knowledge and experience.
With current technology, it would probably take a hundred man-years to write all those rules for a computer to use (and add a million years for debugging).
But all that is really needed is something to make your brain focus its efforts in the right direction.
Hmm.
How about we give it just one unforgettable (and phenomenally simple and obvious) rule that it has to follow?
It just works. I should stick it in a white box with a minimalist piccy on it.
2.5 Implementing the Wallace Method
Because this whole thing is so phenomenally simple and obvious, you can probably work out the rest for yourself, but here are some pointers:
2.5.1 Use Meaningful Titles/Headers
Remember where we saw that the method works because the human brain can understand the meanings of titles/headings?
Well, if you don't use meaningful titles/headings, then there's nothing to understand, so you just managed to break the most phenomenally simple and obvious process ever.
Don't do it again.
Look at the titles/headings I've used in this article (which is not a technical document, so I haven't really followed any rules). Apart from a couple of old standards ("Objectives" and "Requirements") that don't need any more words in them, you can tell what is in the sections because the titles/headings tell you what is in the sections.
Imagine a world where you could open any technical document, and use the Table of Contents to find what you need by simply following an obvious trail through the titles/headings, instantly knowing which bits of the document are of no interest to you.
One rule, OK? Just follow one rule.
2.5.2 If a Section's Title and its Content no Longer Match, Change Something
Products change; things get bigger or smaller as stuff is added or taken away, and processes can become more complicated and convoluted (or, as is often the case, they already are more complicated and convoluted, but no-one bothered to tell you about it).
Obviously, that has an impact on the documentation, and changes to the product can make it look as though you're never going to be able to squeeze everything into the right place, with the right titles/headers.
But it only looks that way.
It looks like a problem because of the typical human aversion to change – once you've fixed all the problems in your document, all your headings and content are perfect, and you're proud of what you've achieved, your brain will resist the idea of changing the headers and content; it won't want to split content up, or remove a header that was perfectly OK last week, replacing it with two new headers that are not the same.
But lookit: you created the document on a computer, so it's really easy to change things – to change everything, if need be – it's not like you have to scrap a dozen stone tablets, and carve fifteen more to replace them.
You can split sections, add sections, remove sections, or merge sections; you can edit titles, add titles, or remove titles. No problem.
If you even find yourself using the word "squeeze", start looking for ways to restructure the document, not just for ways to add the new information (it's a mind-set thing: "I am restructuring the document", rather than "I am adding stuff").
All you have to do is make sure that your new structure follows one rule, and it'll have a happy ending.
2.5.3 It Goes all the Way to the Top
Remember the perspective that we have to keep on our technical documents?
The one where there is only one document that is split into sub-documents?
- The "Our Products" document is the top of the ladder.
- Each individual product is a subsection of "Our Products".
- Each sub-document for a product (user guide, admin guide, help file, whatever) is a subsection of the product's subsection.
- Each chapter in a product sub-document is a subsection of the subsection of the subsection of the "Our Products" document.
- And so on.
The whole thing is one big ladder, or tree, or however you want to imagine it.
Remember that.
And remember that there's a bunch of other documents that contain sections where some of the information you have might fit better than where it is now.
That is: if you follow the one rule, you cannot describe how to use a different product within a section of your document, like they did at Gliebules and Daughter; you have to move it to a section (in another sub-document) where it fits properly.
The trick there is that you don't describe how to transmogrificate data in a non-transmogrification document; you just say that your product requires data that has been transmogrificated.
2.5.4 Don't Write it Twice; Single-Source
Read this sentence again:
The trick there is that you don't describe how to transmogrificate data in a non-transmogrification document; you just say that your product requires data that has been transmogrificated.
"What if that is not enough?" I hear you say.
Sure, it happens.
Sometimes you do have to include information about other products within your sub-document – sometimes just a paragraph, sometime a table, sometimes whole sections.
Where that is the case, create a single-source topic/chunk out of the material you need, and put it in both sub-documents.
You may have to massage the text a little, to make it suitable for both documents, and you as sure as taxes have to make sure that your titles/headings make it very clear what's what, but it's eminently doable, if you know how to single-source information.
I won't go into single-sourcing here; maybe later. Just don't write new material where there is existing material you can source, 'K?
Interestingly, that sentence I made you read again: had I been writing this article in FrameMaker or Flare, I'd have single-sourced it. Copy and paste is not always your friend.
History
- 9th January, 2015: Original content

