Introduction
Design patterns explained in a famous book by Martin Fowler [Patterns of Enterprise Application Architecture, 2002], have had great influence on the way the modern applications interoperate with the relational databases. One of the most productive approaches in this area is known as object-relational mapper (ORM). At first glance, the mechanism takes care of mapping from objects of business logic to database tables. Although implementations may significantly differ in details, all of the ORM tools create a new layer of abstraction, promising to ease the manipulations on the objects and relationships comprising the application's business logic.
Using of object-relational mapping literally shifts the development of so called on-line transaction processing (OLTP) applications to a higher level. The choice of ORM framework heavily influences the architecture of the whole project. The benefits advertised by such frameworks could be even the reason for switching the platform in an existing project.
But what is the overhead we get when using different ORM solutions? Is it really true that, as stated by the author of SQLAlchemy Michael Bayer [The Architecture of Open Source Applications: SQLAlchemy. http://aosabook.org/en/sqlalchemy.html], those performance penalties are not crucial, and further more they are going to disappear as the JIT-enabled PyPy technology receives more acceptance? This is not an easy question to answer, because we need to benchmark many different ORM solutions using single set of tests.
In this article we are going to compare the overhead imposed by using two different ORM solutions: SQLAlchemy for Python vs. YB.ORM for C++ [see Quick Introduction here]. To achieve this two special test applications were developed, both implementing the same OLTP logic, and a test suite to test them.
Test stand
For the test server application we have chosen the following subject: car parking automation. Typical operations include: giving out a parking ticket, calculation of time spent on parking, payment for the service, and leaving the parking with ticket returned to the system. This is so called postpaid schema. The prepaid schema has been also implemented, where a user pays beforehand for some time, and has an option to prolongate the parking session at any time. When the user leaves parking the unused amount is sent to his/her parking account, which can be used later to pay for another parking session. All of these operations fit well in what is called CRUD (Create, Read, Update and Delete) semantics.
The source code of the test stand is available at GitHub: https://github.com/vnaydionov/teststand-parking. There you can find a test suite and two distinct applications implemented for two different platforms:
-
folder parking – in Python language, using SQLAlchemy (referred to as sa);
-
folder parkingxx – in C++, using YB.ORM (referred to as yborm below).
Both applications are driven by single test suite, which sequentially reproduces set of test cases for the API the applications implement. The test suite is written in Python, using standard unittest module. And the two applications both show "green light" on the tests.
To run the same test suite against some applications built on different platforms we need some sort of IPC (Inter-Process Communication). The most common IPC out there is the Socket API, it allows for communication between processes running on the same host or on different hosts. The test stand API is thus accessible via a TCP socket, using HTTP for request/response handling, and JSON is used for serialization of data structures. In Python test server application (sa) we use SimpleHTTPServer module to implement an HTTP server. In C++ test server application (yborm) we use HttpServer class for that purpose (files parkingxx/src/micro_http.h, parkingxx/src/micro_http.cpp), borrowed from folder examples/auth of YB.ORM project. For better performance we run both test and application on the same host having a multiple core CPU.
In real life environments there's almost always a requirement to handle incoming requests in parallel threads or processes. In CPython there is a known bottle-neck with multithreading, caused by the GIL (Global Interpreter Lock). Therefore Python powered server applications tend to use multiprocessing instead. On the other hand, in C++ there are no such concerns. Since the result of the benchmark should not be affected by the quality of thread/process pool implementation, this benchmark was run as a series of sequential request sent to server.
We use MySQL database server with its InnoDB transactional storage engine. Each of the two server applications runs on the same database instance.
Logging is configured in such manner to produce roughly the same amount of data for both implementations. All messages from WEB server and database queries are logged. Besides, additional testing was done with no logging enabled.
Both implementations work essentially the same way. To further simplify comparison of the applications, their business logic code bases were structured in a similar way. In this article we don't discuss the expressive power of the ORM tools, although it's one of important things when it comes to such tools. Just let's compare some numbers, the volumes of the code bases are also close: 20.4 KB (sa) versus 22.5 KB (yborm) – business logic code, plus 3.4 KB (sa) versus 5.7 KB (yborm) – data model description. Below is an example of the business logic code, written using SQLAlchemy and Python:
def check_plate_number(session, version=None,
registration_plate=None):
plate_number = str(registration_plate or '')
assert plate_number
active_orders_count = session.query(Order).filter(
(Order.plate_number == str(plate_number)) &
(Order.paid_until_ts > datetime.datetime.now()) &
(Order.finish_ts == None)).count()
if active_orders_count >= 1:
raise ApiResult(mk_resp('success', paid='true'))
raise ApiResult(mk_resp('success', paid='false'))
Similar example, using YB.ORM and C++:
ElementTree::ElementPtr check_plate_number(Session &session,
ILogger &logger,
const StringDict ¶ms)
{
string plate_number = params["registration_plate"];
YB_ASSERT(!plate_number.empty());
LongInt active_orders_count = query<order>(session).filter_by(
(Order::c.plate_number == plate_number) &&
(Order::c.paid_until_ts > now()) &&
(Order::c.finish_ts == Value())).count();
ElementTree::ElementPtr res = mk_resp("success");
res->add_json_string("paid", active_orders_count >= 1?
"true": "false");
throw ApiResult(res);
}
</order>
Hardware configuration and software packages
For test system we used Ubuntu Linux, which is very common for deploying server side applications. Testing was done using a desktop computer with the following equipment on board: Intel(R) Core(TM) i5 760 @2.80GHz, 4GB RAM, running 64-bit Ubuntu 12.04.
All versions of software packages are installed from Ubuntu stock repos, except for the following items: PyPy, PyMySQL, SOCI and YB.ORM.
- OS kernel: Linux 3.8.0-39-generic #58~precise1-Ubuntu SMP x86_64
- RDBMS server: MySQL 5.5.37-0ubuntu0.12.04.1
- MySQL client for C: libmysqlclient18 5.5.37-0ubuntu0.12.04.1
- reference Python interpreter: CPython 2.7.3
- MySQL client for СPython DBAPIv2: MySQLdb 1.2.3-1ubuntu0.1
- JIT-enabled Python interpreter: PyPy 2.3.1 (http://pypy.org/)
- MySQL client for PyPy DBAPIv2: PyMySQL 0.6.2 (https://github.com/PyMySQL/PyMySQL)
- C++ compiler: GCC version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5)
- ODBC driver manager: UnixODBC 2.2.14p2-5ubuntu3
- ODBC driver for MySQL: MyODBC 5.1.10-1
- database connectivity library for C++: SOCI 3.2.0 (http://soci.sourceforge.net/)
- ORM framework for C++: YB.ORM 0.4.5 (https://github.com/vnaydionov/yb-orm)
- ORM framework for Python: SQLAlchemy 0.7.4-1ubuntu0.1 (http://www.sqlalchemy.org/)
Test suite structure
To find out what functions get called during a test suite run look at the tbl. 1. The functions that do modify database are emphasized. Their contribution to the total time is roughly calculated, based on logs from the configuration built with YB.ORM and SOCI backend.
-
| function name
| number of calls
by one test suite run
| contribution to the total time of run, %
|
| get_service_info
| 22
| 8.95
|
| create_reservation
| 10
| 26.67
|
| pay_reservation
| 8
| 19.30
|
| get_user_account
| 7
| 1.24
|
| stop_service
| 6
| 13.81
|
| account_transfer
| 6
| 13.14
|
| cancel_reservation
| 4
| 10.69
|
| check_plate_number
| 3
| 0.60
|
| leave_parking
| 1
| 2.69
|
| issue_ticket
| 1
| 2.91
|
| total
| 68
| 100
|
Table 1. Test suite structure by function calls
Let's look at the structure of the test suite in terms of SQL statements being issued, see tbl. 2. It could helpful in order to understand how comparable are those two implementations built on totally different platforms. For these two flavors (build with SQLAlchemy or YB.ORM) the numbers in the table differ a bit, because the design of the libraries is not an exact match. But, as the assertions in the test suite show, the logic works in the same way in both applications.
-
| statement
| number of calls from SQLAlchemy app
| number of calls from YB.ORM app
|
| SELECT
| 78
| 106
|
| SELECT FOR UPDATE
| 88
| 89
|
| UPDATE
| 45
| 42
|
| INSERT
| 27
| 27
|
| DELETE
| 0
| 0
|
| total
| 238
| 264
|
Table 2. Test suite structure in terms of SQL statements
Of course, that kind of load the test suite generates is far from what can be found in real life environments. Nonetheless, this test suite allows us to get an idea of how the performance levels of the ORM layers compare to each other.
Testing methodology
Our test suite was run in consecutive batches, each 20 iterations long. For each of server configurations the timings were measured 5 times, to minimize errors. It yields 100 runs of the test suite for a configuration, in total.
Timings were measured using standard Unix command time, which outputs time spent by a process running in user space (user) and kernel (sys) modes, as well as real time (real) of command execution. The latter strongly influences the user experience.
For the client side only timing real is taken into account. Also standard output and standard error output both were redirected to /dev/null.
Command line sample for starting the test batch
$ time ( for x in `yes | head -n 20`; do python parking_http_tests.py -apu http:
real 0m24.762s
user 0m3.312s
sys 0m1.192s
For a running server process the user and sys timings are of practical interest, since they correlate with physical consumption of CPU resource. Timing real is omitted as it would include idle time when the server was waiting for an incoming request or some other I/O. Also, to see the measured timings, in course of running the tests, one must stop the server, as it normally works in an infinite loop.
Results of the benchmark
The following four configurations have been put to the test:
-
PyPy + SQLAlchemy
-
CPython + SQLAlchemy
-
YB.ORM + SOCI
-
YB.ORM + ODBC
For each of them two kinds of benchmarking has been conducted: with logging turned on and off. Totally – 8 combinations. Averaging was performed on the results of 5 measurements. Measured timings of 20 consecutive test suite runs for each combination are presented on fig. 1.
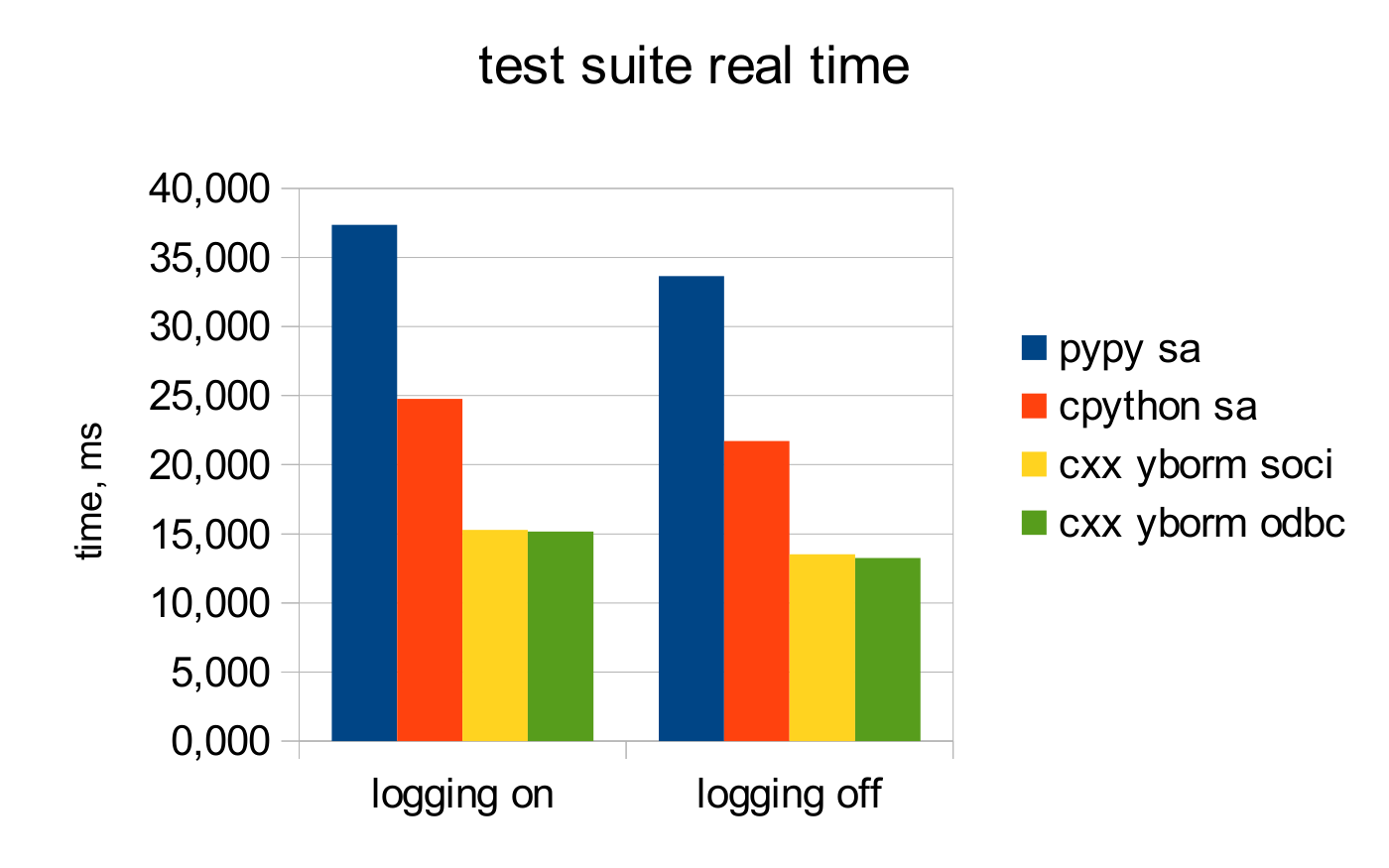
Figure 1. Timings for test suite running at client side, the less is better
From the deployment and maintenance point of view, it's important to know how much CPU time the server application consumes. The higher this number, the more CPU cores it takes to serve the same number of incoming requests, and the higher are the power consumption and heat emission. The CPU time consumed is counted as time a process spends working in user space mode plus time spent in kernel mode. The timings measured are shown at fig. 2.

Figure 2. CPU consumption at server side, the less is better
Switching off logging
In a search for possible ways to improve performance, one of the often considered options is turning off the debug functionality. It's very common to have logging on while developing and testing the software using ORM – one would need means to control what is going on under the hood. But when it comes to production environment, logging becomes a performance concern. Logging may be minimized or turned off, especially when the application functionality has matured.
But how big the log files really are? In these test applications every message from HTTP server gets logged, as well as every SQL statement executed with their input and output data. As noted above, the test suite is run 100 times for each of server configurations. The volume of log files generated is shown in tbl. 3.
|
| pypy sa
| cpython sa
| yborm soci
| yborm odbc
|
| size of log file, MB
| 19.02
| 18.97
| 20.78
| 20.95
|
| lines count, thousands
| 138.5
| 138.5
| 180.0
| 180.0
|
Table 3. The volume of log files after 100 runs of the test suite
The conducted measurements show (tbl. 4) how much the timings have improved, in percent, after logging has been switched off. The first line tells about the server response time, and the second is about the CPU consumption at server side.
|
| pypy sa
| cpython sa
| yborm soci
| yborm odbc
|
| client side tests
| 10.0
| 12.4
| 11.5
| 12.6
|
| CPU consumption
| 11.0
| 26.0
| 19.2
| 21.4
|
Table 4. The performance boost in % after the logging is switched off
Conclusions
Having considered this benchmark leads us to the following conclusions:
-
Among these four server implementations the fastest one is implemented in
C++ (yborm odbc). It performs three times better than the fastest one implemented in Python (cpython sa). Meanwhile the code base in C++ is bigger by only 20 %.
-
Server response time, i.e. after that time a user sees response, under some circumstances may also be shortened if YB.ORM is used. In this example there has been improvement about 38 %.
-
The promised performance of PyPy on running the multi-layered frameworks a-la SQLAlchemy is not achieved yet.
-
For the reasons still to be discovered, using YB.ORM with SOCI backend yields a bit poorer results than with ODBC backend.
-
Switching off the logging at server side did not as much impact as it could have been expected. In particular, the most significant improvement at server side has been observed with CPython+SQLAlchemy: 26 %. For YB.ORM this improvement is about 20 %.
For a long time Python programming language has been considered as a high productivity language. One of the reasons is the shorter cycle of "coding" – "running". And such great tools available as SQLAlchemy, they make this platform even more attractive. At the same time, the performance sometimes may suffer. In some cases it would be better to have Python for prototyping, and to hand over the final implementation to C++, which does have comparable frameworks and tools today.
History
- 2015-01-28: posted the initial revision

