Introduction
When I started learning design patterns, I was pretty excited at the beauty of design patterns and how applying design patterns correctly can make the application flexible, extensible and maintainable. I was so eager that I browsed codeproject almost everyday to look for new articles on design patterns. And soon I realized most of them explain design patterns individually and not many articles demonstrate usage of design patterns in a complete application.
So this is my attempt to bring together several design patterns in a complete (although might be trivial) application as an example for people just started with design patterns. I'm by no means an expert in design patterns, so feel free to comment and provide constructive criticism.
Background
This application makes use of the following design patterns. You may want to take a look at some other articles on codeproject if you need a quick refresh of those patterns, this article will not explain each pattern in detail and just focus on how they are applied in this application context.
- Chain of Responsibility
- Decorator
- Builder
- Template Method
- Factory Method
Using the code
Project Structure
The application solution contains 8 projects:
- Sharpenter.ResumeParser.UI.Console: this is the client of the parsing library
- Sharpenter.ResumeParser.Model: this project contains model classes as well as interfaces/contracts used in the whole application
- Sharpenter.ResumeParser.OutputFormatter.Json: responsible for serializing model classes to Json for output, convert property to use hyphen convention in Json, etc
- Sharpenter.ResumeParser.InputReader.Doc: contain class to read resume in doc file format
- Sharpenter.ResumeParser.InputReader.Docx: contain class to read resume in docx file format
- Sharpenter.ResumeParser.InputReader.Pdf: contain class to read resume in pdf file format
- Sharpenter.ResumeParser.InputReader.Plain: contain class to read resume in txt file format
- Sharpenter.ResumeParser.ResumeProcessor: main processing/parsing logic
The relationship among the projects can be seen in diagram below:
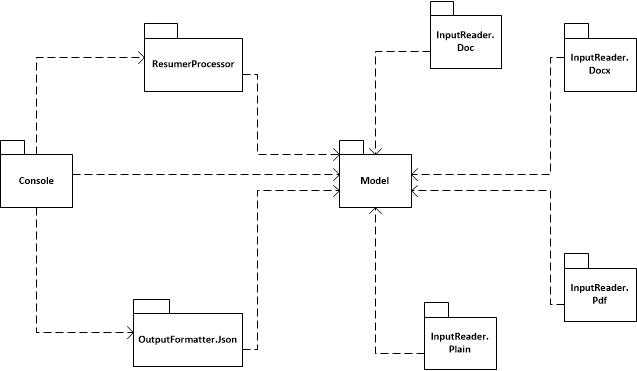
Some design decisions are taken when structuring the application this way:
- The main processing logic/input/output are implemented as class libraries so it can be easily used in any type of client applications like console, web, desktop, etc.
- The client (Console program) only has dependencies to ResumeProcessor (main logic), Model (contracts) and OutputFormatter.Json (formatting output). Different types of input readers are implemented in "plug-in" style so the client is able to detect and load them dynamically at runtime, and therefore there are no hard dependencies between client and input readers. The reason the readers are implemented that way is so that support for new resume format can be added easily by creating new input reader class library, and drop them into specific folder. No re-compilation of client/resume processor needed
- Output formatter is also exposed and controlled by client since formatting output is something client-specific and tend to be different from client to client. New type of output formatting (.e.g. XML) can be added easily. No re-compilation of resume processor needed.
- Common models, interfaces like IOutputFormatter, IInputReader, etc are put in a separated project to be referenced by all other projects.
- Different implementation of input reader, output formatter are put into different class library project, so that one project doesn't need to depend on other project's dependency. E.g. InputReader.Docx project doesn't need to reference iTextSharp library used by InputReader.Pdf.
Processing Flow

- The input resumes will go through several steps before returned as json to client:
- Input readers read resume file from specified location (e.g. folder in hard disk, an url for a html web page) and divide it into list of string
- SectionExtractor will look through the list of string, divide them into different sections (work experience, education, skills, etc)
- Each section is parsed by a parser into object model
- ResumeBuilder assembles all the parsed object models into one complete resume object
- Output formatter takes resume object and formats it before returning to client
Application Design
Some highlights of code/application design
All output formatters implement IOutputFormatter interface from Model project.
public interface IOutputFormatter
{
string Format(Resume resume);
}
The application only provides Json output formatter at the moment, but new type of formatter can be added easily.
The JsonOutputFormatter just delegates to Newsonsoft Json library to do serialization. It also uses a custom serializer class to convert C# property name into expected Json property name .e.g. FirstName -> first-name. I can add [JsonProperty(PropertyName="first-name")] to the model class to change its name when serializing, but that means the Model project will need to have dependency to Json library and I prefer to avoid any extra dependency if not necessary. Using custom serializer will leave my model classes "pure" and not polluted by those attributes.
public class JsonOutputFormatter : IOutputFormatter
{
private readonly JsonSerializerSettings _settings;
public JsonOutputFormatter()
{
_settings = new JsonSerializerSettings();
_settings.Converters.Add(new HyphenNameSerializer());
_settings.ReferenceLoopHandling = ReferenceLoopHandling.Ignore;
}
public string Format(Resume resume)
{
return JsonConvert.SerializeObject(resume, Formatting.Indented, _settings);
}
}
The input readers of the application are the classes that are responsible for reading and parsing different file format into a list of string that can be processed by the application.
The application uses input reader classes in "plug-in" style. When the ResumeProcessor is created, it will look through a specified folder (can be configured in application config file) and look through all assemblies that contain classes that implement IInputReader, create instance of each class and put them into a list. The task of finding all IInputReader is done by InputReaderFactory. This is an example of Factory Method pattern
var parsers = new List<IInputReader>();
foreach (var dll in Directory.GetFiles(parserLocation, "*.dll", SearchOption.AllDirectories))
{
try
{
var loadedAssembly = Assembly.LoadFile(dll);
var instances = from t in loadedAssembly.GetTypes()
where t.GetInterfaces().Contains(typeof(IInputReader))
select Activator.CreateInstance(t) as IInputReader;
parsers.AddRange(instances);
}
catch (FileLoadException)
{
}
catch (BadImageFormatException)
{
}
}
if (!parsers.Any())
{
throw new ApplicationException("No parsers registered");
}
Input readers will be read into a "Chain of Responsibility" to process resume files.
for (var i = 0; i < parsers.Count - 1; i++)
{
parsers[i].NextReader = parsers[i + 1];
}
The resume file will be parsed from front of the "chain" to the end, and stop at the first input reader that can process the file. If no reader found, an exception is thrown. All input readers inheriting from common InputReaderBase. This base class already implement flow to go through input reader one by one, asking each reader whether they can process the current file. So the concrete input reader just need to implement 2 abstract methods: CanHandle() and Handle(). This is an example of Template Method pattern
public abstract class InputReaderBase : IInputReader
{
public IInputReader NextReader { get; set; }
public IList<string> ReadIntoList(string location)
{
if (CanHandle(location))
{
return Handle(location);
}
if (NextReader != null)
{
return NextReader.ReadIntoList(location);
}
throw new NotSupportedResumeTypeException("No reader registered for this type of resume: " + location);
}
protected abstract bool CanHandle(string location);
protected abstract IList<string> Handle(string location);
}
Each input reader will declare what type of file that it can process (at the moment simply by looking at extension of the resume file):
protected override bool CanHandle(string location)
{
return location.EndsWith("pdf");
}
After reading resume file as list of string, the SectionExtractor class is responsible for going through the list of string and divided them into different sections.
At the moment, it just looks for keyword of each section in each line of input (and only limit to line that contains 4 words or less, to reduce the chance of the keyword appearing in normal lines, not the section title). The supported sections are: education, courses, summary, work experience, projects, skills, awards. Nothing much to talk about this class.
After input are divided into different sections, parser classes are called to parse each section into different model class. Each parser class is responsible for one section.
Majority of parses class parsing logic are keyword-based and rely on some assumption of the format of the resume. This is very simple implementation and doesn't mean to be state-of-the-art parser since it's not the main purpose of the application. The parsing logic can be improved further by doing some semantic analysis of each section content, etc
After each parser parses each section into object model, ResumeBuilder class assembles all into one Resume object. This is an example of Builder pattern
public class ResumeBuilder
{
private readonly Dictionary<SectionType, dynamic> _parserRegistry;
public ResumeBuilder(IResourceLoader resourceLoader)
{
_parserRegistry = new Dictionary<SectionType, dynamic>
{
{SectionType.Personal, new PersonalParser(resourceLoader)},
{SectionType.Summary, new SummaryParser()},
{SectionType.Education, new EducationParser()},
{SectionType.Projects, new ProjectsParser()},
{SectionType.WorkExperience, new WorkExperienceParser(resourceLoader)},
{SectionType.Skills, new SkillsParser()},
{SectionType.Courses, new CoursesParser()},
{SectionType.Awards, new AwardsParser()}
};
}
public Resume Build(IList<Section> sections)
{
var resume = new Resume();
foreach (var section in sections.Where(section => _parserRegistry.ContainsKey(section.Type)))
{
_parserRegistry[section.Type].Parse(section, resume);
}
return resume;
}
}
Some parsers also make use of ResourceLoader class. This class is responsible for loading some embedded text resources into list or hash as keyword look up. There's also a CachedResourceLoader implemented as a Decorator to original resource loader to avoid loading the same embedded resource again and again.
With most of the work done by other classes, the responsibility of this class is just to initialize and control the flow of the application:
public class ResumeProcessor
{
private readonly IOutputFormatter _outputFormatter;
private readonly IInputReader _inputReaders;
public ResumeProcessor(IOutputFormatter outputFormatter)
{
if (outputFormatter == null)
{
throw new ArgumentNullException("outputFormatter");
}
_outputFormatter = outputFormatter;
IInputReaderFactory inputReaderFactory = new InputReaderFactory(new ConfigFileApplicationSettingsAdapter());
_inputReaders = inputReaderFactory.LoadInputReaders();
}
public string Process(string location)
{
try
{
var rawInput = _inputReaders.ReadIntoList(location);
var sectionExtractor = new SectionExtractor();
var sections = sectionExtractor.ExtractFrom(rawInput);
IResourceLoader resourceLoader = new CachedResourceLoader(new ResourceLoader());
var resumeBuilder = new ResumeBuilder(resourceLoader);
var resume = resumeBuilder.Build(sections);
var formatted = _outputFormatter.Format(resume);
return formatted;
}
catch (IOException ex)
{
throw new ResumeParserException("There's a problem accessing the file, it might still being opened by other application", ex);
}
}
}
The main logic is in Process() method and as you can see, it's exactly the application flow described above since all logic are already delegated to other classes.
One thing to notice is I choose to accept only output formatter as dependency in the constructor. Other dependencies (InputReaderFactory, InputReaders etc) are instantiated directly in the constructor because libraries other than OutputFormatter are implementation detail of the library, client doesn't need to know about those dependencies. Although this decision makes those dependencies tightly coupled to ResumeProcessor and therefore more difficult to do unit test. It's just one of the trade-off that I need to make and in this case I think it's acceptable.
Points of Interest
I guess the most challenging part for me when writing this application is not the application itself but the logic of how to parse resume accurately. After reading up some semantic analysis theory, I gave up and decided to just implement a simple version of resume parsing based on keywords, since I don't intend to create a state-of-the-art commercial resume parser. So pardon me if the logic in each individual parser class is too simple and annoy you.
Building Note
It seems many people having problems with the post-build commands that I setup for the projects in the solution, so below are the steps to do before performing the build of the downloaded source code:
- Create a folder with the name "Test" at the root of the solution. This folder will contain any input resumes file and will be copied by post-build commands to Console project bin folder after compilation
- Create a folder with the name "InputReaders" at Sharpenter.ResumeParser.UI.Console\bin\Release or Sharpenter.ResumeParser.UI.Console\bin\Debug, depending on your build configuration. There are post-build commands for each input reader projects to automatically copy compiled dll into this folder for run-time loading and therefore it expects there's a folder InputReaders folder at the correct location
History
26/6/2015: Add building note
9/2/2015: Initial version

