Introduction
This simple tool converts a Japanese string to the equivalent Romaji string.
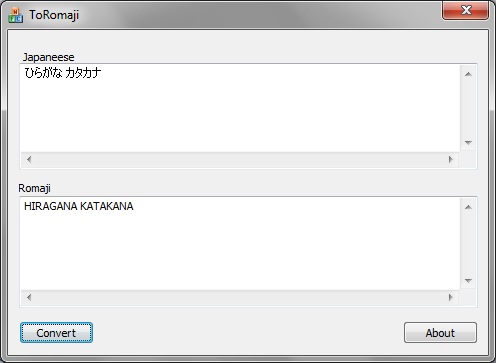
Screenshot of Japanese to Romaji converter.
Background
The romanization of Japanese is the application of the Latin alphabet to write the Japanese language. This method of writing is known as Romji. The Japanese language is written with a combination of three scripts: Chinese characters called kanji, and two syllabic scripts made up of modified Chinese characters, Hiragana and Katakana. Here I converts the Hiragana and Katakana letters to Romaji.
Using the Code
The Unicode chart guided me to build these tools:
When I started studying Japanese, it was very difficult to identify a Japanese text. I thought if a tool can convert Japanese to Romaji, then it will be good. After reading the Unicode range of Japanese characters, I got an idea to create the tool myself. There are a lot of tools available on the internet for converting Japanese to Romaji. Here is a simple technique to convert Japanese to Romaji.
int Parser::ParaseDB( TCHAR* pDBFileData_i, std::map<int,std::wstring>& pUnicodeMap );
The language information is added as two resource files, Hiragana.txt and Katakana.txt. These files are read from resource using the following code:
HRSRC hrInfo = FindResource( 0, MAKEINTRESOURCE
( IDR_IDR_HIRAGANA ),TEXT("IDR_DATA"));
HGLOBAL hRc = LoadResource(0, hrInfo );
TCHAR* pBuffer = (TCHAR* )LockResource( hRc );
Parser p;
p.ParaseDB(pBuffer, m_UnicodeMap);
HRSRC hrInfoKatakana = FindResource
( 0, MAKEINTRESOURCE( IDR_IDR_KATAKANA ),TEXT("IDR_DATA"));
HGLOBAL hRcKatakana = LoadResource(0, hrInfoKatakana );
TCHAR* pBufferKatakana = (TCHAR* )LockResource( hRcKatakana );
p.ParaseDB(pBufferKatakana, m_UnicodeMap);
Points of Interest
The Parser class can parse a text file containing Unicode value and corresponding English string. ParseDB() function parses the data in the below format and outputs a map containing all elements in the input file.
BEGIN_MAP:
//?
3093,12435,N.
..
..
END_MAP:
History
- 13th June, 2010: Initial post

